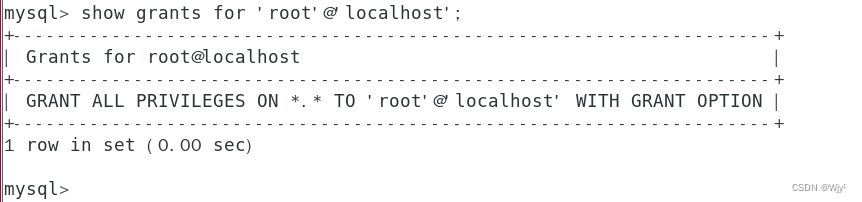
文章目录
- 前言
- 导入库
- 发送请求给指定网址
- 伪装自己
- 发送请求并获取响应
- 设置编码
- 解析HTML并获取结果
- 创建CSV文件并写入数据
- 打印输出结果
- 加载自定义字体
- 绘制折线图
- 完整代码
- 结束语

前言
本文介绍了如何使用Python编程语言获取双色球历史数据,并使用数据可视化工具Matplotlib绘制了红球数量的折线图。通过对双色球历史数据的分析,我们可以更好地了解双色球的开奖规律和趋势。
导入库
import requests
from lxml import etree
import csv
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
这部分代码导入了需要使用的库。requests库用于发送网络请求,lxml库用于解析HTML,csv库用于处理CSV文件,matplotlib.pyplot库用于绘制图表,matplotlib.font_manager.FontProperties库用于加载自定义字体。
发送请求给指定网址

url = 'https://datachart.500.com/ssq/'
在这段代码中,将指定的网址赋值给变量url,该网址是获取双色球历史数据的网站。
伪装自己

headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
这里通过设置headers字典来模拟浏览器的请求头,其中User-Agent字段指定了伪装的浏览器信息。
发送请求并获取响应

resp = requests.get(url, headers=headers)
使用requests.get()方法发送GET请求,并将响应结果赋值给变量resp。
设置编码
resp.encoding = 'gbk'
这里将响应的编码方式设为gbk,以确保正确解析网页内容。
解析HTML并获取结果

e = etree.HTML(resp.text)
reds = [tr.xpath('./td[contains(@class,"chartBall01")]/text()') for tr in e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')]
blues = e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]/td[contains(@class,"chartBall02")]/text()')
使用etree.HTML()方法对响应的文本进行解析,并通过XPath表达式提取出红球和篮球的数据。
-
对于红球的提取,首先通过
e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')获取到所有包含红球号码的行元素;然后在每行元素基础上,使用tr.xpath('./td[contains(@class,"chartBall01")]/text()')提取红球的文本内容。最终将所有红球号码保存在reds列表中。 -
对于篮球的提取,通过
e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]/td[contains(@class,"chartBall02")]/text()')直接提取所有篮球号码的文本内容,保存在blues列表中。
创建CSV文件并写入数据
with open('history.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
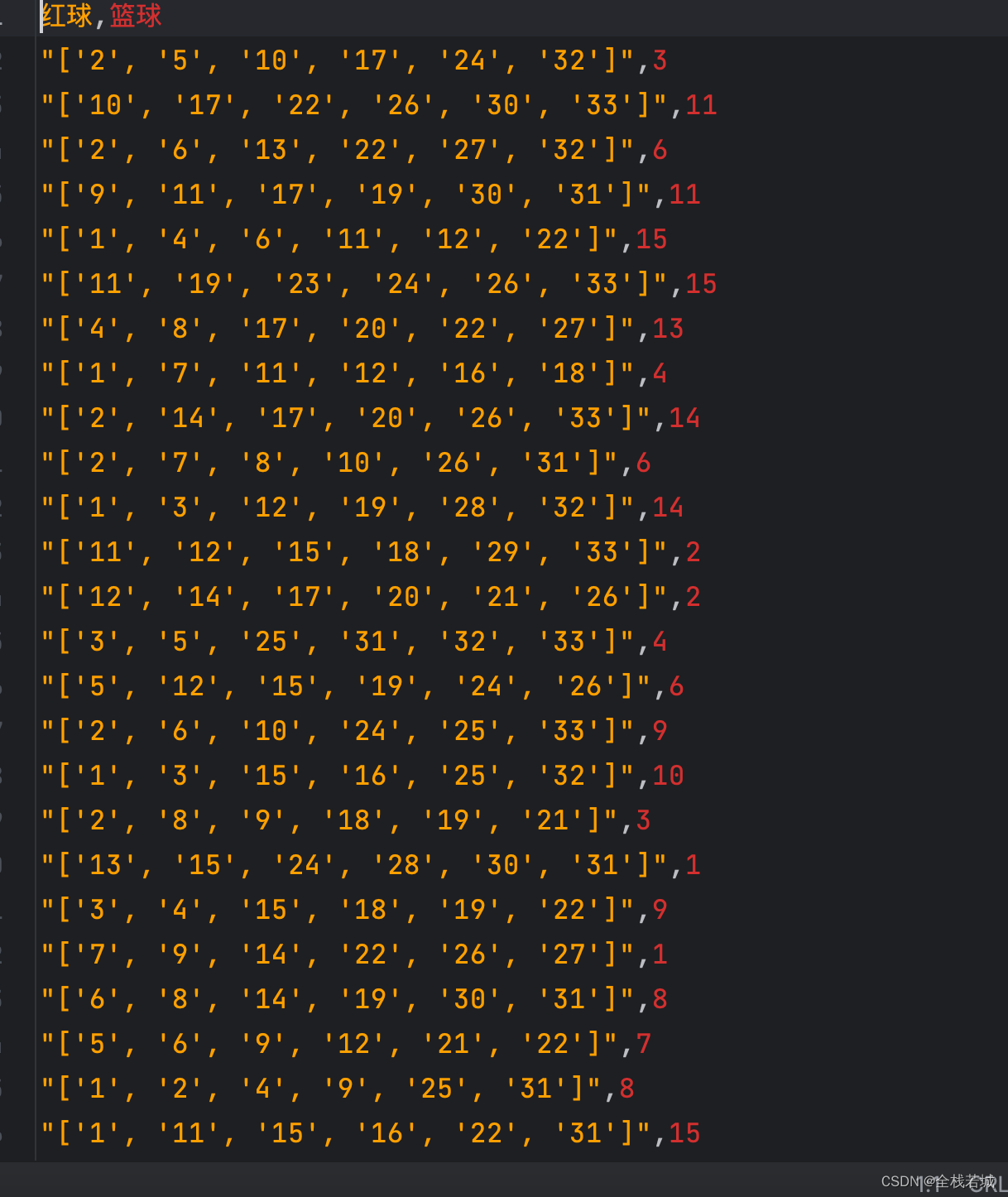
writer.writerow(['红球', '篮球']) # 写入表头
for r, b in zip(reds, blues):
writer.writerow([r, b]) # 写入数据
使用open()函数创建一个名为history.csv的CSV文件,并以写入的模式打开。然后使用csv.writer()创建一个writer对象,将红球和篮球的数据写入CSV文件。
-
with open('history.csv', 'w', newline='') as csvfile::打开文件history.csv,使用'w'模式表示写入,newline=''表示写入的行与行之间没有额外的空行。 -
writer = csv.writer(csvfile):创建一个writer对象,用于写入CSV文件。 -
writer.writerow(['红球', '篮球']):写入表头,即CSV文件的第一行数据。 -
for r, b in zip(reds, blues)::使用zip()函数将红球和篮球的数据进行配对。 -
writer.writerow([r, b]):将每一期的红球和篮球号码写入CSV文件。
打印输出结果
print("数据保存成功!")
简单地打印出"数据保存成功!"的提示信息。
加载自定义字体
font_path = '../caisemenghuanjingyu.ttf'
custom_font = FontProperties(fname=font_path)
指定自定义字体文件的路径,并使用FontProperties()函数创建一个custom_font对象,以便在图表中使用自定义字体。
绘制折线图
red_counts = [len(r) for r in reds]
blue_counts = len(blues)
plt.plot(red_counts, color='red', label='红球' )
plt.axhline(y=blue_counts, color='blue', linestyle='--', label='篮球' )
# 设置使用自定义字体
plt.xlabel('期数', fontproperties=custom_font)
plt.ylabel('数量', fontproperties=custom_font)
plt.title('双色球历史数据', fontproperties=custom_font)
plt.legend( )
plt.show()
使用plt.plot()方法绘制红球的折线图,将red_counts作为纵坐标的数据,设置线条颜色为红色,并指定标签为"红球"。
使用plt.axhline()方法绘制一条水平虚线,表示篮球的数量,将blue_counts作为水平线的位置,设置线条颜色为蓝色,并指定标签为"篮球"。
然后,通过plt.xlabel()和plt.ylabel()方法设定横纵坐标的标签文本,并通过plt.title()方法设定图表的标题。
最后,使用plt.legend()方法显示图例,以及plt.show()方法展示绘制的图表。
完整代码
import requests # 导入requests库,用于发送HTTP请求
from lxml import etree # 导入lxml库,用于解析HTML
import csv # 导入csv库,用于操作CSV文件
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图
from matplotlib.font_manager import FontProperties # 导入FontProperties类,用于设置字体
url = 'https://datachart.500.com/ssq/' # 设置目标网址
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
# 设置请求头信息,伪装成浏览器发送请求
resp = requests.get(url, headers=headers) # 发送HTTP GET请求,获取响应
resp.encoding ='gbk' # 设置响应的编码格式为gbk
e = etree.HTML(resp.text) # 将响应的内容解析为HTML对象
reds = [tr.xpath('./td[contains(@class,"chartBall01")]/text()') for tr in e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')]
# 从HTML对象中提取红球数据,使用XPath路径进行定位并提取文本内容,并将结果保存到reds列表中
blues = e.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]/td[contains(@class,"chartBall02")]/text()')
# 从HTML对象中提取蓝球数据,使用XPath路径进行定位并提取文本内容,并将结果保存到blues列表中
with open('history.csv', 'w', newline='') as csvfile:
# 打开名为history.csv的文件,如果文件不存在,则新建一个
writer = csv.writer(csvfile)
# 创建一个csv写入对象
writer.writerow(['红球', '篮球'])
# 写入表头 ['红球', '篮球']
for r, b in zip(reds, blues):
# 使用zip函数同时遍历reds和blues两个列表
# 将红球和蓝球配对,并按行写入CSV文件中
writer.writerow([r, b])
print("数据保存成功!") # 输出保存成功的提示信息
font_path = '../caisemenghuanjingyu.ttf' # 设置自定义字体文件的路径
custom_font = FontProperties(fname=font_path) # 创建自定义字体对象
red_counts = [len(r) for r in reds] # 计算每期红球数量,并保存到red_counts列表中
blue_counts = len(blues) # 计算篮球数量
plt.plot(red_counts, color='red', label='红球') # 绘制红球数量折线图,设置线条颜色为红色,添加标签"红球"
plt.axhline(y=blue_counts, color='blue', linestyle='--', label='篮球') # 绘制横线,表示篮球数量,设置线条颜色为蓝色,虚线样式,添加标签"篮球"
plt.xlabel('期数', fontproperties=custom_font) # 设置横坐标标签为"期数",使用自定义字体
plt.ylabel('数量', fontproperties=custom_font) # 设置纵坐标标签为"数量",使用自定义字体
plt.title('双色球历史数据', fontproperties=custom_font) # 设置图表标题为"双色球历史数据",使用自定义字体
plt.legend() # 显示图例
plt.show() # 显示图表
##运行效果截图
结束语
通过本文的学习,我们了解到了如何利用Python编程语言来获取网页数据、解析HTML内容,并将数据存储到CSV文件中。同时,我们还学会了使用Matplotlib库进行数据可视化,通过绘制折线图来展示红球数量的变化趋势。








![[CrackMe]Cruehead.1.exe的逆向及注册机编写](https://img-blog.csdnimg.cn/4764eed52f69487ba009f911e869420a.png)