项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
ChatIE:通过多轮问答问题实现实命名实体识别和关系事件的零样本信息抽取,并在NYT11-HRL等数据集上超过了全监督模型
零样本信息抽取(Information Extraction,IE)旨在从无标注文本中建立IE系统,因为很少涉及人为干预,该问题非常具有挑战性。但零样本IE不再需要标注数据时耗费的时间和人力,因此十分重要。近来的大规模语言模型(例如GPT-3,Chat GPT)在零样本设置下取得了很好的表现,这启发我们探索基于提示的方法来解决零样本IE任务。我们提出一个问题:不经过训练来实现零样本信息抽取是否可行?我们将零样本IE任务转变为一个两阶段框架的多轮问答问题(Chat IE),并在三个IE任务中广泛评估了该框架:实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的6个数据集上的实验结果表明,Chat IE取得了非常好的效果,甚至在几个数据集上(例如NYT11-HRL)上超过了全监督模型的表现。我们的工作能够为有限资源下IE系统的建立奠定基础。
1.方法介绍
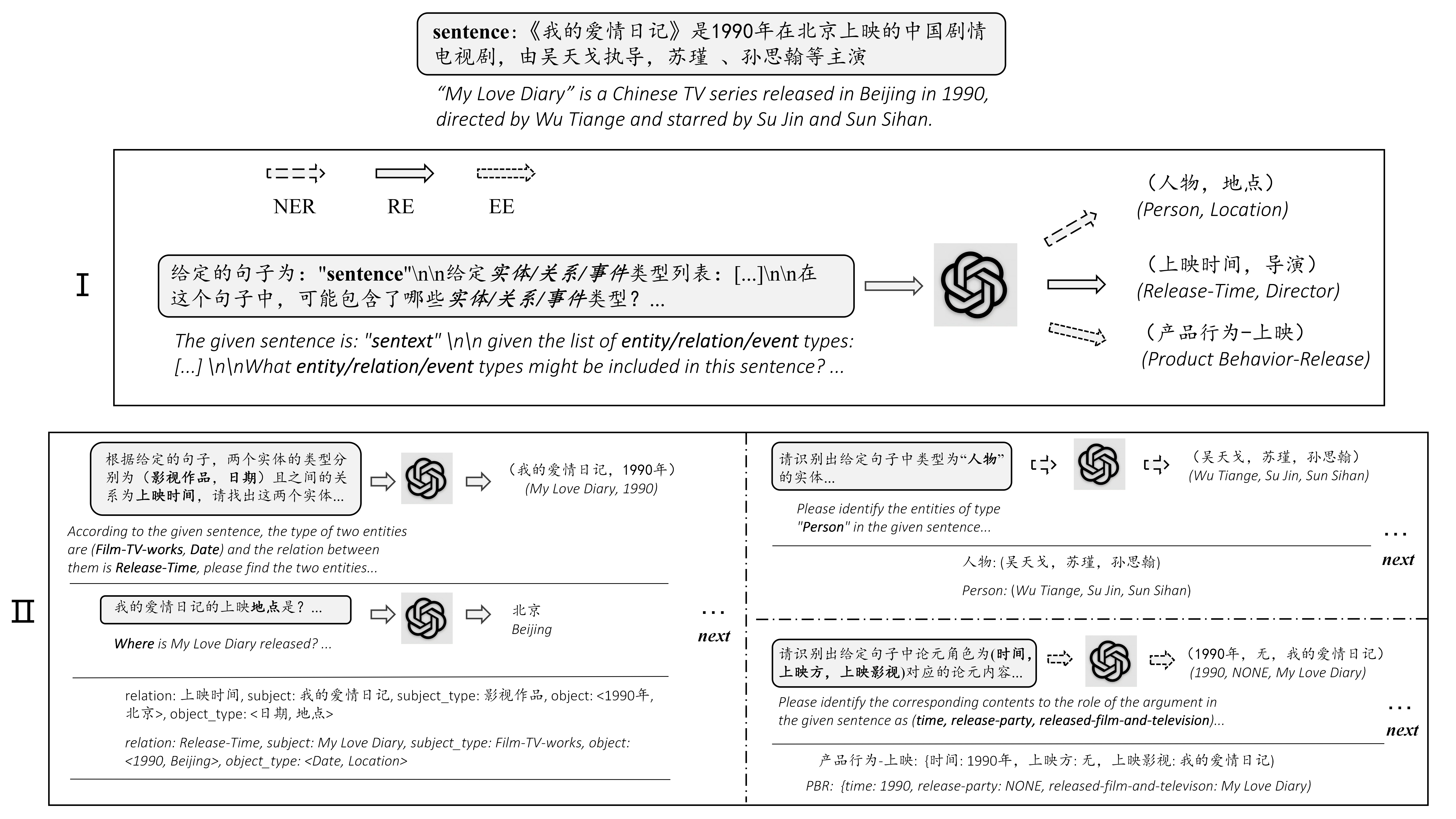
结果展示:
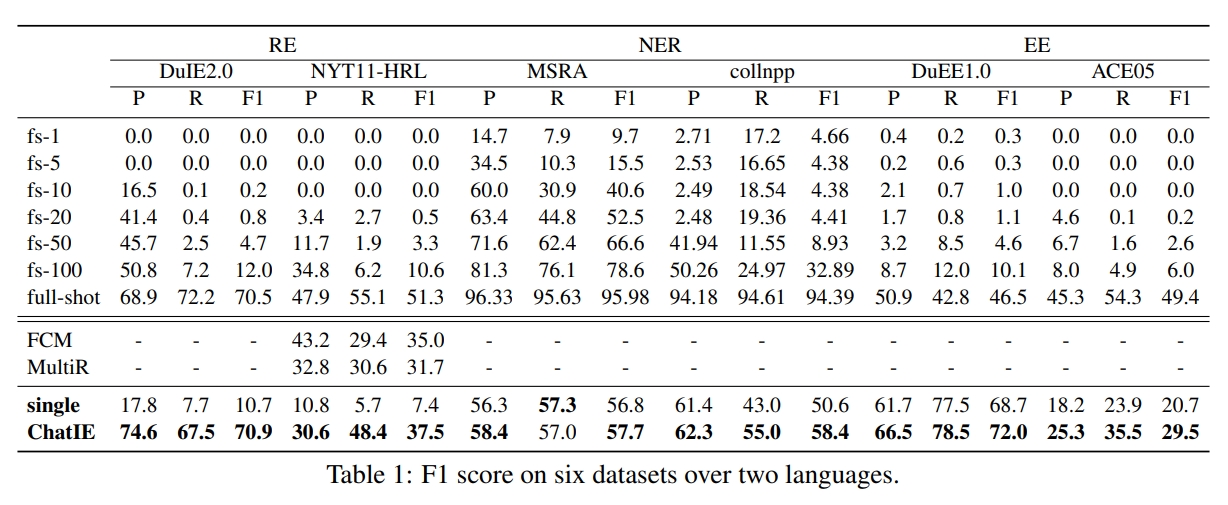
- Description
通过ChatIE 和提示功能的增强,它旨在从原始句子中自动提取结构化信息,并对输入句子进行有价值的深度分析。利用有价值的结构化信息可以帮助企业做出深刻的业务改进决策。demo.
| Task | Name | Lauguages |
|---|---|---|
| RE | entity-relation joint extraction | Chinese, English |
| NER | named entity recoginzation | Chinese, English |
| EE | event extraction | Chinese, English |
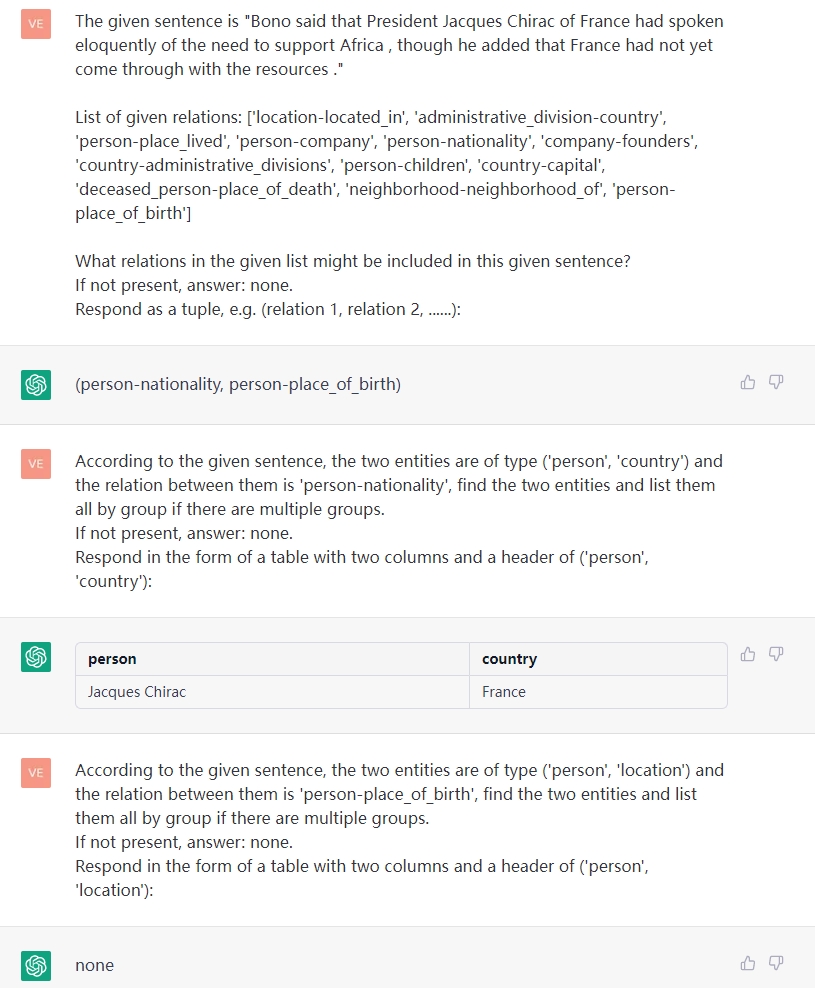
1.1 RE
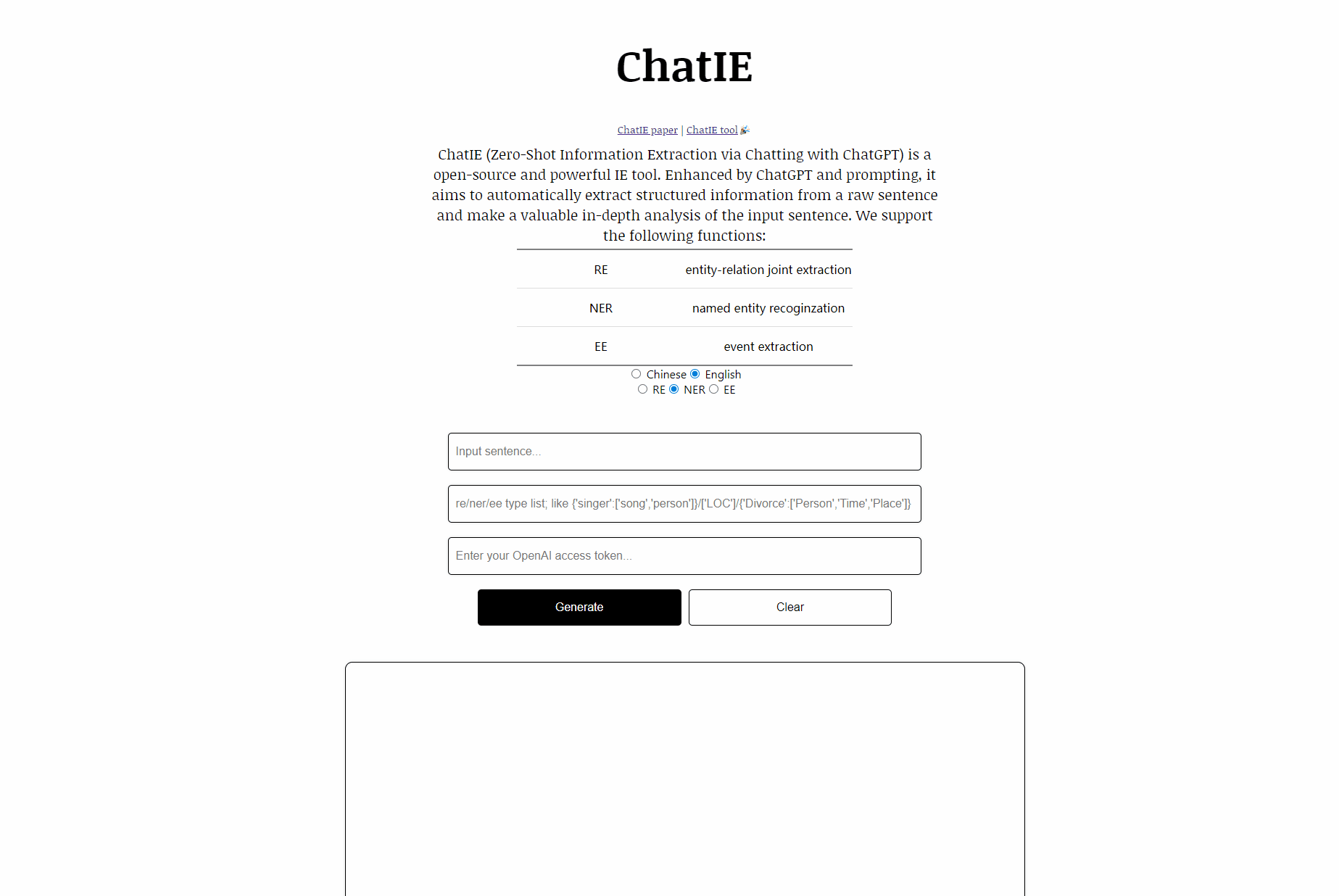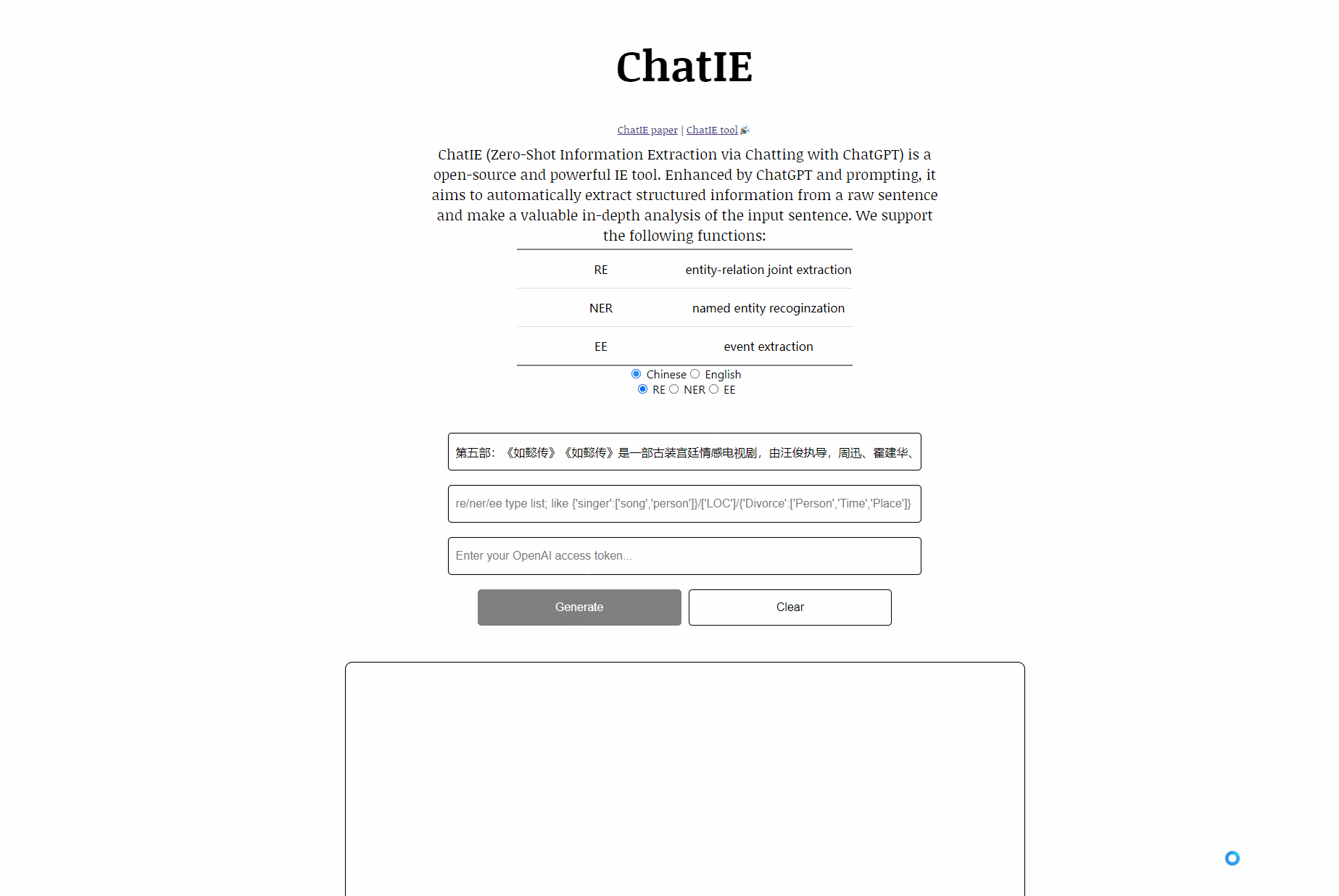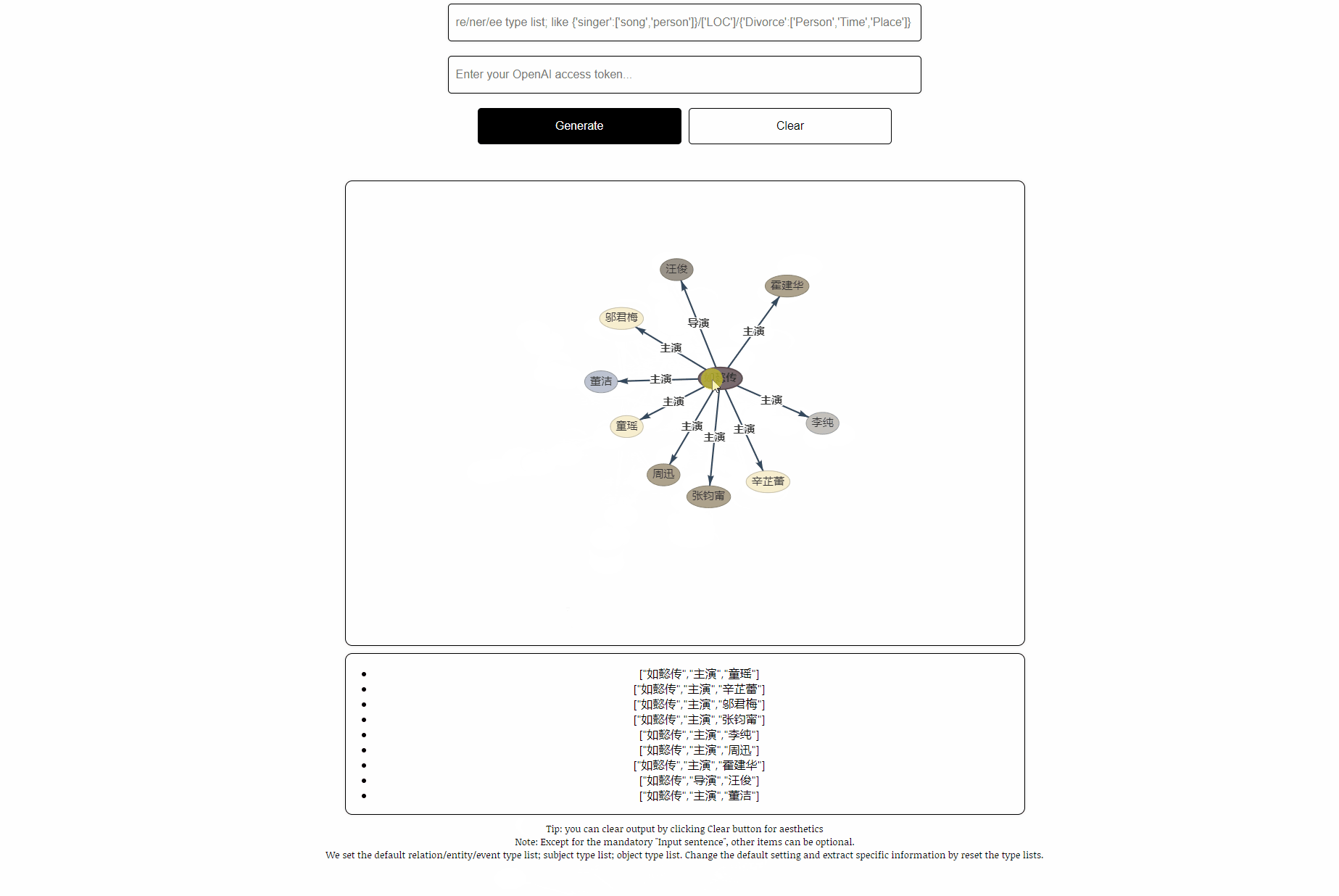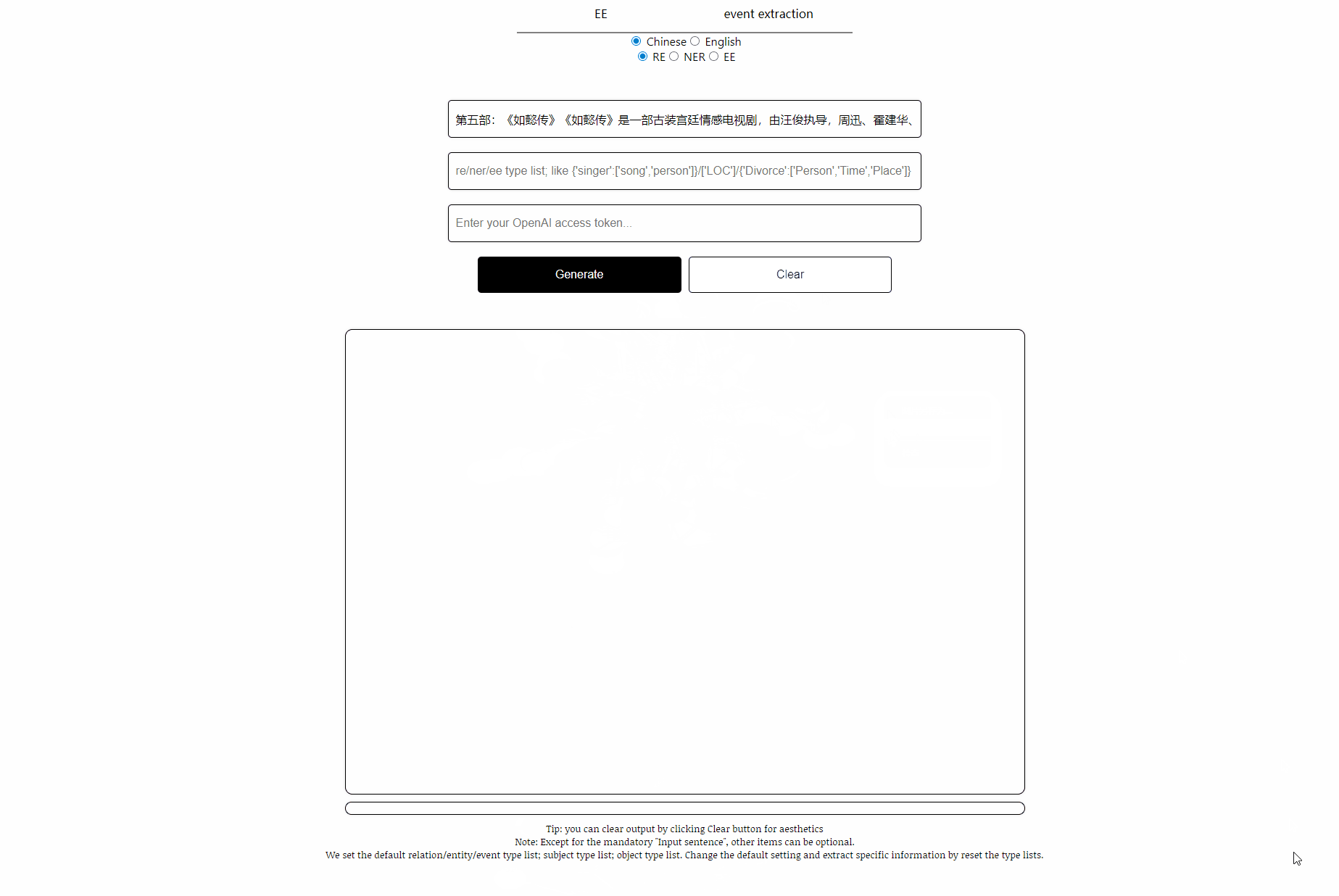
This task aims to extract triples from plain texts, such as (China, capital, Beijing) , (《如懿传》, 主演, 周迅).
- Input
- sentence: a plain text.
- relation type list (rtl)* : {‘relation type 1’: [‘subject1’, ‘object1’], ‘relation type 2’: [‘subject2’, ‘object2’], …}
PS: 表示可选,我们为它们设置默认值。但是为了更好地提取,您应该根据应用程序场景指定三个列表。
-
Examples
-
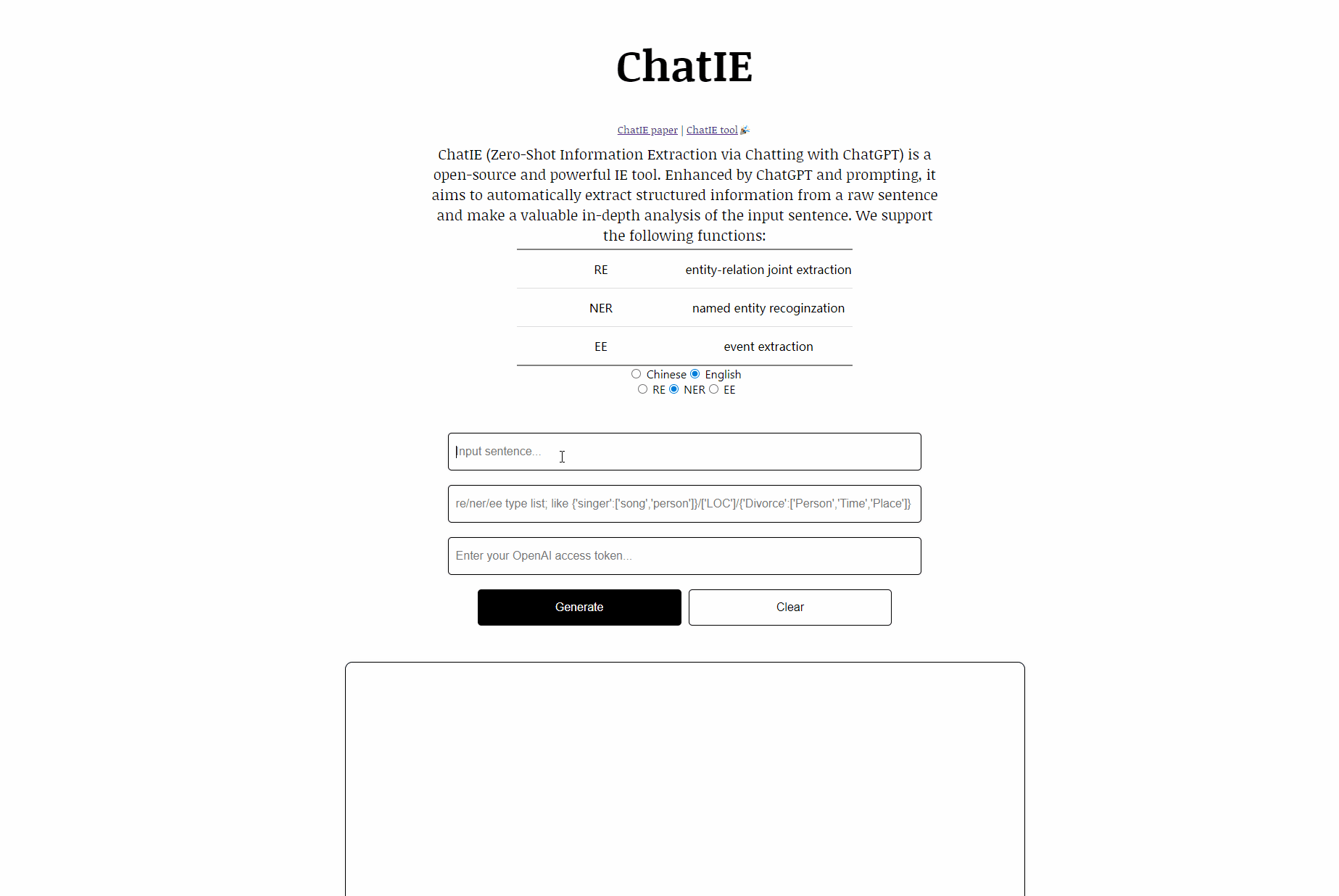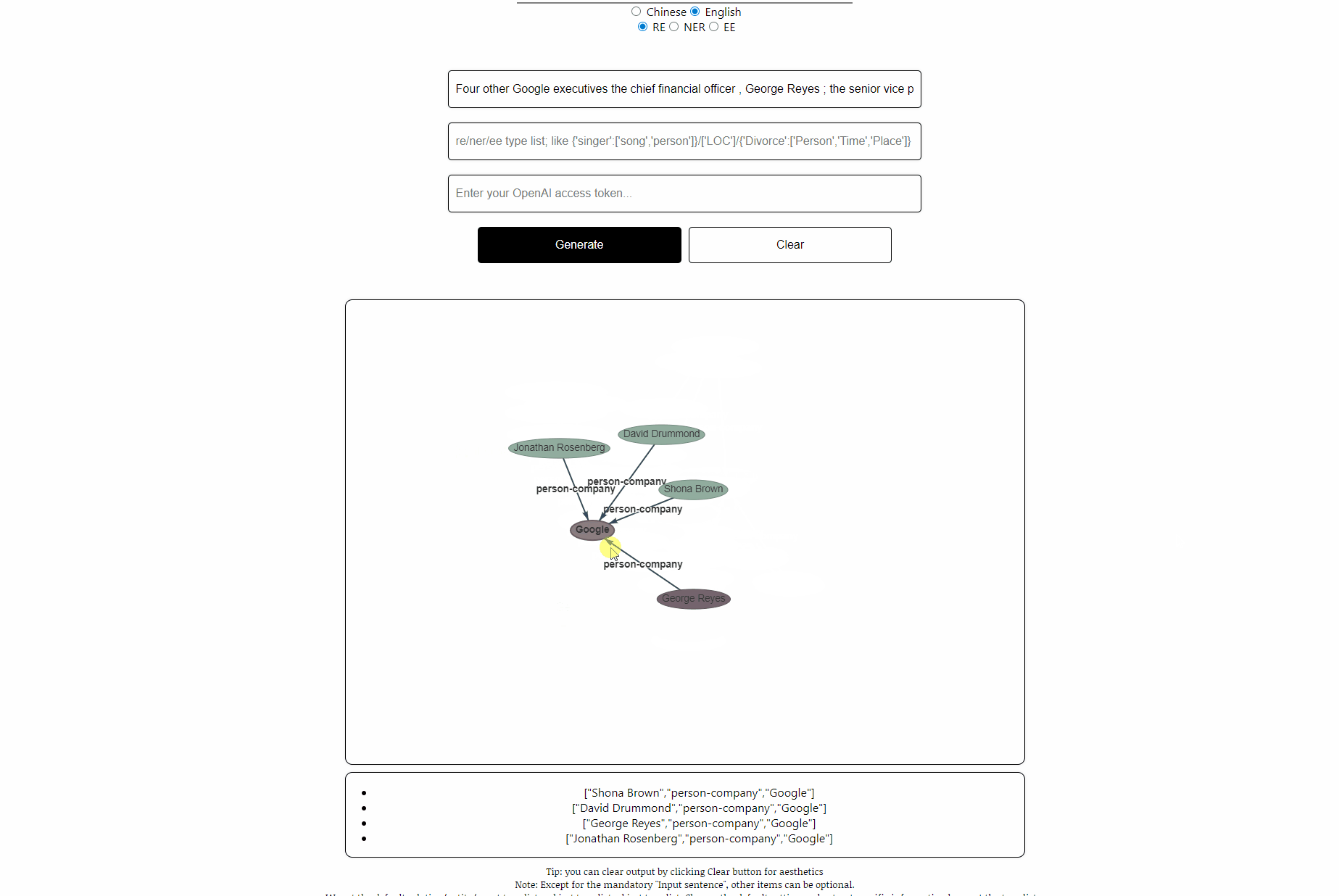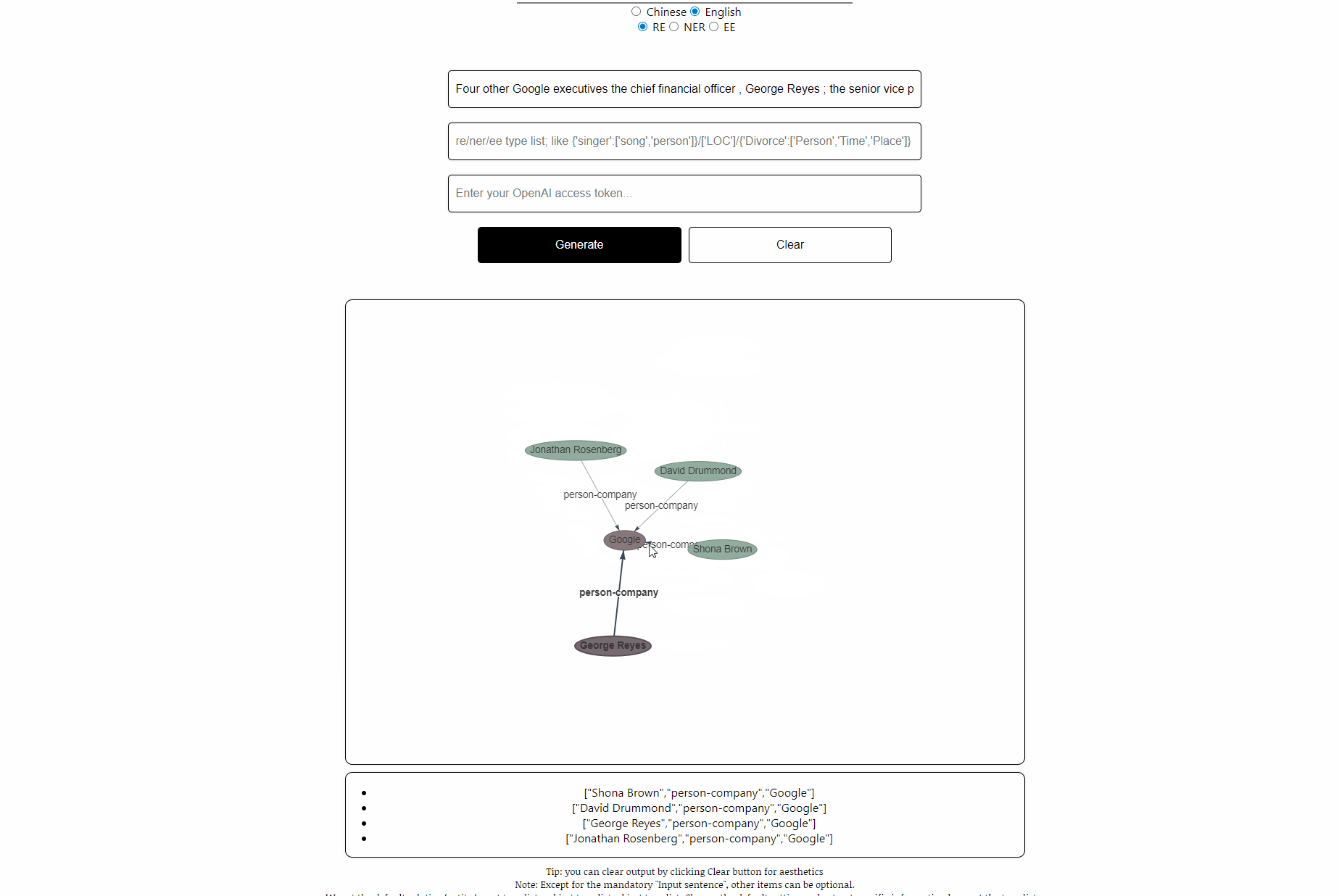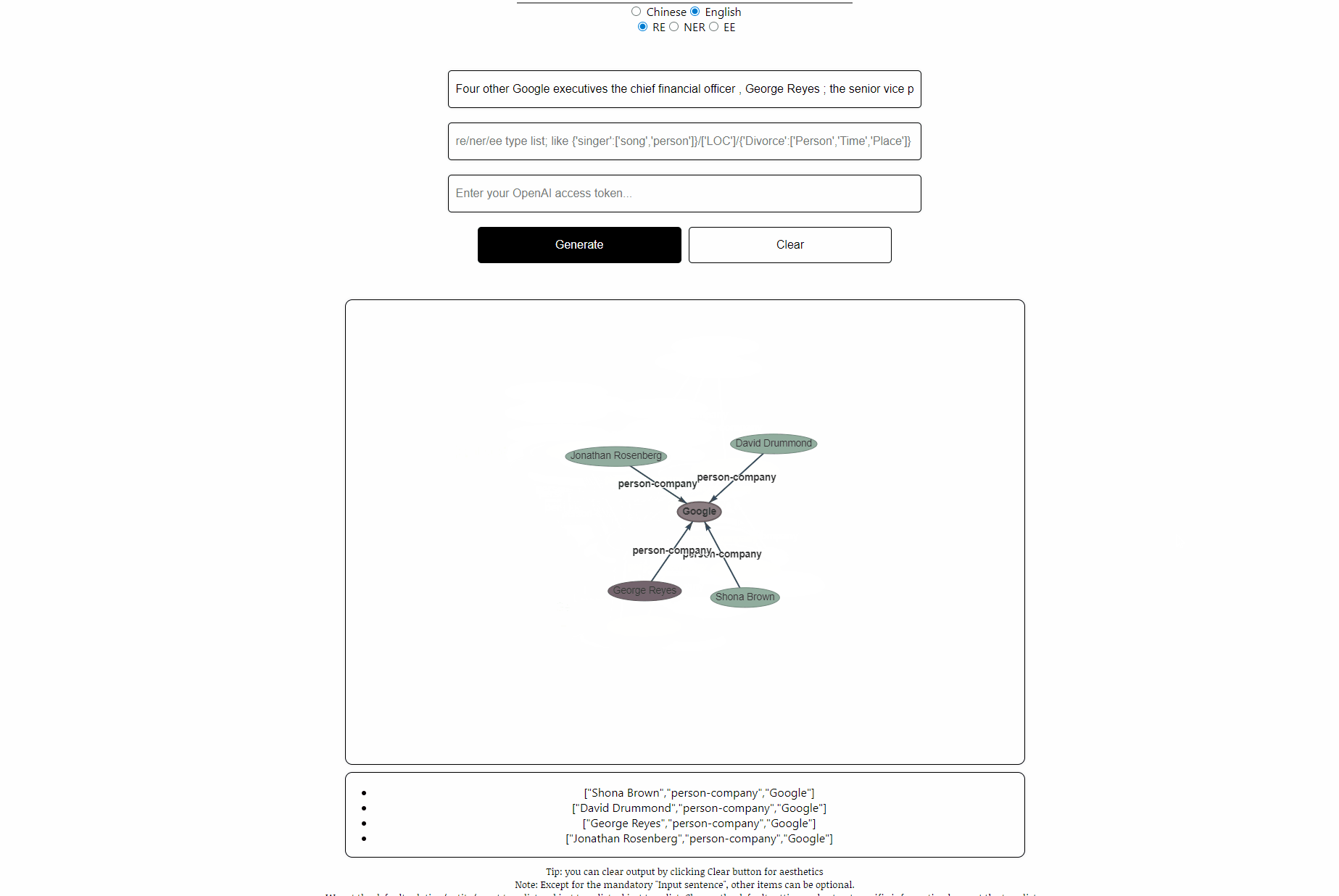
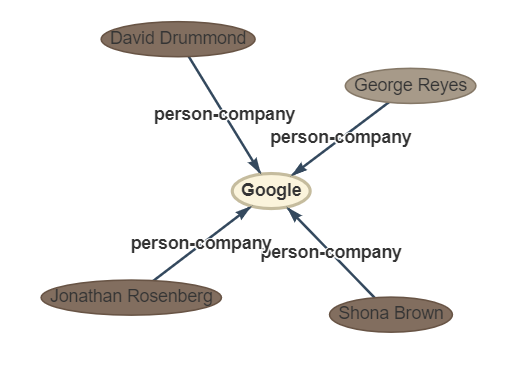
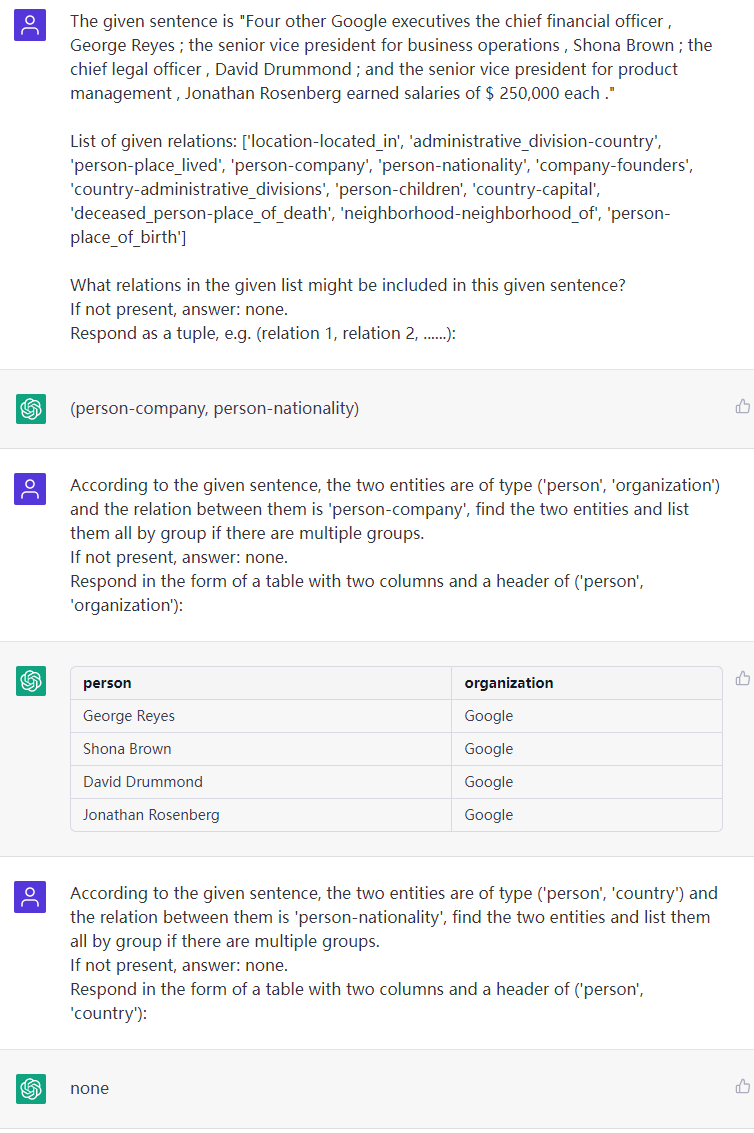
sentence: Four other Google executives the chief financial officer , George Reyes ; the senior vice president for business operations , Shona Brown ; the chief legal officer , David Drummond ; and the senior vice president for product management , Jonathan Rosenberg earned salaries of $ 250,000 each .
-
rtl: default, see file “default-types”
-
ouptut:
- sentence: 第五部:《如懿传》《如懿传》是一部古装宫廷情感电视剧,由汪俊执导,周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
- rtl: default, see file “default-types”
- ouptut:

-
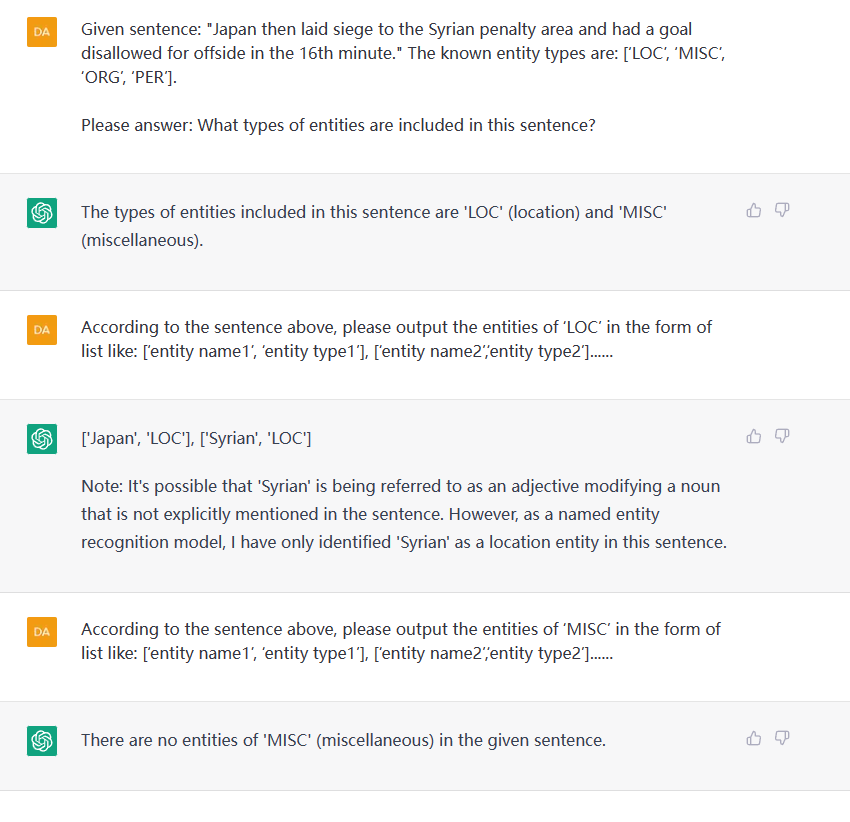
1.2 NER
该任务旨在从纯文本中提取实体, such as (LOC, Beijing) , (人物, 周恩来).
-
Input
- sentence: a plain text.
- entity type list (etl)* : [‘entity type 1’, ‘entity type 2’, …]
-
Examples
-
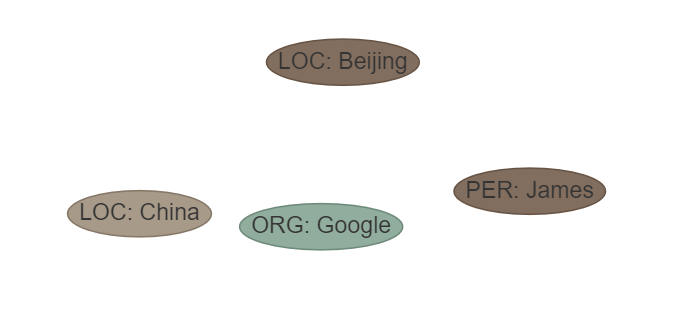
sentence: James worked for Google in Beijing, the capital of China.
-
etl: [‘LOC’, ‘MISC’, ‘ORG’, ‘PER’]
-
ouptut:
-
sentence: 中国共产党创立于中华民国大陆时期,由陈独秀和李大钊领导组织。
-
etl: [‘组织机构’, ‘地点’, ‘人物’]
-
ouptut:

-
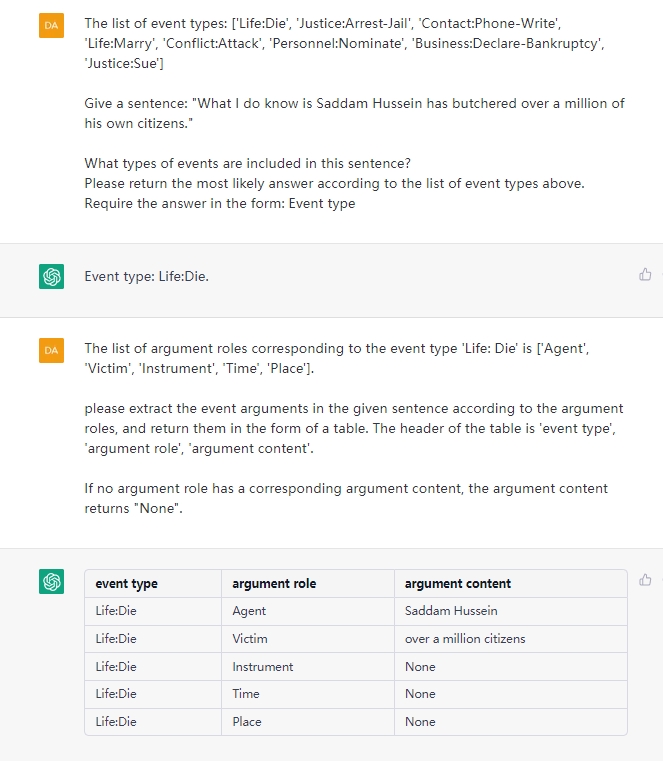
1.3 EE
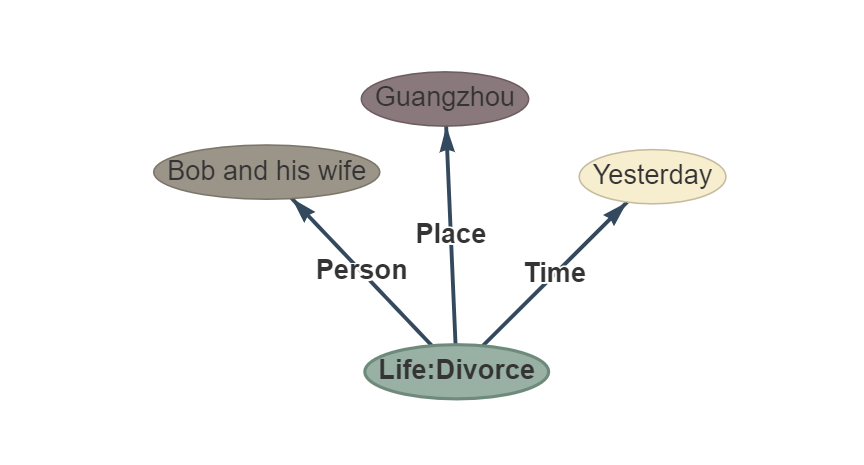
该任务旨在从纯文本中提取事件, such as {Life-Divorce: {Person: Bob, Time: today, Place: America}} , {竞赛行为-晋级: {时间: 无, 晋级方: 西北狼, 晋级赛事: 中甲榜首之争}}.
-
Input
- sentence: a plain text.
- event type list (etl)* : {‘event type 1’: [‘argument role 1’, ‘argument role 2’, …], …}
- sentence: Yesterday Bob and his wife got divorced in Guangzhou.
- etl: default, see file “default-types”
- ouptut:
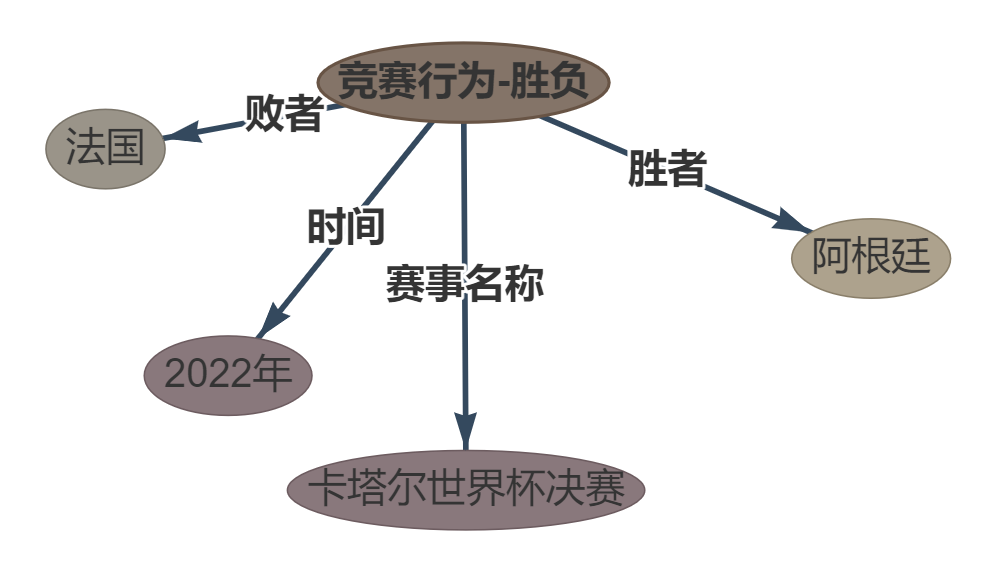
- sentence: 在2022年卡塔尔世界杯决赛中,阿根廷以点球大战险胜法国。
- etl: default, see file “default-types”
- ouptut:
2.本地使用教学
react+flask
- cd
front-endand Runnpm installto download required dependencies. - Run
npm run start. GPT4IE should open up in a new browser tab. - cd
back-endand Runpython run.py. - note: node-version v14.17.4 npm-version 9.6.0
- you may need to configure proxy on your machine.
3.Prompt提示词
3.1 EE提示词
--------------Stage I-------------------------------------------
#text denotes the input sentence
事件类型列表: ['财经/交易-出售/收购', '财经/交易-跌停', '财经/交易-加息', '财经/交易-降价', '财经/交易-降息', '财经/交易-融资', '财经/交易-上市', '财经/交易-涨价', '财经/交易-涨停', '产品行为-发布', '产品行为-获奖', '产品行为-上映', '产品行为-下架', '产品行为-召回', '交往-道歉', '交往-点赞', '交往-感谢', '交往-会见', '交往-探班', '竞赛行为-夺冠', '竞赛行为-晋级', '竞赛行为-禁赛', '竞赛行为-胜负', '竞赛行为-退赛', '竞赛行为-退役', '人生-产子/女', '人生-出轨', '人生-订婚', '人生-分手', '人生-怀孕', '人生-婚礼', '人生-结婚', '人生-离婚', '人生-庆生', '人生-求婚', '人生-失联', '人生-死亡', '司法行为-罚款', '司法行为-拘捕', '司法行为-举报', '司法行为-开庭', '司法行为-立案', '司法行为-起诉', '司法行为-入狱', '司法行为-约谈', '灾害/意外-爆炸', '灾害/意外-车祸', '灾害/意外-地震', '灾害/意外-洪灾', '灾害/意外-起火', '灾害/意外-坍/垮塌', '灾害/意外-袭击', '灾害/意外-坠机', '组织关系-裁员', '组织关系-辞/离职', '组织关系-加盟', '组织关系-解雇', '组织关系-解散', '组织关系-解约', '组织关系-停职', '组织关系-退出', '组织行为-罢工', '组织行为-闭幕', '组织行为-开幕', '组织行为-游行']。
给定一句话:'{text}'。
请问此句话对应的事件类型有哪些? 要求回答形式: '事件类型: 事件类型内容'。
--------------Stage II-------------------------------------------
#vent_type and role_list together form the schema for event extraction, where event_type comes from Stage I.
#Optional schemas are as follows: {'财经/交易-出售/收购': ['时间', '出售方', '交易物', '出售价格', '收购方'], '财经/交易-跌停': ['时间', '跌停股票'], '财经/交易-加息': ['时间', '加息幅度', '加息机构'], '财经/交易-降价': ['时间', '降价方', '降价物', '降价幅度'], '财经/交易-降息': ['时间', '降息幅度', '降息机构'], '财经/交易-融资': ['时间', '跟投方', '领投方', '融资轮次', '融资金额', '融资方'], '财经/交易-上市': ['时间', '地点', '上市企业', '融资金额'], '财经/交易-涨价': ['时间', '涨价幅度', '涨价物', '涨价方'], '财经/交易-涨停': ['时间', '涨停股票'], '产品行为-发布': ['时间', '发布产品', '发布方'], '产品行为-获奖': ['时间', '获奖人', '奖项', '颁奖机构'], '产品行为-上映': ['时间', '上映方', '上映影视'], '产品行为-下架': ['时间', '下架产品', '被下架方', '下架方'], '产品行为-召回': ['时间', '召回内容', '召回方'], '交往-道歉': ['时间', '道歉对象', '道歉者'], '交往-点赞': ['时间', '点赞方', '点赞对象'], '交往-感谢': ['时间', '致谢人', '被感谢人'], '交往-会见': ['时间', '地点', '会见主体', '会见对象'], '交往-探班': ['时间', '探班主体', '探班对象'], '竞赛行为-夺冠': ['时间', '冠军', '夺冠赛事'], '竞赛行为-晋级': ['时间', '晋级方', '晋级赛事'], '竞赛行为-禁赛': ['时间', '禁赛时长', '被禁赛人员', '禁赛机构'], '竞赛行为-胜负': ['时间', '败者', '胜者', '赛事名称'], '竞赛行为-退赛': ['时间', '退赛赛事', '退赛方'], '竞赛行为-退役': ['时间', '退役者'], '人生-产子/女': ['时间', '产子者', '出生者'], '人生-出轨': ['时间', '出轨方', '出轨对象'], '人生-订婚': ['时间', '订婚主体'], '人生-分手': ['时间', '分手双方'], '人生-怀孕': ['时间', '怀孕者'], '人生-婚礼': ['时间', '地点', '参礼人员', '结婚双方'], '人生-结婚': ['时间', '结婚双方'], '人生-离婚': ['时间', '离婚双方'], '人生-庆生': ['时间', '生日方', '生日方年龄', '庆祝方'], '人生-求婚': ['时间', '求婚者', '求婚对象'], '人生-失联': ['时间', '地点', '失联者'], '人生-死亡': ['时间', '地点', '死者年龄', '死者'], '司法行为-罚款': ['时间', '罚款对象', '执法机构', '罚款金额'], '司法行为-拘捕': ['时间', '拘捕者', '被拘捕者'], '司法行为-举报': ['时间', '举报发起方', '举报对象'], '司法行为-开庭': ['时间', '开庭法院', '开庭案件'], '司法行为-立案': ['时间', '立案机构', '立案对象'], '司法行为-起诉': ['时间', '被告', '原告'], '司法行为-入狱': ['时间', '入狱者', '刑期'], '司法行为-约谈': ['时间', '约谈对象', '约谈发起方'], '灾害/意外-爆炸': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-车祸': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-地震': ['时间', '死亡人数', '震级', '震源深度', '震中', '受伤人数'], '灾害/意外-洪灾': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-起火': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-坍/垮塌': ['时间', '坍塌主体', '死亡人数', '受伤人数'], '灾害/意外-袭击': ['时间', '地点', '袭击对象', '死亡人数', '袭击者', '受伤人数'], '灾害/意外-坠机': ['时间', '地点', '死亡人数', '受伤人数'], '组织关系-裁员': ['时间', '裁员方', '裁员人数'], '组织关系-辞/离职': ['时间', '离职者', '原所属组织'], '组织关系-加盟': ['时间', '加盟者', '所加盟组织'], '组织关系-解雇': ['时间', '解雇方', '被解雇人员'], '组织关系-解散': ['时间', '解散方'], '组织关系-解约': ['时间', '被解约方', '解约方'], '组织关系-停职': ['时间', '所属组织', '停职人员'], '组织关系-退出': ['时间', '退出方', '原所属组织'], '组织行为-罢工': ['时间', '所属组织', '罢工人数', '罢工人员'], '组织行为-闭幕': ['时间', '地点', '活动名称'], '组织行为-开幕': ['时间', '地点', '活动名称'], '组织行为-游行': ['时间', '地点', '游行组织', '游行人数']}
事件类型: '{event_type}' 对应的论元角色列表为: {role_list}。
请根据论元角色列表在上述句子中提取出事件论元, 并以表格形式给出, 表头分别为 '事件类型', '论元角色', '论元内容'。
如果某个论元角色没有相应的论元内容,论元内容回答: 无。
#anilla Prompt (Single-turn)
#text denotes the input sentence
#For event_type_{} and role_list_{}, please refer to ChatIE (Two-stage) above
事件类型: '{event_type_1}' 对应的论元角色列表为: {role_list_1}, 事件类型: '{event_type_2}' 对应的论元角色列表为: {role_list_2}, ...
给定一句话:'{text}'。
请提取出上述句子的事件论元, 并以表格形式给出, 表头分别为 '事件类型', '论元角色', '论元内容'。
如果某个论元角色没有相应的论元内容,论元内容回答: 无。
3.2 RE
部分展示
假设你是一个实体关系五元组抽取模型。我会给你头实体类型列表subject_types,尾实体类型列表object_types,关系列表relations,再给你一个句子,请你根据这三个列表抽出句子中的subject和object,并组成五元组,且形式为(subject, subject_type, relation, object, object_type)。
给定的句子为:"{}"
relations:['所属专辑', '成立日期', '海拔', '官方语言', '占地面积', '父亲', '歌手', '制片人', '导演', '首都', '主演', '董事长', '祖籍', '妻子', '母亲', '气候', '面积', '主角', '自', '校长', '丈夫', '主持人', '主题曲', '修业年限', '作曲', '号', '上映时间', '票房', '饰演', '配音', '获奖']
subject_types:['国家', '行政区', '文学作品', '人物', '影视作品', '学校', '图书作品', '地点', '历史人物', '景点', '歌曲', '学科专业', '企业', '电视综艺', '机构', '企业/品牌', ' 娱乐人物']
object_types:['国家', '人物', 'Text', 'Date', '地点', '气候', '城市', '歌曲', '企业', 'Number', '音乐专辑', '学校', '作品', '语言']
3.3 NER
--------------Vanilla Prompt(单轮)-------------------------------------
假设你是一个命名实体识别模型,现在我会给你一个句子,请根据我的要求识别出每个句子中的实体,实体类型只要三种:组织机构、地点、人物。请用列表的形式展示,其中列表的第一个元素为实体名称,第二个元素为实体类型。如果该句子中不含有指定的实体类型,你可以输出:[]。输出格式形为:["实体名称1", "实体类型1"], ["实体名称2", "实体类型2"], …。除了这个列表以外请不要输出别的多余的话。这个句子是:""
--------------Stage I-------------------------------------------
--------------Stage II-------------------------------------------
假设你是一个命名实体识别模型,现在我会给你一个句子,请根据我的要求识别出每个句子中的实体,并用列表的形式展示。其中列表的第一个元素为实体名称,第二个元素为实体类型。如果该句子中不含有指定的实体类型,你可以输出:[]。输出格式形为:["实体名称1", "实体类型1"], ["实体名称2", "实体类型2"], …。除了这个列表以外请不要输出别的多余的话。请识别出以下句子中类型为“组织机构”的实体:""
假设你是一个命名实体识别模型,现在我会给你一个句子,请根据我的要求识别出每个句子中的实体,并用列表的形式展示。其中列表的第一个元素为实体名称,第二个元素为实体类型。如果该句子中不含有指定的实体类型,你可以输出:[]。输出格式形为:["实体名称1", "实体类型1"], ["实体名称2", "实体类型2"], …。除了这个列表以外请不要输出别的多余的话。遇到国家的名字时,可以将其识别成地点类型实体。请识别出以下句子中类型为“地点”的实体:""
假设你是一个命名实体识别模型,现在我会给你一个句子,请根据我的要求识别出每个句子中的实体,并用列表的形式展示。其中列表的第一个元素为实体名称,第二个元素为实体类型。如果该句子中不含有指定的实体类型,你可以输出:[]。输出格式形为:["实体名称1", "实体类型1"], ["实体名称2", "实体类型2"], …。除了这个列表以外请不要输出别的多余的话。请识别出以下句子中类型为“人物”的实体:""
4.更多案例展示
4.1 RE
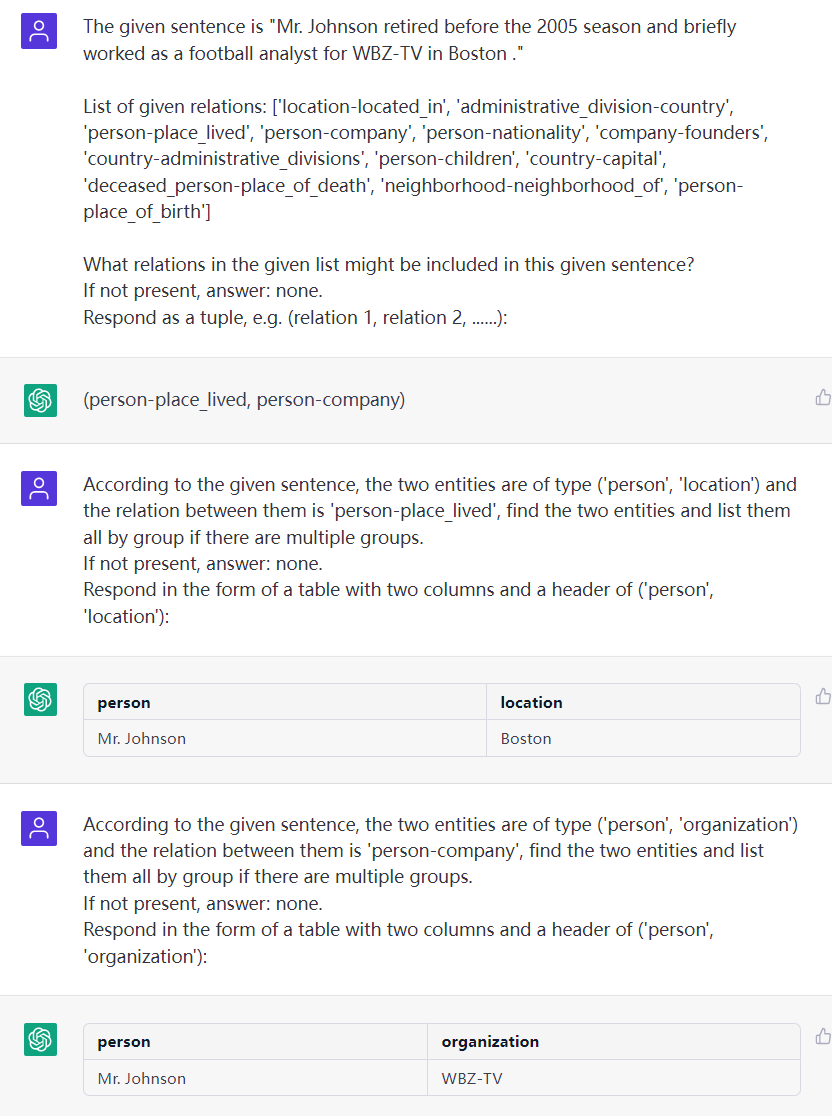
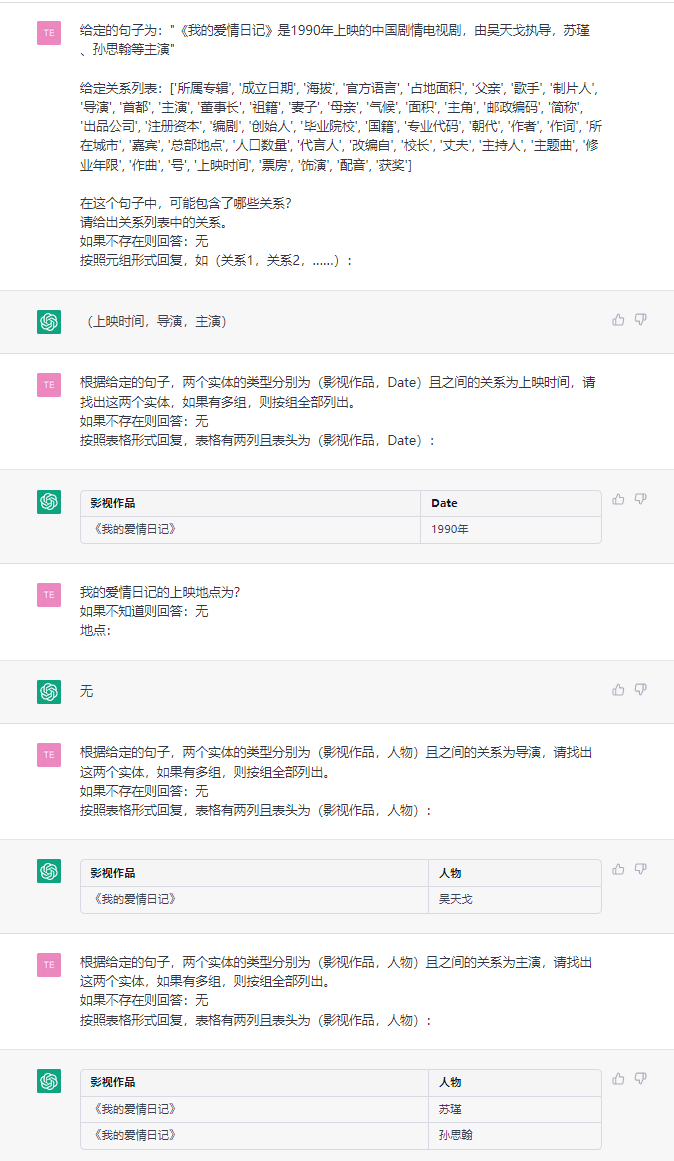
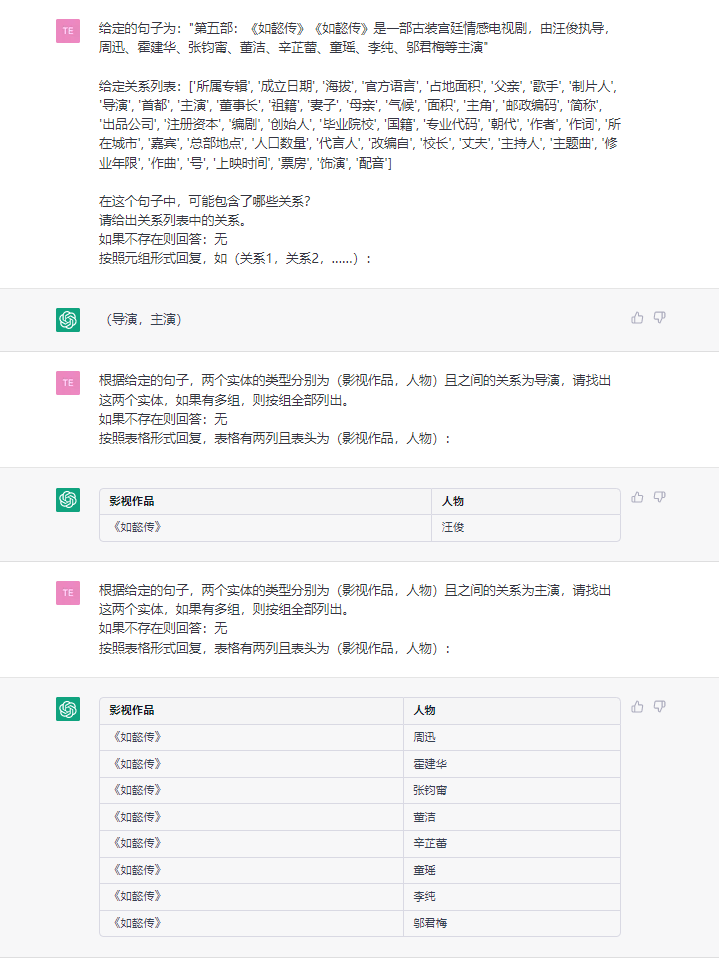
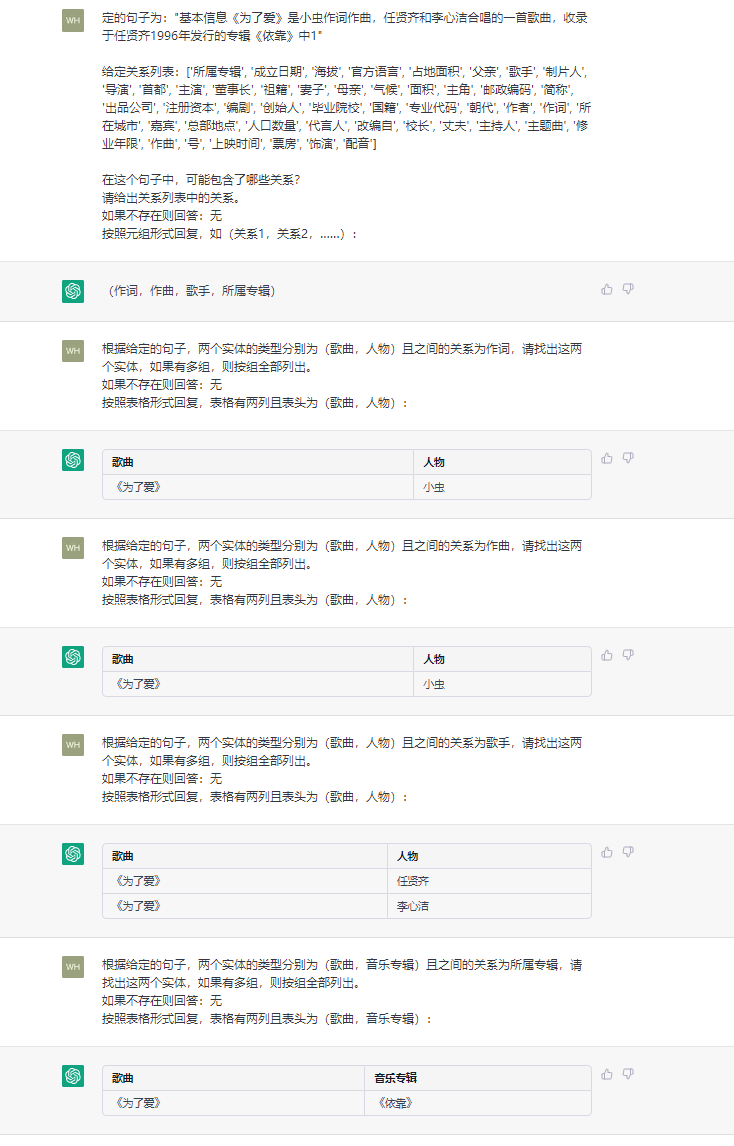
4.2 NER


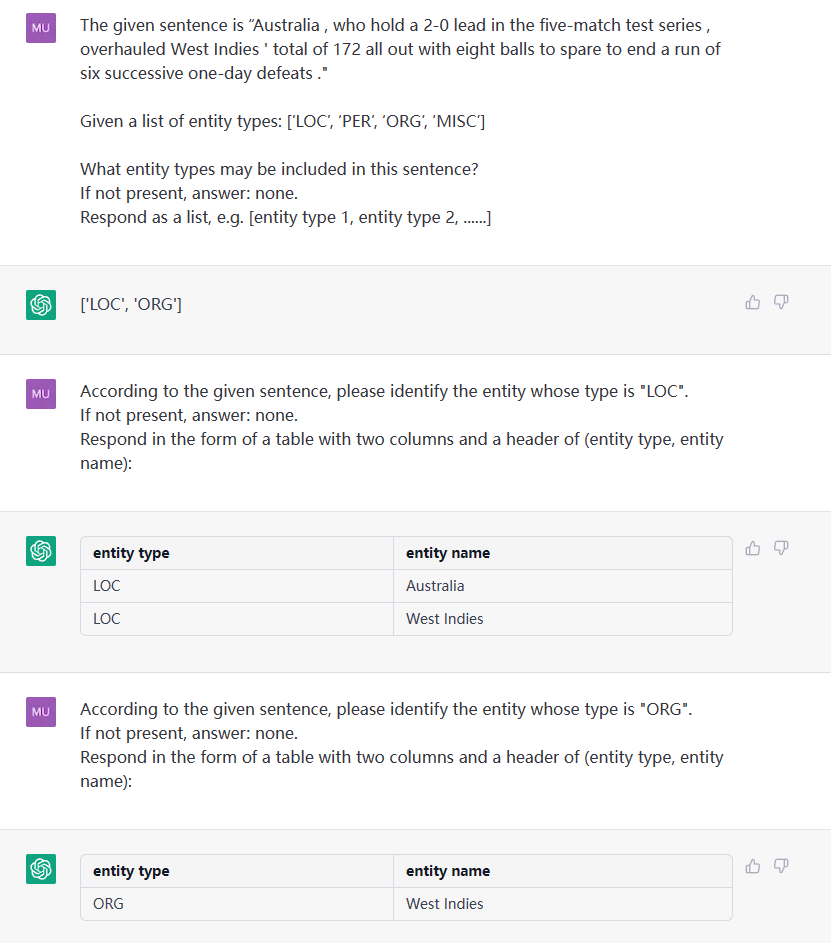

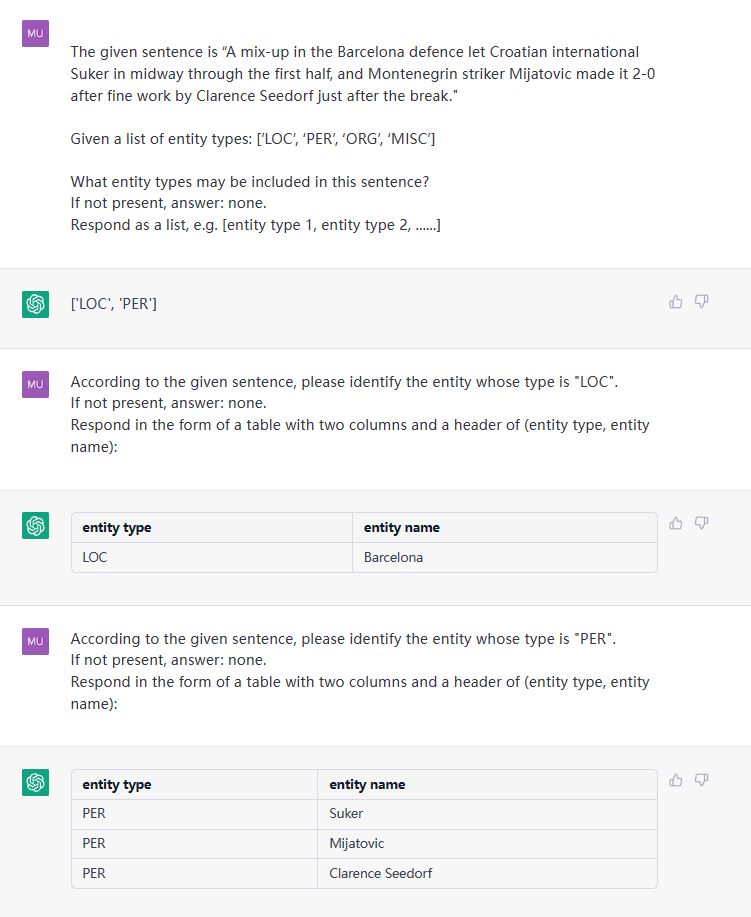
4.3 EE
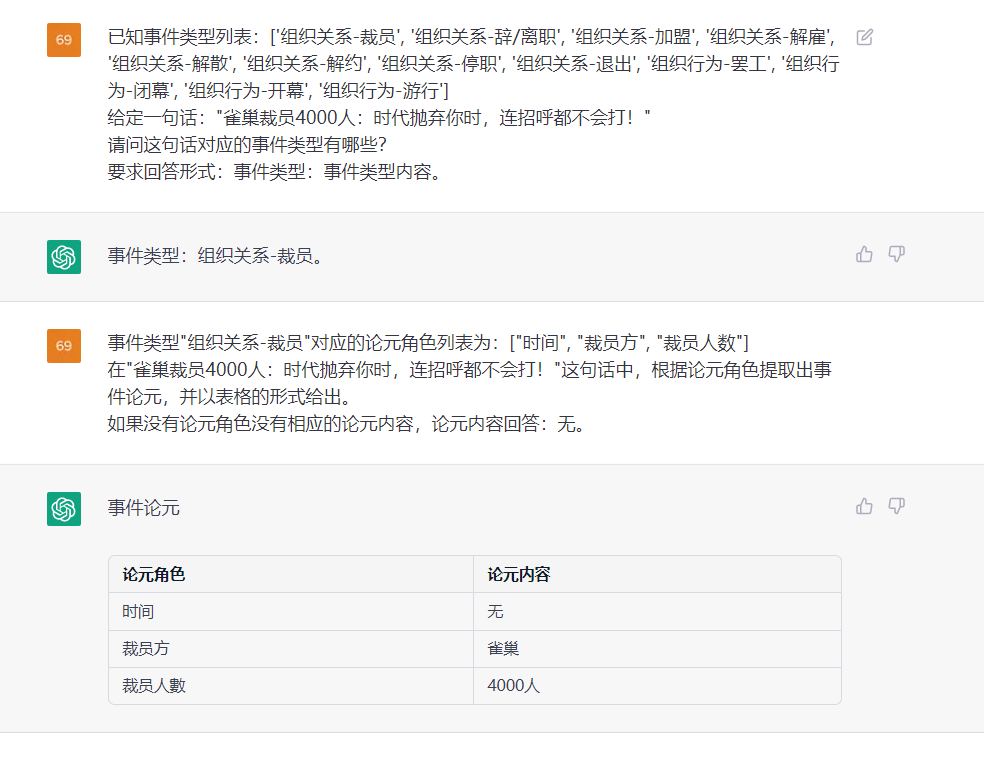

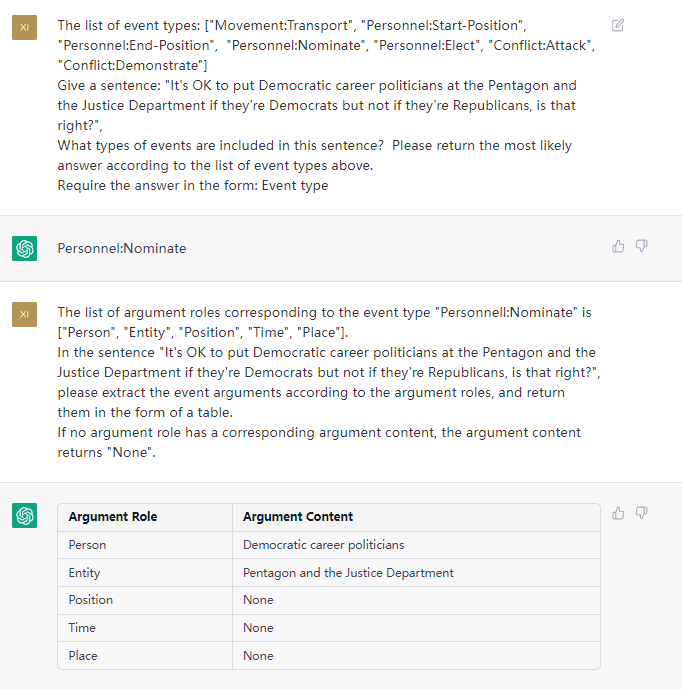
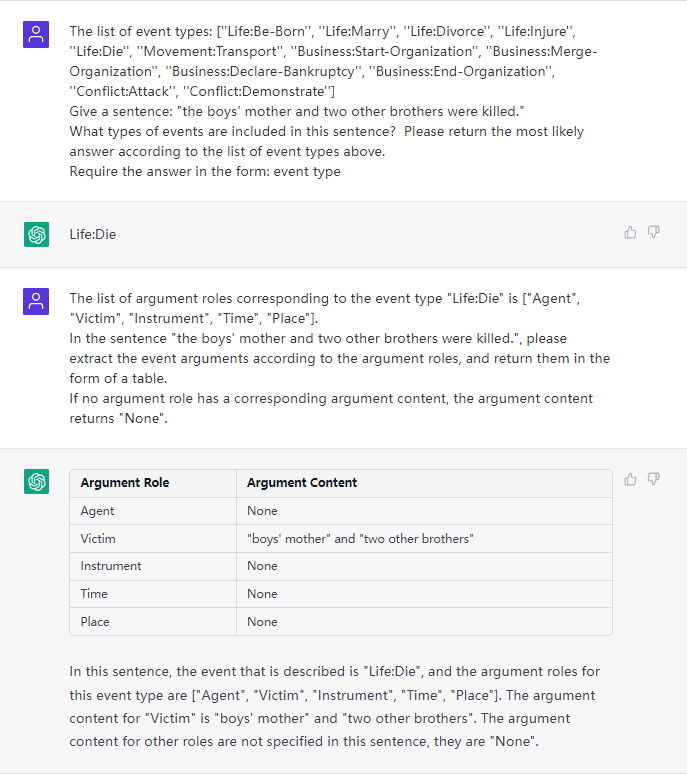
4.4 其他
项目码源以及资料见文章顶部or文末
https://download.csdn.net/download/sinat_39620217/88001594