又搞了一段时间。还是感觉LongNet那种空洞注意力做编码器有搞头。
RetNet等AFT方法,直接生成太长的句子感觉有点难度,不过可以一句句生成,每次生成短句,这样感觉比较合适。
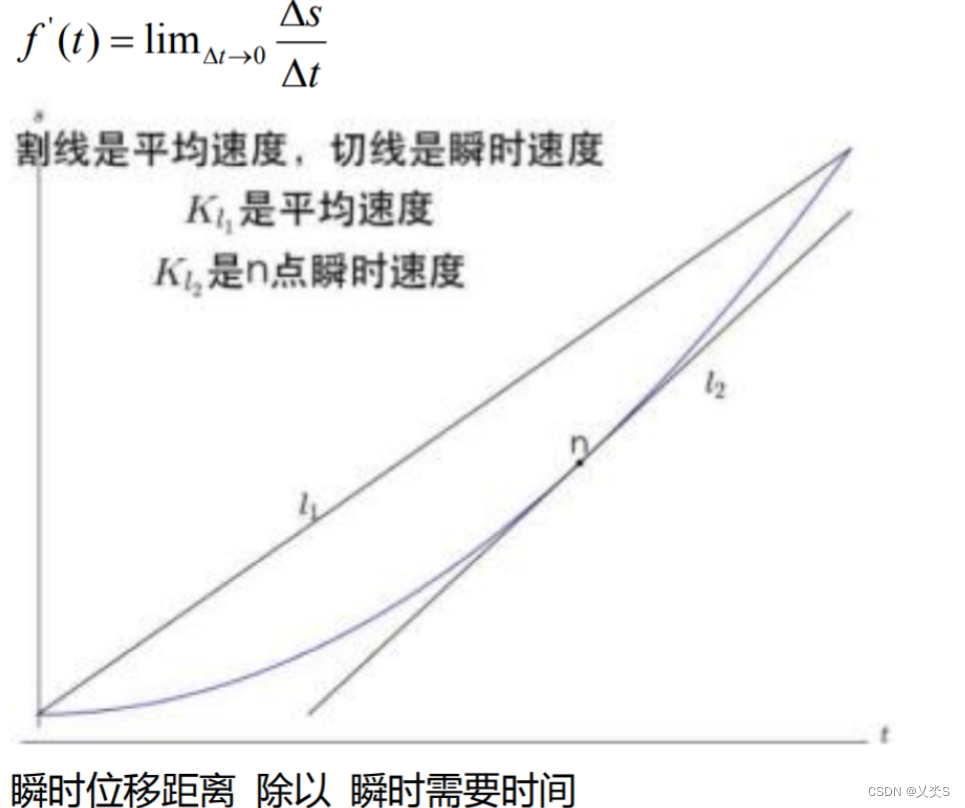
启发
受 MemroyTransformer 和 GLM 启发
想了一个类似T5的设计,包含编码器和解码器
只使用拼接和 CausalSelfAttention ,不使用 CrossAttention
可以等价省去 T5的解码器 里面的交叉注意力层
设计思路
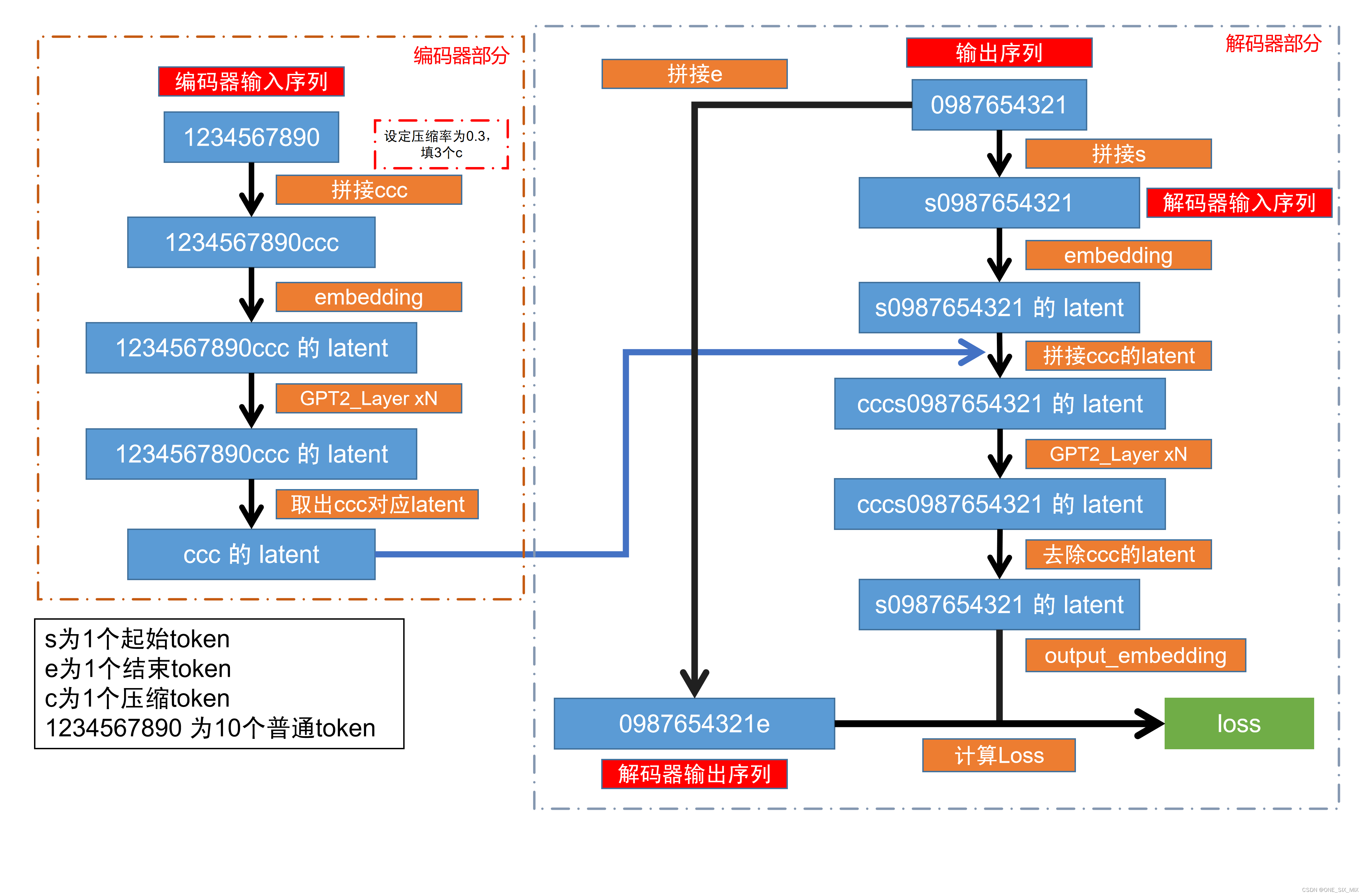
流程文字
设定x输入为 1234567890
设定y目标为 0987654321
每个数字都是一个 token
预先设定压缩比例为 0.3,即输入长度为10的token,后面会附加上3个压缩token
------------------
编码器部分
输入序列
1234567890
在后面填入3个c压缩token,
得到1234567890ccc
经过 GPT2_Layer xN,使用ROPE绝对位置编码
取出后面3个c压缩的潜变量,作为编码器输出
------------------
解码器部分
设定序列
0987654321
在前面填入s开始token,作为解码器输入序列
s0987654321
在后面填入e结束token,作为解码器输出序列
0987654321e
获得 s0987654321 的 emb,然后在前面拼接上编码器的输出 c压缩潜变量
得到 cccs0987654321 的潜变量
经过 GPT2_Layer xN,使用ROPE绝对位置编码
移除前面的c压缩潜变量
得到 s0987654321 的潜变量
经过 output_embedding,获得解码器输出概率
将 解码器输出概率 与 解码器输出序列 0987654321e 计算Loss
对 Loss 计算 Backward
流程图
已进行试验
也做了一些简单的实验,在不成方圆的 中日互译任务上。
与PF6(GPT_style)24层模型做对照。
PF6
ck44,1024维度,24层Decoder,验证准确率是 0.8251
SqueezeLM
ck47,1024维度,16层Encoder,8层Decoder,压缩率1/4,验证准确率是 0.8095
ck48,1024维度,12层Encoder,12层Decoder,压缩率1/5,验证准确率是 0.8050
ck49,1024维度,6层Encoder,6层Decoder,压缩率1/5,验证准确率是 0.8006
ck50,1024维度,6层Encoder,6层Decoder,压缩率1/10,验证准确率是 0.7896
其中,这几个权重拥有几乎相同的参数量ck44,ck47,ck48
参数量为260M
不过确实,相同参数量下,验证分数相比GPT类的,确实差了一点点
如果是训练过程中,使用随机压缩率,在大的区间,例如0.1-0.9之间随机变化,收敛会非常慢
如果让使用小区间,0.3-0.5,收敛速度也有点慢。
如果使用固定压缩率,例如0.3,收敛速度是最快的
扩展想法
- Encoder 上使用CausalAttention,每一个C压缩token可能包含了层级的关系,可能像矩阵的奇异值分解的那样。保留的奇异值越多,就越能还原原始矩阵
- C压缩token里面,可能储存了一部分答案,而不只是输入序列的压缩向量。如果把Encoder层设置为16,Decoder层数设置为8,可能可以让Decoder更多地负责生成句子能力,Encoder更加地负责生成目标句子的意义。
- 可以像DeepFake双头解码器那样。实现一对多翻译器,一个Encoder接着多个Decoder。实现另外一种多语言翻译模式,可以有效隔离不同语言,避免混淆。
- 解码器修改,或许可以换成RWKV或RetNet之类的AFT模型,从而实现O(1)自循环预测。
- 解码器目的修改,不要求解码器生成长篇大论,只需要生成一句话,然后再把生成这句话附加到编码器输入,再生成压缩潜变量,再由解码器生成下一句话。
变体
更之前,有设计过一个变体,是编码器和解码器并行的,每个编码器层的输出都会收集起来。
然后在解码器部分,每层解码器输入都会拼接上 来自编码器的输出。每经过一个解码器层后,就把之前的拼接上的编码器输入的给切掉,再拼接下一个编码器层的输出。数据处理非常麻烦。
不过幸好,初步训练后,发现这个很麻烦的操作,并不能增加分数,训练速度和分数都不够直接把编码器输出拼接到第一层解码器输入那样高。
所以该变体被存档了。




![[JavaWeb]SQL介绍-DDL-DML](https://img-blog.csdnimg.cn/05033827a41648daa359f62a65d01cfc.png#pic_center)

![[nlp] TF-IDF算法介绍](https://img-blog.csdnimg.cn/4e186ba8072d46ecac7be6eda9f882ba.png)