🚀write in front🚀
📜所属专栏:初阶数据结构
🛰️博客主页:睿睿的博客主页
🛰️代码仓库:🎉VS2022_C语言仓库
🎡您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!

文章目录
- 前言
- 一.vector和string的区别:
- 二.vector的使用:
- 三.vector的模拟实现:
- 1.vector的成员变量:
- 2.vector的迭代器问题(重点):
- insert()函数:
- erase()函数:
- insert的迭代器失效:
- erase的迭代器失效:
- string的迭代器失效:
- 3.vector深浅拷贝问题:
- 4.vector构造函数问题:
- 总结
- 总结
前言
在学习完string之后,我们来开始vector的学习,其实vector的各个函数和string是非常类似的,所以我们就着重讲讲vector的易错点就行了。
一.vector和string的区别:
vector是可变大小数组的序列容器,可以存储任意相同类型的元素。而string是专门用来存储字符串的。当然,我们不能用vector<char>来代替string,因为string存在着’\0’的问题,并且string的有些函数是专门针对字符串的,而vector没有。
二.vector的使用:
在这里参考文档就可以了:vector使用介绍
当然对于二维数组,我们就不得不说vector的优势了。在学习c语言时,对于二维数组,我们每一行每一列的大小的空间都是定死的,而如果我们使用vector<vector<int>>就可以灵活使用。
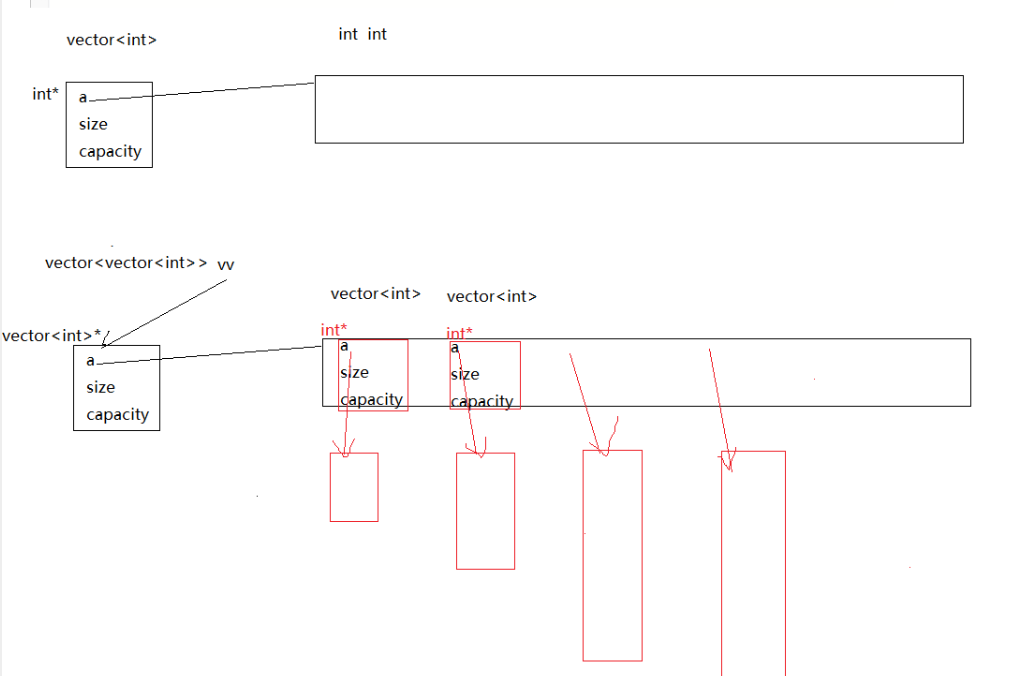
在看完vector的使用文档我们就可以明白里面的原理:
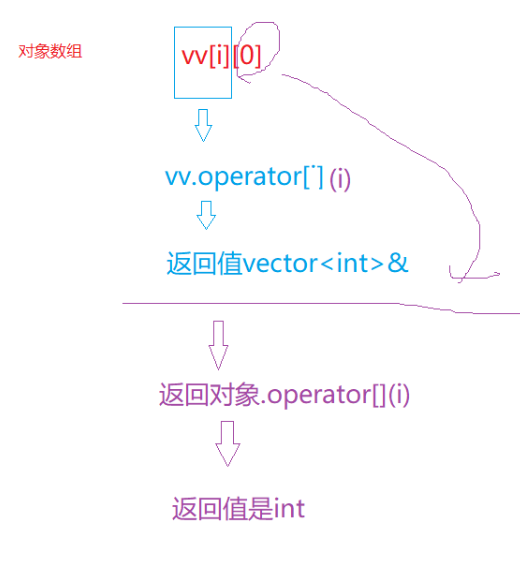
三.vector的模拟实现:
在这里我们就就讲讲和string不同的地方即可,其他地方和string都是类似的。
1.vector的成员变量:
通过查看strl的vector(stl的原代码实现)实现我们可以看出,vector的成员变量和string的是不太一样的:

由此可见,vector的成员变量是通过三个指针来实现的。他们分别指向数组的开头,数组的有效尾部和数组的容量尾部。
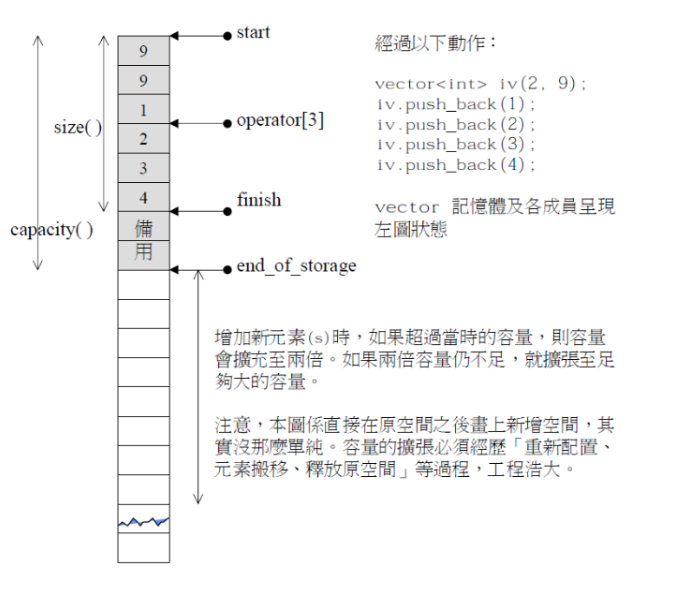
2.vector的迭代器问题(重点):
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,然而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
insert()函数:
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
if (_finish == _endofstorage)
{
size_t len = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
// 解决pos迭代器失效问题
pos = _start + len;
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
erase()函数:
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;
}
insert的迭代器失效:
会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。
如果我们使用以下代码就会发现出错:
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(5);
v1.push_back(5);
v1.push_back(5);
v1.push_back(5);
auto pos=v1.begin();
v1.insert(pos);
v1.insert(pos+1);
这里迭代器失效的原因想必大家都知道,在扩容之后,成员变量的三个指针指向的空间发生了改变,此时我们pos就变成了一个野指针。所以此时我们的迭代器失效了。
erase的迭代器失效:
erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理论上讲迭代器不应该会失效,但是:如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。
vs编译器为了防止这些现象的发生,就对迭代器进行了极端处理:在insert或erase使用了迭代器对象之后,不能在访问这个迭代器,vs认为他是失效,访问是未定义。
然而,在Linux的g++下面不存在这样的强制检查,有时候使用也是对的,但是这样的话就不符合代码的可移植性了。
这就是为什么我们在模拟实现的时候会返回一个迭代器,就是为了给这个迭代器重新赋值:
```cpp
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(5);
v1.push_back(5);
v1.push_back(5);
v1.push_back(5);
auto pos=v1.begin();
pos=v1.insert(pos);
pos=v1.insert(pos+1);
这样就不会出错了。
string的迭代器失效:
与vector类似,string在插入+扩容操作+erase之后,迭代器也会失效
总结一下,为了防止迭代器失效,在使用迭代器前,对迭代器重新赋值即可.
3.vector深浅拷贝问题:
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
vector<string> v1;
v1.push_back("edd");
v1.push_back("werewedf");
v1.push_back("sddeedf");
v1.push_back("sdwdf");
v1.push_back("Sdfef");
我们先来复习一下memcpy的性质:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
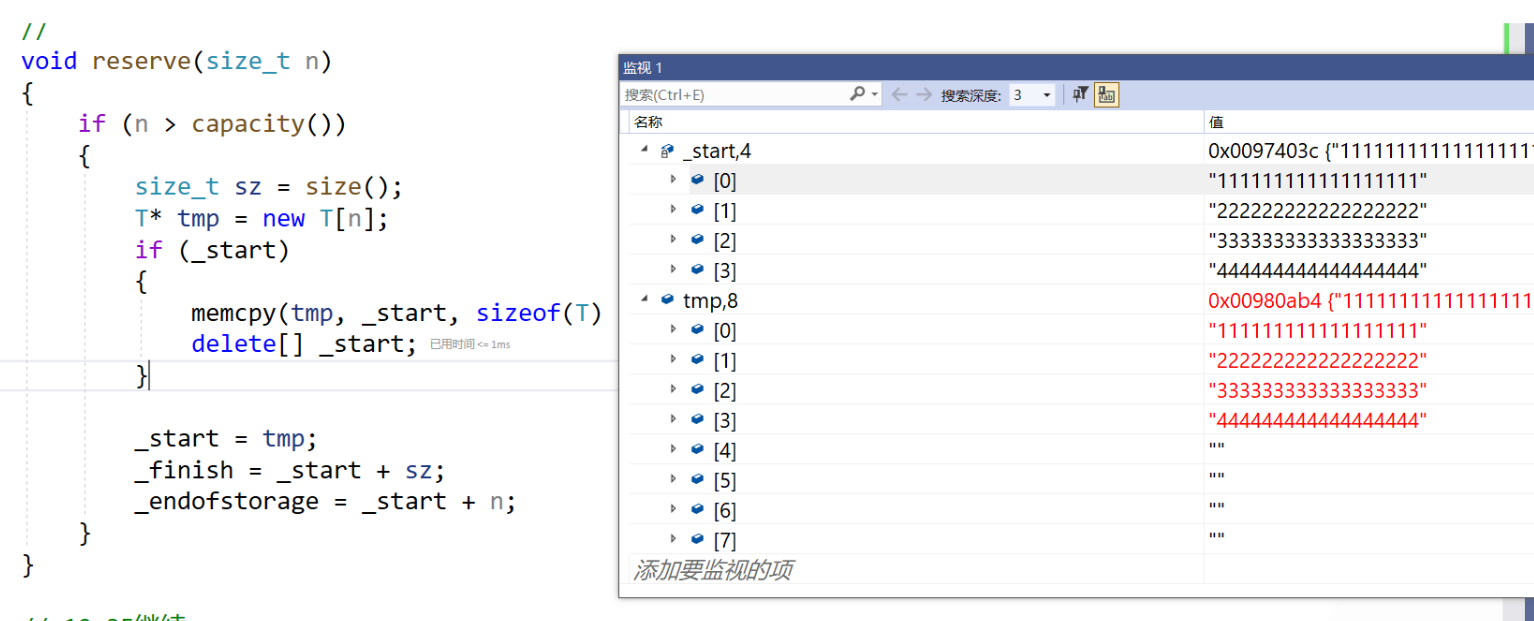
由此可见,在reserve里面如果使用memcpy函数,在vector这个类型里面,此时的复制就是浅拷贝。由于两个string指向同一个空间,在析构函数释放的时候就会出现问题。
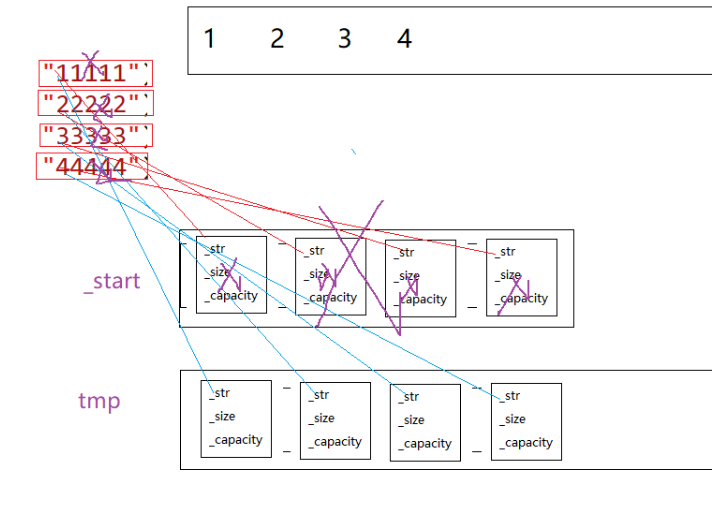
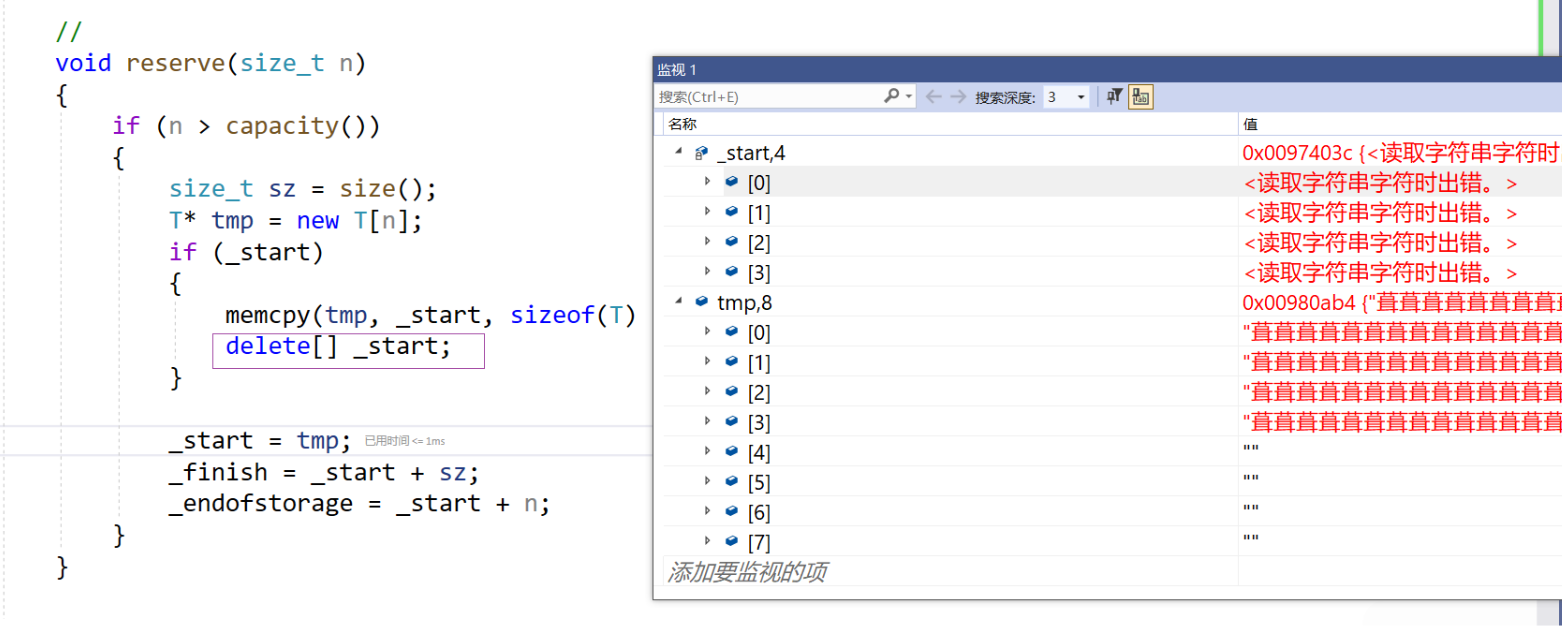
那么我们怎么解决这个问题呢?

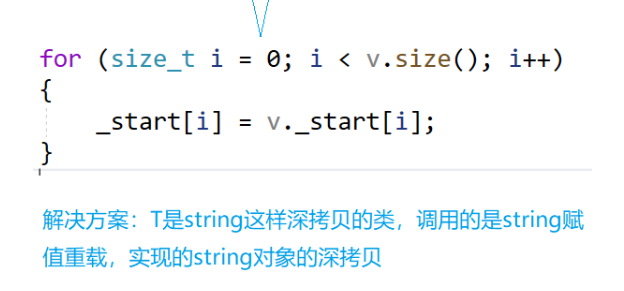
因为不同的类不一样,我们不可能对于string单独写一个,list之类的也存在浅拷贝问题,所以我们直接使用string类的赋值重载来实现string对象的深拷贝:
4.vector构造函数问题:
同学们在看vector构造函数的时候可能会看到这里:

随后便想自己模拟实现一下,但是这里的迭代器类型和模板类的迭代器类型可能不一样,比如当我们用string类来初始化vector的时候。
string str("你干嘛哈哈");
vector<char>(str.begin(),str.end());
//在这里迭代器不同。
所以我们要通过模板类里面在套模板来实现:
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
总结
总的来说,在学完string以后学习vector还是比较轻松的。这里是模拟实现的完整代码:vector模拟实现
总结
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
C语言学习
算法
智力题
初阶数据结构
Linux学习
C++学习
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!