文章目录
- 一 Doris 介绍
- 1.1 使用场景
- 1.1.2 Doris架构
- 二 Doris单机部署
- 2.1 下载 Doris
- 2.2 配置 Doris
- 2.2.1 配置 FE
- 2.2.2 启动 FE
- 2.2.3 查看 FE 运行状态
- 2.2.4 连接 FE
- 2.2.5 停止 FE 节点
- 2.2.6 配置 BE
- 2.2.7 启动 BE
- 2.2.8 添加 BE 节点到集群
- 2.2.9 查看 BE 运行状态
- 2.2.10 停止 BE 节点
- 2.3 创建数据表
- 2.4 查询数据
- 2.5 WebUI查询数据
一 Doris 介绍
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业近百家企业的 300 余位贡献者,并且每月活跃贡献者人数也接近 100 位。 2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)
Apache Doris 如今在中国乃至全球范围内都拥有着广泛的用户群体,截止目前, Apache Doris 已经在全球超过 500 家企业的生产环境中得到应用,在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、微博、贝壳等。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。
1.1 使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6bsWesA1-1690648914585)(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/sekvbs5ih5rb16wz6n9k.png)]
- 报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
- 即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
- 统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
- 数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
1.1.2 Doris架构
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程
- Frontend(FE),主要负责
用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。 - Backend(BE),主要负责
数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vcz28SFi-1690648914586)(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/mnz20ae3s23vv3e9ltmi.png)]
在使用接口方面,Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。
在存储引擎方面,Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
Doris 也支持比较丰富的索引结构,来减少数据的扫描:
- Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景
- Z-order Index :使用 Z-order 索引,可以高效对数据模型中的任意字段组合进行范围查询
- Min/Max :有效过滤数值类型的等值和范围查询
- Bloom Filter :对高基数列的等值过滤裁剪非常有效
- Invert Index :能够对任意字段实现快速检索
在存储模型方面,Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- Aggregate Key 模型:相同 Key 的 Value 列合并,通过提前聚合大幅提升性能
- Unique Key 模型:Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新
- Duplicate Key 模型:明细数据模型,满足事实表的明细存储
Doris 也支持强一致的物化视图,物化视图的更新和选择都在系统内自动进行,不需要用户手动选择,从而大幅减少了物化视图维护的代价。
在查询引擎方面,Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s1WG7yO6-1690648914586)(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vjlmumwyx728uymsgcw0.png)]
Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD 指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V3eEJwuH-1690648914586)(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ck2m3kbnodn28t28vphp.png)]
Doris 采用了 Adaptive Query Execution 技术, 可以根据 Runtime Statistics 来动态调整执行计划,比如通过 Runtime Filter 技术能够在运行时生成生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。Doris 的 Runtime Filter 支持 In/Min/Max/Bloom Filter。
在优化器方面 Doris 使用 CBO 和 RBO 结合的优化策略,RBO 支持常量折叠、子查询改写、谓词下推等,CBO 支持 Join Reorder。目前 CBO 还在持续优化中,主要集中在更加精准的统计信息收集和推导,更加精准的代价模型预估等方面。
二 Doris单机部署
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景,这个简短的指南将告诉你如何下载 Doris 最新稳定版本,在单节点上安装并运行它,包括创建数据库、数据表、导入数据及查询等。
2.1 下载 Doris
Doris 运行在 Linux 环境中,推荐 CentOS 7.x 或者 Ubuntu 16.04 以上版本,同时你需要安装 Java 运行环境(JDK最低版本要求是8),要检查你所安装的 Java 版本,请运行以下命令:
java -version
接下来,下载 Doris 的最新二进制版本,根据自己的cpu选择下载对应类型,我的下面下载ARM架构的版本,然后解压。
#解压和重命名fe
mkdir /usr/local/doris-1.1.4
cd /usr/local/doris-1.1.4
tar -zxvf /home/apache-doris-fe-1.1.4-bin.tar.gz -C ./
mv ./apache-doris-fe-1.1.4-bin/ ./fe
#解压和从命名be
tar -zxvf /home/apache-doris-1.1.4-bin-arm.tar.gz -C ./
mv ./apache-doris-1.1.4-bin-arm/ ./be
2.2 配置 Doris
2.2.1 配置 FE
我们进入到 doris-1.1.4/fe 目录
cd ./fe/
修改 FE 配置文件 conf/fe.conf ,这里我们主要修改两个参数:priority_networks 及 meta_dir ,如果你需要更多优化配置,请参考 FE 参数配置说明,进行调整。
-
添加 priority_networks 参数
vim ./conf/fe.conf priority_networks = 192.168.10.0/24注意:
这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为 FE 指定唯一的IP地址。
这里假设你的节点 IP 是
172.23.16.32,那么我们可以通过掩码的方式配置为172.23.16.0/24。 -
添加元数据目录
meta_dir = /usr/local/doris-1.1.4/fe/doris-meta/注意:
这里你可以不配置,默认是在你的Doris FE 安装目录下的 doris-meta,
单独配置元数据目录,需要你提前创建好你指定的目录
-
修改http的端口,因为和yarn端口冲突,不冲突可以不修改
http_port = 10030
2.2.2 启动 FE
在 FE 安装目录下执行下面的命令,来完成 FE 的启动。
./bin/start_fe.sh --daemon
2.2.3 查看 FE 运行状态
你可以通过下面的命令来检查 Doris 是否启动成功
#通过jps查看
jps
10441 PaloFe
#通过curl方式查看
curl http://127.0.0.1:10030/api/bootstrap
{"msg":"success","code":0,"data":{"replayedJournalId":0,"queryPort":0,"rpcPort":0,"version":""},"count":0}
这里 IP 和 端口分别是 FE 的 IP 和 http_port(默认8030),如果是你在 FE 节点执行,直接运行上面的命令即可。
如果返回结果中带有 "msg":"success" 字样,则说明启动成功。
你也可以通过 Doris FE 提供的Web UI 来检查,在浏览器里输入地址
http://192.168.10.101:10030
可以看到下面的界面,说明 FE 启动成功
注意:
- 这里我们使用 Doris 内置的默认用户 root 进行登录,密码是空
- 这是一个 Doris 的管理界面,只能拥有管理权限的用户才能登录,普通用户不能登录。
登陆成功后如下图所示
2.2.4 连接 FE
我们下面通过 MySQL 客户端来连接 Doris FE,下载免安装的 MySQL 客户端
解压刚才下载的 MySQL 客户端,在 bin/ 目录下可以找到 mysql 命令行工具。然后执行下面的命令连接 Doris。
mysql -uroot -P9030 -h192.168.10.101
注意:
- 这里使用的 root 用户是 doris 内置的默认用户,也是超级管理员用户,具体的用户权限查看 权限管理
- -P :这里是我们连接 Doris 的查询端口,默认端口是 9030,对应的是fe.conf里的
query_port- -h : 这里是我们连接的 FE IP地址,如果你的客户端和 FE 安装在同一个节点可以使用127.0.0.1,这种也是 Doris 提供的如果你忘记 root 密码,可以通过这种方式不需要密码直接连接登录,进行对 root 密码进行重置
执行下面的命令查看 FE 运行状态
show frontends\G;
然后你可以看到类似下面的结果:
mysql> show frontends\G;
*************************** 1. row ***************************
Name: 192.168.10.101_9010_1669775786257
IP: 192.168.10.101
EditLogPort: 9010
HttpPort: 10030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 1181526091
Join: true
Alive: true
ReplayedJournalId: 108
LastHeartbeat: 2022-11-30 10:42:22
IsHelper: true
ErrMsg:
Version: 1.1.4-rc01-8890a58dc
CurrentConnected: Yes
1 row in set (0.07 sec)
ERROR:
No query specified
注意:
如果 IsMaster、Join 和 Alive 三列均为true,则表示节点正常。
2.2.5 停止 FE 节点
Doris FE 的停止可以通过下面的命令完成
./bin/stop_fe.sh
2.2.6 配置 BE
我们进入到 doris-1.1.4/be 目录
cd /usr/local/doris-1.1.4/be
修改 BE 配置文件 conf/be.conf ,这里我们主要修改两个参数:priority_networks' 及 storage_root ,如果你需要更多优化配置,请参考 BE 参数配置说明,进行调整。
-
添加 priority_networks 参数
vim ./conf/be.conf priority_networks = 192.168.10.0/24注意:
这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为 BE 指定唯一的IP地址。
-
配置 BE 数据存储目录
storage_root_path = /usr/local/doris-1.1.4/be/storage/注意:
- 默认目录在 BE安装目录的 storage 目录下。
- BE 配置的存储目录必须先创建好
-
修改ip
webserver_port = 10040 brpc_port = 10060注意:
默认webserver_port = 8040
默认brpc_port = 8060如果这两个端口没有被占用,可以不修改
2.2.7 启动 BE
在 BE 安装目录下执行下面的命令,来完成 BE 的启动。
./bin/start_be.sh --daemon
注意:
BE结点和FE结点启动先后次序无要求
可以通过如下查看是否启动
192.168.10.101:10060
2.2.8 添加 BE 节点到集群
通过MySQL 客户端连接到 FE 之后执行下面的 SQL,将 BE 添加到集群中
ALTER SYSTEM ADD BACKEND "192.168.10.101:9050";
- 配置语法:
ALTER SYSTEM ADD BACKEND "be_host_ip:heartbeat_service_port"; - be_host_ip:这里是你 BE 的 IP 地址,和你在
be.conf里的priority_networks匹配,需要具体ip - heartbeat_service_port:这里是你 BE 的心跳上报端口,和你在
be.conf里的heartbeat_service_port匹配,默认是9050。
2.2.9 查看 BE 运行状态
你可以在 MySQL 命令行下执行下面的命令查看 BE 的运行状态。
SHOW BACKENDS\G
示例:
mysql> SHOW BACKENDS\G
*************************** 1. row ***************************
BackendId: 11001
Cluster: default_cluster
IP: 192.168.10.101
HeartbeatPort: 9050
BePort: 9060
HttpPort: 10040
BrpcPort: 10060
LastStartTime: 2022-11-30 11:04:59
LastHeartbeat: 2022-11-30 11:08:33
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 0
DataUsedCapacity: 0.000
AvailCapacity: 25.518 GB
TotalCapacity: 39.266 GB
UsedPct: 35.01 %
MaxDiskUsedPct: 35.01 %
Tag: {"location" : "default"}
ErrMsg:
Version: 1.1.4-rc01-Unknown
Status: {"lastSuccessReportTabletsTime":"2022-11-30 11:08:30","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false}
1 row in set (0.04 sec)
Alive : true表示节点运行正常
2.2.10 停止 BE 节点
Doris BE 的停止可以通过下面的命令完成
./bin/stop_be.sh
2.3 创建数据表
在doris的fe端使用MySQL客户端连接,使用命令行操作
-
创建一个数据库
create database demo; -
创建数据表
use demo; CREATE TABLE IF NOT EXISTS demo.user_lab( `user_id` LARGEINT NOT NULL COMMENT "用户id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" ); -
示例数据
10000,2017-10-01,北京,20,0,2017-10-01 06:00:00,20,10,10 10000,2017-10-01,北京,20,0,2017-10-01 07:00:00,15,2,2 10001,2017-10-01,北京,30,1,2017-10-01 17:05:45,2,22,22 10002,2017-10-02,上海,20,1,2017-10-02 12:59:12,200,5,5 10003,2017-10-02,广州,32,0,2017-10-02 11:20:00,30,11,11 10004,2017-10-01,深圳,35,0,2017-10-01 10:00:15,100,3,3 10004,2017-10-03,深圳,35,0,2017-10-03 10:20:22,11,6,6将上面的数据保存在一个/usr/local/doris-1.1.4/test.csv文件中。然后导入数据:
这里我们通过Stream load 方式将上面保存到文件中的数据导入到我们刚才创建的表里。
curl --location-trusted -u root: -T /usr/local/doris-1.1.4/test.csv -H "column_separator:," http://192.168.10.101:10030/api/demo/user_lab/_stream_load- -T test.csv : 这里是我们刚才保存的数据文件,如果路径不一样,请指定完整路径
- -u root : 这里是用户名密码,我们使用默认用户root,密码是空
- 127.0.0.1:8030 : 分别是 fe 的 ip 和 http_port
执行成功之后我们可以看到下面的返回信息
{ "TxnId": 2, "Label": "d210bb2e-433e-4a12-a91a-b47d8f576446", "TwoPhaseCommit": "false", "Status": "Success", "Message": "OK", "NumberTotalRows": 7, "NumberLoadedRows": 7, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 399, "LoadTimeMs": 133, "BeginTxnTimeMs": 22, "StreamLoadPutTimeMs": 50, "ReadDataTimeMs": 0, "WriteDataTimeMs": 15, "CommitAndPublishTimeMs": 43 }NumberLoadedRows: 表示已经导入的数据记录数NumberTotalRows: 表示要导入的总数据量Status:Success 表示导入成功
到这里我们已经完成的数据导入,下面就可以根据我们自己的需求对数据进行查询分析了。
2.4 查询数据
我们上面完成了建表,输数据导入,下面我们就可以体验 Doris 的数据快速查询分析能力。
mysql> select * from demo.user_lab;
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
6 rows in set (0.09 sec)
mysql> select * from demo.user_lab where city = '北京';
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
+---------+------------+--------+------+------+---------------------+------+----------------+----------------+
2 rows in set (0.04 sec)
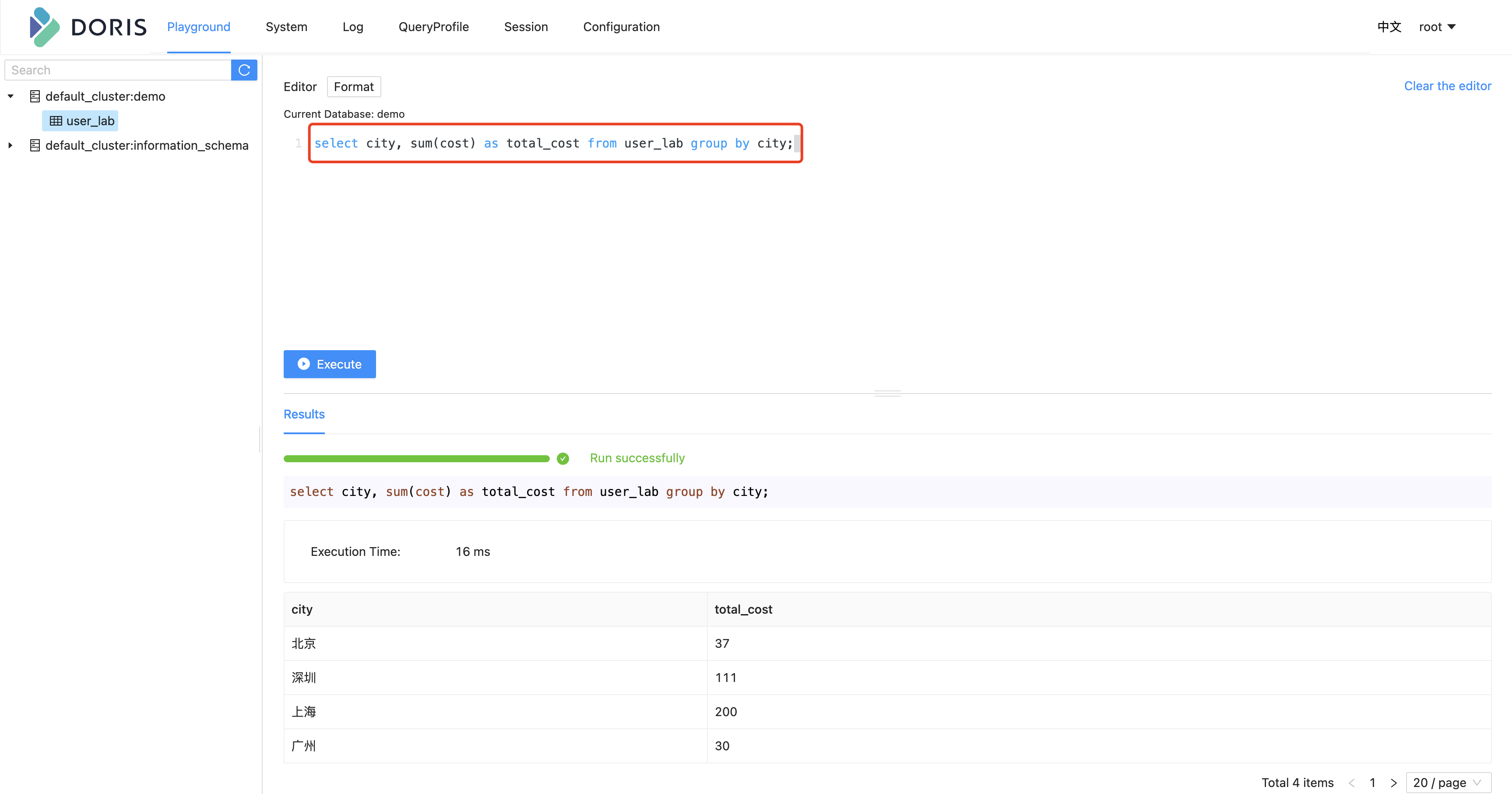
mysql> select city, sum(cost) as total_cost from demo.user_lab group by city;
+--------+------------+
| city | total_cost |
+--------+------------+
| 北京 | 37 |
| 深圳 | 111 |
| 上海 | 200 |
| 广州 | 30 |
+--------+------------+
4 rows in set (0.07 sec)
到这里我们整个快速开始就结束了,我们从 Doris 安装部署、启停、创建库表、数据导入及查询,完整的体验了Doris的操作流程,下面开始我们 Doris 使用之旅吧。
2.5 WebUI查询数据





![BUU [BJDCTF2020]The mystery of ip](https://img-blog.csdnimg.cn/img_convert/981675958f66fe219d60e6b71fab53cd.jpeg)