1、前言
最近对mysql的操作比较多一些,主要是项目上线以后,难免会有一些数据上的问题。开始的时候还主要由后端来处理,后面数据问题确实比较多,于是我就找后端要来服务器的账号密码,连上数据库顺便来看看数据的问题。

周五使用人数达到了高峰,总共有5300人在使用,今天截图的时候是周六人数略有减少。

这是三个表数据比较大的表,目前大致运行两周的时间就已经很大了。

这是数据量最多的一张表,大致已经410W条记录了。
算是一个小小的系统,不算大,但是从目前数据量的增加来看,慢慢的数据量可能会越来越大。
2、mysql 索引
最开始项目刚上线的时候,因为没有数据,所以根本没什么感觉,突然某一天,就感觉到接口的响应时间明显的变慢了。但其实后端并没有什么线上的经验,所以我借机就要来了服务器的账号密码。基本上除了主键以外,没有加任何的索引。打到数据库上的查询就实打实的有一些慢了,(虽然这里使用了一主四从),四个从库相当于都是用来做查询使用的,但是在没有索引的情况下,真的有点慢了。我跟后端稍作沟通,我就准备直接在正式环境添加数据库表的索引了。
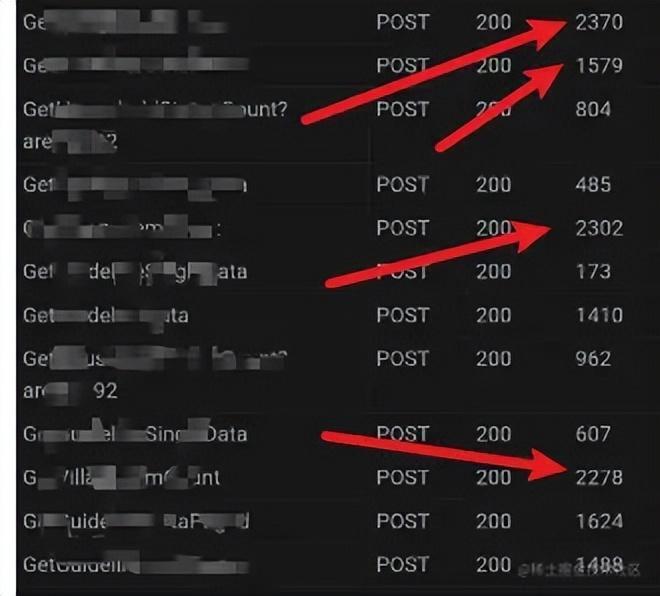
这是平常小程序里接口的返回时间记录。而且有时候根据访问人数的不同,偶尔有时候会到三秒到四秒。
3、打开慢查询记录开关
那么能否通过专业的工具去查看呢?首先我做的第一件事情便是,查看一下mysql的慢查询是否有打开,好家伙,还不错,竟然打开了。如果没开启可以开启一下:
// 查看慢查询日志是否开启 on为开启 off为关闭 默认是关闭的
show variables like 'slow_query_log';
// 设置是否开启慢查询日期记录
set global slow_query_log = on; #开启
set global slow_query_log = off; #关闭
// 查看慢查询的阈值(默认是10秒)
show variables like 'long_query_time';
// 如果想修改慢查询的阈值
// 阈值设置为1秒
set global long_query_time = 1;
// 查看慢查询日志文件路径
show variables like 'slow_query_log_file';如果慢查询记录log没有打开,可以参考一下这篇文章:juejin.cn/post/716761…
4、通过mysqldumpslow 查询慢查询sql
下面是常用的几个查询慢SQL的脚本语句
// 得到返回记录集最多的10条SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/slow.log
// 得到访问次数最多的10条SQL:
mysqldumpslow -s r -t 10 /data/mysql/slow.log
// 得到按照时间排序的前10条里面含有左连接的SQL:
mysqldumpslow -s t -t 100 -g "left join" /var/lib/mysql/slow.log
// 也支持管道符命令
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/slow.log | more //分页显示执行后结果如下所示,一目了然

可以查看到第一个sql 平均耗时2.94s,这个sql不论在哪里使用都会感觉慢了。所以这个时候查看sql以后,可以使用explain + sql 在mysql客户端执行,查看执行计划

可以查看返回结果,我平常观察最多的几个字段便是 type、 rows、Extra、等字段。
如果你想详细了解 explain的执行计划,你可以访问如下链接来重点阅读: juejin.cn/post/716359…
5、直接添加索引
我简单可以总结为如下:
-
join 后看表关联的字段
-
where 后看查询条件的字段
-
group by order by 后的 分组条件和排序条件
在有条件的时候,上述地方能加索引就加索引,但是通常一张表添加五个索引就算比较多的,因为如果一张表索引过多在其他地方,比如存储、添加、删除的时候都会重新整理索引,成本消耗会很大。

目前来说这种简单粗暴的方式,在几百万数据的量级完全解决了我的问题,这里展示了我随便找的一张表,里面添加了四个索引,这里完全可以用四个字段的普通索引即可,我这里当时为了验证联合索引或者叫复合索引就没改了,目前来看效果还是嘎嘎的香,随着数据量的增加我猜测索引会有调整。
6、重置慢查询日志
假如我们优化完毕了,正式环境重新部署了,我们想查看一下效果,比如想去查询一下慢查询的日志记录,但是之前的日志记录还在,这个时候我们应该怎么办呢?
// 通过rm直接删除慢查询日志记录文件
rm slow.log
// 然后记得要重置慢查询才会开启继续登录
// 在 mysql所在的linux服务器上执行
mysqladmin -uroot -p flush-logs slow
//或者在mysql数据库中执行
mysql> FLUSH LOGS;重置后可查看slow.log是否重新生成。
7、注意事项
- 尽量禁止使用 select * 进行查询:减少IO和传递压力等
- 查询条件的类型尽量与数据库里的类型一致:不一致可能导致索引失效
- group by 后如果不想排序 可以在后面添加order by null
- 查询计划中尽量避免全表扫描
- 每张表都要设置主键,因为不设置mysql会自动帮我们设置
- 主键最好不要用GUID,尽量自增ID(GUID插入时时无序的)
- 明确只返回一条记录的sql 可以加上limit 1
- 联合索引(复合索引)查询时要注意查询字段的顺序
- 如果可以尽量给字段设置默认值,不要为null空值,null在一定程度上会造成索引失效
- like 模糊查询尽量不要以% 开头,因为会造成索引失效
- 一个sql关联的表不要过多(通常最多三到五个)
- 多表查询时一定先以小表查询,再来查询大表,也就是小表驱动大表
- 尽量少用or会造成索引失效,有些时候可以使用union all替换
- 当然还有其他的,暂时在项目使用就这么多
8、总结
一种情况时找到具体接口中使用的sql,如果很慢进行优化sql或者添加索引,另外一种时通过mysql工具查找到记录的慢查询sql,可以直接根据表结构进行添加索引,如果很复杂,而且简单的增加索引无法提速,可能要根据具体业务进行分析调整再添加索引。总之索引的使用在大部分情况下是非常有效的。 通过explain 查看sql执行计划,进行优化索引和表设计,因为在某些情况合理的表结构默认值设置、或者表关联字段设置,都能有效的避免全表扫描。 总之不要怂,加错了索引,大不了花点时间删除就好了。