布隆
布隆过滤器(Bloom Filter)是一种概率型数据结构,用于判断一个元素是否可能存在于一个集合中。它使用多个哈希函数和位图来表示集合中的元素。
布隆过滤器的基本原理如下:
-
初始化:创建一个长度为m的位图(bitmap),并将所有位都置为0。
-
插入元素:对于要插入的元素,使用k个哈希函数对其进行哈希计算,得到k个哈希值。然后将位图中对应的位置置为1。
-
查询元素:对于要查询的元素,同样使用k个哈希函数对其进行哈希计算,得到k个哈希值。然后检查位图中对应的位置,如果所有位置都为1,则认为元素可能存在于集合中;如果有任何一个位置为0,则元素一定不存在于集合中。
布隆过滤器的优点是占用空间小、插入和查询速度快,且不需要存储实际的元素值。但布隆过滤器也存在一定的误判率(False Positive),即可能将不存在的元素误判为存在。误判率取决于位图的长度和哈希函数的个数。
布隆过滤器适用于需要高效判断元素是否存在的场景,如缓存穿透问题、URL去重、黑名单过滤等。但它不适用于需要精确判断元素是否存在的场景,因为存在一定的误判率。在使用布隆过滤器时,需要根据实际情况选择合适的位图长度和哈希函数个数,以平衡空间占用和误判率。
哈希切分
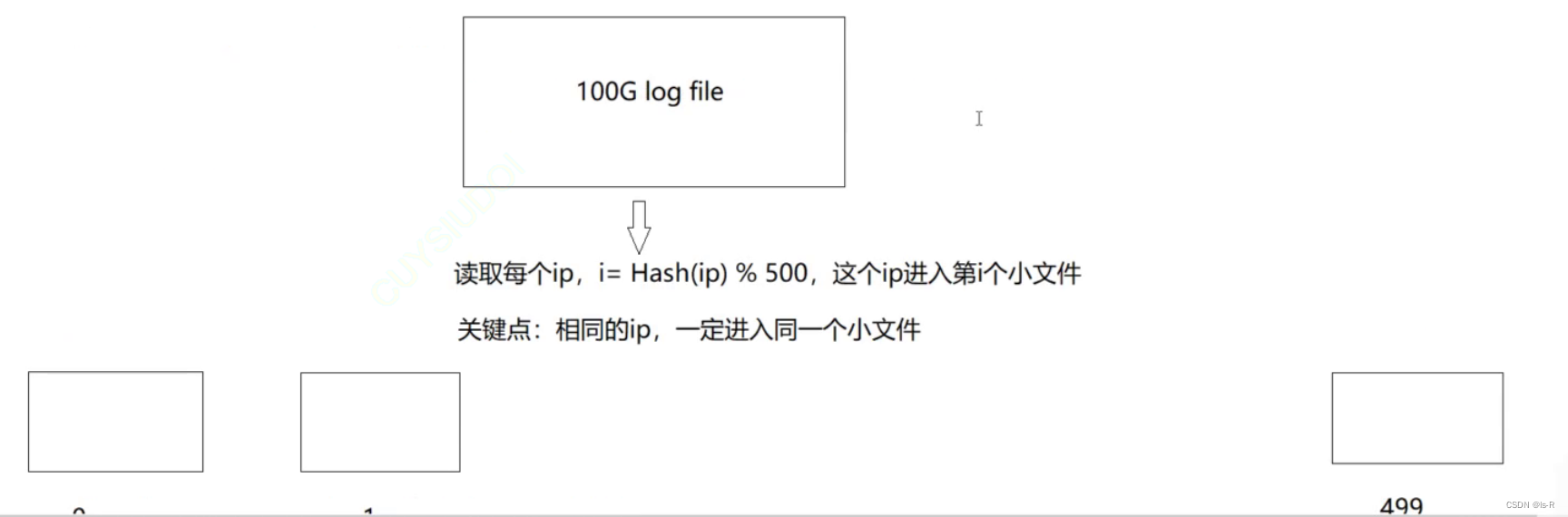
问题:两个文件分别有100亿个query,只有1G内存,如何找到两个文件的交集?分别给出精确算法和近似算法
1.假设每个query 30byte ,100亿query需要多少空间? -> 3000亿byte -> ≈ 300G (10亿byte约等于1G)
2.假设两个文件叫A和B
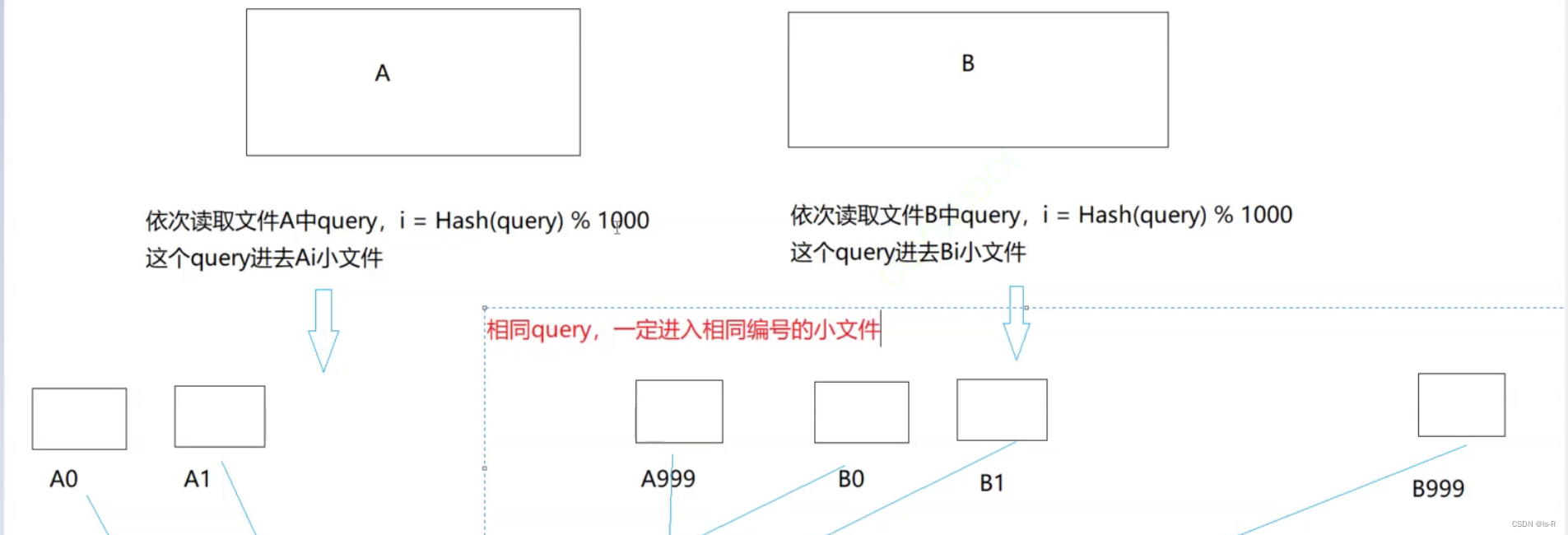
在相同编号的小文件中找交集 A0和B0 …
如果小文件过大也可以切分(递归即可),没有必要分成1000份(分成适当大小即可)
问题






![Docker 入门终极指南[详细]](https://img-blog.csdnimg.cn/img_convert/33f8a04fab9bfef0b493b28368a42740.png)





![[语义分割] DeepLab v2(膨胀卷积、空洞卷积、多尺度信息融合、MSc、ASPP、空洞空间金字塔池化、Step学习率策略、Poly学习率策略)](https://img-blog.csdnimg.cn/526f8d16f5c344dabafa2cb105b7a905.png#pic_center)