上期跟大家聊了下eBPF的发展历史还有特性,点击这里↓↓↓擎创技术流 | 深入浅出运维可观测工具(一):聊聊eBPF的前世今生,一键回看上期精彩内容。
这期主要跟大家分享下eBPF在应用过程中可能出现的问题,希望能帮到遇到类似问题的朋友,话不多说,我们进入正题。
一、内核适应性,老版本的某些功能不可用
eBPF 最低要求版本为LInux 4.1,eBPF的最低内核版本要求是 Linux 4.1,这是在 2015 年发布的内核版本。在这个版本之前的内核不支持 eBPF。
1.对于Linux4.1版本之前的监控
擎创对于Linux 4.1.0 之前的版本采用BPF采集HTTP 1数据以及DNS解析请求,进行可观测统计。
2.对于Linux4.1版本之后的监控
为了保证eBPF程序在各个linux内核版本之间的可移植性,我们编写eBPF程序的时候采用了CORE技术,CORE技术目前只有在 Linux 4.9.0 之后才会支持。
如果用户内核版本低于4.9.0或者内核未开启CO-RE, 我们能够提供linux内核升级包。
BCC总结了kernel版本与eBPF功能的关系:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md

二、权限安全要求
1.eBPF权限
需要具备root权限或CAP_SYS_ADMIN能力,这意味着只有能够加载内核模块的用户才能加载eBPF程序。
2.eBPF执行安全
在执行安全方面,eBPF 在加载之前会通过eBPF验证器对要执行的字节码文件进行校验,包括但不限于以下方面:
-
程序不包含控制循环
-
程序不会执行超过内核允许的最大指令数
-
程序不包含任何无法到达的指令
-
程序不会跳转到程序界限之外

三、uprobe 和 kprobe 差异
1.kprobe的优劣分析
优势:
-
更简单实现和更易维护。
-
不依赖于其他库的具体实现细节
劣势:
-
用户程序可能会将单个请求分割成多个系统调用,重新组装这些请求会带来一些复杂性
-
与TLS不兼容, 无法解包TLS

2.uprobe的优劣分析
优势:
-
我们可以访问和捕获应用程序上下文,如堆栈跟踪
-
我们可以构建uprobes以在解析完成后捕获数据,避免在跟踪器中重复工作
-
可以比较容易捕获https 请求,对TLS兼容性较好
劣势:
(1)对于使用的底层库版本敏感。 无法在剥离了符号的二进制文件上运行
(2)需要为每个库实现不同的探针(每种编程语言可能都有自己的一组库)
(3)会导致额外的调用性能开销

四、性能消耗
虽然内核社区已经对 eBPF 做了很多的性能调优,跟踪用户态函数(特别是锁争用、内存分配之类的高频函数)还是有可能带来很大的性能开销。因此,我们在使用 uprobe,kprobe 时,应该尽量避免长时间跟踪高频函数。
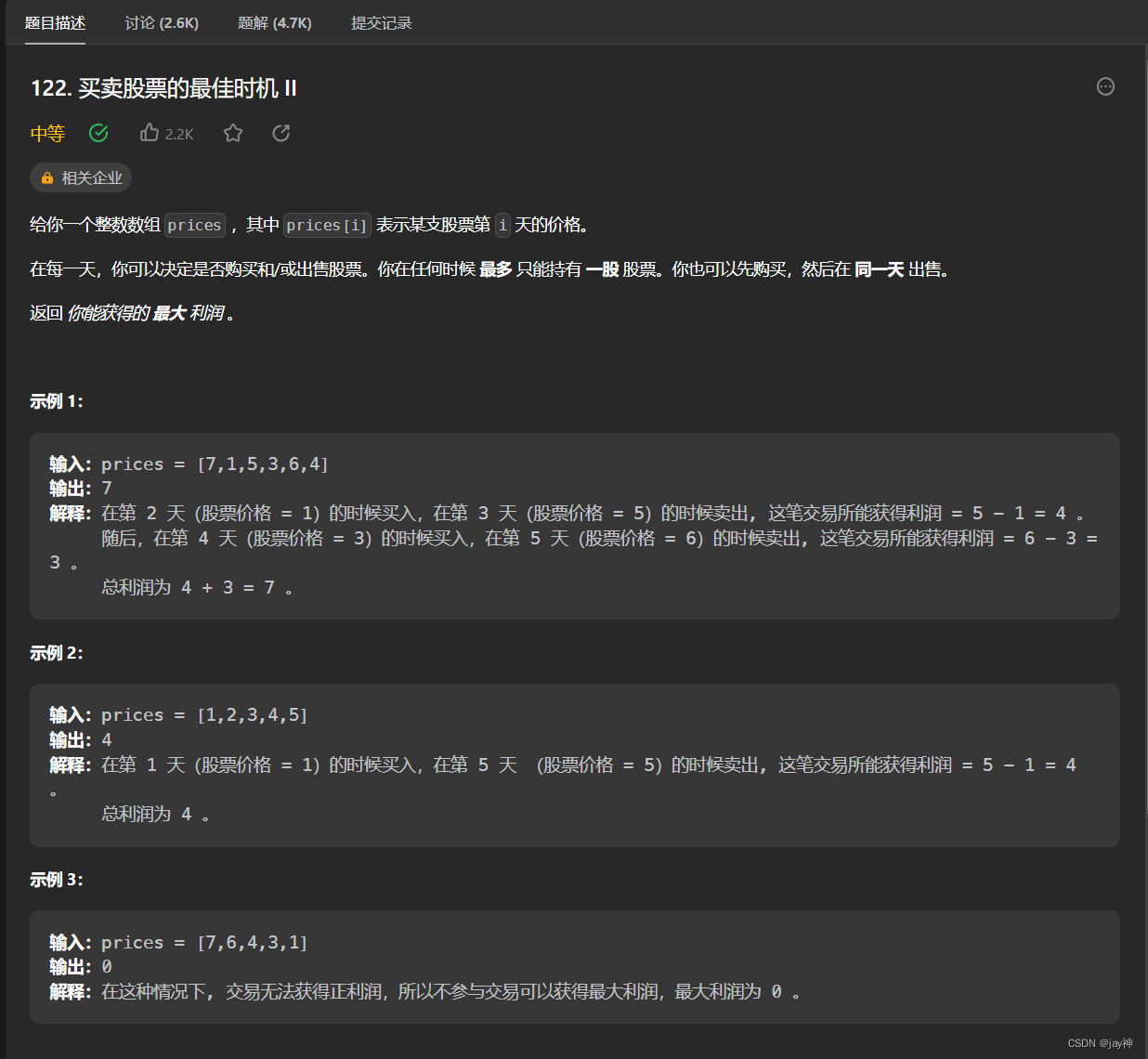
我们以监控一个Golang 程序HTTP 1通信过程为例子,在分别开启uprobe和kprobe时候对该程序进行压力测试:


从结果可以看出,如果HTTP延迟大于1毫秒,引入的开销可以忽略不计,在大多数情况下只是噪音。这对于kprobes和uprobes都是类似的,尽管我们重新解析了所有数据,但kprobes的性能稍微好一些。请注意,开销有时是负值,这很可能只是测量中的噪音。在这里的关键要点是,如果您的HTTP处理程序正在进行任何实际的工作(大约1毫秒计算时间),引入的开销基本上可以忽略不计。
五、能否追踪所有用户态/内核态函数(调用的入参和返回值)
1.用户态
eBPF可以追踪指定函数调用入参和返回值。hook点可以为指定函数名称或者地址。 如果可执行文件的符号被优化,则需要使用一些逆向手段定位指定函数的地址。
2.内核态
我们可以使用bpftrace -l了解可以hook的钩子点。
bpftrace是通过读取(下方代码)获取kernel层所有的可跟踪点。
/sys/kernel/debug/tracing/available_filter_functions
六、是否有丢失事件的风险
1.kprobe和uprobe本身的事件触发并不会丢失
kprobe是一种内核探测机制,它允许用户在内核函数执行前或执行后插入代码。uprobe是一种对用户空间函数进行探测的机制,它允许用户在用户空间函数的入口或出口处插入代码。
eBPF通过将用户编写的处理逻辑加载到内核中,在事件发生时执行此逻辑,以实现用户级的观察和处理。由于eBPF的虚拟机技术提供了一种安全可隔离的方式来在内核中执行用户代码,因此kprobe和uprobe事件不会丢失。

2.bpf_perf_event会有丢失事件的风险
内核态的eBPF代码将收集到的事件写入 bpf_perf_event 环形缓冲区,用户态程序进行收集上报。当读写速度不匹配时,就会丢失事件:
- 写速度过快:例如每个HTTP transaction都作为一个event写入缓冲区,这样比批量写的风险更高。
- 读速度过慢:例如用户态代码没有在专门线程中读取缓冲区,或者系统负载过高。

3.bpf_map会有丢失事件的风险
eBPF map有大小限制,当map被写满的时,将无法写入新的数据
- 丢失数据:由于map已满,新的写入操作将无法成功,导致数据丢失。这可能会影响到程序的正确性和完整性。
- 性能下降:当map写满时,写入操作将被阻塞,导致系统的性能下降。这会影响到整体的系统响应时间和吞吐量。

写在文末
随着eBPF的不断发展和壮大,我们可以看到它在网络和系统领域的巨大潜力。eBPF已经被证明是一种强大且高效的工具,可以用于实现各种高级网络和系统功能。
在未来,我们有理由相信eBPF将继续发展,并被越来越多的开发者和组织使用。随着eBPF功能的不断扩展和完善,我们可以期待更多创新的网络应用和系统工具的出现,从而推动整个行业向前发展。
总之,eBPF的前世今生令人振奋,它不仅继承了BPF的优点,还拥有更强大和灵活的功能。我们期待看到eBPF为网络和系统带来更多的创新和改进,为我们的数字化世界带来更强大的支撑。

互动一下:
关于eBPF,你有什么想分享的?可以留言区探讨起来~

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。