目录
一、目标网址
二、网址分析
2.1、获取并解析网页内容
2.2 两种获取方法
三、获取目标数据
四、代码附件
一、目标网址
目标网址:中国人口排名 省份
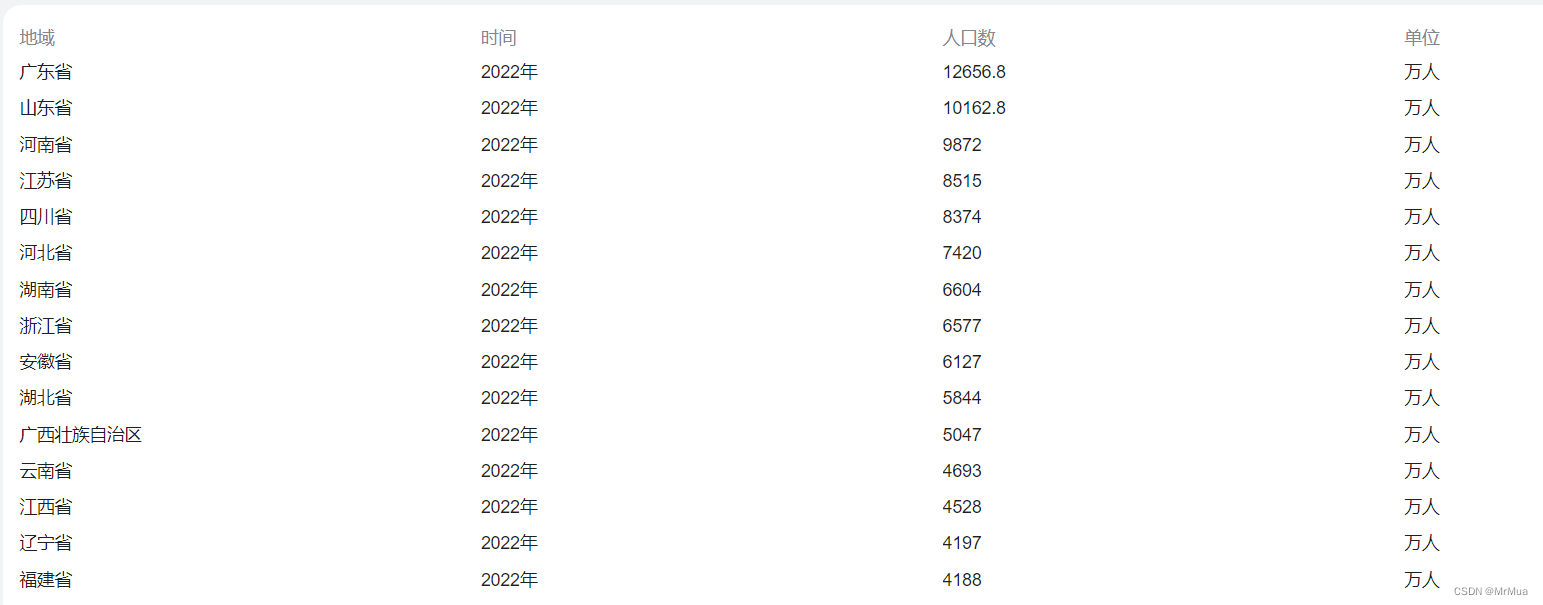
二、网址分析
2.1、获取并解析网页内容
我们需要使用requests库获取网页,使用BeautifulSoup库解析网页内容。
2.2 两种获取方法
这篇主要介绍方法二


三、获取目标数据
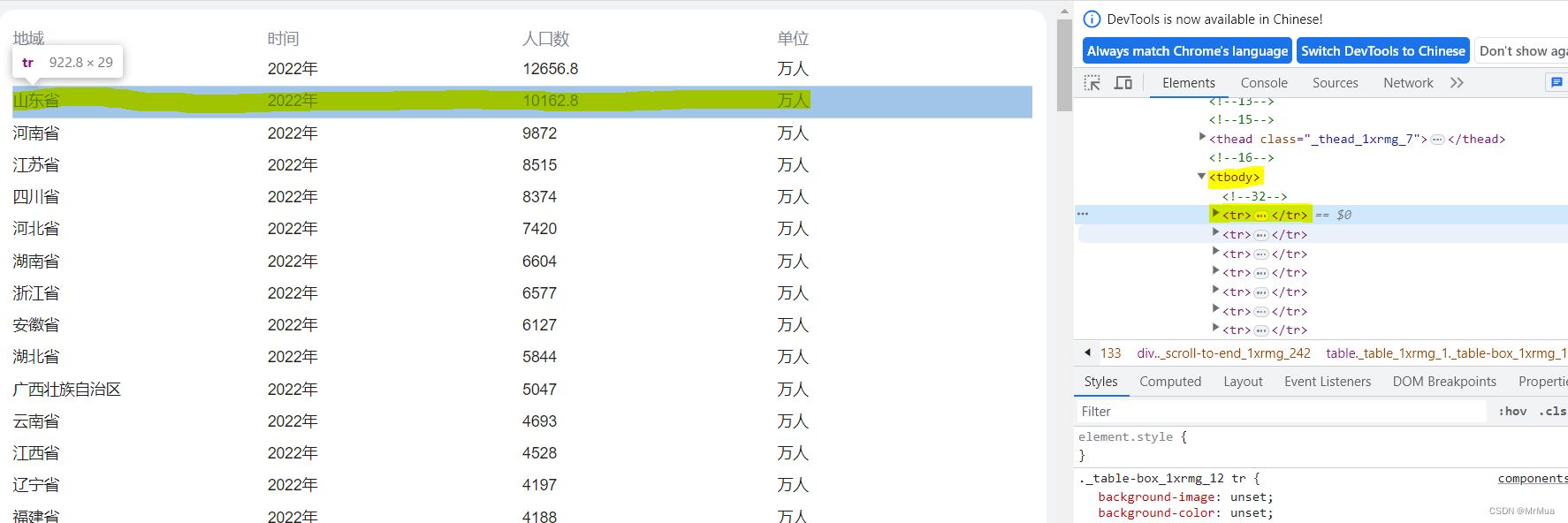
这个网站比较工整,所有的省份数据都在 <tr> 标签中
tbody -> tr -> class="cos-row" -> class="cos-col" -> class="c-line-clamp1"
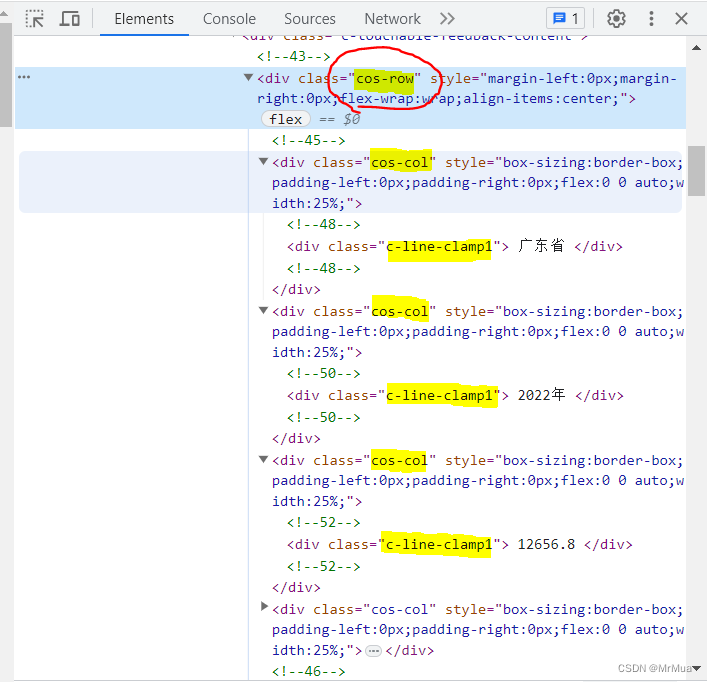
【1】 使用 findall() 方法获取表格中的每一行 tr 标签,
【2】再循环使用 find() 方法获取每一行 class="cos-row" 数据,
【3】findall() 方法获取每一行class="cos-row" 中各个 class="c-line-clamp1" 数据,
【4】row.text.strip() 获取标签内容并除去空白符
【5】最后,我们将获取到的数据存储到一个列表中,并使用pandas库创建一个DataFrame对象,将数据以表格的形式输出。
四、代码附件
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://dbqa.pae.baidu.com/dbqa/page/list?srcid=51103&nl=1&query=%E4%B8%AD%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%90%8D%20%E7%9C%81%E4%BB%BD&en_s=zQqSnP0wKo6ZgYpcz5U994qb0VDmfqIysBkrGsYKsoNWsdIW1ttKBHLP2svkYl3BnmSoegvDPMJjUdH-9AZMouI4u7FKYNlzn-Y62bI0w-xAPNvJbZQvN_GDlVe3cXpDAT6YS94otM1z_3bX8kOqvhMHp-VucIIIQZY3lsdlVqLYl7M8eyxKvHKc-AzXWKklYvTtneuoJUKNTpiQ1Jidsg-1VVN8fUHSTsTZKuuR0cHvPw2qso-sGszsh-u0pzSo79iJcMt6Dlf_eNQQ2I9Jry8c8ShOwY-3_Lci_PuLjvLxuI4cYOMvxkzHic_ujaqHT0tMCM-J1Xo6UKJDA'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
table = soup.find('tbody').findAll('tr', recursive=False) # tbody标签内容
exc = []
i = 0
for subtable in table:
data = subtable.find('div', {'class': "cos-row"})
rows = data.find_all('div', {'class': "c-line-clamp1"})
cols = [row.text.strip() for row in rows] # 循环取所有相同class中间的内容,row.text.strip() # 取class中间的内容
i = i + 1
cols.append(i)
exc.append(cols)
print(exc)
df = pd.DataFrame(exc, columns=['省份', '时间', '人口数', '单位', '排名']) # columns=['排名', '省份', '时间', '人口数', '单位']
df = df[['排名', '省份', '时间', '人口数', '单位']]
print(df)
df.to_excel("population_data.xlsx", index=False)