概括
Onehouse 客户现在可以将他们的 Hudi 表查询为 Apache Iceberg 和/或 Delta Lake 表,享受从云上查询引擎到顶级开源项目的原生性能优化。
在数据平台需求层次结构的基础上,存在摄取、存储、管理和转换数据的基本需求。 Onehouse 提供这种基础数据基础架构作为服务,以在客户数据湖中摄取和管理数据。 随着数据湖在组织内的规模和种类不断增长,将基础数据基础架构与处理数据的计算引擎分离变得势在必行。 不同的团队可以利用专门的计算框架,例如 Apache Flink(流处理)、Ray(机器学习)或 Dask(Python 数据处理),以解决对其组织重要的问题。 解耦允许开发人员在以开放格式存储的数据的单个实例上使用这些框架中的一个或多个,而无需将其复制到和存储紧密耦合的另一服务中。 Apache Hudi、Apache Iceberg 和 Delta Lake 已成为领先的开源项目,为这个解耦存储层提供一组强大的原语,这些原语在云存储中围绕打开的文件提供事务和元数据(通常称为表格式)层,像 Apache Parquet 这样的格式。
背景
AWS 和 Databricks 在 2019 年为此类技术创造了最初的商业势头,分别支持 Apache Hudi 和 Delta Lake。 如今大多数云数据供应商都支持其中一种或多种格式。 然而他们继续构建一个垂直优化的平台以推动对他们自己的查询引擎的粘性,其中数据优化被锁定到某些存储格式, 例如要解锁 Databricks 的 Photon 引擎的强大功能需要使用 Delta Lake。 多年来 AWS 已在其所有分析服务中预安装 Apache Hudi,并继续近乎实时地支持更高级的工作负载。 Snowflake 宣布与 Iceberg 更强大的外表集成,甚至能够将 Delta 表作为外表进行查询。 BigQuery 宣布与所有三种格式集成,首先是 Iceberg。
所有这些不同的选项都提供了混合支持,我们甚至还没有开始列出各种开源查询引擎、数据目录或数据质量产品的支持。 这种越来越大的兼容性矩阵会让组织担心他们会被锁定在一组特定的供应商或可用工具的子集中,从而在进入数据湖之旅时产生不确定性和焦虑。
为什么要建立 Onetable?
在过去的一年里,我们发布了开源项目之间的全面比较,展示了 Hudi 如何具有显着的技术差异化优势,尤其是在为 Hudi 和 Onehouse 的增量数据服务提供支持的更新繁重工作负载方面。 此外Hudi 用于管理和优化表格的自动化表格服务为数据基础架构奠定了全面的基础,同时完全开源。 在选择表格格式时,工程师目前面临着一个艰难的选择,即哪些好处对他们来说最重要。 例如选择 Hudi 的表服务或像 Databricks Photon 这样快速的Spark引擎。 在 Onehouse我们会问真的有必要进行选择吗? 我们希望客户在处理他们的数据时获得尽可能好的体验,这意味着支持 Hudi 以外的格式以利用数据生态系统中不断增长的工具和查询引擎集。 作为一家倡导跨查询引擎互操作性的公司,如果我们不对元数据格式应用相同的标准以帮助避免将数据分解成孤岛,那我们的表现就很虚伪。 今天我们通过 Onetable 朝着这个方向迈出了一大步。
什么是 Onetable?
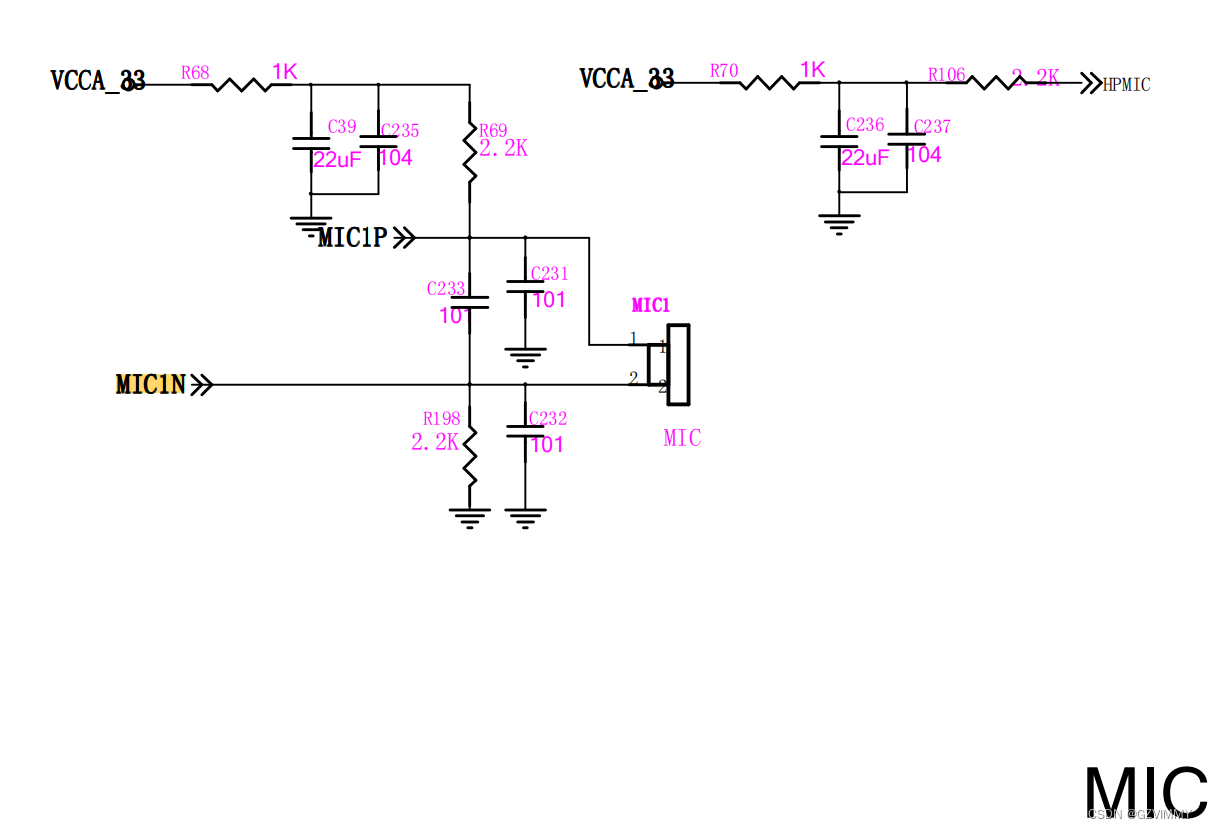
Onehouse 致力于开放,并希望通过我们的云产品 Onetable 上的一项新功能,帮助组织享受 Hudi 解锁的成本效率和高级功能,而不受当前市场产品的限制。 当数据静止在湖中时三种格式并没有太大区别。 它们都提供了对一组文件的表抽象,以及模式、提交历史、分区和列统计信息。 Onetable 采用源元数据格式并将表元数据提取为通用格式,然后可以将其同步为一种或多种目标格式。 这使我们能够将通过 Hudi 摄取的表公开为 Iceberg 和/或 Delta Lake 表,而无需用户复制或移动用于该表的底层数据文件,同时维护类似的提交历史记录以启用适当的时间点查询。
这种方法类似于 Snowflake 为 Iceberg 表保留其内部元数据,同时为外部互操作性创建 Iceberg 元数据的方式。 Hudi 还已经支持与 BigQuery 的集成,大型开源用户和 Onehouse 用户正在使用它。

我们为什么兴奋?
Onehouse 客户可以选择启用 Onetable 作为目录来自动将他们的数据公开为 Hudi 表以及 Iceberg 和/或 Delta Lake 表。 以这些不同的元数据格式公开表使客户能够轻松地加入 Onehouse 并享受托管Lakehouse的好处,同时使用他们喜欢的工具和查询引擎维护他们现有的工作流程。
例如Databricks 是运行 Apache Spark 工作负载的一个非常受欢迎的选择,其专有的 Photon 引擎可在使用 Delta Lake 表格式时提供性能加速。 为了确保使用 Onehouse 和 Databricks 的客户获得良好的体验而没有任何性能缺陷,我们使用 1TB TPC-DS 数据集来对查询性能进行基准测试。 我们比较了 Apache Hudi 和 Delta Lake 表,有/没有 Onetable 和 Databricks 的平台加速,如磁盘缓存和 Photon。 下图显示了 Onetable 如何通过基于 Delta Lake 协议转换元数据来解锁 Onehouse/Hudi 表上 Databricks 内部的更高性能。

此外我们将 Snowflake 中的同一张表公开为外部表,该表通常用于数仓。 我们执行了类似的 1TB TPC-DS 基准测试,比较了 Snowflake 的原生/专有表、外部Parquet表和使用 Onetable 的 Hudi 表。 下图显示 Onetable 如何向 Snowflake 查询公开 Hudi 表的一致快照,同时提供与 Snowflake 的 parquet 表类似的性能。
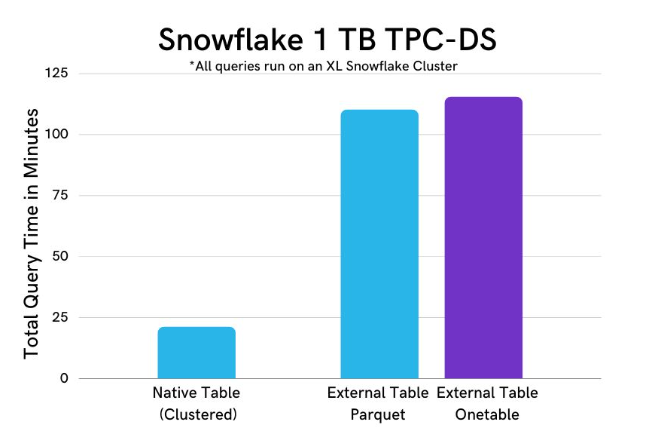
虽然上述外表的性能不如本地 Snowflake 表快,Onetable 提供了公开 Snowflake 内部数据湖的最新视图的功能,以帮助支持下游 ETL/转换或在组织过渡到构建Lakehouse以补充其 Snowflake 数据仓库时保持查询运行。 这种方法避免了将全套数据复制到仓库或使存储成本加倍,同时仍允许工程师和分析师派生出更有意义的聚合原生表,以快速提供报告和仪表板,充分利用 Snowflake 的强大功能。
最重要的是我们很高兴看到这如何帮助用户使用灵活的分层数据架构取得成功,这种架构已经在许多大型数据组织中流行。 Apache Hudi 为数据湖上的增量摄取/etl 提供行业领先的速度和成本效益,这是 Onehouse 的基础。 用户利用 Hudi 将这种高效、成本优化的数据摄取到原始/铜银表中。 Onehouse 的表管理服务可以直接在湖级别优化此数据的布局,以获得更好的查询性能。 然后用户可以使用 BigQuery、Redshift、Snowflake 等仓库引擎或 Databricks、AWS EMR、Presto 和 Trino 等湖引擎转换这些优化表。 然后将派生数据提供给最终用户,以构建个性化、近实时仪表板等数据应用程序。 Onetable 为用户提供了非常需要的可移植性,让他们可以根据自己的需求和成本/性能权衡来选择他们喜欢的查询引擎。 同时用户可以通过 Hudi 经验证的具有挑战性的变更数据捕获场景的效率以及 Onehouse 的表优化/管理服务来降低计算成本。

未来工作
数据空间中查询引擎、开源工具和新产品的格局在不断发展。 每年涌现的这些现有服务和新服务中的每一项都对这些表格格式提供了不同程度的支持。 Onetable 允许我们的客户使用任何与三种格式中的至少一种集成的服务,从而为他们提供尽可能多的选择。
Onehouse 致力于开源,其中包括 Onetable。 最初这将是为 Onehouse 客户保留的内部功能,因为我们会迭代设计和实施。 我们正在寻找来自其他项目和社区的合作伙伴来迭代这个共享的表标准表示,并最终为整个生态系统开源该项目。 例如当底层 Hudi 表发生变化时,Hudi 的目录同步表服务会增量维护此类目录元数据。 与 Onetable 的类似实现,将通过单个集成使不同引擎之间的元数据保持同步,从而为数据湖用户创造巨大的价值。