位置编码的区别:
相对位置编码和绝对位置编码是两种不同的位置编码方法。
绝对位置编码是一种基于位置嵌入的方法,其中每个位置都被分配了一个唯一的位置向量。这些向量是固定的,与输入序列的内容无关。这种编码方式对于处理较短的序列效果较好,但在处理长序列时可能会存在问题,因为序列的长度超过了模型能够处理的位置编码的范围。
相对位置编码是一种基于相对位置的方法,其中每个位置被编码为一个偏移量,表示该位置与其他位置之间的相对距离。相对位置编码可以通过在输入嵌入中添加额外的信息来实现。这种编码方式可以处理长序列,并且能够在不同的上下文中保持一定的一致性。
Transformers使用Position Encoding,使用sinusoidal函数
BERT和BART都换成了可学习的绝对位置嵌入 (absolute position embeddings)
T5改成了相对位置嵌入(relative position embeddings)
sinusoidal函数
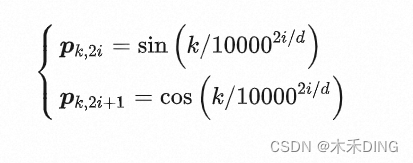
代码也就是:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
绝对位置编码
代码层面
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super(BertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None):
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
都是随机初始化的 nn.Embedding 词在神经网络中的向量表示。
介绍:
一个简单的查找表(lookup table),存储固定字典和大小的词嵌入。
此模块通常用于存储单词嵌入并使用索引检索它们(类似数组)。模块的输入是一个索引列表,输出是相应的词嵌入。
参数:
num_embeddings - 词嵌入字典大小,即一个字典里要有多少个词。
embedding_dim - 每个词嵌入向量的大小。
变量:
Embedding.weight(Tensor)–形状模块(num_embeddings,Embedding_dim)的可学习权重,初始化自(0,1)。
也就是说,pytorch的nn.Embedding()是可以自动学习每个词向量对应的w权重的。
class Embedding(Module):
def __init__(self, num_embeddings, embedding_dim, padding_idx=None):
super(Embedding, self).__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
# 构造一个num_embeddings x embedding_dim的可学习的权重矩阵
self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))
self.reset_parameters()
def reset_parameters(self):
# 初始化权重矩阵
nn.init.xavier_uniform_(self.weight)
def forward(self, input):
# 如果存在padding_idx,则将其嵌入向量设为0
if self.padding_idx is not None:
self.weight[self.padding_idx].zero_()
# 将输入张量中的每个整数标记替换为对应的向量嵌入
return F.embedding(input, self.weight, self.padding_idx, self.max_norm, self.norm_type, self.scale_grad_by_freq, self.sparse)
相对位置编码
参数式训练会受到句子长度的影响,bert起初训练的句子最长为512,如果只训练到128长度的句子,那在128—512之间的位置参数就无法获得,所以必须要训练更长的预料来确定这一部分的参数
在NAZHA中,距离和维度都是用正弦函数导出来的,并且在模型训练期间也是固定的。
绝对位置编码需要固定长度,一般是512,所以适用于短的
在处理较短的序列和数据集上,绝对位置编码可能会更加适用。而在处理长序列和数据集上,相对位置编码则可能会更加有效。
参考
https://zhuanlan.zhihu.com/p/369012642

![go 查询采购单设备事项[小示例]](https://img-blog.csdnimg.cn/cc4f4e917ae142e8ac7ed42331aaacae.png)