金翅大鹏盖世英,展翅金鹏盖世雄。
穿云燕子锡今鸽,踏雪无痕花云平。
---------------- 本文密钥:338 -----------------
本文描述了在macbook pro的macos上安装hadoop3的过程,也可以作为在任何类linux平台上安装hadoop3借鉴。
1、准备工作
确保已安装jdk,本地已安装jdk1.8.0_221。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_221.jdk/Contents/Home/
下载Hadoop-3.0.0:
https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
放到安装目录,我使用的是:/user/local/
解压:tar zxf hadoop-3.0.0.tar.gz
方便后续维护,建立符号链接:ln -s hadoop-3.0.0 hadoop
2、在~/.bashrc文件中配置HADOOP_HOME
export HADOOP_HOME=/user/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME3、配置本地ssh免密登录
ssh localhost # 若成功,则已配置,跳过
cd ~/.ssh
# 生成秘钥文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 将公钥文件加入授权文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#测试一下
ssh localhost4、修改core-site.xml
<confiquration>
<property>
<name>hadoop.tmp.dir</name>
<value>/user/local/hadoop/tmp</value>
<description>A base for other temporary directories<description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>5、修改mapred-site.xml
<configuration>
<property>
<name>mapredjob.tracker</name>
<value>localhost:9010</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6、修改hdfs-site.xml
<configuration>
<!--伪分布式配置-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>7、修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--集群配置-->
<!--<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>-->
</configuration>8、修改hadoop-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_221.jdk/Contents/Home/
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
# Under certain conditions, Java on OS X will throw SCDynamicStore errors
# in the system logs.
# See HADOOP-8719 for moreinformation. If one needs Kerberos
# support on 0S Xone will want to change/remove this extra bit
case ${HADOOP_OS_TYPE} in
Darwin*)
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.realm= "
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.kdc= "
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.conf= "
;;
esac9、启动
cd $HADOOP_HOME
# 格式化namenode
./bin/hdfs namenode -format
./sbin/start-all.sh成功:
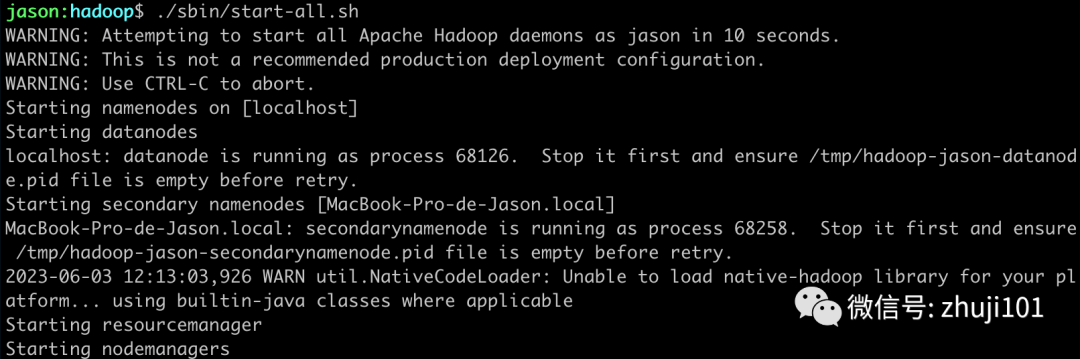
检查jps:
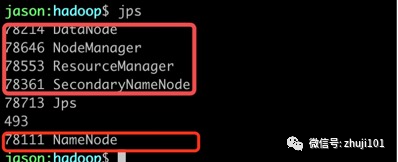
检查管理页面:
Hadoop管理页面:http://localhost:8088/cluster
NameNode:http://localhost:9870/
DataNode:http://localhost:9864/
HDFS目录:http://localhost:9870/explorer.html#/
相关问题
问题1:启动时start-all.sh出现错误
错误:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方法:
需要下载hadoop源码包:hadoop-3.0.0-src.tar.gz,重新编译后,将安全库拷贝到hadoop目录中:
tar zxf hadoop-3.0.0-src.tar.gz
cd hadoop-3.0.0-src
mvn package -Pdist,native -DskipTests -Dtar -Dmaven.javadoc.skip=true
# 成功后
cp ./hadoop-common-project/hadoop-common/target/native/target/usr/local/lib/libhadoop.* ../hadoop-3.0.0/lib/native/
cd ../hadoop-3.0.0问题2:启动时namenode错误
WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /user/local/hadoop/tmp/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible
解决方法:
执行一下格式化namenode命令:
./bin/hdfs namenode -format
其他错误如目录权限等问题,具体情况具体分析。