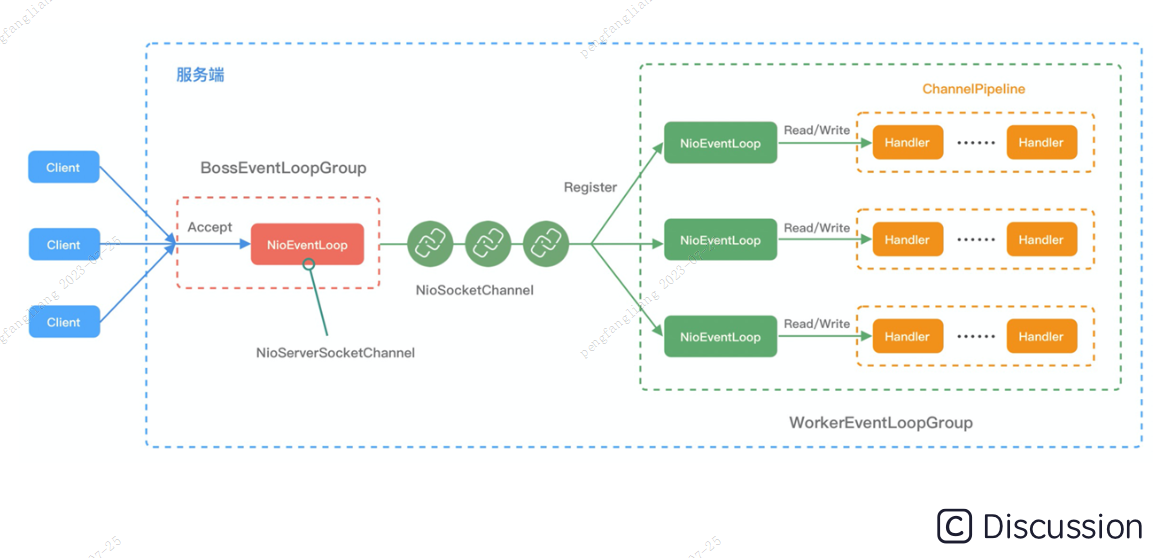
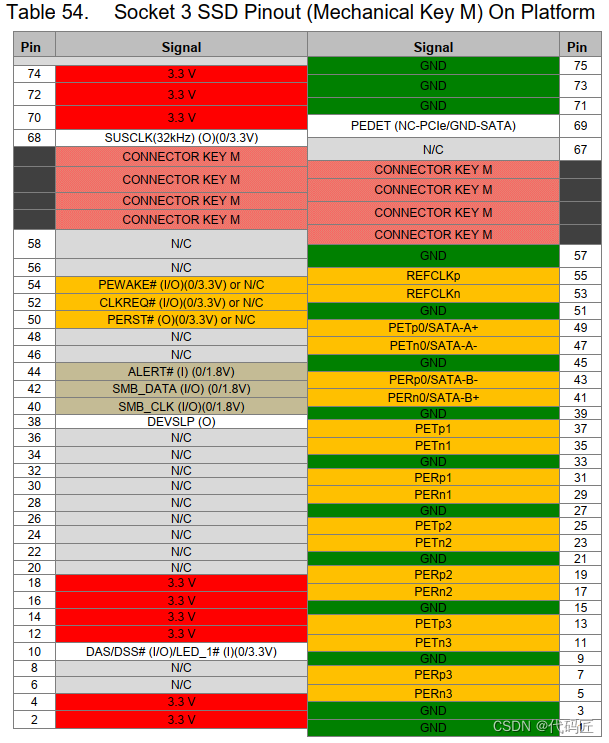
文章目录
- 1、概述
- 2、方法实验
- 主要贡献
- 框架概述
- 3、实验结果
- 比较方法
- 实验结果
- 忘却完整性
- 忘却效率
- 模型实用性
- 4、总结
原文链接: Federated Unlearning via Active Forgetting
1、概述
对机器学习模型隐私的⽇益关注催化了对机器学习的探索,即消除训练数据对数学学习模型影响的过程。这种担忧也出现在联邦学习领域,促使研究⼈员解决联邦遗忘学习问题。然⽽,联邦遗忘仍然具有挑战性。现有的遗忘⽅法⼤致可分为两种⽅法,即精确遗忘和近似遗忘。⾸先,以分布式⽅式实现精确遗忘(通常依赖于分区聚合框架)在理论上不会提⾼时间效率。其次,现有的联邦(近似)遗忘⽅法存在不精确的数据影响估计、⼤量的计算负担或两者兼⽽有之的问题。为此,该论文提出了⼀种基于增量学习的新型联邦遗忘框架,该框架独⽴于特定模型和联邦设置。本论文中的框架不同于现有的联合联邦⽅法,后者依赖于近似的再训练或数据影响估计。相反,本论文提出的方法利⽤新的记忆来覆盖旧的记忆,模仿神经病学中主动遗忘的过程。具体来说,该模型旨在遗忘,充当学⽣模型,不断从随机启动的教师模型中学习。为了防止灾难性地遗忘非⽬标数据,论文中利⽤弹性权重整合来弹性约束权重变化。在三个基准数据集上的⼤量实验证明了论文中提出的⽅法的有效性。后门攻击的结果表明,所提⽅法实现了令⼈满意的完备性。
2、方法实验
在本⽂中,论文中提出了⼀种新颖的联邦遗忘⽅法,称为FedAF,它独⽴于特定模型和联邦设置。如图 1 所示,与流⾏的遗忘⽅法相⽐,FedAF从神经病学中的主动遗忘中汲取灵感,使⽬标模型(即意图忘记的客户中的模型)能够使⽤新记忆来覆盖旧记忆。这允许⽆缝的遗忘过程集成到原始的联邦学习过程中,从根本上克服了现有联合遗忘⽅法的局限性,⽽⽆需存储历史更新或估计数据影响。
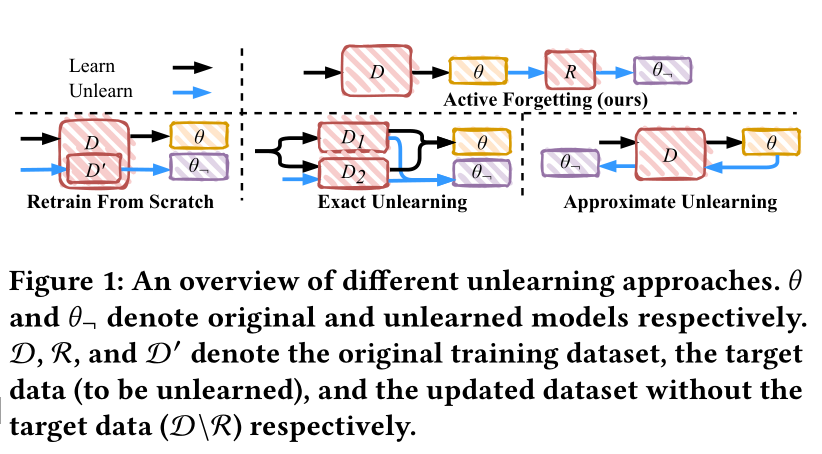
当使⽤增量学习来摒弃学习时,需要考虑两个关键点:
(i)产⽣有效的新记忆,以及
(ii)克服灾难性的遗忘。
FedAF由两个模块组成,即记忆⽣成器和知识保存器,分别⽤于解决这些问题。⾸先,我们需要⽣成⽆知识且易于学习的新记忆来覆盖旧记忆。无知识意味着不包含关于数据的有效信息,例如随机标签向量。同时,新的记忆必须易于学习,这样就不会花费⼤量的计算开销来完成忘却。记忆⽣成器遵循师⽣学习模式来⽣成假标签并将其与原始特征配对。其次,以前的研究发现,由于灾难性遗忘现象,传统的深度学习⽅法⽆法解决增量学习问题。
主要贡献
• 论文中提出了⼀种新的联邦遗忘⽅法,即基于主动遗忘概念的FedAF,从根本上克服了现有联邦遗忘⽅法的局限性。
• 为了有效地产⽣新的记忆来覆盖旧的记忆,论文中采⽤了师⽣学习模式。⽬标客户端(即学⽣)中的模型从教师模型⽣成的操纵数据中提取知识。
• 为了缓解非目标数据的灾难性遗忘现象,论文中⾸先推导新的损失来解决任务冲突问题,然后⽤弹性权重固结动态约束模型参数的变化。
•论文中对三个基准数据集进⾏了⼴泛的实验,以评估FedAF的性能。结果表明,论文中提出的FedAF在效率、效用和完整性⽅⾯优于同类⽅法。
框架概述
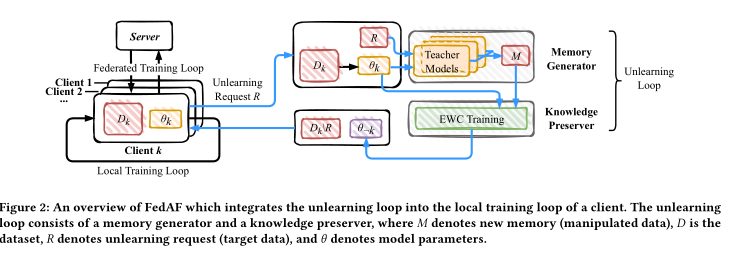
框架概述 FedAF 从新的记忆中学习以实现遗忘。新内存不包含⽬标数据的有效知识,这可能会覆盖旧数据。图 2 显示了FedAF 的学习(⿊⾊箭头)和取消学习(蓝⾊箭头)⼯作流程。在学习⼯作流程中,FedAF 既不会⼲扰原始的联邦学习过程,也不会存储任何历史更新。我们可以将原始的联邦学习过程压缩为两个循环,即本地训练循环和联合训练循环。在取消学习⼯作流中,FedAF在本地训练循环中插⼊⼀个取消学习循环,然后通过联合训练循环⼴播未学习的更新。FedAF中的忘却循环由两个模块组成,即记忆⽣成器和知识保存器。这两个模块分别解决了上述问题,即产⽣有效的新记忆和克服灾难性遗忘。通常,记忆⽣成器初始化⼀组教师模型以⽣成假标签,然后将它们与原始特征配对以⽣成操作数据。知识保存者在操纵的数据上不断训练模型。借助源⾃EWC框架的新损失函数,知识边缘保护器设法缓解灾难性遗忘现象。
记忆生成器 记忆⽣成器的⽬标是产⽣⽆知识且易于学习的新记忆以进⾏覆盖。在本⽂中,论文中重点关注在监督学习中,知识通常存在于标签中。因此,论文中操纵标签来产⽣新的记忆。
知识保存器 在取消学习⽬标数据的同时,我们还需要保存从非目标数据中学到的剩余知识。传统的深度学习⽅法在增量学习⼀系列任务时会遇到灾难性遗忘现象。为了模仿⼈脑中的主动遗忘,论文中提出的 FedAF 基于增量学习的理念。⽬标客户端𝑘顺序在两个任务上训练模型,即D𝑘和M。为了避免混淆,论文中直接通过其数据集来命名任务。任务 D𝑘 和 M 分别代表学习和忘却过程。当对后⼀个任务(即 M)进⾏训练时,会发⽣灾难性遗忘。新的记忆不仅会覆盖⽬标数据的旧记忆,还会使模型忘记⾮⽬标数据的记忆。因此,我们引⼊EWC培训来缓解这种现象。正如4.1节中介绍的,我们不改变学习过程,这意味着任务D𝑘采⽤常规训练。在本⽂中,我们以经验⻛险最⼩化为例。客户端𝑘通过最⼩化任务D𝑘的损失来优化模型𝜃
实验论文中基于三个原则(即遗忘完整性、遗忘效率和模型效⽤)评估了论文中提出的⽅法在三个⼴泛使⽤的数据集上的有效性。为了进⼀步研究论文中提出的⽅法,论文中还进⾏了消融研究。
3、实验结果
比较方法
论文中将提出的 FedAF 与两种适⽤于按类别遗忘的代表性遗忘⽅法进⾏⽐较。
• 重新训练:从头开始重新训练是计算开销很⼤的基本事实忘却⽅法。
• FRR :联邦快速再训练(FRR)是最先进的(SOTA)样本联邦取消学习⽅法,可应⽤于类别取消学习。
实验结果
忘却完整性
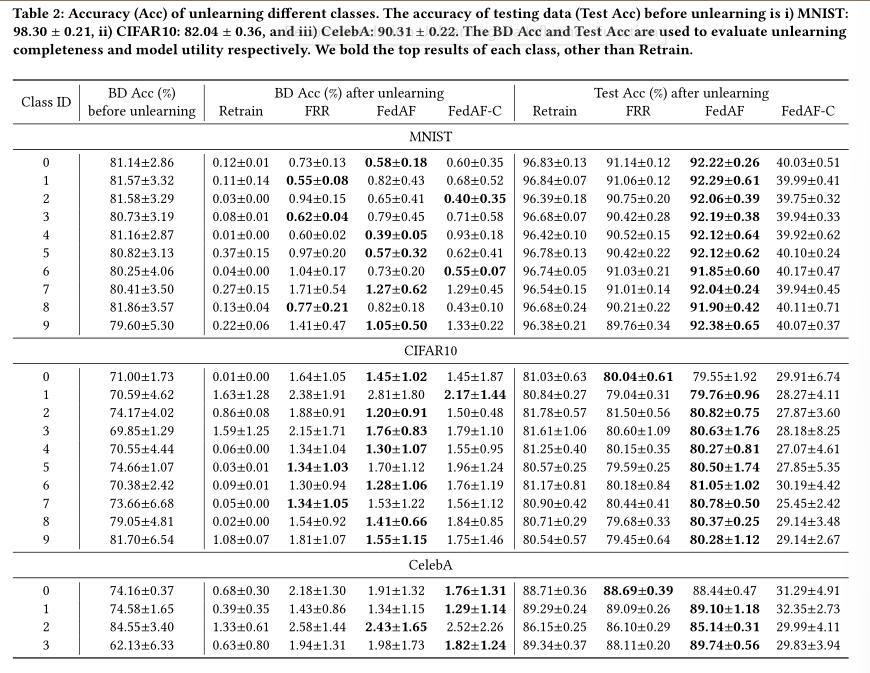
论文中利⽤后⻔攻击来评估遗忘的完整性。具体来说,论文中将后⻔触发器植⼊到论文中想要忘记的⽬标数据中,并将它们的标签翻转为随机类别。通过这个过程,后⻔攻击强制模型在触发模式和翻转标签之间建⽴映射。因此,我们可以通过⽐较取消学习前后⽬标数据的性能来评估取消学习的完整性。我们在表 2 中报告了未学习数据的ackDoor Accuracy(BD Acc)。从中,论文中得到以下观察结果:
i) 所有⽐较⽅法在取消学习后都显着降低了 BD Acc(平均从 76.21% 降⾄1.00%),表明⽬标数据的影响⼒显着降低;
ii) FRR 和FedAF ⽆法实现与Retrain ⼀样低的 BDAcc(忘记学习后)。与Retrain的BD Acc相⽐,FRR和FedAF平均分别提升了1.02%和0.90%;
iii) 在完整性⽅⾯的表现⽅⾯,FRR 和FedAF 之间仅存在微⼩差异。
总体⽽⾔,FedAF 在遗忘完整性⽅⾯略优于 SOTA ⽅法。
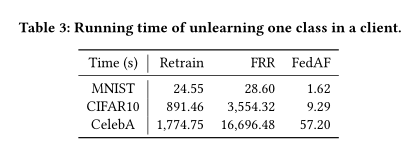
忘却效率
论文中使⽤运⾏时间来衡量⽐较⽅法的遗忘效率。具体来说,论文中在表 3 中报告了特定客户端中取消学习第⼀类的平均运⾏时间。如表 3 所示,论文中提出的 FedAF 平均将 Retrain 的效率提⾼了 39.51倍。相反,由于⽜顿优化器需要精确的计算,FRR 花费的时间明显多于Retrain。这是完全不可接受的,因为取消学习⽅法背后的设计理念是实现⽐重新训练更有效的取消学习。
模型实用性
保留模型效⽤也是联邦取消学习的⼀个重要原则。适当的遗忘⽅法应该避免过度消除⽬标数据的影响。因此,论文中通过评估模型在测试集上的性能来⽐较遗忘后模型的效⽤,并将结果报告在表2中。从中我们观察到所有⽐较的⽅法,即Retrain、FRR和FedAF,都达到了测试 Acc 接近于取消学习之前所达到的成绩。具体来说,以Retrain为基线,FRR和FedAF可以将其Test Acc与Retrain的差异分别限制在3.12%和2.31%以下,表明⾮⽬标数据没有明显的遗忘。
4、总结
在本⽂中,论文中提出了⼀种新的联邦遗忘⽅法,称为FedAF。受到神经病学主动遗忘的启发,FedAF通过利⽤新记忆覆盖旧记忆来取消学习,这从根本上克服了现有联合遗忘⽅法的局限性,⽽⽆需存储历史更新或估计数据影响。⼀般来说,我们基于增量学习的理念构建FedAF,以实现主动遗忘。具体来说,FedAF在每个客户端中由两个模块组成,即记忆⽣成器和知识保存器。记忆⽣成器根据师⽣学习产⽣⽆知识且易于学习的假标签,并将它们与⽬标数据特征配对以产⽣新的记忆。知识保存者不断⽤新的记忆训练模型,并采⽤EWC训练,利⽤论文中得出的损失来减轻灾难性的遗忘。⽬标客户端通过提交遗忘请求来触发这两个模块,⽽其他客户端则遵循标准训练过程。在三个基准数据集上进⾏的实验表明,论文中提出的FedAF不仅可以有效地从全局模型中解读特定客户的⽬标数据,还可以保留⾮⽬标数据的知识。