实现功能
利用limit 与 offset进行数据库数据批量查询与处理
实现代码
def query_batch(self,engine,batch_step,end,sql):
session = make_session(engine)
cursor = session.execute(sql.format(batch_step, end))
fields = cursor._metadata.keys
df = pd.DataFrame([dict(zip(fields, item)) for item in cursor.fetchall()])
print(len(df))
cursor.close()
session.close()
return df
# 批量查询并做表连接处理
sql1 = 'select count(*) from clusterAllReplicas (clickhouse, data_mgmt.gha_activity_2023_03)'
start=0
max_length = make_session(engine).execute(sql1).fetchall()[0][0]
batch_step = 5000000
result_df = pd.DataFrame()
for i in range(start, max_length, batch_step):
print(i)
print(batch_step, i)
df2 = query_batch(engine,batch_step, i,sql='select * from clusterAllReplicas (clickhouse, data_mgmt.gha_activity_2023_03) order by id limit {} offset {}')
# df2['repo_url'] = df2['repo.url'].map(lambda x: Object2.string_extraction(x))
temp_df = merge_data(df1, df2)
if len(temp_df):
result_df = result_df.append(temp_df)
print(len(result_df))
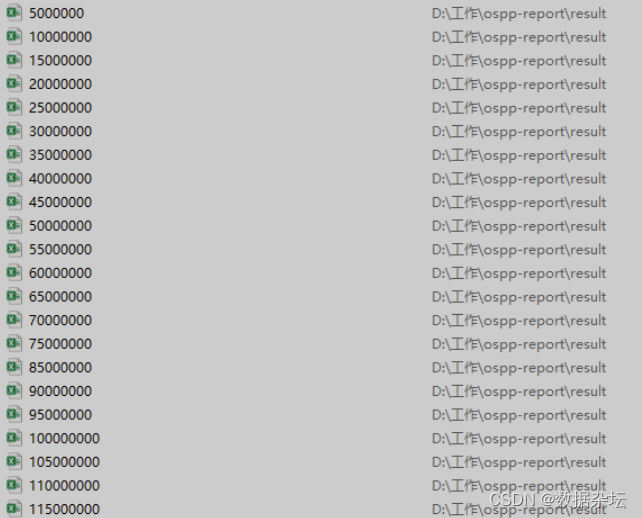
result_df.to_excel('D:\工作\ospp-report\\result\%d.xlsx' % i)实现效果
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注V订阅号:数据杂坛,联系我获取更多技能和源码。