Reinforcement Learning with Code
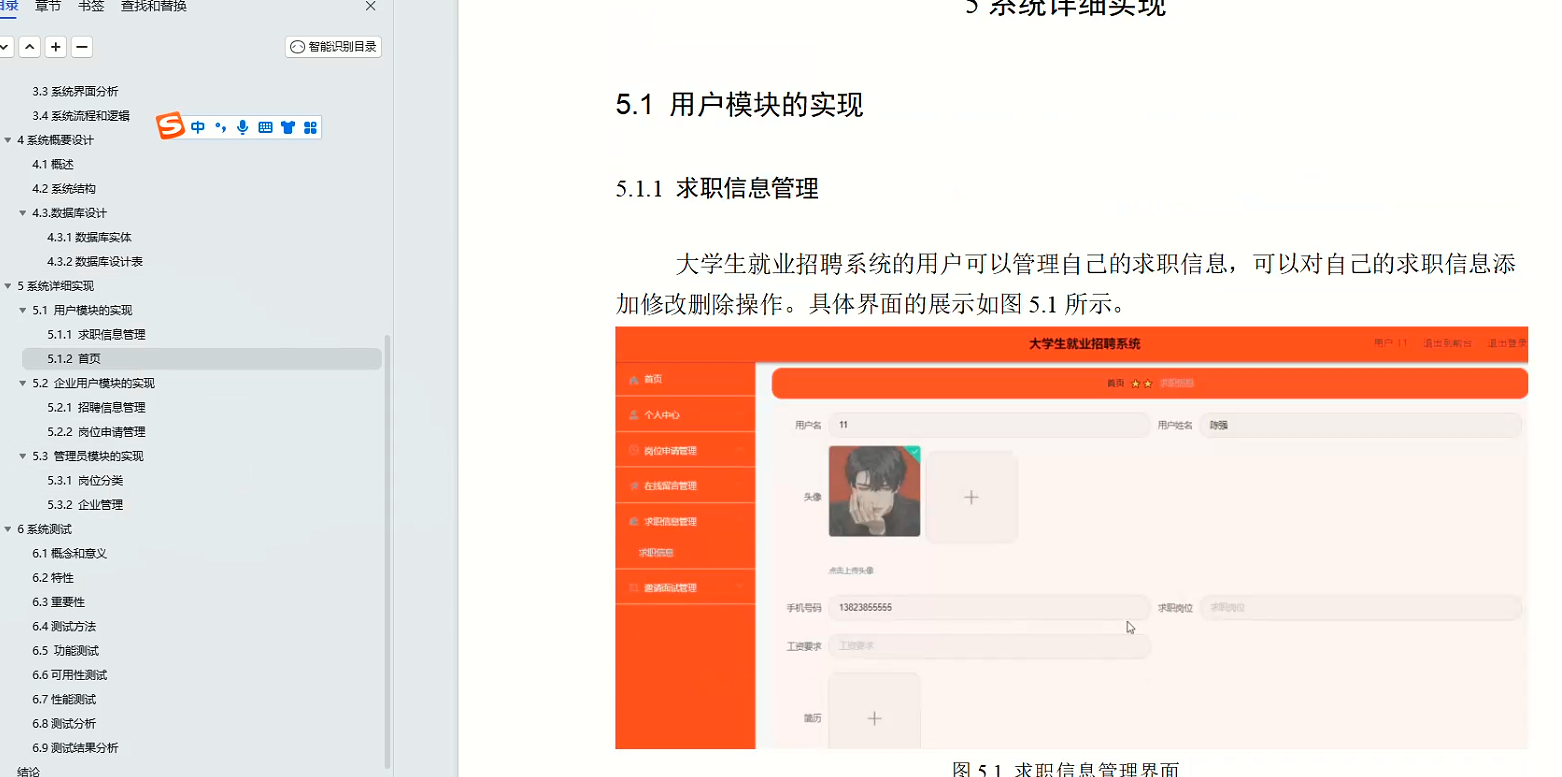
This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation of Reinforcement Learning, .
文章目录
- Reinforcement Learning with Code
- Chapter 8. Value Funtion Approximation
- 8.1 State value: MC/TD learning with function approximation
- 8.2 Action value: Sarsa with funtion approximation
- 8.3 Optimal action value: Q-learning with function approximation
- 8.4 Deep Q-learning (DQN)
- Reference
Chapter 8. Value Funtion Approximation
As so far in this note, state and action values are represented in tabular fashion. There are two problems that first although tabular representation is intuitive, it would encounter some problems when the state action space is large. Second since the value of a state is updated only if it is visited, the values of unvisited states cannot be estimated.
We can sovle the problems using a parameterized function v ^ ( s , w ) \hat{v}(s,w) v^(s,w) to approximate the value funtion, where w ∈ R m w\in\mathbb{R}^m w∈Rm is the parameter vector. On the one hand, we only need to store the parameter w w w instead of all states s s s, which is much smaller. On the other hand, when a state s s s is visited, the parameter w w w is updated so that the values of some other unvisited states can also be estimated.
We usually use neural network to approximate the value function. This problem basically is a regression problem. We can find the optimal parameter w w w by minimize some objective funtions, which we will introduce next.
8.1 State value: MC/TD learning with function approximation
Let
v
π
(
s
)
v_\pi(s)
vπ(s) and
v
^
(
s
,
w
)
\hat{v}(s,w)
v^(s,w) be the true value and approximated state value of
s
∈
S
s\in\mathcal{S}
s∈S. The objective funtion considered in value function approximation is usually
J
(
w
)
=
E
[
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
2
]
\textcolor{red}{J(w) = \mathbb{E}\Big[ \big( v_\pi(S)-\hat{v}(S,w) \big)^2 \Big]}
J(w)=E[(vπ(S)−v^(S,w))2]
which is also called mean square error in deep learning field. Where
S
,
S
′
S,S^\prime
S,S′ denote random variable of state
s
s
s.
Next, we discuss the distribution of random variable
S
S
S. We often use the stationary distribution, which describeds the long-run behavior of a Markov process. Let
{
d
π
(
s
)
}
s
∈
S
\textcolor{blue}{\{d_\pi(s)\}_{s\in\mathcal{S}}}
{dπ(s)}s∈S donte the stationary distribution of random variable
S
S
S. By definition,
d
π
(
s
)
≥
0
d_\pi(s)\ge 0
dπ(s)≥0 and
∑
s
∈
S
d
π
(
s
)
=
1
\sum_{s\in\mathcal{S}} d_\pi(s)=1
∑s∈Sdπ(s)=1. Hence, the objective funciton can be rewritten as
J
(
w
)
=
∑
s
∈
S
d
π
(
s
)
[
v
π
(
s
)
−
v
^
(
s
,
w
)
]
2
\textcolor{red}{J(w) = \sum_{s\in\mathcal{S}} d_\pi(s) \Big[v_\pi(s)-\hat{v}(s,w) \Big]^2}
J(w)=s∈S∑dπ(s)[vπ(s)−v^(s,w)]2
This objective function is a weighted squared error. How to compute the stationary distribution of random variable
S
S
S? We often use the equation
d
π
T
=
d
π
T
P
π
d_\pi^T = d_\pi^T P_\pi
dπT=dπTPπ
As a result,
d
π
d_\pi
dπ is the left eigenvector of
P
π
P_\pi
Pπ associated with the eigenvalue of
1
1
1. The proof is omitted.
Recall the spirit of gradient descent (GD). We can use it to minimize the objective function as
w
k
+
1
=
w
k
−
α
k
∇
w
E
[
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
2
]
=
w
k
−
α
k
E
[
∇
w
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
2
]
=
w
k
−
2
α
k
E
[
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
∇
w
(
−
v
^
(
S
,
w
)
)
]
=
w
k
+
2
α
k
E
[
v
π
(
S
)
−
v
^
(
S
,
w
)
∇
w
v
^
(
S
,
w
)
]
\begin{aligned} w_{k+1} & = w_k - \alpha_k \nabla_w \mathbb{E}\Big[ (v_\pi(S)-\hat{v}(S,w))^2 \Big] \\ & = w_k - \alpha_k \mathbb{E} \Big[ \nabla_w(v_\pi(S)-\hat{v}(S,w))^2 \Big] \\ & = w_k - 2\alpha_k \mathbb{E}\Big[ (v_\pi(S)-\hat{v}(S,w)) \nabla_w(-\hat{v}(S,w)) \Big] \\ & = w_k + 2\alpha_k \mathbb{E} \Big[v_\pi(S)-\hat{v}(S,w) \nabla_w\hat{v}(S,w) \Big] \end{aligned}
wk+1=wk−αk∇wE[(vπ(S)−v^(S,w))2]=wk−αkE[∇w(vπ(S)−v^(S,w))2]=wk−2αkE[(vπ(S)−v^(S,w))∇w(−v^(S,w))]=wk+2αkE[vπ(S)−v^(S,w)∇wv^(S,w)]
where without loss of generality the cofficient 2 before
α
k
\alpha_k
αk can be dropped. By the spirit of stochastic gradient descent (SGD), we can remove the expectation operation to obtain
w
t
+
1
=
w
t
+
a
t
(
v
π
(
s
t
)
−
v
^
(
s
t
,
w
t
)
)
∇
w
v
^
(
s
t
,
w
t
)
w_{t+1} = w_t + a_t (v_\pi(s_t) - \hat{v}(s_t,w_t))\nabla_w \hat{v}(s_t,w_t)
wt+1=wt+at(vπ(st)−v^(st,wt))∇wv^(st,wt)
However this equation can’t be implemented. Because it requires the true state value
v
π
v_\pi
vπ, which is the unknown to be esitmated. Hence, we can use the idea of Monte Carlo or TD learning to estimate it.
By Monte Carlo learning spirit, we can use the
g
t
g_t
gt to denote the discounted return that
g
t
=
r
t
+
1
+
γ
r
t
+
2
+
γ
2
r
t
+
3
+
⋯
g_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots
gt=rt+1+γrt+2+γ2rt+3+⋯
Then,
g
t
g_t
gt can be used as an approximation of
v
π
(
s
)
v_\pi(s)
vπ(s). The algorithm becomes
w
t
+
1
=
w
t
+
a
t
(
g
t
−
v
^
(
s
t
,
w
t
)
)
∇
w
v
^
(
s
t
,
w
t
)
w_{t+1} = w_t + a_t (\textcolor{red}{g_t} - \hat{v}(s_t,w_t))\nabla_w \hat{v}(s_t,w_t)
wt+1=wt+at(gt−v^(st,wt))∇wv^(st,wt)
By TD learning spirit, we can use the
r
t
+
1
+
γ
v
^
(
s
t
+
1
,
w
t
)
r_{t+1}+\gamma \hat{v}(s_{t+1},w_t)
rt+1+γv^(st+1,wt) as the approximation of
v
π
(
s
)
v_\pi(s)
vπ(s). The algorithm becomes
w
t
+
1
=
w
t
+
a
t
(
r
t
+
1
+
γ
v
^
(
s
t
+
1
,
w
)
−
v
^
(
s
t
,
w
t
)
)
∇
w
v
^
(
s
t
,
w
t
)
w_{t+1} = w_t + a_t (\textcolor{red}{r_{t+1}+\gamma \hat{v}(s_{t+1},w)} - \hat{v}(s_t,w_t))\nabla_w \hat{v}(s_t,w_t)
wt+1=wt+at(rt+1+γv^(st+1,w)−v^(st,wt))∇wv^(st,wt)
Pesudocode:

8.2 Action value: Sarsa with funtion approximation
To seach for optimal policies, we need to estimate action values. This section introduces how to estimate action values using Sarsa in the presence of value function approximation.
The action value
q
π
(
s
,
a
)
q_\pi(s,a)
qπ(s,a) is described by a function
q
^
(
s
,
a
,
w
)
\hat{q}(s,a,w)
q^(s,a,w) parameterized by
w
w
w. The objective funtion considered in action value approximation is usually selected as
J
(
w
)
=
E
[
(
q
π
(
S
,
A
)
−
q
^
(
S
,
A
,
w
)
)
2
]
\textcolor{red}{J(w) = \mathbb{E}[(q_\pi(S,A) - \hat{q}(S,A,w))^2]}
J(w)=E[(qπ(S,A)−q^(S,A,w))2]
Use the stochasitic gradient descent to minimize the objective function
w k + 1 = w k − α k ∇ w E [ ( q π ( S , A ) − q ^ ( S , A , w ) ) 2 ] = w k + 2 a k E [ q π ( S , A ) − q ^ ( S , A , w ) ] ∇ w q ^ ( S , A , w ) = w k + α k ( q π ( s , a ) − q ^ ( s , a , w ) ) ∇ w q ^ ( s , a , w ) \begin{aligned} w_{k+1} & = w_k - \alpha_k \nabla_w \mathbb{E}[(q_\pi(S,A) - \hat{q}(S,A,w))^2] \\ & = w_k + 2a_k \mathbb{E}[q_\pi(S,A) - \hat{q}(S,A,w)]\nabla_w \hat{q}(S,A,w) \\ & = w_k + \alpha_k (q_\pi(s,a) - \hat{q}(s,a,w))\nabla_w\hat{q}(s,a,w) \end{aligned} wk+1=wk−αk∇wE[(qπ(S,A)−q^(S,A,w))2]=wk+2akE[qπ(S,A)−q^(S,A,w)]∇wq^(S,A,w)=wk+αk(qπ(s,a)−q^(s,a,w))∇wq^(s,a,w)
where without loss of generality the cofficient 2 before α k \alpha_k αk can be dropped.
By Sarsa spirit, we use the
r
+
γ
q
^
(
s
′
,
a
′
,
w
)
r+\gamma \hat{q}(s^\prime,a^\prime,w)
r+γq^(s′,a′,w) to approximate ture action value
q
π
(
s
,
a
)
q_\pi(s,a)
qπ(s,a). Hence we have
w
k
+
1
=
w
k
+
α
k
(
r
+
γ
q
^
(
s
′
,
a
′
,
w
)
−
q
^
(
s
,
a
,
w
)
)
∇
w
q
^
(
s
,
a
,
w
)
w_{k+1} = w_k + \alpha_k (r+\gamma \hat{q}(s^\prime,a^\prime,w) - \hat{q}(s,a,w))\nabla_w\hat{q}(s,a,w)
wk+1=wk+αk(r+γq^(s′,a′,w)−q^(s,a,w))∇wq^(s,a,w)
The sampled data
(
s
,
a
,
r
k
,
s
k
′
,
a
k
′
)
(s,a,r_k,s^\prime_k,a^\prime_k)
(s,a,rk,sk′,ak′) is changed to
(
s
t
,
a
t
,
r
t
+
1
,
s
t
+
1
,
a
t
+
1
)
(s_t,a_t,r_{t+1},s_{t+1},a_{t+1})
(st,at,rt+1,st+1,at+1). Hence
w
t
+
1
=
w
t
+
α
t
[
r
t
+
1
+
γ
q
^
(
s
t
+
1
,
a
t
+
1
,
w
t
)
−
q
^
(
s
t
,
a
t
,
w
t
)
]
∇
w
q
^
(
s
t
,
a
t
,
w
t
)
w_{t+1} = w_t + \alpha_t \Big[ \textcolor{red}{r_{t+1}+\gamma \hat{q}(s_{t+1},a_{t+1},w_t)} - \hat{q}(s_t,a_t,w_t) \Big]\nabla_w \hat{q}(s_t,a_t,w_t)
wt+1=wt+αt[rt+1+γq^(st+1,at+1,wt)−q^(st,at,wt)]∇wq^(st,at,wt)
Pseudocode:

8.3 Optimal action value: Q-learning with function approximation
Similar to Sarsa, tabular Q-learning can also be extended to the case of value function approximation.
By the spirit of Q-learning, the update rule is
w
t
+
1
=
w
t
+
α
t
[
r
t
+
1
+
γ
max
a
∈
A
(
s
t
+
1
)
q
^
(
s
t
+
1
,
a
,
w
t
)
−
q
^
(
s
t
,
a
t
,
w
t
)
]
∇
w
q
^
(
s
t
,
a
t
,
w
t
)
w_{t+1} = w_t + \alpha_t \Big[ \textcolor{red}{r_{t+1}+\gamma \max_{a\in\mathcal{A}(s_{t+1})} \hat{q}(s_{t+1},a,w_t)} - \hat{q}(s_t,a_t,w_t) \Big]\nabla_w \hat{q}(s_t,a_t,w_t)
wt+1=wt+αt[rt+1+γa∈A(st+1)maxq^(st+1,a,wt)−q^(st,at,wt)]∇wq^(st,at,wt)
which is the same as Sarsa expect that
q
^
(
s
t
+
1
,
a
t
+
1
,
w
t
)
\hat{q}(s_{t+1},a_{t+1},w_t)
q^(st+1,at+1,wt) is replaced by
max
a
∈
A
(
s
t
+
1
)
q
^
(
s
t
+
1
,
a
,
w
t
)
\max_{a\in\mathcal{A}(s_{t+1})} \hat{q}(s_{t+1},a,w_t)
maxa∈A(st+1)q^(st+1,a,wt).
Pseudocode:

8.4 Deep Q-learning (DQN)
We can introduce deep neural networks into Q-learning to obtain deep Q-learning or deep Q-network (DQN).
Mathematically, deep Q-learning aims to minimize the objective funtion
J
(
w
)
=
E
[
(
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
)
−
q
^
(
S
,
A
,
w
)
)
2
]
\textcolor{red}{J(w) = \mathbb{E} \Big[ \Big( R+\gamma \max_{a\in\mathcal{A}(S^\prime)} \hat{q}(S^\prime, a, w) - \hat{q}(S,A,w) \Big)^2 \Big]}
J(w)=E[(R+γa∈A(S′)maxq^(S′,a,w)−q^(S,A,w))2]
where
(
S
,
A
,
R
,
S
′
)
(S,A,R,S^\prime)
(S,A,R,S′) are random variables representing a state, an action taken at that state, the immediate reward, and the next state. This objective funtion can be viewed as the Bellman opitmality error. That is because
q
(
s
,
a
)
=
E
[
R
t
+
1
+
γ
max
a
∈
A
(
S
t
+
1
)
q
(
S
t
+
1
,
a
)
∣
S
t
=
s
,
A
t
=
a
]
q(s,a) = \mathbb{E} \Big[ R_{t+1} + \gamma \max_{a\in\mathcal{A}(S_{t+1})} q(S_{t+1},a) | S_t = s, A_t= a \Big]
q(s,a)=E[Rt+1+γa∈A(St+1)maxq(St+1,a)∣St=s,At=a]
is the Bellman optimality equation in terms of action value.
Then we can use the stochastic gradient to minimize the objective funtion. However, it is noted that the parameter
w
w
w not only apperas in
q
^
(
S
,
A
,
w
)
\hat{q}(S,A,w)
q^(S,A,w) but also in
y
≜
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
)
y\triangleq R+\gamma \max_{a\in\mathcal{A}(S^\prime)}\hat{q}(S^\prime,a,w)
y≜R+γmaxa∈A(S′)q^(S′,a,w). For the sake of simplicity, we can assume that
w
w
w in
y
y
y is fixed (at least for a while) when we calculate the gradient. To do that, we can introduce two networks. One is a *main networ*k representing
q
^
(
s
,
a
,
w
)
\hat{q}(s,a,w)
q^(s,a,w) and the other is a target network
q
^
(
s
,
a
,
w
T
)
\hat{q}(s,a,w_T)
q^(s,a,wT). The objective function in this case degenerates to
J
(
w
)
=
E
[
(
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
T
)
−
q
^
(
S
,
A
,
w
)
)
2
]
J(w) = \mathbb{E} \Big[ \Big( R+\gamma \max_{a\in\mathcal{A}(S^\prime)} \hat{q}(S^\prime, a, w_T) - \hat{q}(S,A,w) \Big)^2 \Big]
J(w)=E[(R+γa∈A(S′)maxq^(S′,a,wT)−q^(S,A,w))2]
where
w
T
w_T
wT is the target network parameter and
w
w
w is the main network parameter. When
w
T
w_T
wT is fixed, the gradient of
J
(
w
)
J(w)
J(w) is
∇
w
J
=
−
2
∗
E
[
(
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
T
)
−
q
^
(
S
′
,
A
,
w
)
)
∇
w
q
^
(
S
,
A
,
w
)
]
\nabla_{w}J = -2*\mathbb{E} \Big[ \Big( R + \gamma \max_{a\in\mathcal{A}(S^\prime)} \hat{q}(S^\prime,a,w_T) - \hat{q}(S^\prime,A,w) \Big) \nabla_{w}\hat{q}(S,A,w) \Big]
∇wJ=−2∗E[(R+γa∈A(S′)maxq^(S′,a,wT)−q^(S′,A,w))∇wq^(S,A,w)]
There are two techniques should be noticed.
When the target network is fixed, using stochastic gradient descent (SGD) we can obtain
w
t
+
1
=
w
t
+
α
t
[
r
t
+
1
+
γ
max
a
∈
A
(
s
t
+
1
)
q
^
(
s
t
+
1
,
a
,
w
T
)
−
q
^
(
s
t
,
a
t
,
w
)
]
∇
w
q
^
(
s
t
,
a
t
,
w
)
\textcolor{red}{w_{t+1} = w_{t} + \alpha_t \Big[ r_{t+1} + \gamma \max_{a\in\mathcal{A}(s_{t+1})} \hat{q}(s_{t+1},a,w_T) - \hat{q}(s_t,a_t,w) \Big] \nabla_w \hat{q}(s_t,a_t,w)}
wt+1=wt+αt[rt+1+γa∈A(st+1)maxq^(st+1,a,wT)−q^(st,at,w)]∇wq^(st,at,w)
One technique is experience replay. This is, after we have collected some experience samples, we don’t use these samples in the order they were collected. Instead, we store them in a data set, called replay buffer, and draw a batch of samples randomly to train the neureal network. In particular, let
(
s
,
a
,
r
,
s
′
)
(s,a,r,s^\prime)
(s,a,r,s′) be an experience sample and
B
≜
{
(
s
,
a
,
r
,
s
′
)
}
\mathcal{B}\triangleq \{(s,a,r,s^\prime) \}
B≜{(s,a,r,s′)} be the replay buffer. Every time we train the neural network, we can draw a mini-batch of random samples from the reply buffer. The draw of samples, or called experience replay, should follow a uniform distribution.
Another technique is use two networks. A main network parameterized by w w w, and a target network parameterized by w T w_T wT. The two network parameters are set to be the same initially. The target output is y T ≜ r + γ max a ∈ A ( s ′ ) q ^ ( s ′ , a , w T ) y_T \triangleq r + \gamma \max_{a\in\mathcal{A}(s^\prime)}\hat{q}(s^\prime,a,w_T) yT≜r+γmaxa∈A(s′)q^(s′,a,wT). Then, we directly minimize the TD error or called loss function ( y − q ^ ( s , a , w , ) ) 2 (y-\hat{q}(s,a,w,))^2 (y−q^(s,a,w,))2 over the mini-batch { ( s , a , y T ) } \{(s,a,y_T)\} {(s,a,yT)} instead of a single sample to improve efficiency and stability.
The parameter of the main network is updated in every interation. By contrast, the target network is set to be the same as the main network every a certain number of iterations to meet the assumption that w T w_T wT is fixed when calculating the gradient.
Pseudocode:

Reference
赵世钰老师的课程


![c++学习(位图)[22]](https://img-blog.csdnimg.cn/cd0538fc9ab94a00967765c5592a4452.png)