项目简介
本文将对项目的功能及部分细节的实现进行介绍。个人随笔分享平台基于 SpringBoot + SpringMVC + MyBatis 实现。实现了用户的注册与登录、随笔主页、文章查询、个人随笔展示、个人随笔查询、写随笔、草稿箱、随笔修改、随笔删除、访问量及阅读量统计等功能。该项目登录模块对明文密码进行了加盐处理,并且将session使用Redis进行了持久化存储,为分布式的支持奠定了基础,同时,使用了统一功能处理与拦截器。
文章目录
- 项目简介
- 1 功能概览
- 2 主要功能展示
- 3 系统部分实现细节
- 3.1 草稿箱实现
- 3.2 分页查询
- 3.3 查询功能
- 3.4 随笔的修改与发布
- 3.5 随笔与草稿的删除
- 3.5 对随笔摘要的 markdown 标签处理
- 3.6 基于 MD5 的加盐算法处理明文密码
- 3.7 使用 Redis 持久化 Session
- 4 开发过程遇到的问题
- 4.1 Redis服务的远程连接问题与session持久化失败
- 4.2 查询功能url获取参数中文乱码问题
- 4.3 草稿箱内容出现在个人随笔页
- 写在最后
1 功能概览
以下是对个人随笔分享平台功能的表格整理:
| 功能 | 描述 |
|---|---|
| 登录功能 | 用户可以使用用户名和密码登录到平台。 |
| 注册功能 | 用户可以注册新的账户来访问平台。 |
| 个人信息展示 | 可以查看个人信息: 头像、昵称、访问量、文章数等。 |
| 个人随笔列表展示 | 用户可以查看自己发布的随笔列表。 |
| 查询个人随笔 | 用户可以根据关键字查询自己发布的随笔。 |
| 随笔主页分页查询功能 | 用户可以在随笔主页浏览所有用户的随笔,系统将用户的文章进行分页展示 |
| 查询随笔 | 用户可以根据关键字查询其他用户发布的随笔。 |
| 发布随笔功能 | 用户可以发布新的随笔。 |
| 随笔草稿箱 | 用户可以保存随笔的草稿,并在需要时进行编辑和发布。 |
| 随笔或草稿编辑功能 | 用户可以编辑已发布的随笔或草稿。 |
| 随笔详情展示 | 用户可以查看随笔的详细内容和相关信息。 |
| 随笔或草稿删除功能 | 用户可以删除已发布的随笔或草稿。 |
| 访问量与阅读量统计 | 平台可以统计每篇随笔的访问量和阅读量,并显示给用户。 |
2 主要功能展示
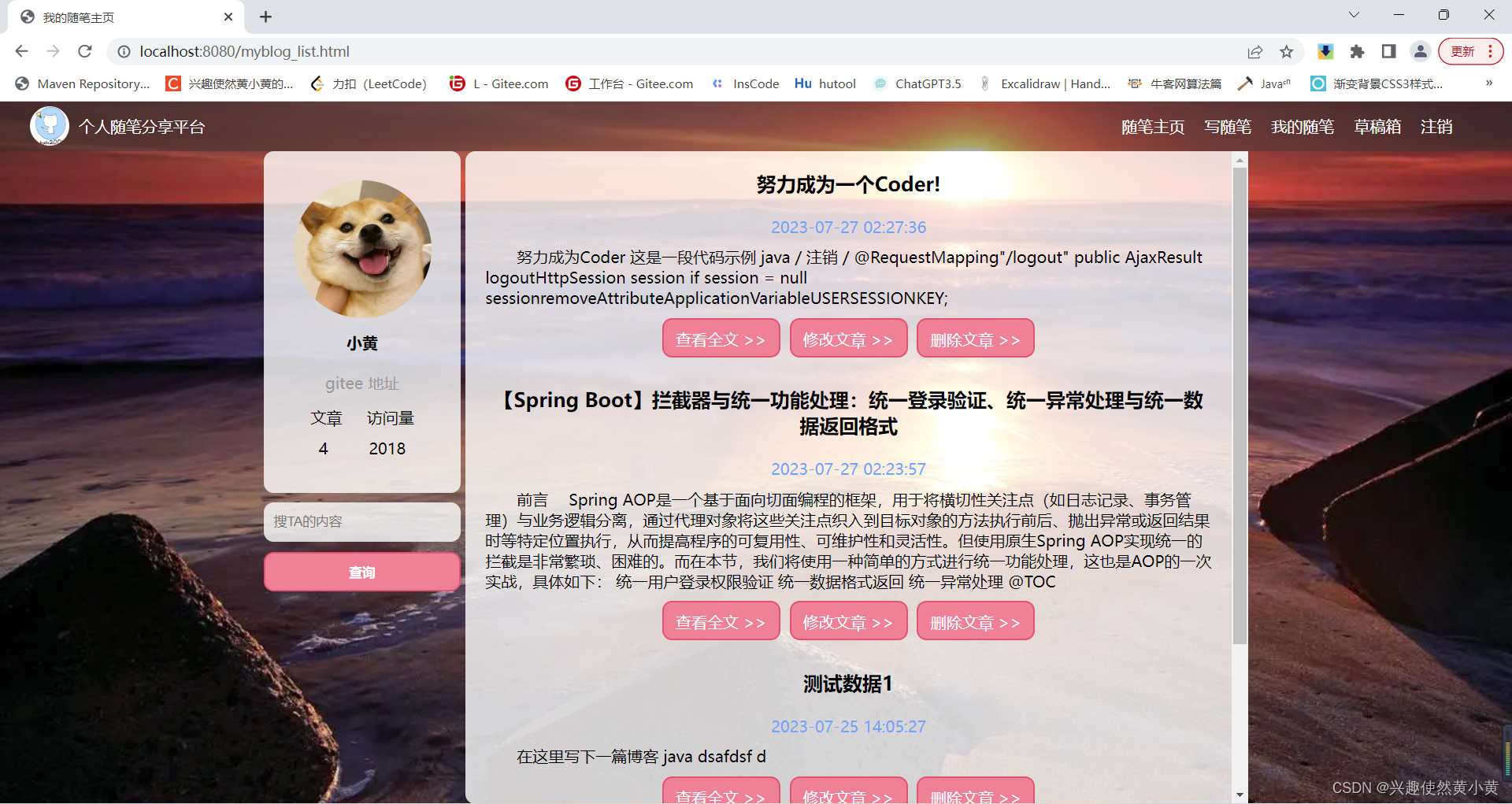
随笔主页
无论用户是否登录,都可以使用随笔主页。在该界面中,您可以查阅所有作者发布的内容。
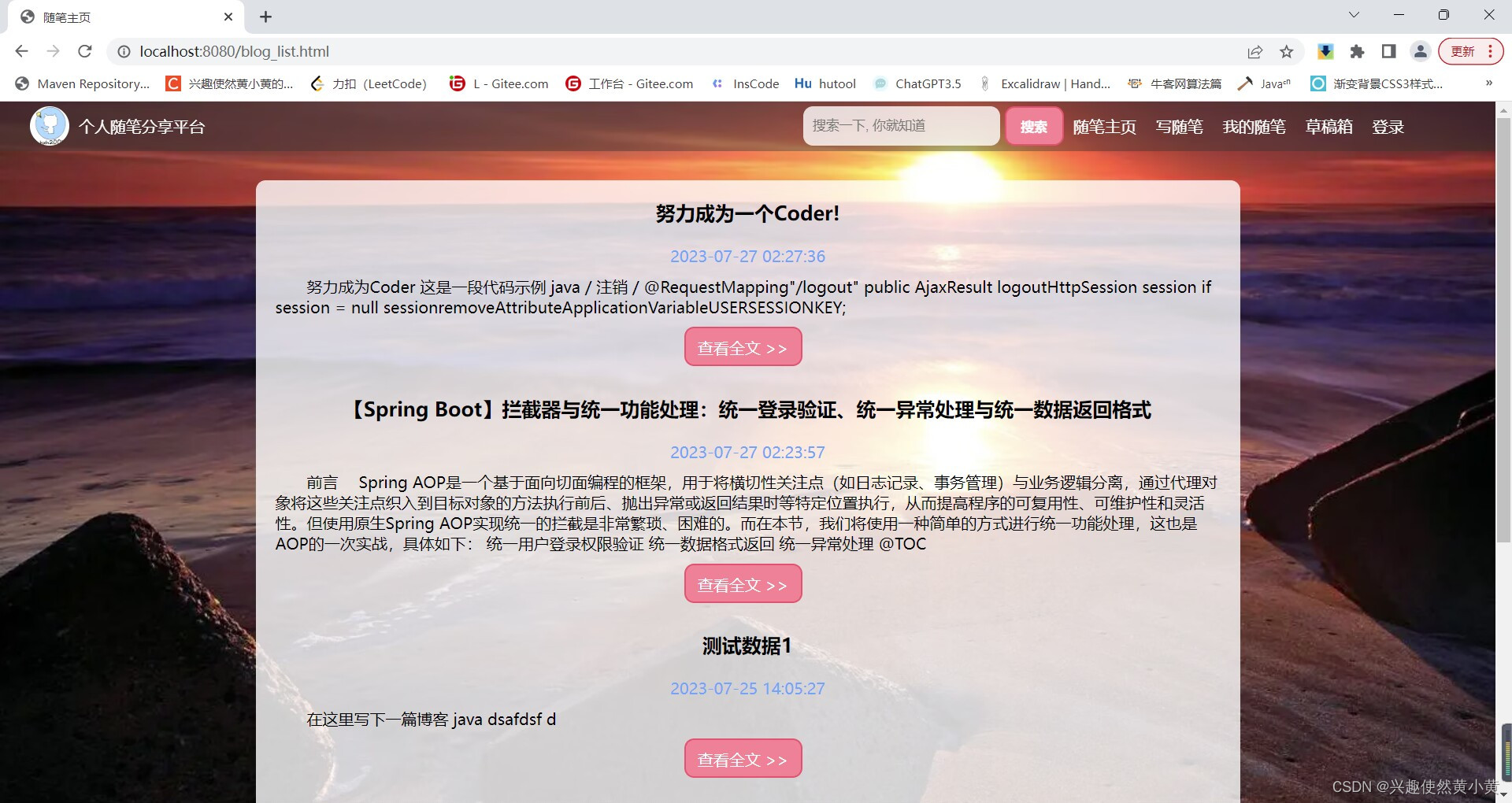
分页展示
在随笔主页,内容采用分页展示,默认每页展示的文章条数最大为5条,点击下一页等按钮可以进行页面内容切换。

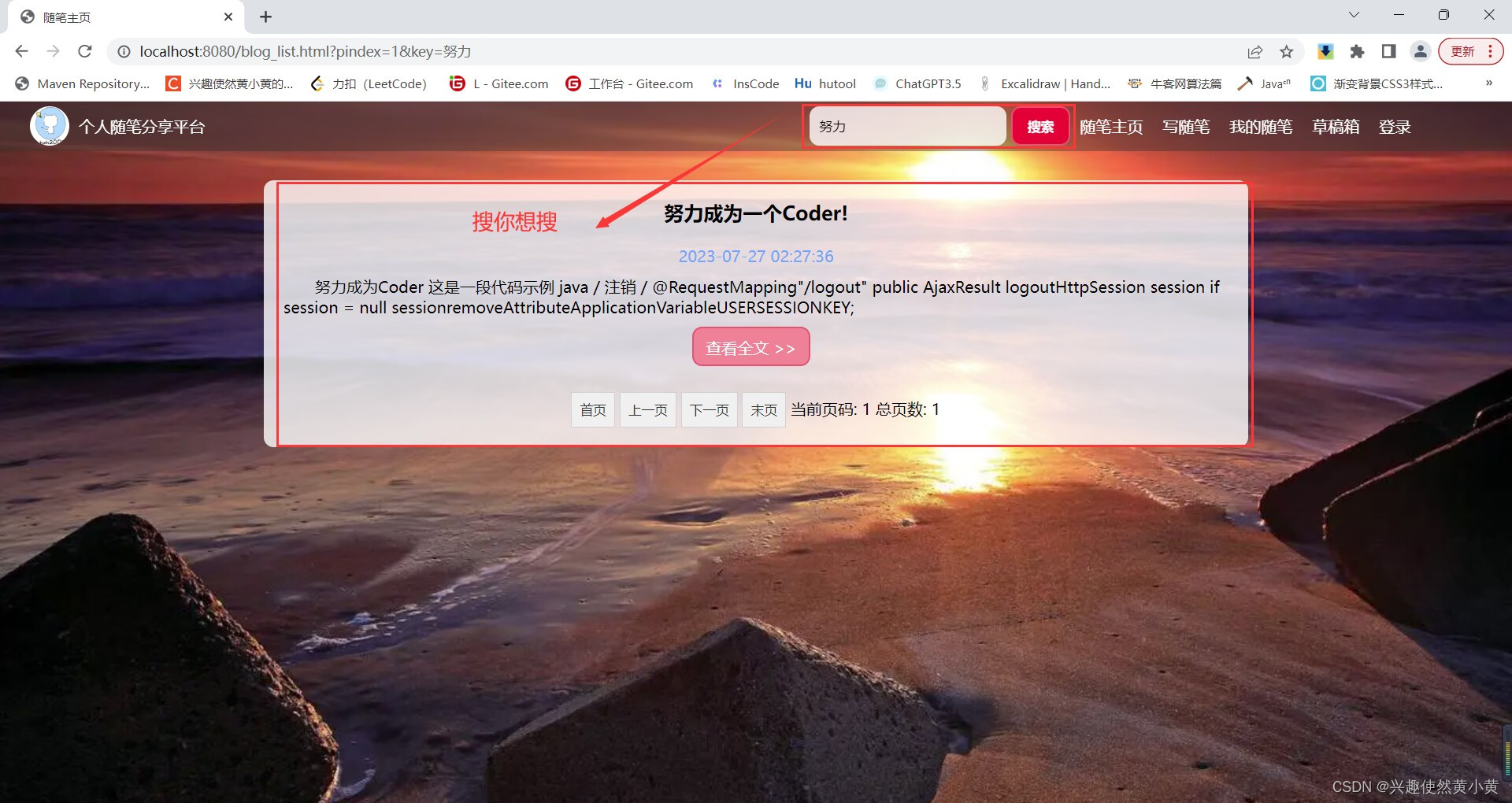
“搜你想搜”
在随笔主页,你可以使用搜索框搜索你想要查询的内容,系统会根据你给定的字段进行模糊匹配,检索系统中符合条件的文章,并同样以分页展示的形式呈现给你。
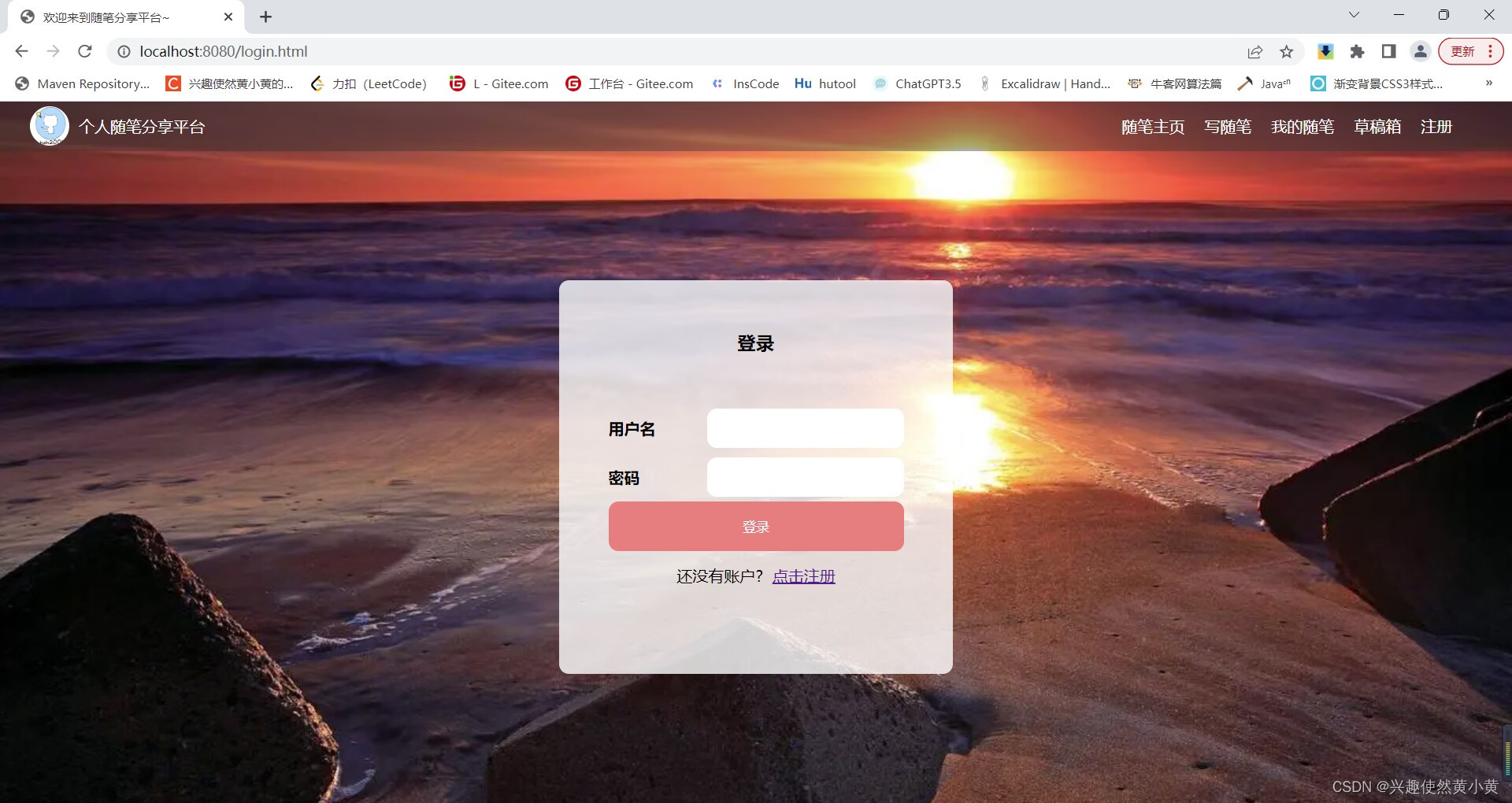
登录与注册模块
与大多数为用户提供服务的系统一样,该平台同样包含了注册与登录功能。未注册的用户通过登记相关信息可以成为平台的用户,平台的用户可以使用用户名和密码进入自己的随笔主页,同时也拥有了体验该平台完整功能的权利。需要注意的是,该平台暂未提供手机登录等“生产”级别的业务,如有需要,可自行扩展–比如可以使用某某云之类提供的接口扩展短信验证码等模块。
个人随笔列表展示
在该页面中,将展示您发布的所有随笔(草稿除外),您可以在该页面查看自己的信息(包括自己的头像、文章数量及总访问量),搜索自己的内容,或者选择查看、编辑、删除自己的随笔。

搜索TA的内容
在用户随笔主页中,可以在搜索框中输入想要搜索的内容,系统将模糊匹配您发布的文章是否有包含该字段的文章,如果有,将以列表的方式呈现给你。
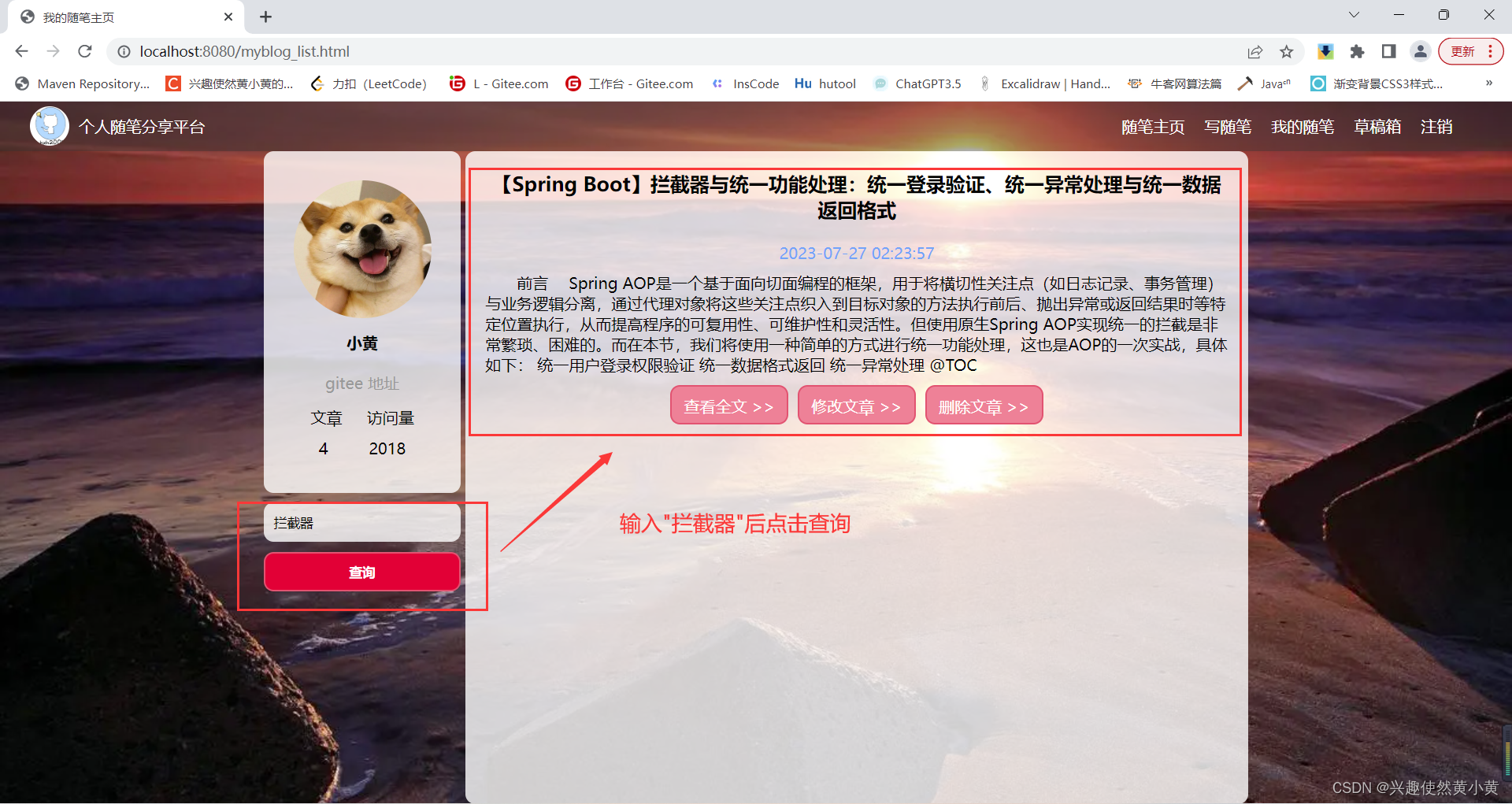
发布随笔与编辑随笔
你可以选择对应随笔进行编辑,或者点击写随笔按钮来新建一篇随笔。随笔的编辑与发布支持MarkDown语法。
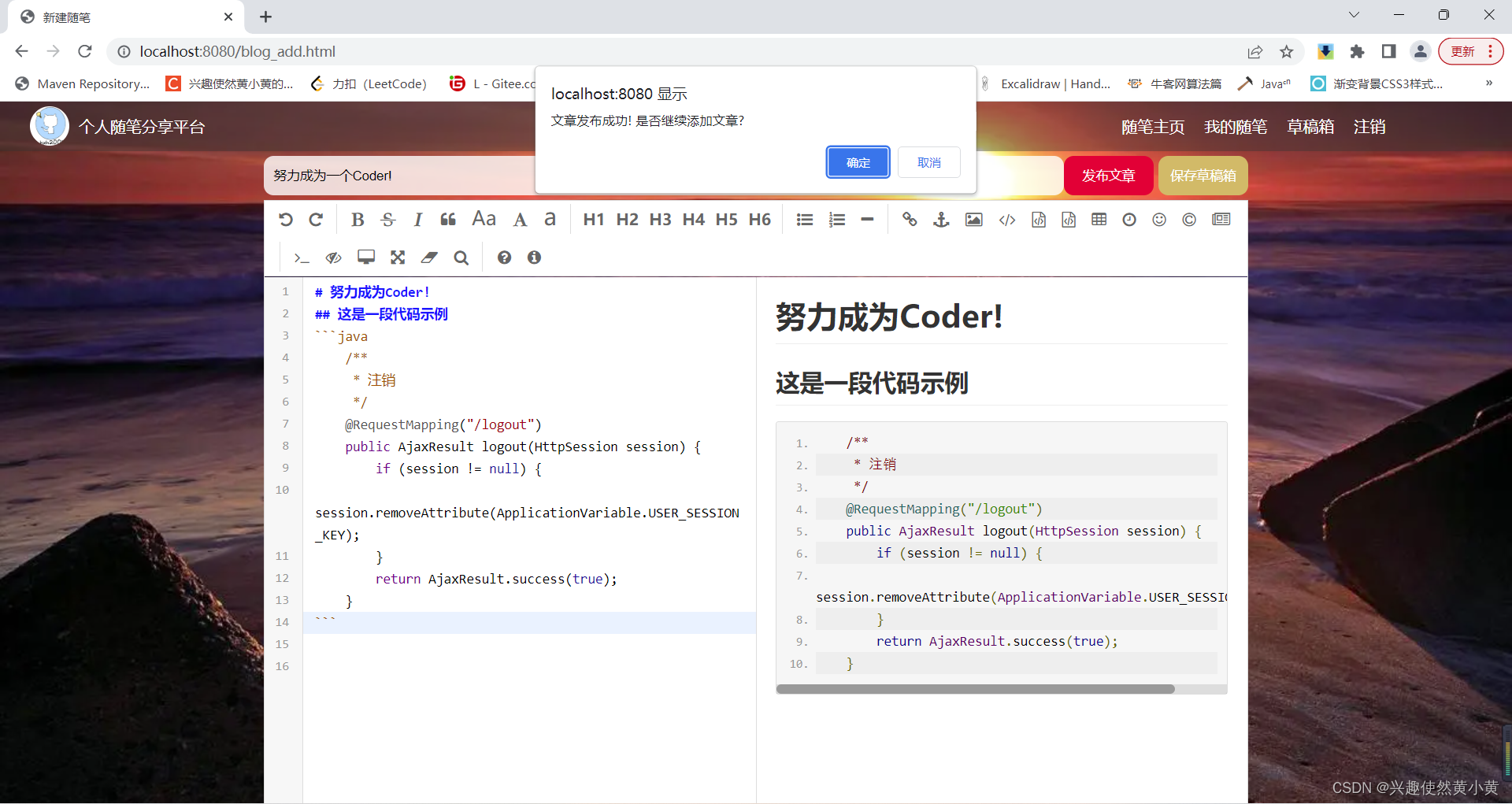
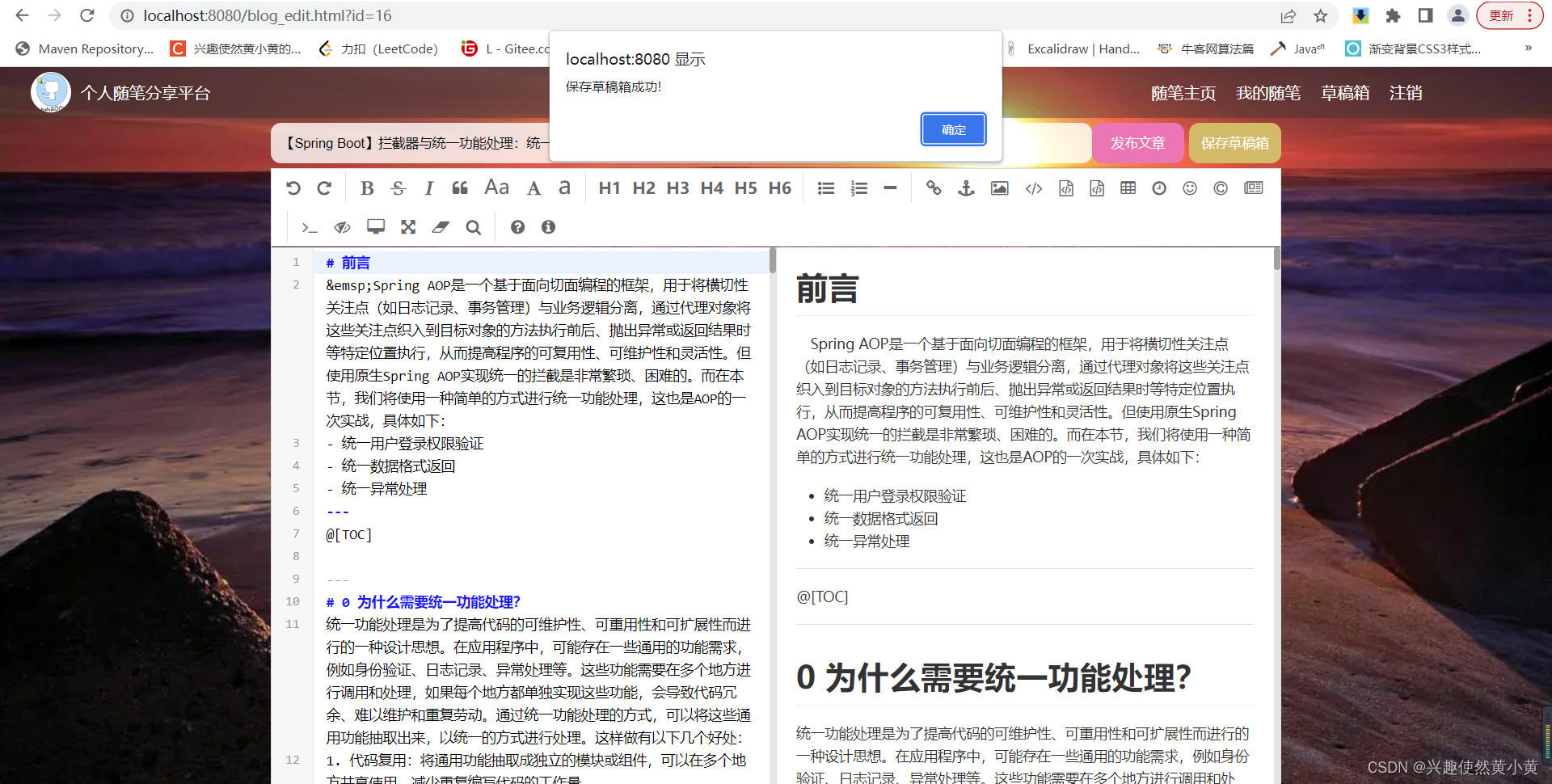
草稿箱模块
由于并不是每个人都有连续的时间,能够将一篇随笔写完发布后再去处理其他事情。因此,本系统提供了草稿箱功能,您可以将你编辑的内容先保存到草稿箱,等到您需要的时候进行发布、编辑或者删除。

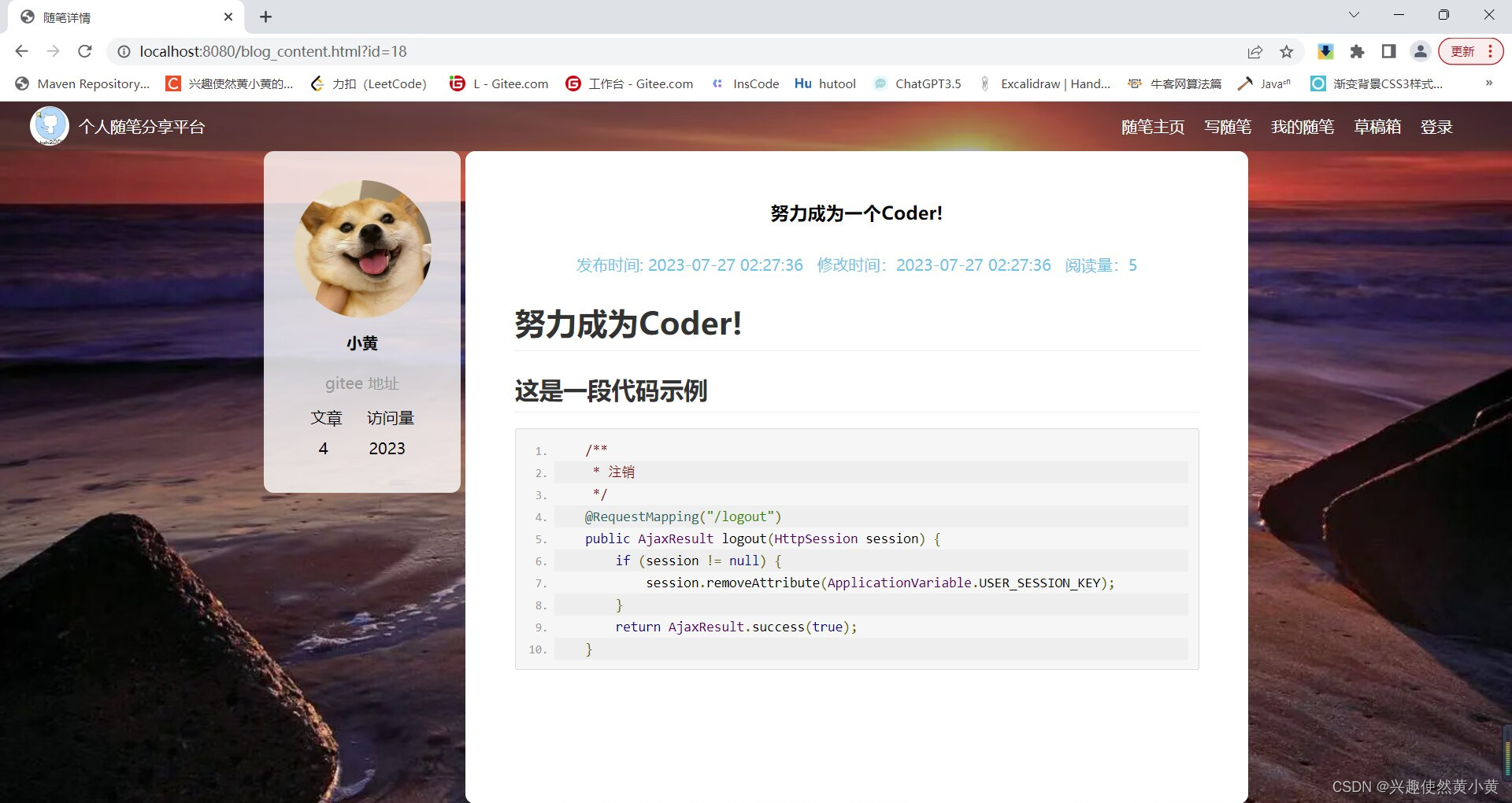
随笔详情展示
在随笔主页或者“我的随笔”页面,您可以通过点击查看全文按钮的方式查看随笔的全文内容。不仅如此,您还可以查阅本文的部分作者信息、文章的阅读量与发布时间修改时间等信息。
3 系统部分实现细节
3.1 草稿箱实现
本系统对于草稿箱的实现,实际是对文章的状态进行区分。在articleinfo文章表中,我们预留出了一个state字段,用于表示文章的状态:
- state = 1 : 正常的发布文章;
- state = 0 : 处于草稿箱的文章;
在进行个人随笔主页以及草稿箱页面展示文章信息,只需要对应展示该登录用户对应文章状态的文章即可。对于前端页面,对“发布文章”与“保存草稿”按钮的监听进行了区分:
- 点击发布文章按钮: 请求包含文章的标题、文章的内容和 state = 1;
- 点击保存草稿按钮: 请求同上,区别是 state = 0;
基于此构造 ajax 请求后端进行 insert 操作。
后端实现的核心代码:
/**
* 发布文章 state = 1 与保存草稿箱 state = 0
* 如果是保存草稿箱, 则请求的文章对象中 state = 0
* 更新了传入 createtime 和 updatetime 解决数据库不兼容问题
*/
@RequestMapping("/add")
public AjaxResult add(HttpServletRequest request, Articleinfo articleinfo) {
// 非空校验
if (articleinfo == null || !StringUtils.hasLength(articleinfo.getTitle()) ||
!StringUtils.hasLength(articleinfo.getContent())) {
return AjaxResult.fail(-1, "非法参数");
}
// 发布文章操作
// 得到当前用户的 uid
Userinfo userinfo = UserSessionUtils.getSessUser(request);
if (userinfo == null || userinfo.getId() <= 0) {
// 无效的登录用户
return AjaxResult.fail(-2, "无效的登录用户");
}
articleinfo.setUid(userinfo.getId()); // 设置作者 id
// 设置创建时间和更新时间, 解决数据库没有默认约束的情况
articleinfo.setCreatetime(LocalDateTime.now());
articleinfo.setUpdatetime(LocalDateTime.now());
// 添加数据库并返回
return AjaxResult.success(articleService.add(articleinfo));
}
3.2 分页查询
分页查询的实现涉及几个重要的因素:
- pIndex: 当前页码;
- pSize: 每页最多显示的文章条数。
而分页功能在 SQL 中的实现基于如下的 SQL:
select xxx from articleinfo
where xxx
limit pIndex offset offsetSize;
经过推导,我们可以得出如下映射关系:
offsetSize = (pIndex - 1) / pSize
对于 where 子句的内容,我们使用 Mybatis 的动态 SQL 进行处理。
而总页数需要通过对 文章总数 / 每页最大文章数 的结果进行向上取整,比如: ceil()进行处理。
同时,在前端页面,该平台使用的是拼接跳转的方式,点击下一页就将pIndex ++(需要对范围进行判断,防止越界),而每页结果在构造 ajax 请求发送给后端请求响应哦时候,就从 location.search 中获取请求参数中的 pindex。
后端核心代码如下:
/**
* 分页查询
* @param pIndex 当前页码
* @param pSize 每页最多显示的文章条数
* @param key 检索的 title
* @return 返回的 data 中包含一个 map, 含有当前页的文章列表与文章总数量
*/
@RequestMapping("/listbypage")
public AjaxResult getListByPage(@RequestParam("pindex") Integer pIndex,
@RequestParam("psize") Integer pSize,
@RequestParam("key") String key) {
// 参数校正
if (pIndex == null || pIndex < 1) {
pIndex = 1;
}
if (pSize == null || pSize <= 1) {
pSize = 3;
}
// 分页查询
int offSize = (pIndex - 1) * pSize;
List<Articleinfo> articleInfoList = articleService.getListByPage(pSize, offSize, key);
// 对摘要进行处理
for (Articleinfo articleinfo : articleInfoList) {
articleinfo.setContent(
MarkdownUtils.removeMarkdownTags(articleinfo.getContent(), 256));
}
// 获取文章总数
int totalArticleCount = articleService.getTotalArticleCount(key);
HashMap<String, Object> map = new HashMap<>();
map.put("articleInfoList", articleInfoList);
map.put("totalArticleCount", totalArticleCount);
return AjaxResult.success(map);
}
}
3.3 查询功能
查询功能主要通过 Mybaties 的动态 SQL 实现,在 *mapper.xml 的相应 select 语句中使用了 if 标签。如果前端构造请求的时候没有 key (即搜索框中没有内容),则默认返回的是当前页应该展示的文章列表或者是当前登录用户的所有文章列表。注意,这里所说的列表指的是正常发布的文章,对于草稿箱的内容,需要在草稿箱中查看。
后端核心代码如下
/**
* 加载用户的文章列表信息
* key: 搜索 title
* state: 0 草稿, 1 文章
*/
@RequestMapping("/mylist")
public AjaxResult getMyList(HttpServletRequest request, Integer state, String key) {
Userinfo userinfo = UserSessionUtils.getSessUser(request);
if (userinfo == null) {
return AjaxResult.fail(-1, "非法请求");
}
List<Articleinfo> list = articleService.getMyList(userinfo.getId(), state, key);
// 将 list 中每个文章信息对象的正文进行处理, 去除 markdown 标签并最多显示 256 个字符
for (Articleinfo articleinfo : list) {
String content = articleinfo.getContent();
content = MarkdownUtils.removeMarkdownTags(content,
ApplicationVariable.THE_MAXIMUM_NUMBER_OF_CHARACTERS_IN_THE_DIGEST);
articleinfo.setContent(content);
}
return AjaxResult.success(list);
}
3.4 随笔的修改与发布
随笔的修改与发布与草稿箱的实现模块类似,修改会先将文章id作为请求,请求后端返回当前文章内容,往后点击发布文章进行 update 操作。而发布文章则是 insert 操作。与草稿箱不同的是,这里的修改与发布所更新的 state 字段都是 1。
后端实现核心代码如下
/**
* 修改文章
* 只有当前登录用户是作者的情况下才能进行修改(验权)
*/
@RequestMapping("/update")
public AjaxResult update(HttpServletRequest request, Articleinfo articleinfo) {
// 非空检验
if (articleinfo == null || !StringUtils.hasLength(articleinfo.getTitle()) ||
!StringUtils.hasLength(articleinfo.getContent()) ||
articleinfo.getId() == null ||
articleinfo.getId() <= 0) {
return AjaxResult.fail(-1, "非法参数");
}
// 得到当前登录用户的 id
Userinfo userinfo = UserSessionUtils.getSessUser(request);
if (userinfo == null || userinfo.getId() == null || userinfo.getId() <= 0) {
return AjaxResult.fail(-2, "无效用户");
}
// 设置文章对象的 uid 为当前用户的 id, 便于 mapper 验证是否为当前登录用户
articleinfo.setUid(userinfo.getId());
articleinfo.setUpdatetime(LocalDateTime.now());
return AjaxResult.success(articleService.update(articleinfo));
}
3.5 随笔与草稿的删除
对于随笔与草稿的删除都是通过传给后端当前文章或草稿的 id 请求删除操作。同时,后端需要对当前登录用户进行验权,即判断当前登录用户是否为文章的作者。以解决当前登录用户注销后忘记关闭页面而另一个人登录后,由于session存在导致的误删误改的情况。
后端实现的核心代码如下
/**
* 删除文章
* 只有当前登录的用户是文章的作者才能删除(验权)
*/
@RequestMapping("/del")
public AjaxResult del(HttpServletRequest request, @RequestParam("aid") Integer id) {
// 参数检验
if (id == null || id <= 0) {
return AjaxResult.fail(-1, "非法参数");
}
// 进行删除
// 只有当前登录的用户同时是文章的作者的情况下才能删除
Userinfo user = UserSessionUtils.getSessUser(request);
if (user == null) {
return AjaxResult.fail(-2, "用户未登录");
}
int delCount = articleService.del(id, user.getId());
return AjaxResult.success(delCount);
}
3.5 对随笔摘要的 markdown 标签处理
由于数据库存储的文章内容均为 markdown 字符,因此,需要对 markdown 标签进行处理。使得在随笔的列表展示中,摘要不显示形如 # 这样的符号。
笔者实现的方式是通过正则表达式匹配,从而进行处理,具体实现代码如下:
import java.util.regex.Pattern;
/**
* @author 兴趣使然黄小黄
* @version 1.0
* @date 2023/7/23 23:18
* 用于处理文章列表的文章摘要信息
* 1. 对摘要去除 markdown 标签处理
* 2. 摘要只截取文章正文前 n 个字符
*/
public class MarkdownUtils {
// 匹配Markdown标签的正则表达式
private static String regex = "\\*\\*|__|\\*|_|~~|`|\\[\\]|\\(|\\)|\\{|\\}|\\[|\\]|#|\\+|-|\\.|!";
/**
* 对摘要进行去 markdown 标签处理
*/
public static String removeMarkdownTags(String markdown, int n) {
// 先对 markdown 字符串进行截取
markdown = preprocessingString(markdown, n);
// 使用空字符串替换Markdown标签并返回
return Pattern.compile(regex).matcher(markdown).replaceAll("");
}
/**
* 截取正文的前 n 个字符作为摘要
*/
private static String preprocessingString(String s, int n) {
if (s == null || s == "" || n <= 0) {
return "";
}
String result = "";
if (n >= s.length()) {
result = s.substring(0, s.length());
} else {
result = s.substring(0, n);
}
return result;
}
}
3.6 基于 MD5 的加盐算法处理明文密码
若数据库存储的密码是形如: 11111 这样的明文形式,则是非常不安全的,若数据库泄露,用户的密码很容易被获取。因此,需要对密码进行处理。
单一的采用 md5 的方式进行加密也是不安全的,因为 md5 对固定字符的加密结果是相同的,比如对于111加密,加密结果是EF2类似这样,通过彩虹表就可以逆向查出来加密前的密码。
笔者采用的方式是通过“加盐”的方式进行处理,即将未加密的密码拼接一个随机值(盐值),然后再进行md5加密,这样就解决了固定密码加密结果相同的的问题。而在存储到数据库前,也需要将盐值一并存储,笔者采用的方式是使用$符号进行分割:
盐值\$加密的密码。进行比对的时候,只需要从数据库中取出盐值,进行加密后与取出加密的密码进行比较。 具体实现如下:
import cn.hutool.core.util.IdUtil;
import cn.hutool.crypto.SecureUtil;
import org.springframework.util.StringUtils;
/**
* @author 兴趣使然黄小黄
* @version 1.0
* @date 2023/7/24 17:01
* 密码明文基于 MD5 随机盐值加密处理
*/
public class PasswordUtils {
/**
* 加密(加盐)
* @param password 需要加密的密码
* @return 盐值$加密的密码
*/
public static String encrypt(String password) {
// 随机盐值
String salt = IdUtil.simpleUUID();
// 密码 md5(随机盐值 + 密码)
String encryptPassword = SecureUtil.md5(salt + password);
return salt + "$" + encryptPassword;
}
/**
* 解密
* @param password 要验证的密码(未加密)
* @param securePassword 数据库中加了盐值的密码
* @return 返回密码是否正确
*/
public static boolean decrypt(String password, String securePassword) {
boolean result = false;
if (StringUtils.hasLength(password) && StringUtils.hasLength(securePassword)) {
if (securePassword.length() == 65 && securePassword.contains("$")) {
String[] securePasswordArr = securePassword.split("\\$");
// 盐值
String salt = securePasswordArr[0];
// 加密后的密码
String encryptPassword = securePasswordArr[1];
// 使用同样的 md5 与同样的盐值对 password 进行加密
password = SecureUtil.md5(salt + password);
// 比较是否相同
return encryptPassword.equals(password);
}
}
return result;
}
}
3.7 使用 Redis 持久化 Session
首先,需要在 SpringBoot 项目中引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
在配置文件中添加上 redis 相关的配置:
spring:
redis:
host: xxx.xxx.xxx.xxx
port: 6379
session:
store-type: redis
timeout: 1800
redis:
flush-mode: on_save
namespace: spring:session
4 开发过程遇到的问题
4.1 Redis服务的远程连接问题与session持久化失败
笔者在开发过程中,使用 Xshell 连接云服务器的 redis 总是出现问题,在处理过程中发现服务器被劫持,最终只得重装系统。当然,也安装了一些工具来防止暴力破解。回到正题,启动了 redis 服务为什么关闭远程连接会话窗口后不久,服务器的 redis 进程就关闭了呢? 后面笔者采用 nohup 的方式启动服务,问题得到解决(需要在配置文件中先把 redis 配置后台运行):

正当我兴致慢慢去启动项目的时候,项目又出现了问题,大概就是在持久化 session 的过程中抛了异常,经查: 当对象需要进行网络传输的时候,需要实现序列化接口,而在项目中,当用户登录成功时,其 session 就是存储了 userinfo 对象。当实现了序列化接口后,问题得到解决。
4.2 查询功能url获取参数中文乱码问题
在实现随笔主页的查询过程中,笔者的思路是将查询的 key 通过点击按钮的方式构造到 url 上,这样每一页都可以通过自己写的方法获取到 search 上的指定参数。在功能完成时,测试英文搜索没问题,而当输入中文检索的时候,则显示不了预期结果。通过调试,发现后端的 sql 竟然传入了一段乱码的 key!!! 将前端对应的代码进行修改,使用decodeURIComponent()进行解码,问题得到解决:
// 获取当前 url 的参数
function getUrlValue(key) {
var params = location.search; // '?xxx&xxx'
if (params.length > 1) {
// 截取
params = params.substring(1);
var paramArr = params.split("&");
// 获取对应的 keyValue
for(var i = 0; i < paramArr.length; i++) {
var kv = paramArr[i].split("=");
if(kv[0]==key) {
return decodeURIComponent(kv[1]); // 处理中文乱码
}
}
}
return "";
}
4.3 草稿箱内容出现在个人随笔页
这个问题的出现实属不该,是笔者在迭代功能的过程中忘记给 sql 添加 where state = xxx 的子句。导致在随笔主页和个人随笔主页以及草稿箱均显示了草稿和已发布的文章。在生产环境中,很多企业都有自己的工具,对于忘记添加 where 语句的 sql 是会报错的!还好,笔者的该模块还仅仅是查询,如果是 insert 或者 update 就会出现数据污染问题了。
写在最后
本文被 JavaEE编程之路 收录点击订阅专栏 , 持续更新中。
以上便是本文的全部内容啦!创作不易,如果你有任何问题,欢迎私信,感谢您的支持!