目录
一、基本操作
二、自动求导机制
三、线性回归DEMO
3.1模型的读取与保存
3.2利用GPU训练时
四、常见的Tensor形式
五、Hub模块
一、基本操作
操作代码如下:
import torch
import numpy as np
#创建一个矩阵
x1 = torch.empty(5,3)
# 随机值
x2 = torch.rand(5,3)
# 初始化一个全零的矩阵
x3 = torch.zeros(5,3,dtype = torch.long)
# view操作改变矩阵维度
x4 = torch.randn(4,4) #4*4矩阵
y = x4.view(16) #变成一行的矩阵
z = x4.view(-1,8) #变为2*8的矩阵
print(y.size()) #矩阵的尺寸
#与numpy的协同操作
# tensor转array
a = torch.ones(5)
b = a.numpy()
# array转tensor
a1 = np.ones(5)
b1 = torch.from_numpy(a)
二、自动求导机制
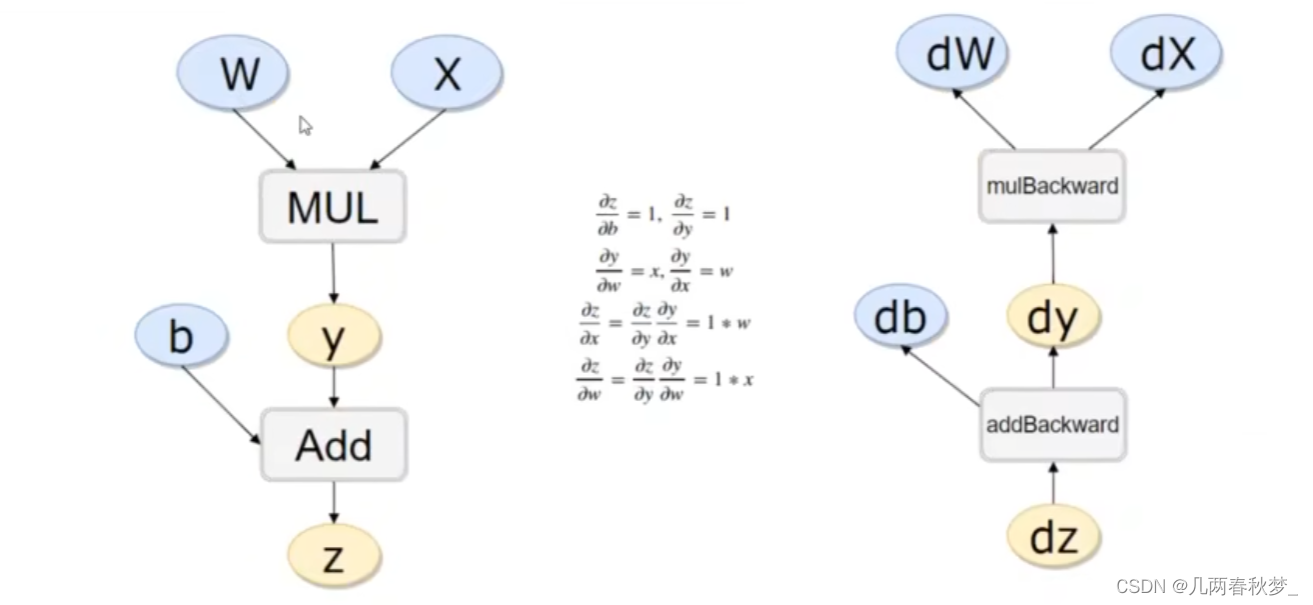
案例代码如下:
import torch
#计算流程
x = torch.rand(1)
b = torch.rand(1,requires_grad=True)
w = torch.rand(1,requires_grad=True)
y = w * x
z = y + b
# 反向传播计算
z.backward(retain_graph = True)
print(w.grad)
print(b.grad)三、线性回归DEMO
import numpy as np
import torch
import torch.nn as nn
# 构建线性回归模型
class LinearRegressionModel(nn.Module):
def __init__(self,input_dim,output_dim):
super(LinearRegressionModel,self).__init__()
self.linear = nn.Linear(input_dim,output_dim)
def forward(self,x):
out = self.linear(x)
return out
x_values = [i for i in range(11)]
x_train = np.array(x_values,dtype=np.float32)
x_train = x_train.reshape(-1,1)
print(x_train.shape)
#y = 2x + 1
y_values = [2*i + 1 for i in range(11)]
y_train = np.array(x_values,dtype=np.float32)
y_train = x_train.reshape(-1,1)
# 构建model
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim,output_dim)
# 指定好参数和损失函数
epochs = 1000 #训练次数
learning_rate = 0.01 #学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate) #优化器
criterion = nn.MSELoss() #损失函数
# 训练模型
for epoch in range(epochs):
epoch += 1
#注意转行为tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
#梯度要清零每一次迭代
optimizer.zero_grad()
#前向传播
outputs = model(inputs)
#计算损失
loss = criterion(outputs,labels)
#反向传播
loss.backward()
#更新权重参数
optimizer.step()
if epoch % 50 ==0:
print('epoch {},loss {}'.format(epoch,loss.item()))3.1模型的读取与保存
# 模型的保存与读取
torch.save(model.state.dict(),'model.pkl') #保存
model.load_state_dict(torch.load('model.pkl')) #读取3.2利用GPU训练时
利用GPU训练时要将数据与模型导入cuda
#注意转行为tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
#利用GPU训练数据时的数据
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
model = LinearRegressionModel(input_dim,output_dim)
#使用GPU进行训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
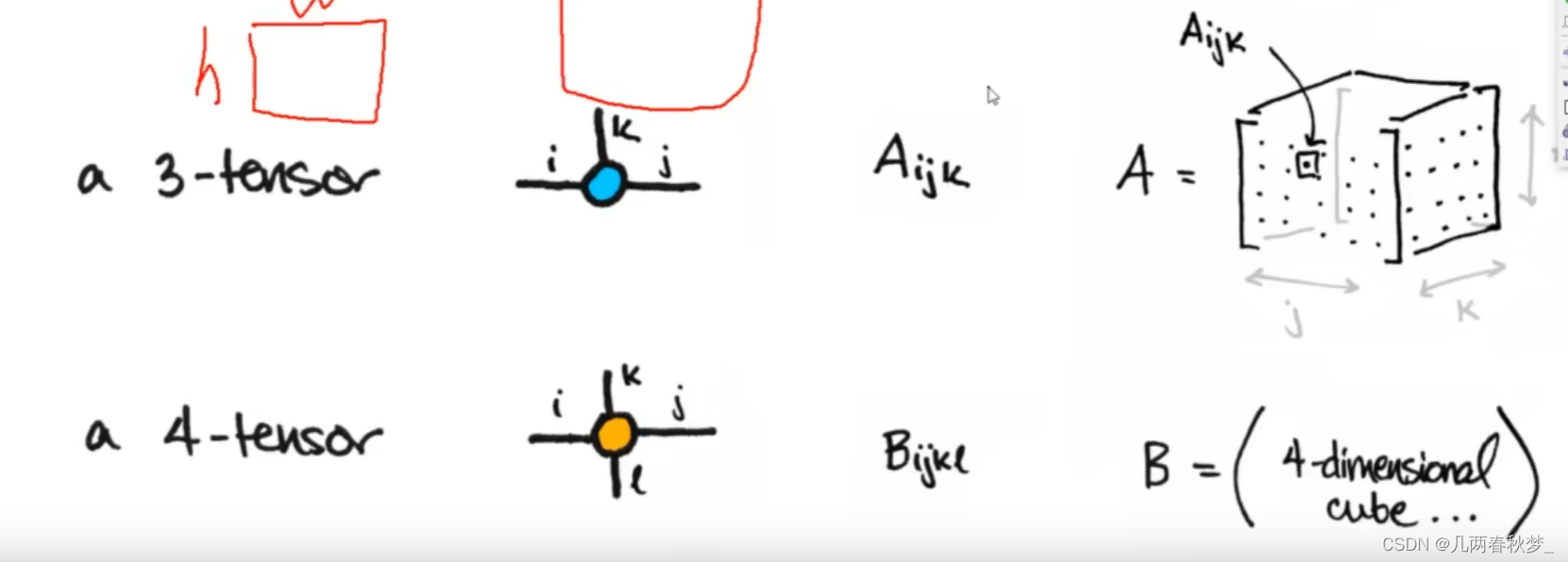
model.to(device)四、常见的Tensor形式
- 1.scalar:通常是指一个数值
- 2.vector:通常是指一个向量
- 3.matrix:通常是指一个数据矩阵
- 4.n-dimensional tensor:高维数据
五、Hub模块
Github地址:https://github.com/pytorch/hub
Hub已有模型:https://pytorch.org/hub/research-models






![[STL]list使用介绍](https://img-blog.csdnimg.cn/img_convert/8c4fbda650978d5c5523caaad7b6f987.png)