PS前面几节课的内容在专栏这里,欢迎大家考古:点我
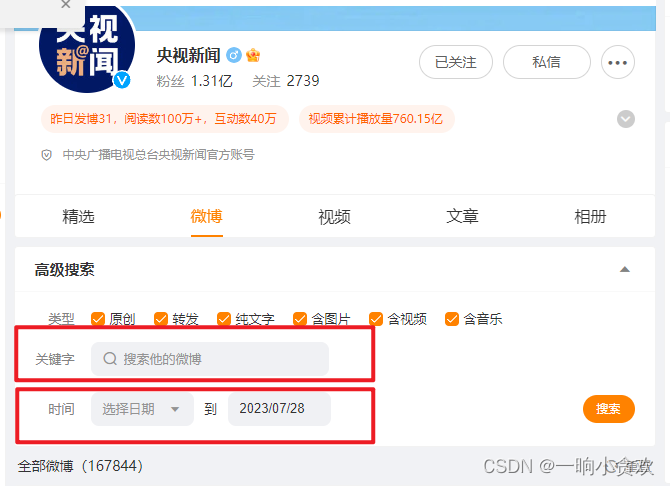
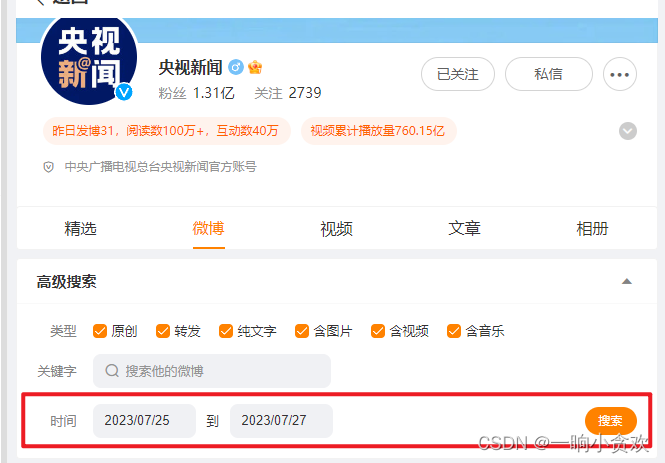
首先第一步我们先登录一下微x博:点我
import json
import time
import requests
cookie = {
'cookie' : '请填写自己的cookie' }
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' }
comments_count = con_json[‘data’][‘list’][i][‘comments_count’] # 评论
import json
import time
import requests
cookie = {
'cookie' : '请填写自己的cookie' }
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' }
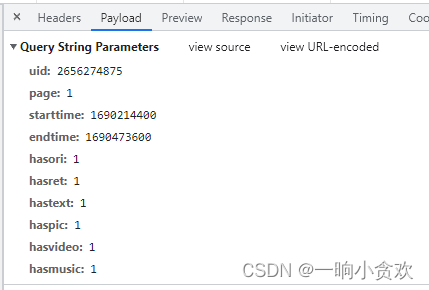
for i1 in range ( 1 , 999 ) :
params2 = {
'uid' : '2656274875' ,
'page' : f' {
i1} ' ,
'feature' : '0' ,
'starttime' : '1690214400' ,
'endtime' : '1690473600' ,
'hasori' : 1 ,
'hasret' : 1 ,
'hastext' : 1 ,
'haspic' : 1 ,
<









![go 查询采购单设备事项[小示例]V2-两种模式{严格,包含模式}](https://img-blog.csdnimg.cn/c3203894ba96451b834340c003cb0a67.png)