向阳花花花花 - 个人主页
迄今所有人生都大写着失败,但并不妨碍我继续向前
Python 数据分析专栏 正在火热更新中 🔥
文章目录
- 前言
- 一、处理某瓣电影top250空数据
- 二、对于空值,有没有别的处理办法?
- 三、上述案例总结
- 3.1 查看数据信息
- 3.2 判断数据是否有空值
- 3.3 查看含空行、删除含空行
- 结语
前言
大家好!我是向阳花,是一位正在努力成长的数据小白。
本期给大家带来的是,使用 pandas 处理某瓣电影top250数据中的空数据。
知识点对应一个小案例,洗碗这种 学习+案例实践 的学习模式会对你有帮助。

一、处理某瓣电影top250空数据
- 1.环境准备
首先导入必要的模块:
import numpy as np
import pandas as pd
加载数据:(数据获取链接:「movie_top_250.xlsx」)
df = pd.read_excel('../datas/pandas练习/movie_top_250.xlsx')
- 2.观察数据
确定数据行列:
df.shape

从以上让我们知道,数据总共有 262条,11列。
- 3.空值行列查找
接下来我们使用 count() 函数,确定哪些列有空值:
df.count()

从以上我们可以看出,有五列,评分、评价人数、国家/地区、语言、时长(分钟)这些列有空值。
也可以使用 isnull() 进一步验证,找出含有空值的列:
df.isnull().any()

和使用 count() 得到的结果含义是一致的。
- 4.查看含有空值的行
发现了存在空值,我们先不着急使用 dropna() 方法删除含有空值的行,我们先看看含有空值的行具体是哪些。
data = df.isnull().any(axis=1)
data

有空值的行即为True,下面打印含有空值的行(行数过多只显示前5行):
df.loc[data].head()

这样,含有 NaN 的数据行就被我们找出来了。
下面我们统计,有多少行含有空值的行。
print(df.loc[data].shape)

也就是说,有24行有空值的行,一开始我们有262条数据,那么使用 dropna() 删除行后,应该剩下:262 - 24 = 238 条数据。
- 5.删除含有空值的行
df.dropna(inplace=True)
再次查看数据行列:
df.shape

与预期相符。
二、对于空值,有没有别的处理办法?
答案肯定是有的。
有时候只是缺失了一行中的某一个,我们希望保留这行数据,使用填充的方式补充空值。
- 1.整体填充(单值填充)
使用 # 号填充所有 NaN 。
df.fillna(value='#')
- 2.向上向下填充
向上填充:
df.fillna(method='ffill',axis=0)
向下填充:
df.fillna(method='bfill',axis=0)
- 3.整体均值填充
df.fillna(df.mean())
- 4.上下列均值填充
df.fillna(df.interpolate())
三、上述案例总结
3.1 查看数据信息
- 1.查看数据行列
df.shape
- 2.查看数据信息
df.info()
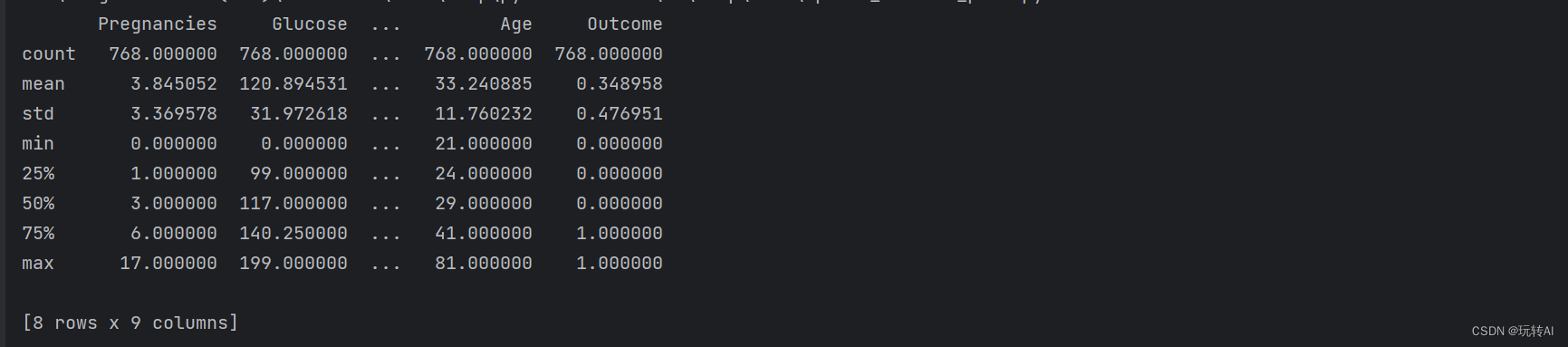
- 3.查看数据更多详细信息,包含条数,平均数,方差,最小、最大值等
df.describe()
3.2 判断数据是否有空值
- 1.count() 方法与 shape 结果对比
df.count()
- 2.使用 isnull() 方法
df.isnull().any()
- 3.使用 notnull() 方法
df.notnull().all()
3.3 查看含空行、删除含空行
- 1.找出含有空值的行
data = df.isnull().any(axis=1)
df.loc[data].head()
高亮显示 NaN:
df.loc[data].style.highlight_null(null_color='skyblue')
- 2.删除含空行
df.dropna(inplace=True)
结语
🔥 如果文中有些地方不清楚的话,欢迎联系我,我会给大家提供思路及解答。🔥







![解决[Vue Router warn]: No match found for location with path “/day“问题](https://img-blog.csdnimg.cn/d2e9732ac14e4d1a819d4efa1ccafba3.png)