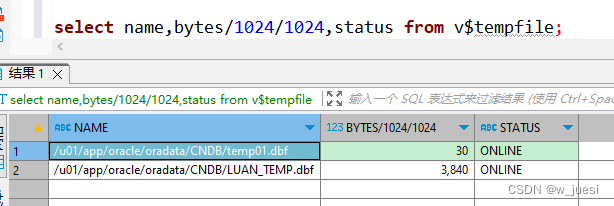
这是我们关于使用检索增强生成构建 AI 代理的系列的最后一章 (3/3)。在第 1/3 部分中,我们讨论了断开连接的嵌入和基于矢量的检索管道的局限性。在第 2/3 部分中,我们介绍了神经数据库,它消除了存储和操作繁重且昂贵的嵌入的需要。相反,它使用简单统一的端到端可学习检索系统。我们认为嵌入表示比文本数据本身重 3-25 倍,而神经数据库只需要几十亿个参数网络和简单的整数哈希表(开销小于 20GB),即使是数百 GB 到 TB 的文本,导致内存使用量显着减少。
在第 2/3 部分结束时,我们强调了 ThirdAI 经科学证明的“动态稀疏性”,这是构建和部署 CPU 上神经数据库所需的 LLM 的关键功能。为了使神经数据库广泛适用,具有简单商用的CPU基础设施应该就足以进行训练和部署。
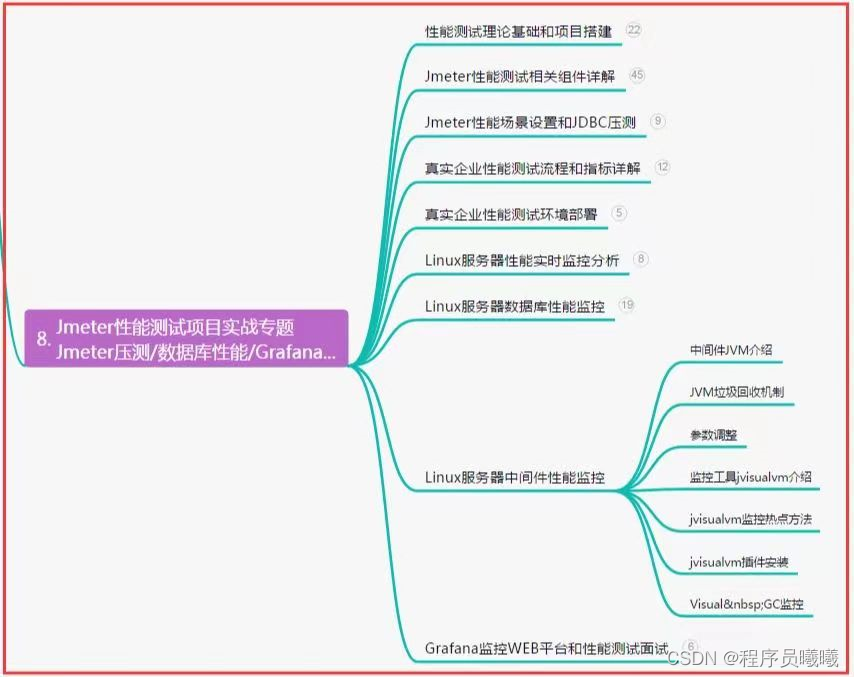
ThirdAI特点:使NeuralDB在商用CPU上具有商业可行性的两大突破
下图说明了ThirdAI的NeuralDB系统的组件。NeuralDB 是一个新概念,它的实现是专业且罕见的,主要存在于 Meta 等特定行业中。然而,为了使NeuralDB商业化,需要一个独特的专家团队来结合制作神经网络的专业知识及其与高度并行化哈希表的检索系统的集成。在做出设计选择和自动化内部流程方面需要多年的经验才能使其广泛访问。

ThirdAI团队一直处于这些想法的最前沿。我们的创始人和团队成员开创了一些关于端到端和高效学习检索系统的最早工作。最后引用了14 NIPS(最佳论文)、NeurIPS 2019、ICLR 2020、KDD 2022的关键论文。
我们的 NeuralDB 需要大型语言模型 (LLM),将文本映射到离散存储桶的大空间中。存储桶的范围可以轻松达到数百万甚至更多,而 GPT 型号通常处理的输出空间仅为 50k。如果没有 ThirdAI 的“动态稀疏”BOLT 引擎,在 CPU 上使用如此大的 LLM 进行训练、微调和执行推理是不可能的。这个独特的软件堆栈由 ThirdAI 开创,是我们方法不可或缺的一部分。
应该注意的是,采用这些能力完全在CPU上运行NeuralDB所有操作至关重要,特别是对于使用NeuralDB的PocketLLM等应用程序。该技术使最先进的神经搜索系统能够在笔记本电脑和台式机上使用,迎合计算资源有限的一般无代码用户。
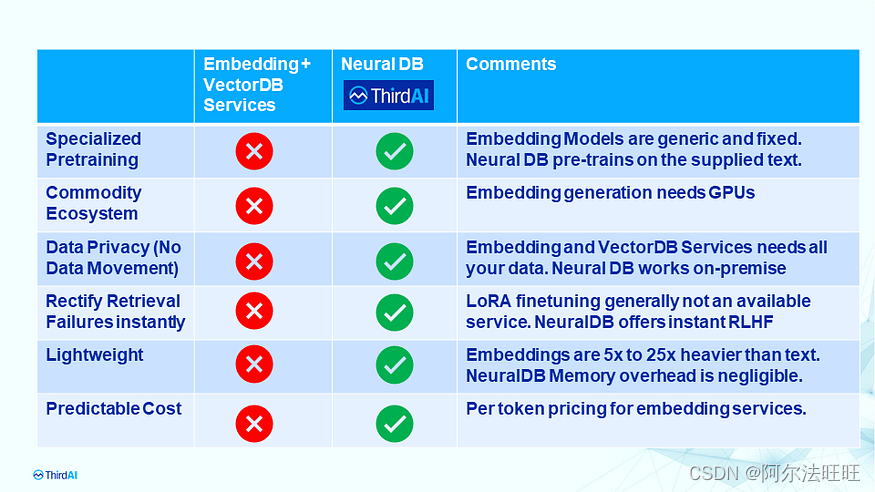
在我们深入研究ThirdAI的NeuralDB API及其与langchain和ChatGPT的无缝集成之前,我们总结了神经数据库相对于现有生态系统的差异和优势,如上表所示。
ThirdAI的轻量级NeuralDB Python API,适用于任何环境(内部部署或云上)
我们很高兴推出我们的NeuralDB API,这是一个仅限CPU的“语义检索”生态系统。我们的 NeuralDB 提供高级语义搜索和微调功能,以及简单、自动调优的 API,以提供轻松的用户体验。这些功能也可以在笔记本电脑/台式机(Windows和Mac)上使用PocketLLM应用程序提供的无代码UI界面进行访问。
- 对插入的文本进行自动自监督预训练:将任何原始文本插入 NeuralDB 中,并带有一个标志,以便对新数据进行额外的微调。该标志在预训练过程中启动,允许 NeuralDB 专注于理解插入文本中的共现。此过程适用于各种输入,例如日志、代码甚至多语言数据。与现有的固定和预训练嵌入模型不同,自监督预训练使 NeuralDB 能够实现领域专业化,从而在端到端检索方面提供了重大升级。
- NeuralDB 的监督训练:除了自我监督的预训练外,NeuralDB 还可以以监督的方式进行训练。您可以利用文本到文本映射(弱或强)来指定应彼此接近的文本信息,类似于嵌入模型的对比训练。此外,可以使用从文本到已知类别的任何监督映射,例如将用户查询映射到产品的产品搜索引擎。
- 具有人工反馈的实时强化学习:NeuralDB可以使用人工实时反馈进一步完善。NeuralDB API 支持两种形式的人工反馈。首先,可以使用首选项信息,其中用户对几个检索到的选项中的最佳选项竖起大拇指或点赞。其次,可以引导模型以在线方式关联两个不同的文本字符串,类似于监督训练。例如,您可以对齐 NeuralDB 以了解石油行业术语,其中“WOW”与“Wait On Weather”相关联。
NeuralDB API 功能提供对检索生态系统的精确控制和个性化。您不再需要仅仅依靠开源社区或现有的LLM服务提供商来改进AI模型以满足您的特定需求。借助 NeuralDB,您可以负责并提供最适合您业务需求的愿景和改进。这是人工智能对每个人的真正民主化。
人工智能社区已经认识到从 ChatGPT 的成功中吸取了关键教训:即使是最先进的人工智能系统也需要不断的人类专家反馈。我们的NeuralDB在设计时就考虑到了这一点。实现高质量的 AI 模型是一个持续的过程,涉及持续的训练、微调和强化学习。
NeuralDB:急需减少AI软件堆栈
LLM(大型语言模型)堆栈变得越来越复杂,具有多层和组件,超过了传统AI堆栈的复杂性。开发人员意识到,每个组件都会增加更多的摩擦、不确定性、故障点、成本和延迟。嵌入模型所需的繁重 GPU 基础设施迫使开发人员构建一个低效的生态系统,在 CPU 和 GPU 之间不断移动数据。简而言之,涉及的组件和数据移动越多,管理和调试流程就越困难。
ThirdAI,独特的技术使我们能够通过消除中间嵌入表示的生成和管理来显着简化LLM堆栈。通过与数据共置并消除 CPU 和 GPU 之间的来回数据移动,我们实现了优先考虑隐私、稳定性和可靠性的简化堆栈。
资源、Notebook和 PubMed 问答 NeuralDB
我们所有的 API 都总结在这个简单的 Python 笔记本中。要使用它们,您可以在此处申请免费的 ThirdAI 许可证。这些笔记本电脑可以在笔记本电脑上高效运行,在短短几分钟内处理数千页。例如,我们有一个完全免费的NeuralDB,它是在800k Pubmed抽象数据集上预先训练的。它在几个小时内在单个CPU上进行了训练。您可以下载模型,并使用提供的脚本直接将其用于问答。
引用
- BLISS:使用迭代重新分区的十亿级索引。
Gaurav Gupta, Tharun Medini, Anshumali Shrivastava 和 Alex Smola
SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD) 2022. - SOLAR:稀疏正交学习和随机嵌入。
Tharun Medini, Beidi Chen, Anshumali ShrivastavaInternational Conference on Learning Representations (ICLR) 2021. - 使用最小计数草图的日志内存中的极端分类:使用 50M 产品的亚马逊搜索案例研究。
Tharun Medini,Qixuan Huang,Yiqiu Wang,Vijai Mohan,Anshumali ShrivastavaNeural Information Processing Systems (NeurIPS) 2019. - 非对称 LSH (ALSH) 用于次线性时间最大内积搜索 (MIPS)。
Anshumali Shrivastava and Ping Li.
Neural Information Processing Systems (NIPS) 2014 Best Paper Award.




![解决[Vue Router warn]: No match found for location with path “/day“问题](https://img-blog.csdnimg.cn/d2e9732ac14e4d1a819d4efa1ccafba3.png)