机器学习数据理解是指对数据集进行详细的分析和探索,以了解数据的结构、特征、分布和质量。数据理解是进行机器学习项目的重要第一步,它有助于我们对数据的基本属性有全面的了解,并为后续的数据预处理、特征工程和模型选择提供指导。
数据理解的主要目标包括但不限于以下内容:
- 数据集概览:查看数据集的规模(样本数量和特征数量),了解数据的基本信息。
- 数据质量评估:检查数据集是否存在缺失值、异常值和噪声。缺失值可能影响模型的训练和预测,异常值和噪声可能对模型的性能造成负面影响。
- 数据可视化:通过绘制直方图、散点图、箱线图等图形,展示数据的分布和特征之间的关系,从而洞察数据的规律和特点。
- 特征理解:对每个特征进行分析,了解其含义、数据类型和取值范围。理解特征的意义有助于我们选择合适的预处理方法和特征工程策略。
- 数据分布:了解数据集中不同类别或目标值的分布情况,特别是对于分类问题来说,类别不平衡可能会影响模型的性能。
- 相关性分析:分析不同特征之间的相关性,帮助我们理解特征之间的关系,以及是否有一些特征对于预测目标更有信息量。
- 数据采样:对于大规模数据集,可能需要进行数据采样,以便更快地进行探索和实验。
通过数据理解阶段,我们能够更好地理解数据集的特点和问题,为后续的数据预处理、特征工程和模型选择提供指导。数据理解是建立有效机器学习模型的重要前提,因为只有充分理解数据,我们才能做出合适的决策,优化模型性能,并避免潜在的问题。
大白话 就是 这些数据是干嘛用得,里面有哪些字段和属性,每个字段得数据列 统计,分布都是怎么样得
数据导入
在训练机器学习的模型时,需要用到大量数据,最常用的做法是利用历史的数据来训练模型。这些数据通常会以CSV的格式来存储,或者能够方便地转化为CSV格式。在开始启动机器学习项目之前,必须先将数据导入到Python中。
下面将介绍三种将CSV数据导入到Python中的方法,以便完成对机器学习算法的训练。
· 通过标准的Python库导入CSV文件。
· 通过NumPy导入CSV文件。
· 通过Pandas导入CSV文件。
CSV 文件说明
CSV 文件是用逗号(,)分隔的文本文件。在数据导入之前,通常会审查一下 CSV文件中包含的内容。在审查CSV文件时,通常要注意以下几个方面。
如果CSV的文件里包括文件头的信息,可以很方便地使用文件头信息来设置读入数据字段的属性名称。如果文件里不含有文件头信息,需要自己手动设定读入文件的字段属性名称。
数据导入时,设置字段属性名称,有助于提高数据处理程序的可读性。
在 CSV 文件中,注释行是以“井”号(#)开头的。是否需要对读入的
注释行做处理,取决于采用什么方式读入CSV文件。
CSV文件的标准分隔符是逗号(,),当然也可以使用Tab键或空格键作为自定义的分隔符。当使用这两种分隔符时,文件读取是要指明分隔符的。
当有的字段值中有空白时,这些值通常都会被引号引起来,默认使用双引号来标记这些字段值。如果采用自定义格式,那么在文件读取时要明确在文件中采用的自定义格式。
Pima Indians数据集
首先介绍一下在本章和后续章节中要使用的测试数据。目前在 UCI 机
器学习仓库(http://archive.ics.uci.edu/ml/datasets.html)中有大量的免费数
据,可以利用这些数据来学习机器学习,并训练算法模型。本章选择的
Pima Indians数据集就是从UCI中获取的。官方下载地址
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database?resource=download
这是一个分类问题的数据集,主要记录了印第安人最近五年内是否患糖尿病的医疗数据。这些数据都是以数字的方式记录的,并且输出结果是 0 或 1,使我们在机器学习的算法中建立模型变得非常方便。
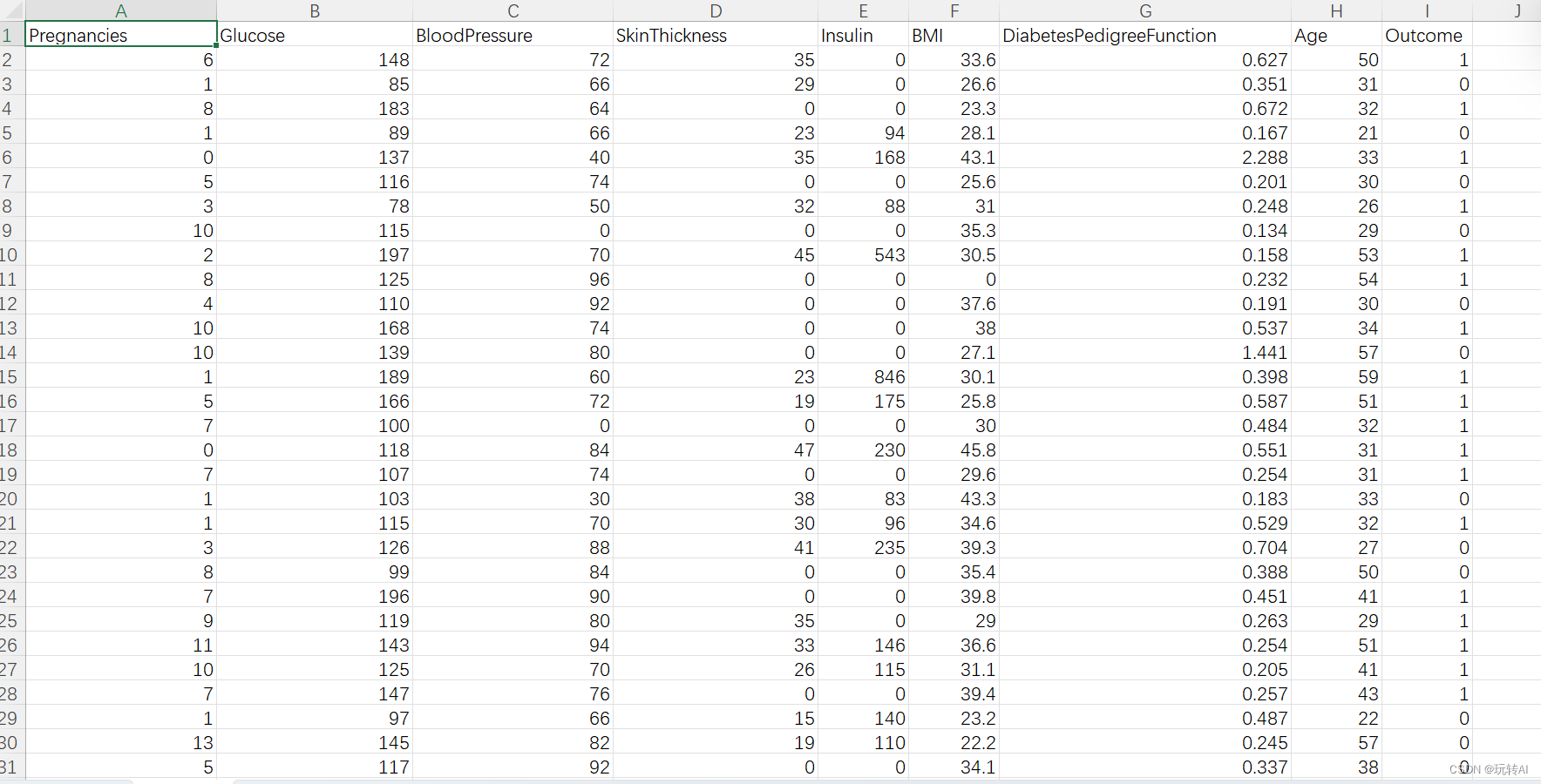
数据格式如下:
糖尿病数据集来源Pima印第安人糖尿病数据集。数据集包含768条数据,9个变量
我们也可以通过pandas 对数据集进行读取并打印数据集得维度信息
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
print(data.shape)
运行结果:
(768, 9)
我们再看下这张表数据的每列分别代表什么意思
该数据集共有768条数据项,包含8个医学预测变量和1个结果变量,其具体属性包括:
怀孕次数(Pregnancies)、
血糖浓度(Glucose)、
血压(BloodPressure)、
肱三头肌皮脂厚度(SkinThickness)、
胰岛素含量(Insulin)、
身体质量指数(BMI)、
糖尿病遗传系数(DiabetesPedigreeFunction)
年龄(Age)、
结 果(Outcome,1代 表 患 糖 尿 病,0代 表 未 患 糖 尿 病).
在PimaIndianDiabetes数据集中,Outcome为1的有268例,即为糖尿病患者人数;Outcome为0的有500例,即为未患有糖尿病的人数.
结合前面几节我们可以知道 这个数据集有 8 个 特征变量,两个数据分类,及数据标签
有了数据之后我们接下来对数据进行进一步得分析
问题:
8个特征变量哪些变量 对结果的影响更大?
换句话说就是 得糖尿病得主要决定因素 是什么?
如何分析出重要特征变量?
数据属性和类型 dtypes
import pandas as pd
#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
print(data.dtypes)
运行结果:
Pregnancies int64
Glucose int64
BloodPressure int64
SkinThickness int64
Insulin int64
BMI float64
DiabetesPedigreeFunction float64
Age int64
Outcome int64
描述性统计
描述性统计是一种用于对数据进行概括和总结的统计学方法,目的是通过一些关键指标和图表来描述数据的基本特征、分布和趋势,从而更好地理解数据集。这些统计指标可以帮助我们了解数据的集中趋势、离散程度、形状、异常值等信息,是进行数据理解和数据预处理的重要工具。
常见的描述性统计指标包括:
均值(Mean):所有样本的和除以样本数量,用于表示数据的集中趋势。
中位数(Median):将数据按大小排列后,处于中间位置的数值,用于表示数据的中间值,对于受异常值影响较小。
众数(Mode):在数据中出现频率最高的数值,用于表示数据的峰值。
方差(Variance):用于表示数据的离散程度,反映数据分散在均值周围的程度。
标准差(Standard Deviation):方差的平方根,用于度量数据的离散程度。
最小值(Minimum)和最大值(Maximum):数据中的最小值和最大值,用于表示数据的范围。
四分位数(Quartiles):将数据按大小排列后,将数据分成四等份的三个数值,用于了解数据的分布。
偏度(Skewness):用于描述数据分布的偏斜程度,正偏斜表示数据向右偏,负偏斜表示数据向左偏。
峰度(Kurtosis):用于描述数据分布的尖峰或平缓程度,正峰度表示尖峰,负峰度表示平缓。
import pandas as pd
#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
print(data.describe())
运行结果:
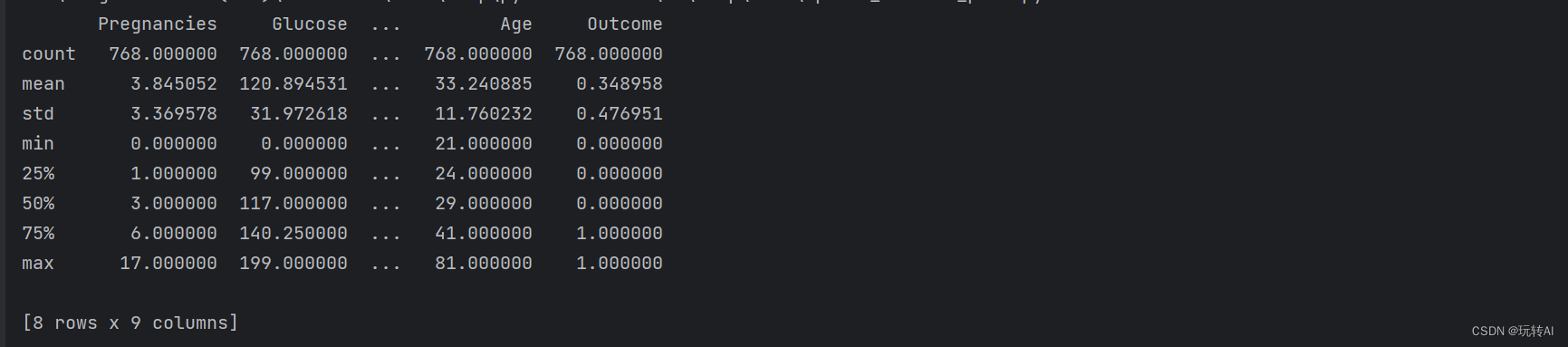
describe()函数 是一个常用的 Python 数据分析工具 pandas 中的方法。它用于生成数据的描述性统计摘要,包含数据的均值、标准差、最小值、最大值、分位数等统计信息。data.describe() 适用于数据框(DataFrame)或数据系列(Series)对象。
在使用 data.describe() 时,它将返回一个包含描述性统计信息的数据框,其中包含以下统计指标:
count:非缺失值的数量。
mean:均值。
std:标准差。
min:最小值。
25%:第 25 百分位数(第一四分位数)。
50%:第 50 百分位数(中位数)。
75%:第 75 百分位数(第三四分位数)。
max:最大值。
上面表格中的数据比较多, 从统计里不好看,我们模拟一个简单得表格来看看 describe() 这个函数,代码如下:
import pandas as pd
# 假设 data 是一个数据框
data = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]})
# 生成数据的描述性统计信息
description = data.describe()
print(description)
运行结果如下:
A B C
count 5.000000 5.000000 5.000000
mean 3.000000 30.000000 300.000000
std 1.581139 15.811388 158.113883
min 1.000000 10.000000 100.000000
25% 2.000000 20.000000 200.000000
50% 3.000000 30.000000 300.000000
75% 4.000000 40.000000 400.000000
max 5.000000 50.000000 500.000000
这样,我们就可以一目了然地了解数据的基本统计信息,包括均值、标准差、最小值、最大值和分位数等,帮助我们对数据有一个初步的认识
数据的分布分析- skew()
数据的分布分析是指对数据集中的样本值进行统计和可视化分析,以了解数据值的分布情况。通过数据的分布分析,我们可以得到关于数据的结构、特点、离散程度、异常值等信息,有助于对数据进行更深入的理解和进一步的数据处理。
常见的数据分布分析方法包括:
直方图(Histogram):直方图是将数据划分为若干个区间(称为“箱子”或“bin”),并计算每个区间内样本值的数量或频数。直方图能够直观地展示数据的分布情况,帮助我们观察数据的集中趋势和离散程度。
箱线图(Box Plot):箱线图可以显示数据的五数概括(最小值、第一四分位数、中位数、第三四分位数、最大值),并用箱体展示数据的中间 50% 区间。
箱线图可以帮助我们发现数据中的异常值和离群点。
概率密度函数(Probability Density Function,PDF):对于连续型数据,PDF 表示了数据值的概率密度分布,可以帮助我们观察数据的分布形状。
累积分布函数(Cumulative Distribution Function,CDF):CDF 表示了数据中小于或等于某个值的样本占总样本的比例,可以帮助我们理解数据的累积分布情况。
QQ 图(Quantile-Quantile Plot):QQ 图用于检验数据是否符合某个理论分布,通过将数据的分位数与理论分布的分位数进行比较,观察数据是否在理论分布上分布均匀。
通过这些数据分布分析方法,我们可以了解数据的中心趋势(均值、中位数)、离散程度(标准差、四分位距)、分布形状(偏度、峰度)等特征,进一步辅助我们做出数据预处理、特征工程和模型选择等决策。同时,数据分布分析也有助于我们发现异常值和异常情况,为后续的数据清洗和数据处理提供依据。
在数据分析工具 pandas 中,skew() 函数用于计算数据的偏度(skewness),它用于描述数据分布的偏斜程度。
偏度是统计学中的一个重要概念,用于度量数据分布的不对称性。
正偏斜表示数据分布右偏(尾部较长),
负偏斜表示数据分布左偏(尾部较长)。
偏度为0表示数据分布对称。
skew() 函数接受一个数据框(DataFrame)或数据系列(Series)作为输入,并返回一个标量值,表示数据的偏度。
针对pima 数据集 得偏度分析如下:
import pandas as pd
#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
print(data.skew())
运行结果:
Pregnancies 0.901674
Glucose 0.173754
BloodPressure -1.843608
SkinThickness 0.109372
Insulin 2.272251
BMI -0.428982
DiabetesPedigreeFunction 1.919911
Age 1.129597
Outcome 0.635017
dtype: float64
继续对skew 理解,传入自定义数组进行理解,相信大家这样会对这个函数有更好得来验证
负偏斜表示数据分布右偏(尾部较长),
正偏斜表示数据分布左偏(尾部较长)。
偏度为0表示数据分布对称。
代码如下:
import pandas as pd
# 假设 data 是一个数据框或数据系列
data = pd.Series([2, 2, 2, 5, 5, 5, 5, 5, 5, 5, 5])
data2 = pd.Series([2, 2, 2, 2, 2, 2, 5, 5, 5, 5, 5,5])
data3 = pd.Series([2, 2, 2, 2, 2, 2,2, 2, 2, 5, 5, 5])
# 计算数据的偏度
print("数据的偏度为:", data.skew())
print("数据的偏度为:", data2.skew())
print("数据的偏度为:", data3.skew())
上面代码我们定义得三个数组,第一组左边得2
运行结果:
数据的偏度为: -1.1893733869134377
数据的偏度为: 0.0
数据的偏度为: 1.3266499161421599
从上面得结果中我们看着感觉清晰多了, 特别是data2, 表示偏度为0表示数据分布对称。那接下来我们又要问了
什么是尾部较长?
在给定的数据集中,"尾部"通常用于描述数据分布的两端,即数据中较小或较大的值。
在这个数据集中,我们可以观察到两个值,即"2"和"5",这两个值分别是数据的尾部。
具体来看下data1 说:
在给定的数据集 [2, 2, 2, 5, 5, 5, 5, 5, 5, 5, 5] 中,尾部是指数据集中位于两端的值。根据数据集,我们可以看到两个值:2 和 5。在这个数据集中:
数据集中较小的值为 2,它出现了 3 次,位于数据的左尾部(左端)。
数据集中较大的值为 5,它出现了 8 次,位于数据的右尾部(右端)。
因此,根据给定的数据集,“5” 是数据的尾部值,它是出现次数最多的值,也是数据集中较大的值,因此属于右尾部。
通过上面得例子我们对 数据得分布有了一些新得理解,我们再重新回到pima 分析得年龄 得偏度分析 看看,
从年龄 分析出的结果是
Age 1.129597
得出得结论 是正偏斜, 从这个数据来看我们可以很快得得出 数据集中 年龄小得比年龄大得要多得多
数据分析我们先到这里,下一节我们 针对这个数据集进行可视化操作进一步探讨




![解决[Vue Router warn]: No match found for location with path “/day“问题](https://img-blog.csdnimg.cn/d2e9732ac14e4d1a819d4efa1ccafba3.png)