聚类是一种经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律,即不依赖于训练数据集的类标记信息。聚类试图将数据集划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类算法体现了“物以类聚,人以群分”的思想。“物以类聚,人以群分”出自《战国策·齐策三》,用于比喻同类的东西常聚在一起,志同道合的人相聚成群。俗话说“近朱者赤,近墨者黑”,每一个人都或多或少地受周围的人的影响,所以我们要“见贤思齐,择善而从”,向优秀的人学习,树立积极进取、乐观向上的人生态度,从而形成正确的人生价值评判标准。
01、案例导入——客户聚类
通过对客户的消费行为进行聚类分析,将客户细分,从而企业可以针对不同客户提供不同的产品内容,采取不同的促销手段等。
本案例数据集来自UCI机器学习数据集Wholesale customers,该数据集记录了某批发经销商不同商品的年度销售情况。数据集包括440行记录和8个属性列,这些属性分别为客户渠道(channel)、客户所在区域(region)以及新鲜商品(fresh)、奶制品(milk)、零食(grocery)、冷冻商品(frozen)、洗涤剂和纸品(detergents_paper)、熟食(delicatessen)6种商品的年度销售。该数据集的部分数据如图1所示,详细介绍可以查看UCI机器学习数据集http://archive.ics.uci.edu/ml/datasets/Wholesale+customers。
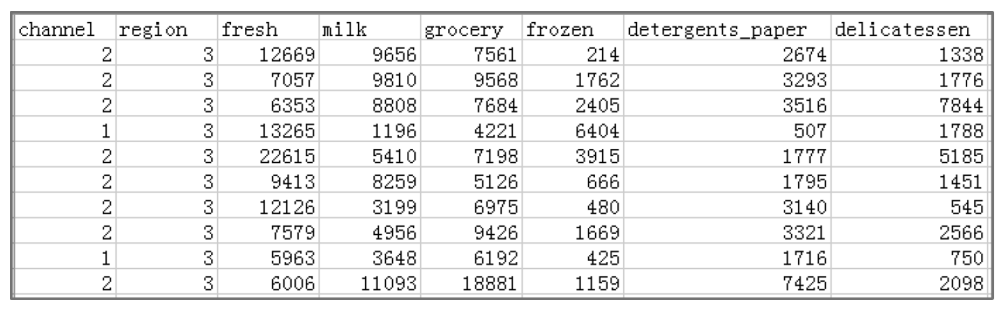
■图1 Wholesale customers数据集的部分数据展示
本案例通过6种商品的销售数据对客户进行聚类,分析客户的消费行为,从而帮助经销商针对不同客户制订营销计划。
02、案例实现
使用某批发经销商的6种商品的年度销售数据集Wholesale customers,采用K-means聚类算法对其客户进行聚类,分析客户的消费行为。
(1) 导入库。代码如下。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing
import Normalizerfrom sklearn.cluster
import KMeans
from sklearn.metrics import silhouette score
from collections import Counter(2) 导入数据,并对数据做预处理。为了方便展示字段名称,从数据表中读取数据时,将列名指定为中文。因为本案例主要通过6种商品的年度销售量分析客户行为,所以只使用数据表中的6列商品数据,即列号从2至7。代码如下。
dfO=pd.read csv("Wholesale customers data.csv",header=0,names=渠道区域’,'新鲜商品’,'奶制品’,'零食’,'冷冻商品 ,"洗涤剂和纸品’,"熟食门)df=df0.iloc[:,2:8]
print(df.info())#输出数据表的基本信息(维度、列名称、数据格式、所占空间等)输出结果为:
<class 'pandas .core .frame .DataFrame'>
RangeIndex: 440 entries,0 to 439
Data columns (total 6 columns):
新鲜商品 440 non-null int64
奶制品 440 non-null int64
零食 440 non-null int64
冷冻商品 440 non-null int64
洗涤剂和纸品 440 non-null int64
熟食 440 non-null int64
从数据表的基本信息可以看出,数据表没有缺失值。下面对数据表的异常值进行处理,然后对数据进行标准化。
① 异常值处理。首先绘制散点图,查看数据是否存在异常值。代码如下。函数plot_scatter()的功能是绘制数据表中6种商品的散点图,初始数据集各列数据的散点图如图2所示。
def plot scatter(df) :
""""""
绘制数据集中 6种商品销量的散点图
:param df:数据集,类型为 DataFrame
""""""
plt.rcparamsl'font.sams-serif =SimHeir7# 调查字体设置
plt.figure(figsize=(14,10))
for i in range(0,6):
plt.subplot(2,3,i+1)
field=df.columns i]
plt.scatter(df.index,df[field],s=5,c='b')
plt.title(field)
plt.xlabel('索引 )
plt.tight layout()
plt.show()
plot scatter(df) # 调用函数
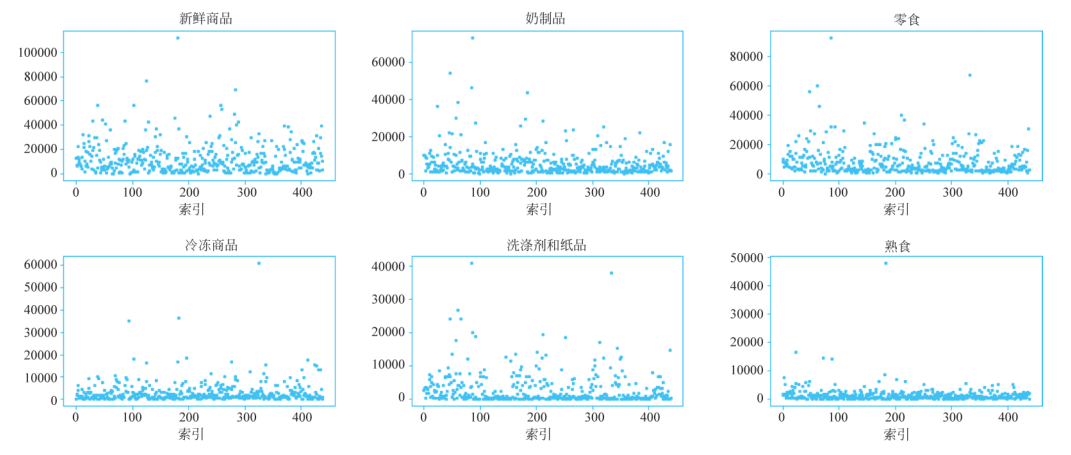
■图2 初始数据集各列数据的散点图
从图8-20可以看出,6种商品都存在一些异常值。函数drop_outlier(df,n)的功能是删除数据集中6种商品的异常值,其中参数df表示原始数据集,参数n表示标准差的倍数,即使用均值和标准差进行异常值判定:异常值是指在[mean-n*std,mean+n*std]范围之外的数据。原数据集样本容量为440,调用drop_outlier()函数删除异常值后得到的新数据集容量为396,即删除了44个异常值。绘制新数据集中各列数据的散点图,如图2所示。代码如下。
def drop outlier(df,n):
""""""
删除数据集中 6 种商品的异常值
:param df:数据集,类型为 DataFrame
:param n:标准差的倍数,一般取值为 2或 3
:return:删除异常值后的数据集,类型为 DataFrame
""""""
for i in range(0,6):
field=df.columns i
mu=round(dfl field .mean())
sigma=round(df_field .std())
df=dfl(df field]>=mu-n*sigma) & (df field <=mu+n*siqma)
return df
df new=drop outlier(df,3) # 调用函数删除 3 倍标准差之外的异常值
plot scatter(df new) # 绘制新数据集中 6种商品销量的散点图
print("原有样本容量:{0],删除异常值后样本容量:1)".format (df.shape[0],df new.shape[07))输出结果为:
原有样本容量:440,删除异常值后样本容量:396
■ 图2 删除异常值后各列数据的散点图
② 数据标准化。以下代码输出数据集中各列的统计信息,可以看出各列数据的数值差别比较大,所以在聚类前需要标准化。
print (df new.describe()) #输出数据的统计信息输出结果为:
新鲜商品 奶制品 ... 洗涤剂和纸品 熟食
count 396.000000 396.000000 ... 396.000000 396.000000
mean 10867.648990 4529.628788 ... 1993.757576 1176.411616
std 9898.704567 4127.47209 ... 2520.657749 1082.264178
min 3.000000 55.000000 ... 3.000000 3.000000
使用sklearn.preprocessing.Normalizer()方法对数据进行标准化,然后输出标准化后的数据。这里使用Normalizer()方法的默认参数,即对样本的所有值计算其2-范数,然后用该样本的每个元素除以该范数。代码如下。可以看出,标准化后,各列数据在同一个量级。
X=df new.values # 读取 df 的数据
print(norm X)
norm X=Normalizer() .fit transform(X)输出结果为:

(3) 使用K-means算法对标准化的数据进行聚类。如何选择合适的n_clusters值?本案例中使用轮廓系数作为肘部法则的目标函数,选择轮廓系数最大的n_clusters值。代码如下。大家可自行练习采用总簇内平方和作为目标函数的肘部法则算法。
#选择合适的 n clusters 值
range n clusters=[2,3,4]
for n clusters in range n clusters:
cluster=KMeans(n clusters=n clusters,random state=1)
cluster labels=cluster.fit predict(norm X)
# 计算所有样本的平均轮廓系数
silhouette=silhouette score(norm X,cluster labels)
print("For n clusters=,n clusters,
silhouette score is :", round(silhouette,2))输出结果为:
For n clusters=2,silhouette score is : 0.5
For n clusters=3,silhouette score is : 0.41
For n clusters=4,silhouette score is : 0.36n _ clusters=2 时,轮廓系数最大,所以选用 n _ clusters=2 对数据集进行聚类分析。代码如下。
cluster=KMeans(n clusters=2,random state=1)
cluster=cluster.fit(norm X)
y predict=cluster.labels
df new['类别']=y_predict
# 如果要保存聚类的类别,可以将 df new 保存为 csv 文件
df new.to csv('Wholesale customers data new.csv',encodig='gbk')(4) 分析聚类结果。可以查看聚类后每一类的样本数,以及每一类的类中心等信息。代码如下。
print(Counter(y predict)) #输出聚类后每一类的样本数
centroid=cluster.cluster_centers
df_center=pd.DataFrame(centroid[:,0:6],columns=['新鲜商品奶制品’,'零食'冷冻商品,,"洗涤剂和纸品,,,熟食 )
print(df center) #输出聚类中心
输出结果为:

通过聚类,将客户分为两类: 客户群1(类标签为0) 和客户群2(类标签为1),客户群1的样本数为235,客户群2的样本为161。centroid变量保存了这两类客户群的类中心,即这两类客户群的平均购买情况,将类中心绘制为如图8-22所示的柱状图,代码如下所示。注意,在图3中,y轴是标准化后的销售额。可以看出客户群1主要购买新鲜品,客户群2主要购买零食和奶制品。
plt.rcParams['font.sans-serif门=['SimHei] #用来正常显示中文标签
plt.rcParams ['axes.unicode minus'] =False
colors_list=['snow','gainsboro','silver','darkgray','gray','black']
df_center.plot(kind='bar', color = colors list,ec='k')
plt.xticks(rotation=360)
plt.show()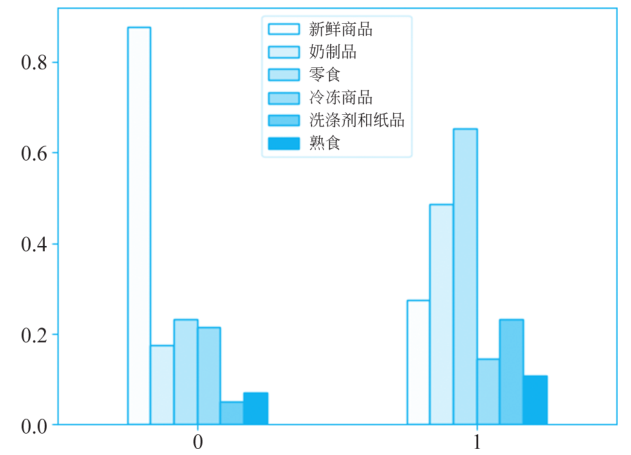
■ 图3 聚类中心的6种商品分布情况
下面分析客户群 1 和客户群 2 的购买总额情况,代码如下。可以看出客户群 1 的购买总额比客户群 2 的购买总额大,客户群 1 是重要的价值客户。公司可进行一些打折促销活动,刺激客户群 2 的购买行为。
df group = df new.groupby(by=['类别门)[新鲜商品 奶制品',零食,冷冻商品',洗涤剂和纸品 ,熟食].sum()
print(r--------两类客户的 6 种商品销售总额----)
print(df group)输出结果为:

下面分析两类客户的购买渠道(channel)和所在区域(region),代码如下。因为渠道和区域这两列数据在初始数据表df0里,而在df_new数据表中没有这两列数据,所以,首先需要将聚类后的类别标签写入初始数据表df0里,然后再分析两类客户在渠道和区域的分布情况。
dfO new = df0.loc df new.index
dfO new['类别]= y_predict
print ("----两类客户在数据列,渠道,的统计----")
print('客户群 1:,Counter(dfO new[dfO new.类别==0][·渠道门))
print('客户群 2:,Counter(dfO new[dfO new.类别==1][·渠道]))
print("----两类客户在数据列,区域,的统计----")
print('客户群 1:,Counter(dfO new[dfO new.类别==0]['区域门))print 客户群 2:,Counter(dfO new[dfO new.类别==1][区域))输出结果为:

可以看出,客户群1来源倾向于渠道1(channel=1),可加大在该渠道上的宣传力度。客户群1和客户群2都倾向于区域3(region=3),营销政策可以倾向于该区域。