调用Embedding接口完成文本分类
前面博客介绍了如何调用ChatGPT的Embedding接口完成文本聚类任务,实现过程入下图所示:
 除了完成文本分类,调用Embedding接口还可完成聚类任务。
除了完成文本分类,调用Embedding接口还可完成聚类任务。
调用Embedding接口完成聚类任务
聚类任务是一种无监督学习任务,其目的是将一组数据点划分成若干个类别或簇,使得同一个簇内的数据点之间的相似度尽可能高,而不同簇之间的相似度尽可能低。聚类算法可以帮助我们发现数据中的内在结构和模式,发现异常点和离群值,简化数据表示。大白话讲就是无监督学习的内容分类。下面的代码中,读取的数据文件是带向量的20_newsgroup_with_embdding.parquet数据,即调用ChatGPT的Embedding接口生成向量信息。原始的20_newsgroup是来源于“from sklearn.datasets import fetch_20newsgroups”。
import numpy as np
from sklearn.cluster import KMeans
import pandas as pd
from IPython.display import display
embedding_df = pd.read_parquet("cluster/20_newsgroup_with_embedding.parquet")
matrix = np.vstack(embedding_df.embedding.values)
num_of_clusters = 20
kmeans = KMeans(n_clusters=num_of_clusters,
init="k-means++", n_init=10, random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
embedding_df["cluster"] = labels
embedding_df.head()
# 统计每个cluster的数量
new_df = embedding_df.groupby(
'cluster')['cluster'].count().reset_index(name='count')
# 统计这个cluster里最多的分类的数量
title_count = embedding_df.groupby(
['cluster', 'title']).size().reset_index(name='title_count')
first_titles = title_count.groupby('cluster').apply(
lambda x: x.nlargest(1, columns=['title_count']))
first_titles = first_titles.reset_index(drop=True)
new_df = pd.merge(new_df, first_titles[[
'cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(
columns={'title': 'rank1', 'title_count': 'rank1_count'})
# 统计这个cluster里第二多的分类的数量
second_titles = title_count[~title_count['title'].isin(first_titles['title'])]
second_titles = second_titles.groupby('cluster').apply(
lambda x: x.nlargest(1, columns=['title_count']))
second_titles = second_titles.reset_index(drop=True)
new_df = pd.merge(new_df, second_titles[[
'cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(
columns={'title': 'rank2', 'title_count': 'rank2_count'})
new_df['first_percentage'] = (
new_df['rank1_count'] / new_df['count']).map(lambda x: '{:.2%}'.format(x))
# 将缺失值替换为 0
new_df.fillna(0, inplace=True)
# 输出结果
display(new_df)
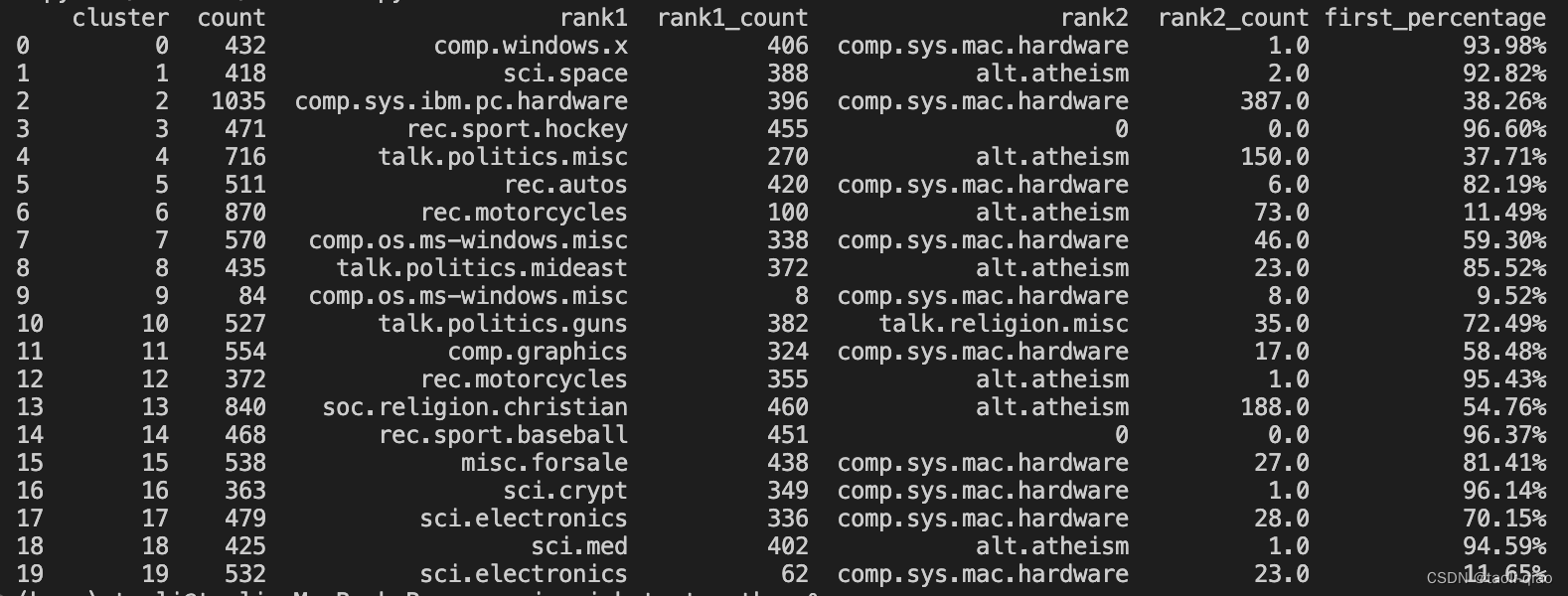
上面的代码读取带向量的文本信息后,再调用比较简单的聚类算法K-means完成聚类任务,因为知道原始数据是来源于不同类型的20种news,所以调用Kmeans函数时,传入的number_of_cluster是20.后续的代码主要是验证Kmeans算法得到的聚类结果准确性。下面的表格是验证逻辑输出的结果,通过计算每种cluster中前两类类型的占比来看聚类准确率,以cluster0为例,first_percentage的占比是93%,说明聚类效果比较好。
总结而言,调用Eembedding接口完成聚类的任务的步骤如下,和文本分类步骤很相似。
 调用Embedding接口优化检索功能
调用Embedding接口优化检索功能
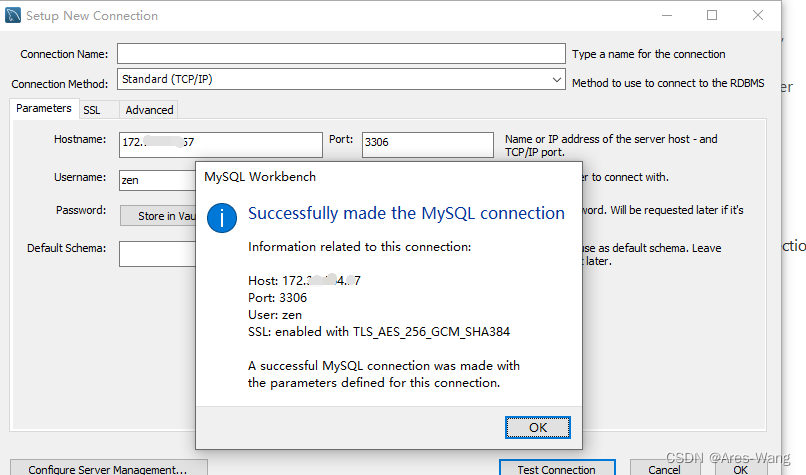
在了解如何使用Embedding接口优化检索功能时,我们先来看Elasticsearch是如何做检索。Elasticsearch是一个基于Lucene的开源搜索引擎,它提供了分布式、多租户的全文搜索引擎服务。Elasticsearch的搜索原理如下所示:
-
文档索引:在Elasticsearch中,所有的数据都被组织成一个或多个索引。每个索引包含一个或多个文档,每个文档都有一个唯一的ID和一个或多个字段。
-
分词:在搜索之前,查询语句和文档中的字段都需要进行分词处理,将它们分成一个个词语。
-
倒排索引:Elasticsearch使用倒排索引来加快搜索速度。倒排索引是一种数据结构,它将每个词语映射到包含该词语的所有文档中,这样就可以快速地找到包含某个词语的所有文档。
-
搜索:当用户发送一个查询请求时,Elasticsearch会对查询进行解析和分析,并在倒排索引中查找匹配的文档。Elasticsearch会计算每个文档的相关度分数,并将最相关的文档返回给用户。
-
分片:由于数据量可能非常大,Elasticsearch将索引划分为多个分片(shard),每个分片存储索引的一部分数据。当搜索请求发送到集群时,它会被发送到每个分片,然后每个分片都会返回匹配的文档。
-
聚合:Elasticsearch还支持聚合操作,可以对搜索结果进行统计、分组、排序等操作。聚合操作可以帮助用户更好地理解数据,提供更有价值的信息。
总结而言,Elasticsearch是通过对查询语句和文档进行分词处理,检索时进行匹配检索的。例如,“气质小清新拼接百搭双肩斜挎包”这样的商品名称,拆分成“气质”“小清新”“拼接”“百搭”“双肩”“斜挎包”。每个标题都是这样切分。然后,建立一个索引,比如“气质”这个词,出现过的标题的编号,都按编号顺序跟在气质后面。其他的词也类似。当用户搜索的时候,比如用户搜索“气质背包”,也会拆分成“气质”和“背包”两个词。然后就根据这两个词,找到包含这些词的标题,根据出现的词的数量、权重等等找出一些商品。通过分词检索可以检索到相关内容,但是如果是相近含义的词语检索可能效果就不太理想。对于这个点,Elasticsearch也提供了一些解决办法:
-
同义词过滤器:Elasticsearch可以使用同义词过滤器来将多个词语视为同一个词语。例如,将“汽车”、“轿车”和“车辆”视为同一个词语。
-
正则化:在搜索期间,Elasticsearch会对搜索词进行正则化,以便将不同形式的同一词语视为同一个词语。例如,将“running”和“ran”视为同一个词语。
-
模糊搜索:Elasticsearch可以使用模糊搜索来查找与搜索词相似的词语。这对于处理拼写错误或仅了解部分词汇的情况非常有用。
其中模糊检索,正则化在常规软件检索功能中也经常用到,同义词过滤的方法,需要将相关同义词都归纳进来才行,而且要完成一个复杂的检索,以电商为例,需要整合的同义词非常多。除了这些方法外,实际还可以利用自然语言处理技术,即利用自然语言处理技术中判断两个词语是否是同义词来完成同义词检索。
因为ChatGPT开放了Eebedding接口,那么完全可以获取文本的向量信息,然后通过计算距离来确定文本相似性,从而提升相近词语检索准确度。下面的这段代码通过计算检索的内容与原有的所有product的向量见的余弦距离,来找到匹配最相近的内容。
import openai
import os
from openai.embeddings_utils import get_embedding, cosine_similarity
import pandas as pd
import numpy as np
openai.api_key = os.environ.get("OPENAI_API_KEY")
embedding_model = "text-embedding-ada-002"
# read the reviews embedding information
# load data
datafile_path = "cluster/product_with_embedding.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(
np.array) # convert string to array
# search through the reviews for a specific product
def search_product(df, query, n=3, pprint=True):
product_embedding = get_embedding(
query,
engine=embedding_model
)
df["similarity"] = df.embedding.apply(
lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.productname
)
if pprint:
for r in results:
print(r)
return results
results = search_product(df, "凉快的裙子", n=3)


代码中设置了找到最相近的三个product,当检索“凉快的裙子”的时候,原始的product文件中并没有完全相同的词语,因为采用向量间距离的方式,最终检索出了三条数据,例如清凉透气,轻盈凉爽等,和用检索的目标product很贴近。总结而言,调用Embeeding接口,优化检索能力的过程如下所示:
 另外,除了上面的优化检索功能,还可以应用到推荐产品的冷启动上。
另外,除了上面的优化检索功能,还可以应用到推荐产品的冷启动上。
调用Embedding接口完成推荐系统的冷启动
推荐系统的“冷启动”问题是指,在推荐系统开始运行时或添加新的产品时,由于缺乏足够的用户行为数据或产品元数据,导致推荐系统无法准确预测用户喜好或推荐相应的产品。这个问题对于新产品的上线和新用户的注册都是很常见的。在这种情况下,推荐系统需要寻找其他的方式来生成个性化推荐,例如利用用户的基本信息、偏好标签等,或者采用基于内容的推荐或混合推荐方法。在有了Eebedding接口后,可以提前生成所有product的向量信息,当用户在review某个product时,可以计算review的product的向量信息与其他product的向量间的距离来推荐给用户。总结而言辅助进行冷启动的过程如下所示:

当然上面的代码只是一个demo code,因为每次检索都需要计算和所有产品的余弦距离,如果product很多的情况下,检索性能不一定高,在实际项目中可以利用一些能快速检索向量相似性的库来提升匹配性能。例如Faiss,Faiss(Facebook AI Similarity Search)是Facebook开源的一个高性能相似性搜索库,其主要作用是进行向量的相似性搜索和聚类。Faiss是基于高度优化的算法实现的,具有快速高效的搜索速度和低内存占用等优点。它支持多种相似性度量,包括欧几里得距离、内积和余弦相似度等,还提供了多种搜索算法,如精确搜索、近似搜索和聚类等。
除了Faiss,还有Pinecone、Weaviate等。Pinecone是一种托管服务,用于存储、索引和查询向量。它旨在帮助开发人员更轻松地构建、部署和管理基于向量的应用程序,如搜索、推荐和相似性匹配。Pinecone提供高性能的向量索引和查询,可以支持海量向量的存储和快速检索。同时,它还提供了简单易用的API和客户端库,可以轻松地将向量集成到应用程序中。
Weaviate是一种基于向量搜索的开源知识图谱和搜索引擎,使用GraphQL API进行查询。它支持半结构化和非结构化数据,并使用机器学习算法为实体和属性赋予向量表示。这使得Weaviate能够对数据进行相似度搜索,例如:相似问题,相似产品,相似文章等。Weaviate还具有自动化数据管理和验证功能,可以轻松地添加,更新和删除实体,属性和关系。
总结而言,通过调用ChatGPT的Embedding接口获取向量信息,存储到Pinecone或者Weaviate等服务上,通过计算输入信息也已有信息的向量距离,可以快速进行相似性度量。