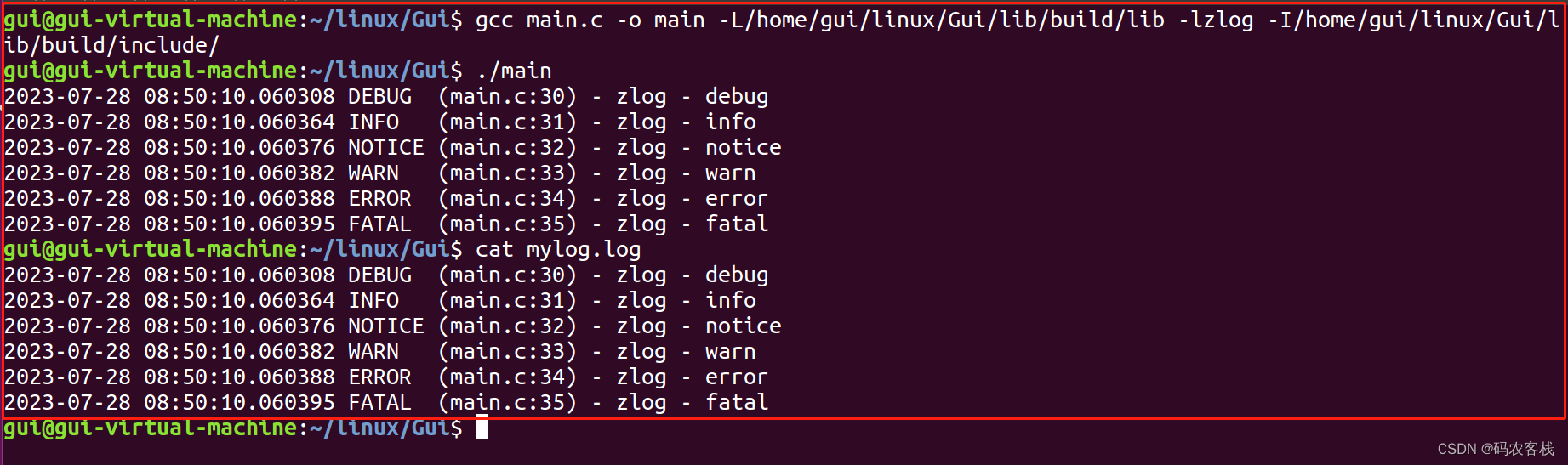
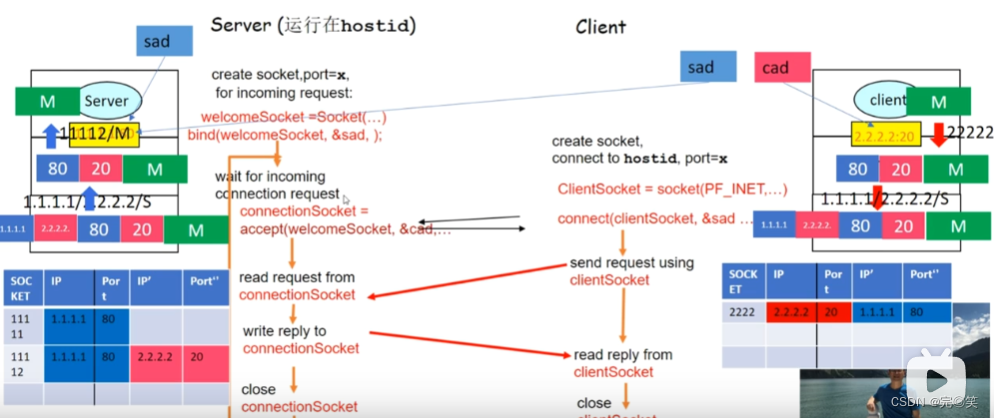
socket是啥?
网络套接字(Socket)通常被表示为一个类或类似于类的数据结构。网络套接字类封装了网络通信的细节,并提供了用于建立、发送和接收网络数据的方法和属性。常见的成员有源端口,目标端口,源IP,目标IP还有读写缓冲区。TCP现在的感觉就是一些类。socket将IP和port传给TCP,TCP根据port中的值封装出TCP报文,然后将TCP报文和IP地址交给IP。IP根据IP地址值封装出IP报文,然后将IP报文发送给服务端。服务端IP收到后,进行解封装得到TCP报文,和IP地址,然后将TCP报文和IP地址交给TCP.TCP得到TCP报文后进行解封装,得到报文和IP,PORT,然后根据IP和port将得到socket文件描述符,然后TCP将报文内容封装到服务端的socket里面(图片中科大郑烇老师)。
什么是多路IO转接?
概念:多路I/O转接(Multiplexing I/O)是一种技术,它允许单个进程同时监视和处理多个I/O流(如套接字、文件描述符)的输入和输出。多路I/O转接通过使用特定的系统调用,如select()、poll()、epoll()等,可以同时监视多个I/O流的状态,当在有可读,可写和异常事件发生时通知应用程序,而不需要阻塞整个进程。


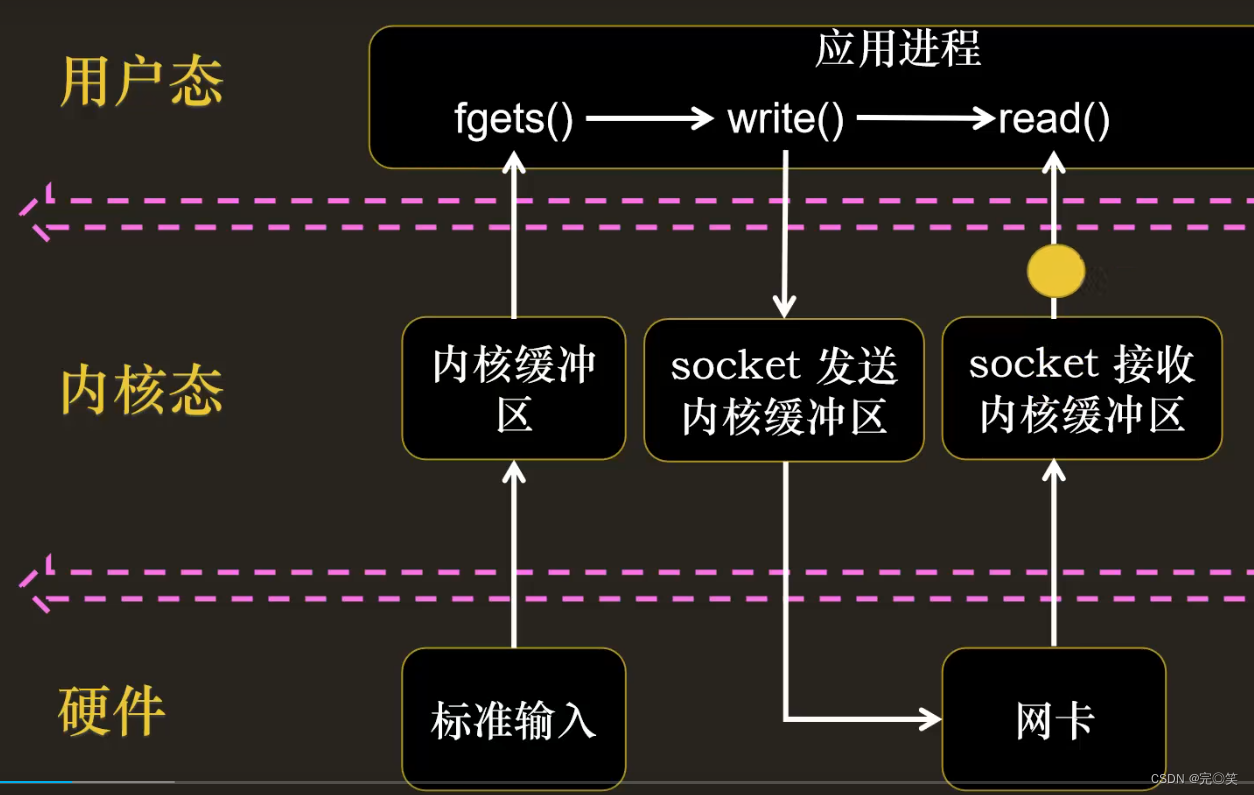
在传统的阻塞I/O模型中,当一个I/O操作阻塞时(比如这个IO一直发消息),整个进程会被阻塞,无法处理其他的I/O操作,从而导致效率低下。比如说:服务器进程监听控制台IO和socket IO。监听到内核缓冲区有控制台IO的信息,然后调用fgets,发送给应用进程,应用进程进行逻辑处理。然后监听内核缓冲区是否有socket IO的信息,然后调用read,发送给应用进程,应用进程进行逻辑处理,然后循环监听,又开始监听控制台IO,这时候如果socket IO如果有消息将被控制台IO阻塞。
还有一种是忙轮训+非阻塞IO也不好,轮训的过程中会占用CPU。
select,poll,epoll之间的区别和优缺点
每次执行select或poll调用后,应用程序需要采用遍历的方式,遍历整个文件描述符集合去判断各个文件描述符是否就绪;epoll则不需要去以这种方式检查,当有活动产生时,内核将这些就绪的文件描述符放到之前提到的ready list中等待epoll_wait调用后被处理。
对于select和poll:文件描述符集合是在用户态(应用程序)中创建和维护的。每次调用select或poll函数时,需要将整个文件描述符集合从用户态拷贝到内核态。内核在处理完I/O事件后,再将就绪的文件描述符集合从内核态拷贝回用户态,以供应用程序进行处理。这种方式意味着每次调用select或poll时都需要将整个文件描述符集合从用户态拷贝到内核态,可能会引起一定的性能开销。特别是当文件描述符集合较大时,拷贝的开销会更加显著。对于epoll:文件描述符集合被维护在内核态。每次添加文件描述符到epoll实例时,需要执行一个系统调用。内核会直接管理和维护文件描述符集合,无需进行用户态和内核态之间的重复拷贝。

epoll底层实现:
epoll 模型的实现主要包括以下几个组件:epoll_create 系统调用:创建 epoll 实例,并返回一个对应的文件描述符。实际上,epoll_create 函数会在内核中创建一个红黑树和一个双向链表,用来存储事件集合和就绪事件的信息。epoll_ctl 系统调用:用来添加、修改或删除事件。当我们通过 epoll_ctl 函数向 epoll 实例中添加一个事件时,内核会在红黑树中创建一个节点,并将该节点与指定的文件描述符相关联。epoll_wait 系统调用:用来等待就绪事件。当我们调用 epoll_wait 函数时,内核会遍历红黑树,查找是否有文件描述符对应的节点上有就绪事件。如果找到了就绪事件,内核会将它加入到双向链表中的就绪队列中。最后,epoll_wait 函数会返回就绪事件的信息,供应用程序处理。
epoll为啥有ET模式和LT模式,分别适用于什么样的场景?
ET:1.在ET模式下,当文件描述符上有新的数据可读或可写时,内核仅通知一次。2.鉴于1的原因ET模式要求应用程序立即处理所有可读或可写的数据,否则会造成数据堆积或资源耗尽。3.综上:ET模式适用于高效处理数据的场景,要求立即处理所有可读或可写的数据。
LT:1.在LT模式下,当文件描述符上有新的数据可读或可写时,内核会重复通知应用程序,直到应用程序处理完所有可读或可写的数据并不再阻塞。2.鉴于1的原因LT模式适用于需要对数据进行轮询或按需处理数据的场景,例如使用非阻塞I/O的应用程序,可以在处理完一部分数据后继续进行其他操作。
reactor和proactor异同
阻塞IO:当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。阻塞等待的是内核数据准备好和数据从内核态拷贝到用户态的过程。
非阻塞IO:非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。当内核数据准备好拷贝到应用程序缓冲区,是一个同步的过程,是需要等待的过程。
如果 socket 设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
同步IO:无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
异步IO:「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
reactor和proactor模式的优缺点:
reactor优点:实现相对简单,对于耗时短的处理场景处理高效,主线程会在事件处理器中执行相应的操作,此时会阻塞等待操作完成。
reactor缺点:reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理。
proactor的优点:能够处理耗时长的并发场景,避免了主线程的阻塞。
proactor的缺点:在 Linux 下的异步 I/O 是不完善的,aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的。
HTTP状态机解析&响应请求报文
有限状态机
有限状态机一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
解析报文
从状态机负责读取报文的一行,主状态机负责对该行数据进行解析,主状态机内部调用从状态机,从状态机驱动主状态机。
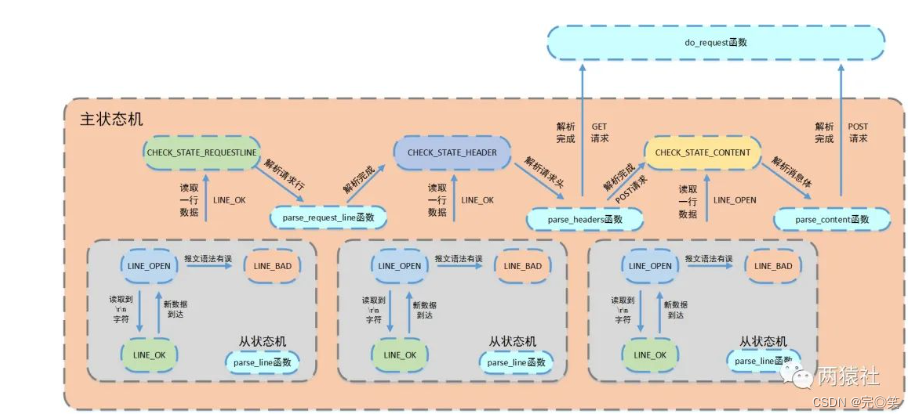
从状态机 1.三种状态:LINE_OK(读取完整的一行)、LINE_OPEN(读取的行不完整)和 LINE_BAD(报文的语法有错)。
2.从状态机初始状态为LINE_OK,每次调用parse_line()读取缓冲区中的报文改变状态
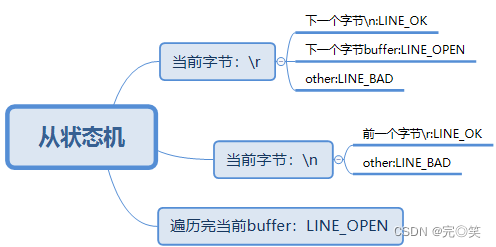
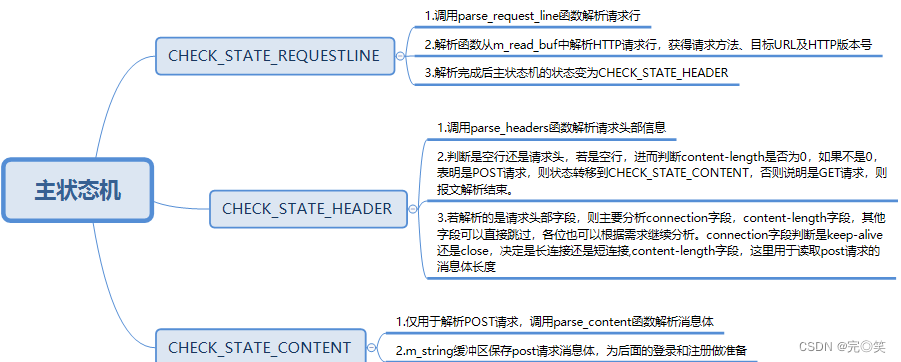
主状态机 1.三种状态:CHECK_STATE_REQUESTLINE(解析请求行)、 CHECK_STATE_HEADER(解析请求头)和CHECK_STATE_CONTENT(解析请求 体)。
2.主状态机初始状态是CHECK_STATE_REQUESTLINE,通过调用从状态机来驱动 主状态机。
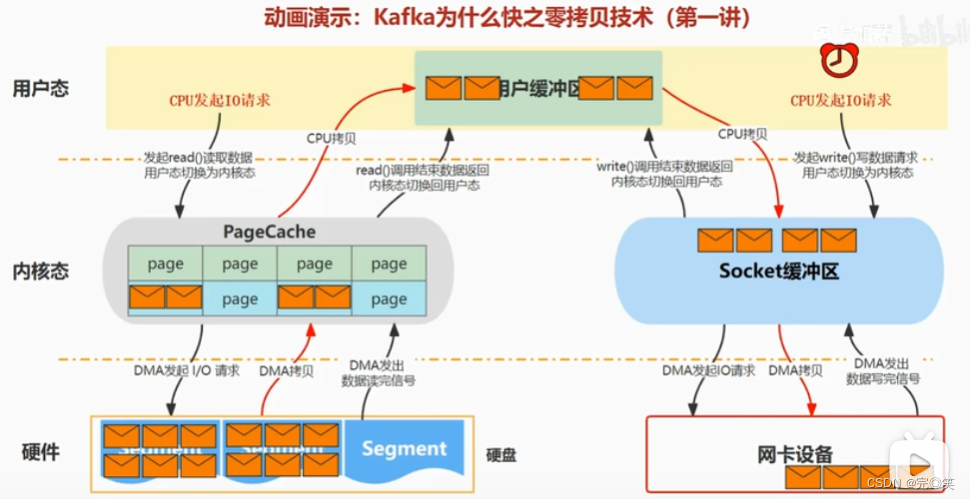
零拷贝(b站up码上加薪)
概念:零” :表示次数为0,它表示拷贝数据的次数为0。“拷贝”:就是指数据从一个存储区域转移到另一个存储区域。零拷贝就是不需要将数据从一个存储区域复制到另一个存储区域。零拷贝并不是没有拷贝数据,而是减少用户态/内核态的切换次数以及CPU拷贝的次数。
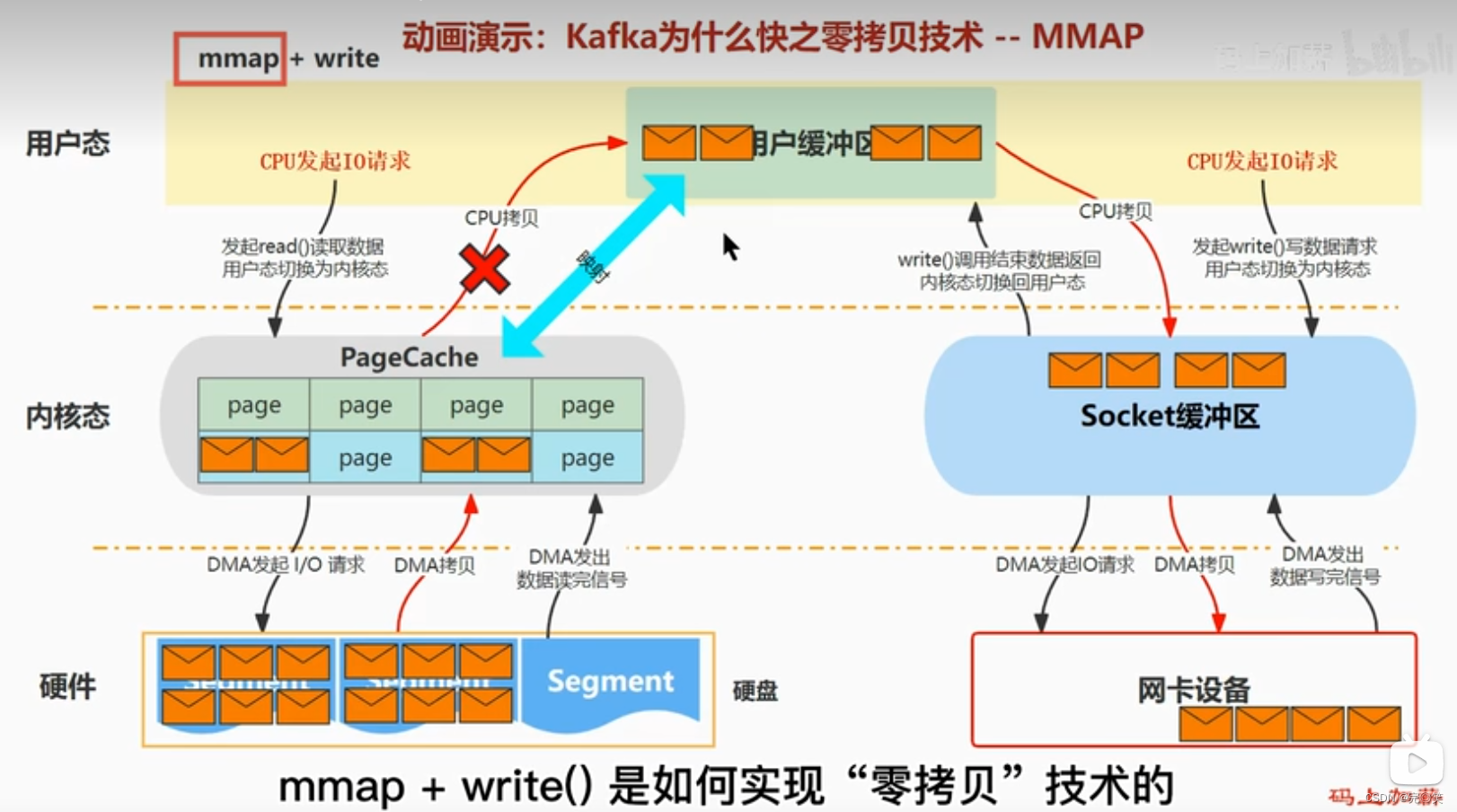
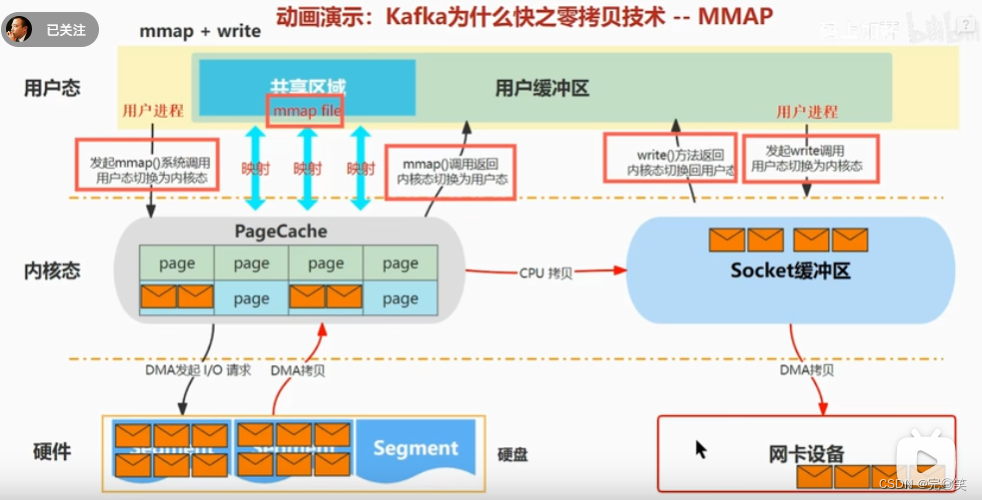
mmap
mmap()函数将文件映射到内存是一种常见的操作,它允许将一个文件的内容直接映射到进程的虚拟内存空间,从而使得文件的数据在内存中以页的形式可访问。mmap是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,所以节省了一次CPU拷贝。
线程池相关
如何设计
(1)设置一个生产者消费者队列,作为临界资源。
(2)初始化n个线程,并让其运行起来,加锁去队列里取任务运行
(3)当任务队列为空时,所有线程阻塞。
(4)当生产者队列来了一个任务后,先对队列加锁,把任务挂到队列上,然后使用条件变量去通 知阻塞中的一个线程来处理。
参数选择
(1) 线程池大小:线程池大小是指线程池中同时运行的线程数量。
项目中:开启了8条线程。
threadpool(connection_pool *connPool, int thread_number = 8, int max_request = 10000);(2) 队列容量:队列容量指的是线程池任务队列能够容纳的最大任务数量
项目中:最大任务数量是10000
(3)拒绝策略:拒绝策略用于处理线程池已满时的新任务。
项目中:采用丢弃策略,不进行任何处理。
//向线程池的队列中添加任务
bool threadpool<T>::append(T *request)
{
m_queuelocker.lock();
if (m_workqueue.size() > m_max_requests)
{
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlock();
m_queuestat.post();//唤醒等待的线程(将信号量的值+1),以便它们可以处理队列中的请求。
return true;
}if (users[sockfd].read_once()){
LOG_INFO("deal with the client(%s)", inet_ntoa(users[sockfd].get_address()->sin_addr));
Log::get_instance()->flush();
//若监测到读事件,将该事件放入请求队列
pool->append(users + sockfd);
//若有数据传输,则将定时器往后延迟3个单位
//并对新的定时器在链表上的位置进行调整
if (timer){
time_t cur = time(NULL);
timer->expire = cur + 3 * TIMESLOT;
LOG_INFO("%s", "adjust timer once");
Log::get_instance()->flush();
timer_lst.adjust_timer(timer);
}
}(4)线程创建方式:线程池可以选择在启动时创建一组固定数量的线程,也可以选择按需创建线 程。
项目中:在线程池的构造函数中创建8个线程。
template <typename T>
threadpool<T>::threadpool( connection_pool *connPool, int thread_number, int max_requests) : m_thread_number(thread_number), m_max_requests(max_requests), m_stop(false), m_threads(NULL),m_connPool(connPool)
{
if (thread_number <= 0 || max_requests <= 0)
throw std::exception();
m_threads = new pthread_t[m_thread_number];
if (!m_threads) throw std::exception();
for (int i = 0; i < thread_number; ++i)
{
//m_threads + i:指向 pthread_t 类型的指针,用于存储新创建的线程的 ID。返回0,表示线程创建成功
if (pthread_create(m_threads + i, NULL, worker, this) != 0)
{
delete[] m_threads;
throw std::exception();
}
//pthread_detach() 函数的返回值为 0 表示分离线程成功
if (pthread_detach(m_threads[i]))
{
delete[] m_threads;
throw std::exception();
}
}
}(5)核心线程数:核心线程数是指线程池中始终保持存活的线程数量。无论这些核心线程是否正 在执行任务,它们都会一直存在于线程池中,以提供即时的任务处理能力。如果线程池中的 任务数量超过了核心线程数,新的任务将会被放入任务队列中等待执行。
最大线程数:最大线程数是线程池能容纳的最大线程数量,包括核心线程和非核心线程(临 时线程)。当任务队列已满且核心线程数已达到上限时,线程池会创建额外的非核心线程来 处理任务。这些非核心线程在完成任务后,如果一段时间内没有新的任务可执行,会被线程 池自动回收销毁,以避免长时间占用系统资源。
(6)线程空闲时间:线程空闲时间指的是线程在没有任务可执行时的等待时间。如果线程空闲时 间过长,可以选择终止空闲线程以释放系统资源;如果线程空闲时间较短,可以选择让线程 保持活动状态以减少线程创建和销毁的开销。
最大线程数和核心线程数该怎么设置
对于任务耗时较短的情况:线程数不宜过多
对于任务耗时较长的情况:如果是IO密集型任务,那CPU空闲时间比较多,那就可以适当增加 线程 数,增加CPU利用率。比如:4核CPU,考虑将核心线程数设置为5或6。这样可以确保在 执行I/O操作期间,仍有一些额外的线程可供其他任务使用,以充分利用CPU的并行处理力。如 果是CPU密集型任务,CPU一直被占用计算,线程数不应该过过多。比如:4核CPU,可以考虑 将核心线程数设置为4或稍小。这样可以确保每个CPU核心都有一个线程来执行任务。最大限度 地利用CPU资源。
阻塞队列
阻塞队列是一种支持并发操作的队列数据结构,它提供了线程安全的入队和出队操作,并且在 队列为空时,出队操作会阻塞等待直到队列非空,在队列已满时,入队操作会阻塞等待直到队 列有空闲位置。
项目中使用互斥量+条件变量实现线程安全和阻塞等待。添加任务:任务入队前先获取互斥锁, 入队后释放互斥锁并唤醒阻塞在条件变量上的线程。执行任务:当阻塞在条件变量上的线程被 唤醒后,首先获得获取互斥锁,然后取出队头元素,解锁,执行任务。
拒绝策略
(1) 默认策略:拒绝新任务并抛出std::runtime_error异常。这是默认的拒绝策略,会导致提交的任务无法执行。
(2)Discard Policy:拒绝新任务并丢弃该任务,不会进行任何处理。
(3)Discard Oldest Policy:拒绝新任务,并丢弃线程池中最早提交的任务(即等待时间最长的 任务),然后尝试再次提交新任务。
(4)Caller Runs Policy:拒绝新任务,并将该任务交给提交任务的线程来执行。这种策略可以避 免任务丢失,但是会导致提交任务的线程也参与任务执行,可能会导致调用线程阻塞。
项目中使用第二种策略。
线程池中的任务存了什么
线程池中任务存放的是http_conn对象,首先这个对象封装了与客户端通信的套接字,然后维护了一个缓冲区用来存放通讯报文,还有一个核心函数(process)用来解析报文和进行报文相应。
线程池的半同步半反应堆模式
概念:一种结合了同步模型和反应堆模式的并发编程模式。
同步部分:同步部分通常由一个线程池组成,负责处理一些短时间内可以完成的任务,如请求的解析、身份验证等简单任务。
反应堆部分:反应堆部分由一个事件循环线程(也称为反应堆线程)组成,负责处理长时间运行的任务,如I/O操作和复杂的业务逻辑。
缺点:主线程和工作线程共享请求队列。主线程添加任务,工作线程取出任务,都需要对请求队里进行加锁保护,从而耗费cpu时间。
c++部分知识
前置知识:
std::function:函数包装器模板
#include <iostream>
#include <functional>
using namespace std;
template <class T>
T g_Minus(T i, T j){
return i - j;
}
int main(){
function<int(int, int)> f = g_Minus<int>;
cout << f(1, 2) << endl;
return 0;
} std::unique_lock :可以使用互斥锁作为底层数据结构
//互斥锁作为底层实现结构
std::unique_lock<std::mutex> lock(mutex_);std::move: C++11提供一个函数std::move()来将一个左值强制转化为右值
std::forward:完美转发,看下面的例子
//下面这个例子就不是完美转发
#include <iostream>
using namespace std;
void func(int& i) {
cout << "func(int&):" << i << endl;
}
void func(int&& i) {
cout << "func(int&&):" << i << endl;
}
void myforward(int&& i) {
cout << "myforward(int&&):" << i << endl;
func(i);
}
int main() {
myforward(2);
return 0;
}
//下面的这个例子就是完美转发
#include <iostream>
using namespace std;
void func(int& i) {
cout << "func(int&):" << i << endl;
}
void func(int&& i) {
cout << "func(int&&):" << i << endl;
}
void myforward(int&& i) {
cout << "myforward(int&&):" << i << endl;
func(std::forward<int>(i));
}
int main() {
myforward(2);
return 0;
}
void ThreadWorker() {
while (true) {
std::function<void()> task;
{
//互斥锁作为底层实现结构
std::unique_lock<std::mutex> lock(mutex_);
//条件变量首先会获取lock,并检查条件是否满足,如果条件满则会立即返回。
//如果条件不满足,则释放lock,等待其他线程的唤醒,唤醒后重新获取后重新获取锁,并判断条件。
condition_.wait(lock, [this] { return stop_ || !tasks_.empty(); });
if (stop_ && tasks_.empty()) {
return;
}
task = std::move(tasks_.front());
tasks_.pop();
}
task();
}
}原子操作:直接看代码
#include <atomic>
#include <vector>
#include <thread>
#include <iostream>
//std::atomic<int> num(0);
int num = 0;
int count(){
for (int i = 0; i < 10000; i++){
num++;
}
}
int main() {
clock_t start = clock();
//创建4个线程
std::vector<std::thread> threads;
for(int i = 0; i < 4; i++){
threads.push_back(std::thread(count));
}
for(int i = 0; i < 4; i++){
threads[i].join();
}
std::cout << num;
clock_t finish = clock();
std::cout << "duration:" << finish - start << "ms" << std::endl;
}
模板参数包,函数参数包:两者配合使用可以实现函数接受任意数量,任意类型的参数
#include <iostream>
// 可变参数模板函数,接受可变数量的模板参数和函数参数
template<typename... Ts>
void printArgs(const Ts&... args) {
std::cout << "Template Arguments: ";
(std::cout << ... << args) << std::endl; // 展开函数参数包,打印参数
}
int main() {
printArgs(1, 2.5, "Hello", 'a'); // 调用可变参数模板函数
return 0;
}