众所周知,爬虫玩的好,牢饭吃的早(如有侵犯利益,请您告知,我将立删!)。
其实抓包嘛,简单的H5网页直接就能用浏览器的开发者工具进行抓包,但是很多平台剔除了网页版,如果有网页版当然我们用py或者Java都能爬,无非是单次会话先登录获取自己的相关校验参数,带着参数去爬拿到商家数据之后快速持久化或者提前解码(很久之前爬到一堆乱码,有的网页简单的是Base64的编码,但是meituan的就是woff),近期测试一下如何爬取app的数据,所以我就研究了一下怎么爬美团外卖的数据,拿到数据了再怎么用Java 将数据的XML文件或者JSON进行解析持久化,到MYSQL之后进行SQ分析。本章主要是记录我使用抓包工具结合局域网代理技术去爬meituan的一些商家数据(其实也就是大家使用APP时眼里能看到的数据而已,并不能拿到人家接口不返回的数据,要是能击穿那世界上抓包的工具不还翻了天啦)。
1、学习代理技术
代理技术是一种在因特网中实现代理服务的技术。通过代理,用户或设备可以通过代理服务器访问互联网,同时可以提供其他功能,如访问控制、缓存、安全性等。以下是几种常见的局域网代理技术:
1. HTTP代理:HTTP代理是最常见的代理技术之一。它基于HTTP协议,允许客户端通过代理服务器发送HTTP请求并接收响应。HTTP代理可以用于过滤和监控网络流量。
2. SOCKS代理:SOCKS(Socket Secure)代理是一种网络协议,允许客户端与代理服务器建立通信并通过代理服务器与远程主机进行通信。SOCKS代理可以用于支持各种应用程序,如网络浏览器、邮件客户端等。
3. 路由器代理:某些路由器设备具有代理功能,可以在局域网中充当代理服务器。这些路由器可以配置为代理网络流量,并提供访问控制、缓存、内容过滤等功能。
4. 反向代理:反向代理是一种位于服务器端的代理服务器,用于接收客户端请求并将其转发到后端服务器。反向代理可以提供负载均衡、安全性、缓存等功能,还可以隐藏后端服务器的真实地址。
其中最常见的反向代理与路由器代理一个影响着我们的软件世界,一个则影响着我们的Internet世界,其余的则是在网络传输与通信过程中的代理技术,套接字代理也是很常用的。
我们要想抓app的包,就必须要我们的计算机可以获取到手机app的访问情况,那么以上四种代理技术,只有HTTP代理可以快速的帮助我们(你想想,我们的手机访问app的接口,那么我们就是客户端,而HTTP代理正是将客户端的请求与传输先行经过代理服务器上的,也就是说这条链路其实是:rpc server ----> proxy ------> my phone,反之亦然)。
那么你想,如果请求的出口是proxy,而恰好proxy是我的电脑,对不对?那我只需要有一个可以作为端口代理的软件并且恰好它能够监控出口的访问情况,是不是就可以抓到app的包了?
2、一款代理软件且支持https且还能监控出口访问情况 fiddler
这个软件很好用,自己安装去。谢谢(我这里不分享安装配置的操作,网上一堆呢)!
3、将手机的代理服务器配置成你运行fiddler的计算机(端口是fiddler内部连接的配置端口,IP是计算机在局域网内部的IP地址,手机注意也要链接同一局域网)
我认为在这里你已经成功的配置好了fiddler且你也已经解决了HTTPS的配置项问题。
那么接下来就是分享如何处理你抓的数据了:
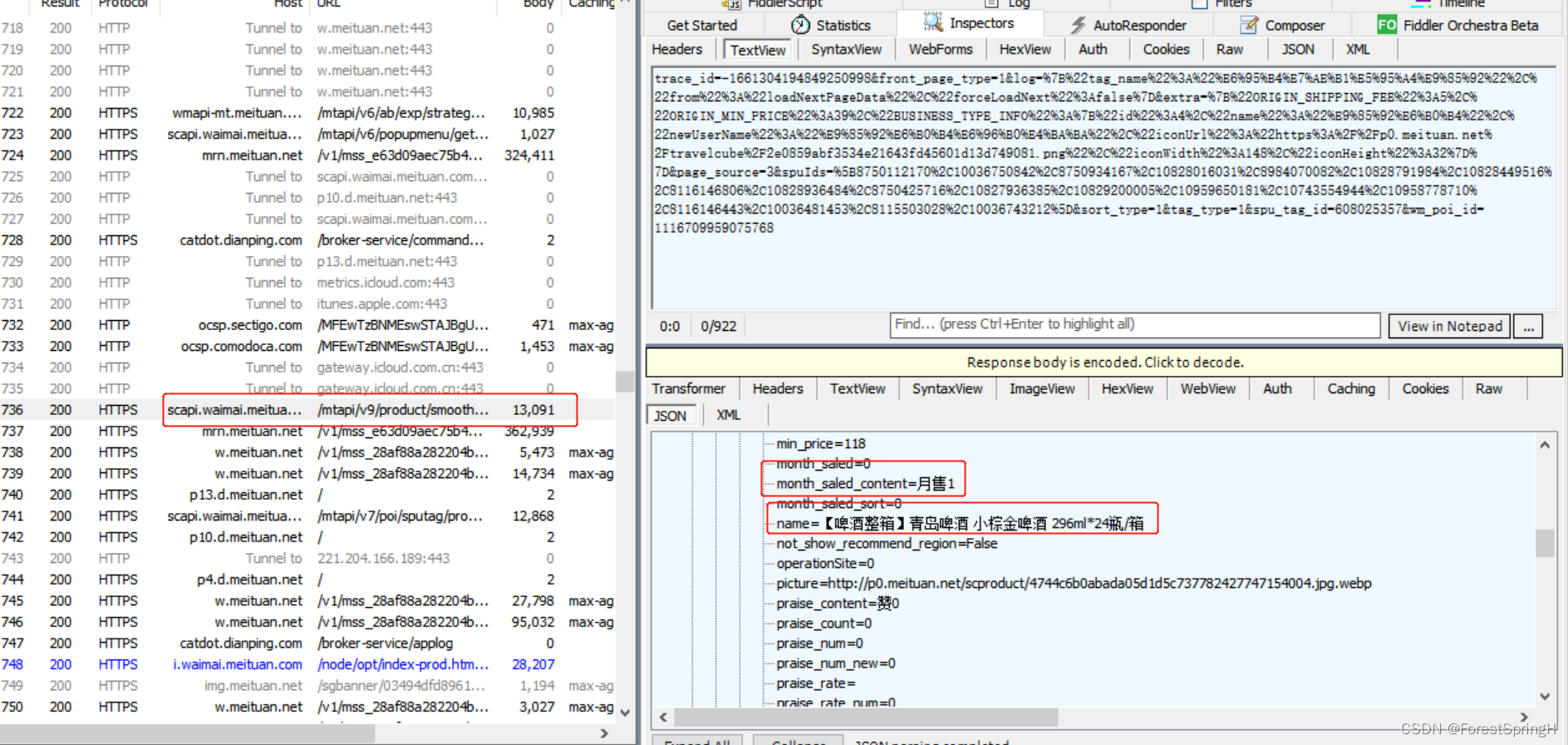
我现在抓的是20条某店铺的spu商品列表,关键的数据是最低价118,月售数量1,品名青岛啤酒.....
其实到这里很多兄弟就明白了,解决了数据源的问题,那就写个小应用把JSON解析出来我们想要数据并持久化咯。
后面解析这些字串的小应用就不分享了,无非是解析text文件,扫描json串并截断。封装数据利用ORM持久化数据。