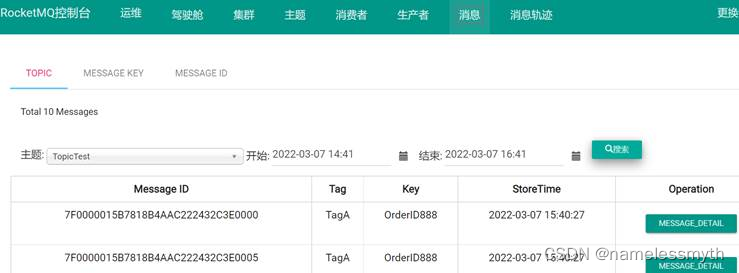
Transformer是一个深度学习模型。主要功能通俗的来说就是翻译。输入,处理,输出。
https://zhuanlan.zhihu.com/p/338817680 大牛写的很完整
目录
- 总框架
- Encoder
- 输入部分
- 注意力机制
- 前馈神经网络
- Decoder
总框架
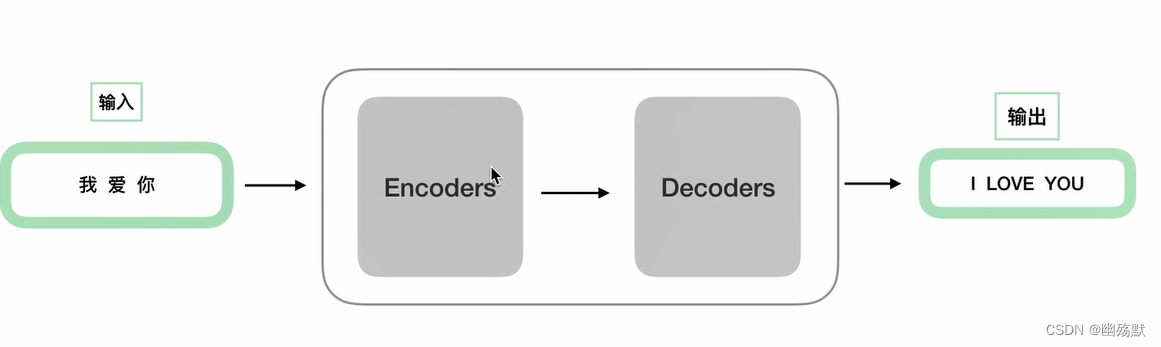
- Encoders: 编码器
- Decoders: 解码器
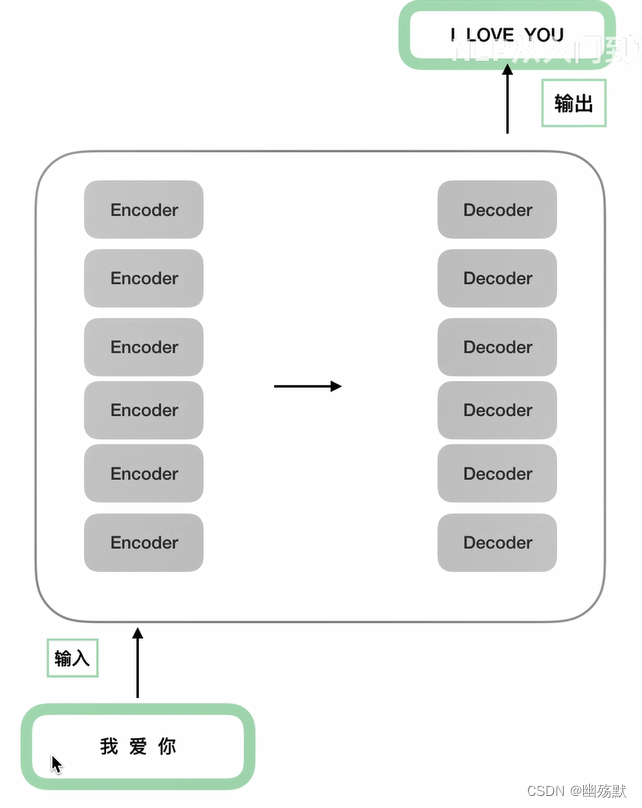
Encoder和Decoder结构是不同的,6个Encoder是完全相同的,6个Decoder是完全相同的。
这里的6个Encoder完全相同,指的是结构相同但是参数不同。
Encoder
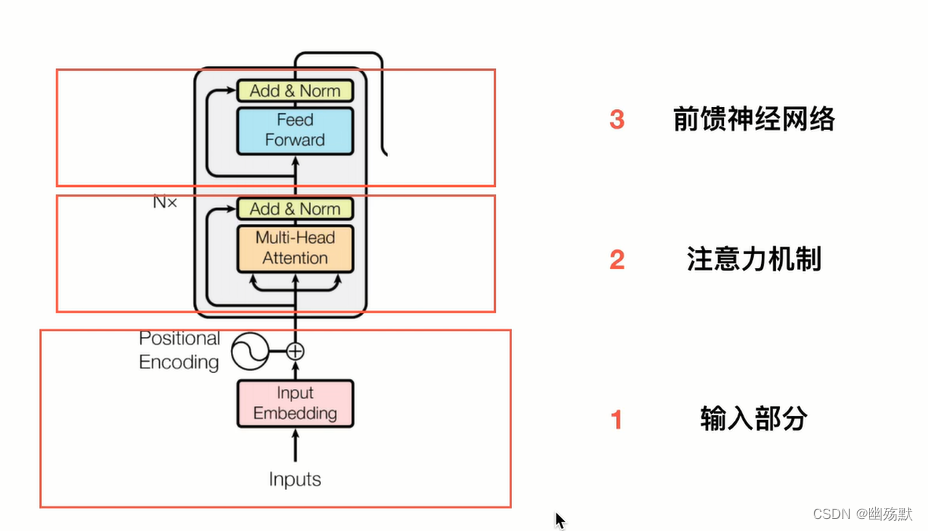
输入部分

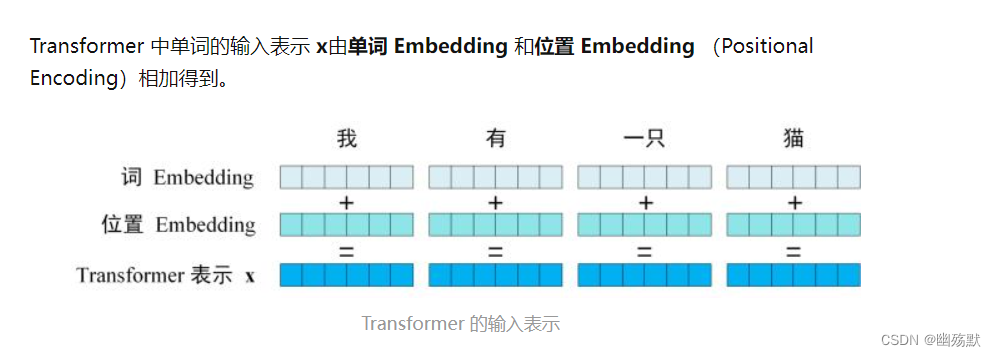
Embedding翻译成中文: 嵌入。
输入部分:
- 单词 Embedding(Embedding就是从原始数据提取出来的Feature)
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。 - 位置 Embedding
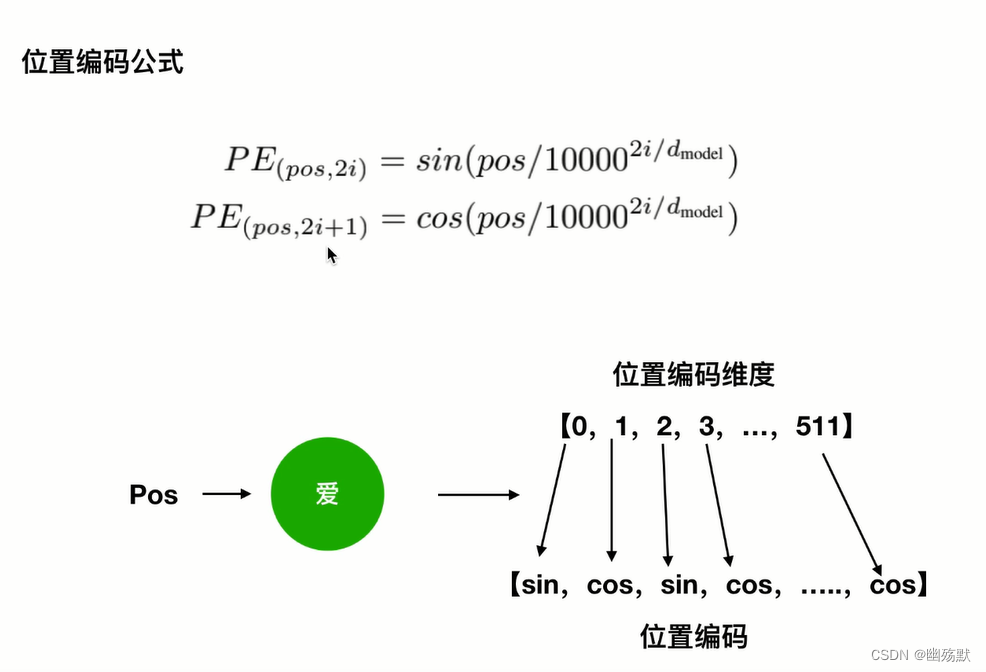
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。

注意力机制
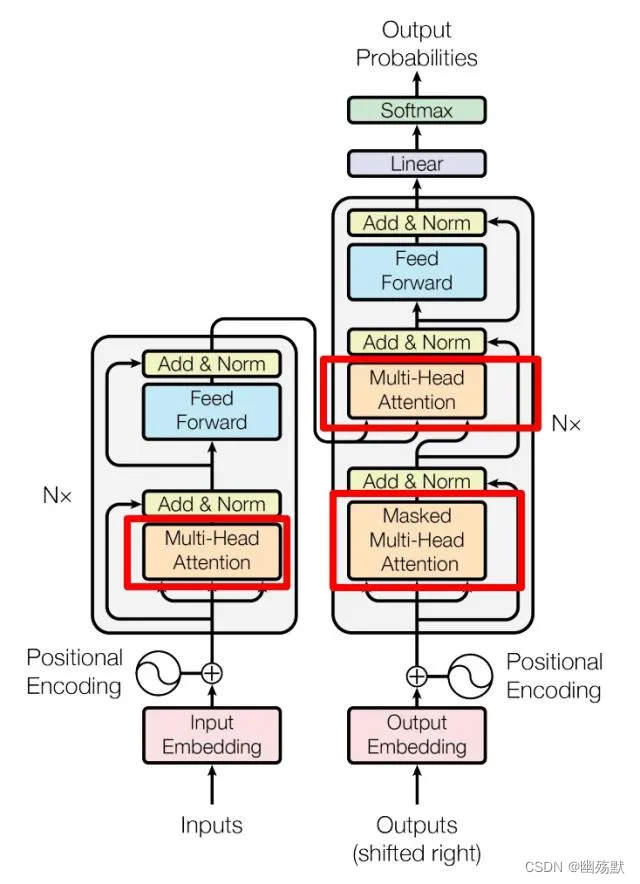
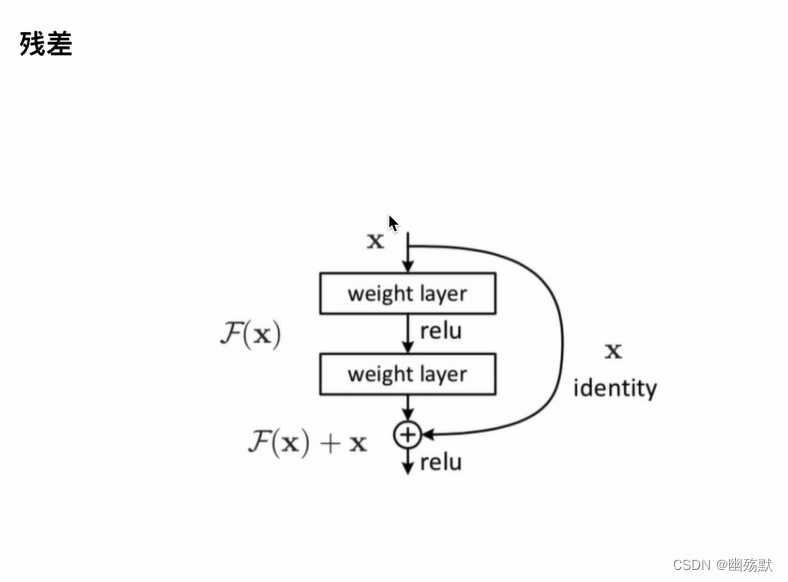
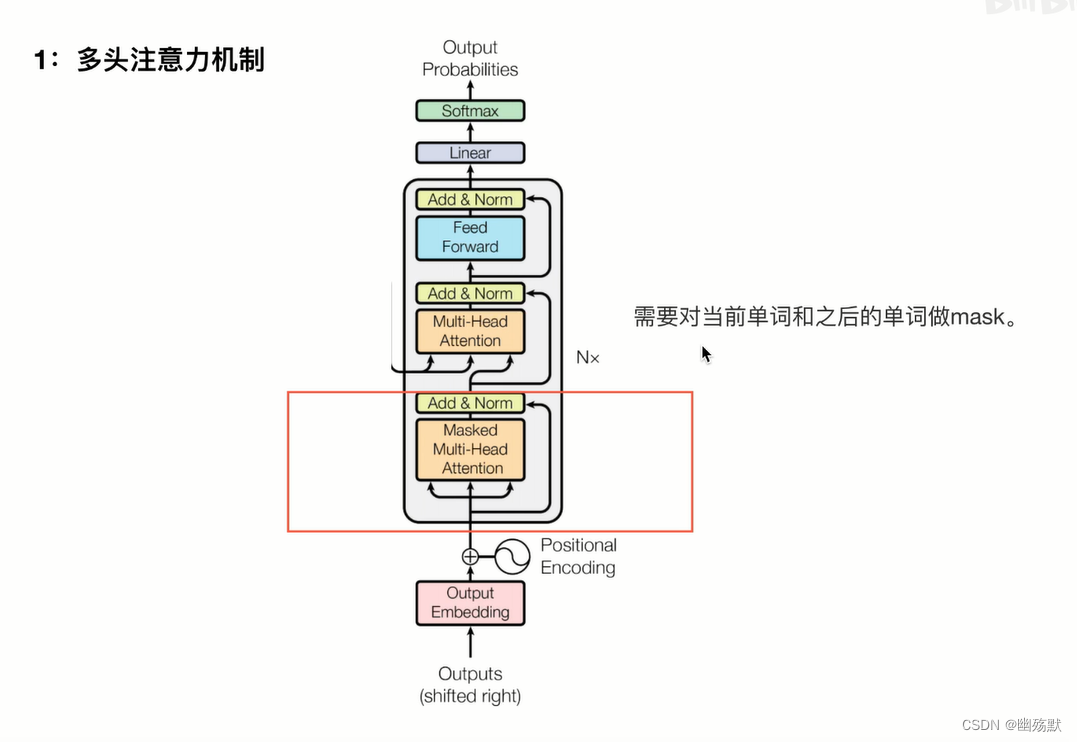
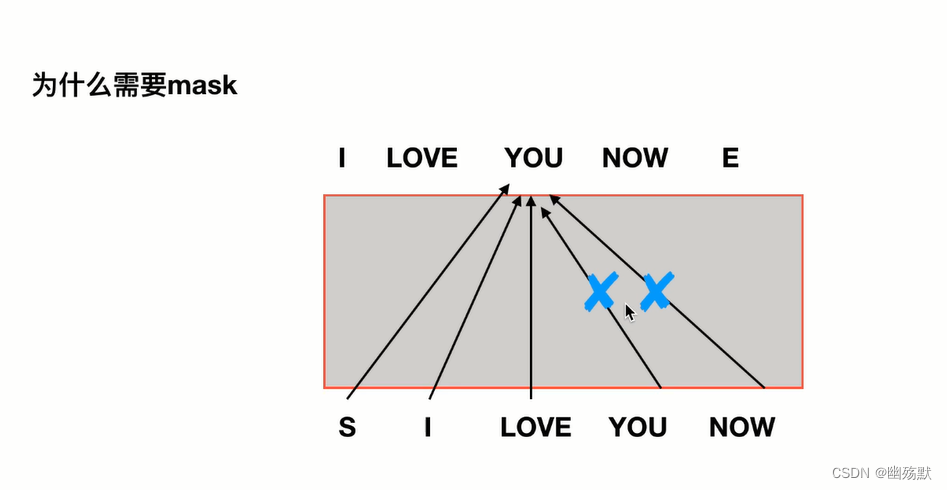
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
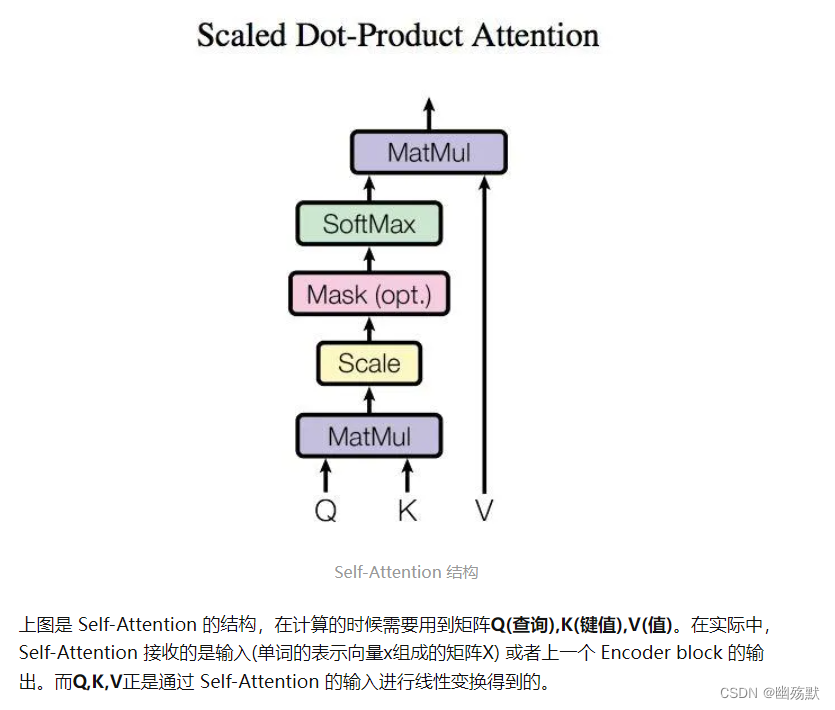
Q, K, V 的计算
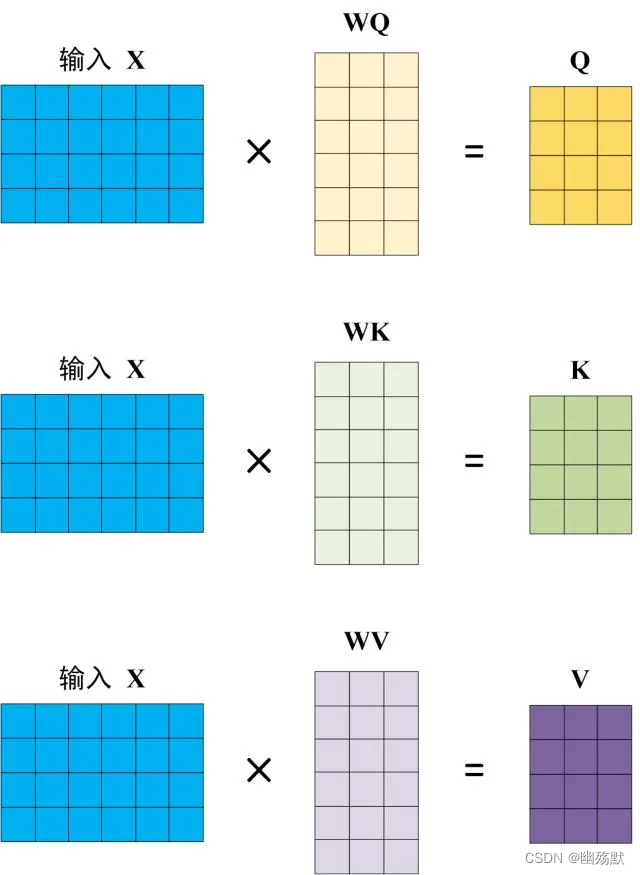
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。
计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
Self-Attention 的输出

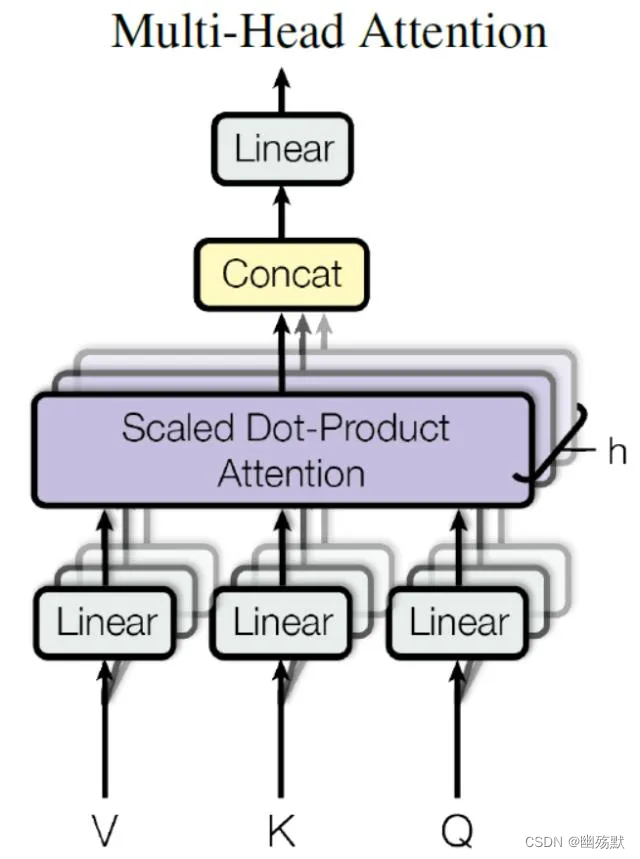
Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
残差和LayNorm
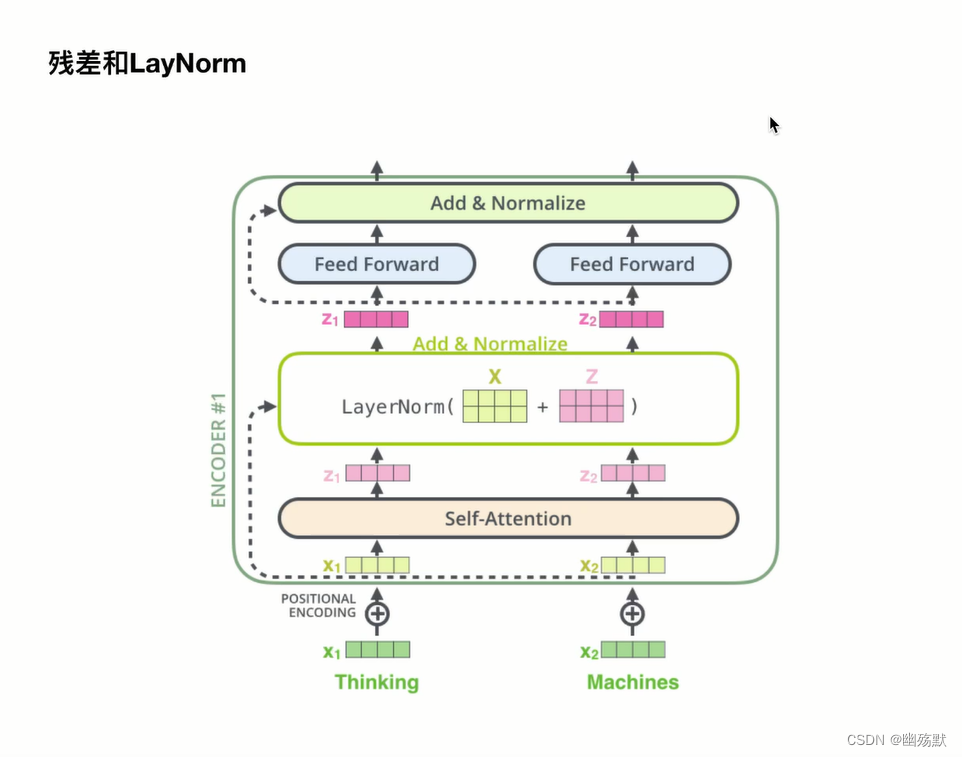
Add and Norm
Add表示残差连接(Residual Connection)用于防止网络退化,Norm表示Layer Normalizaion,用于对每一层的激活值进行归一化。
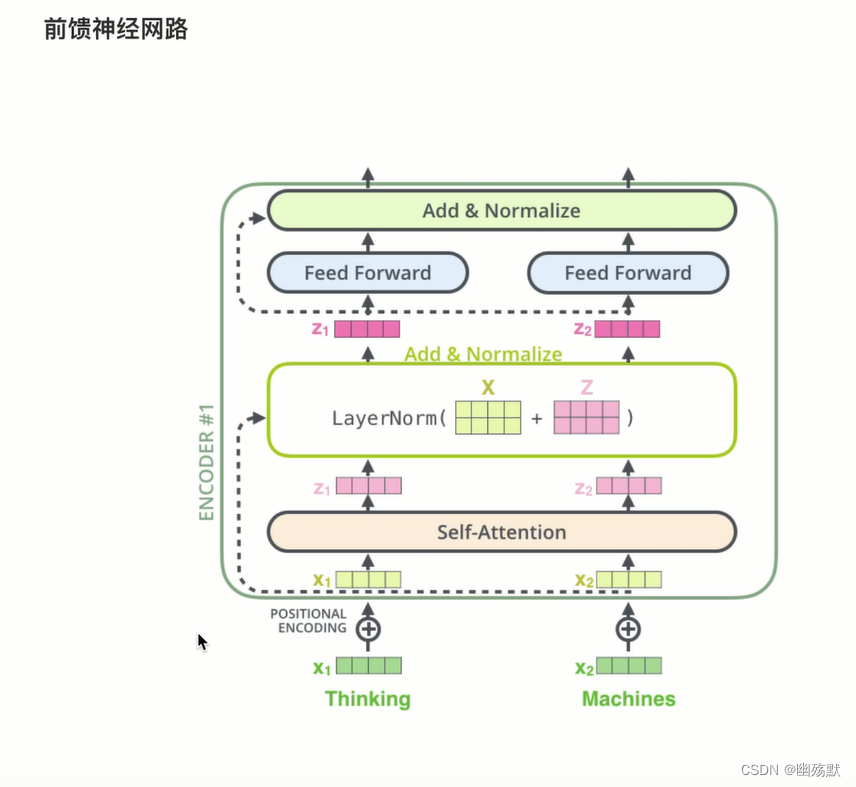
前馈神经网络

Decoder
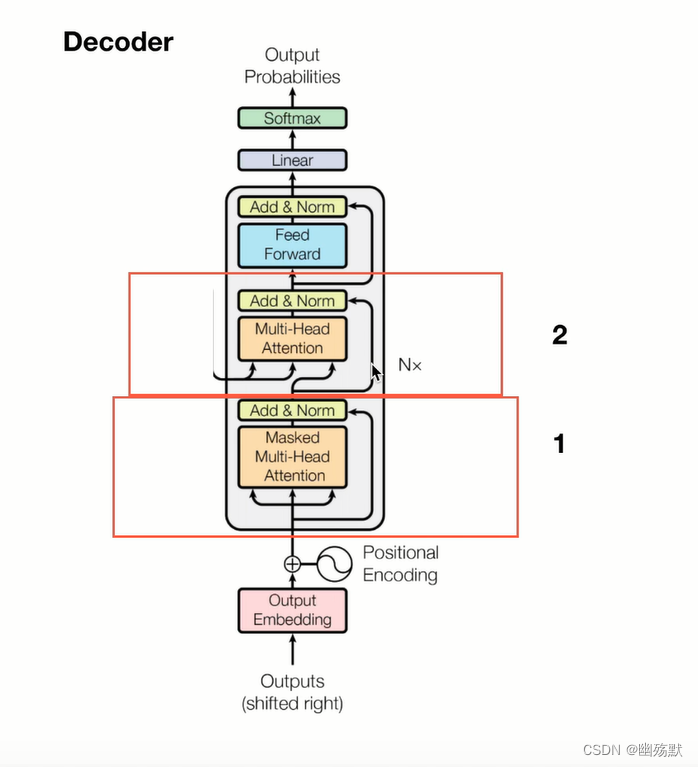

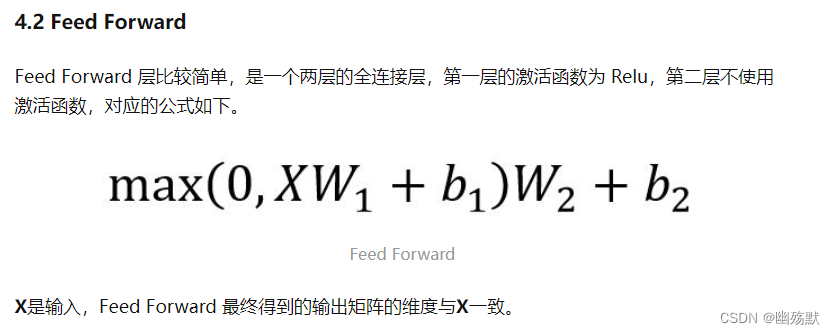
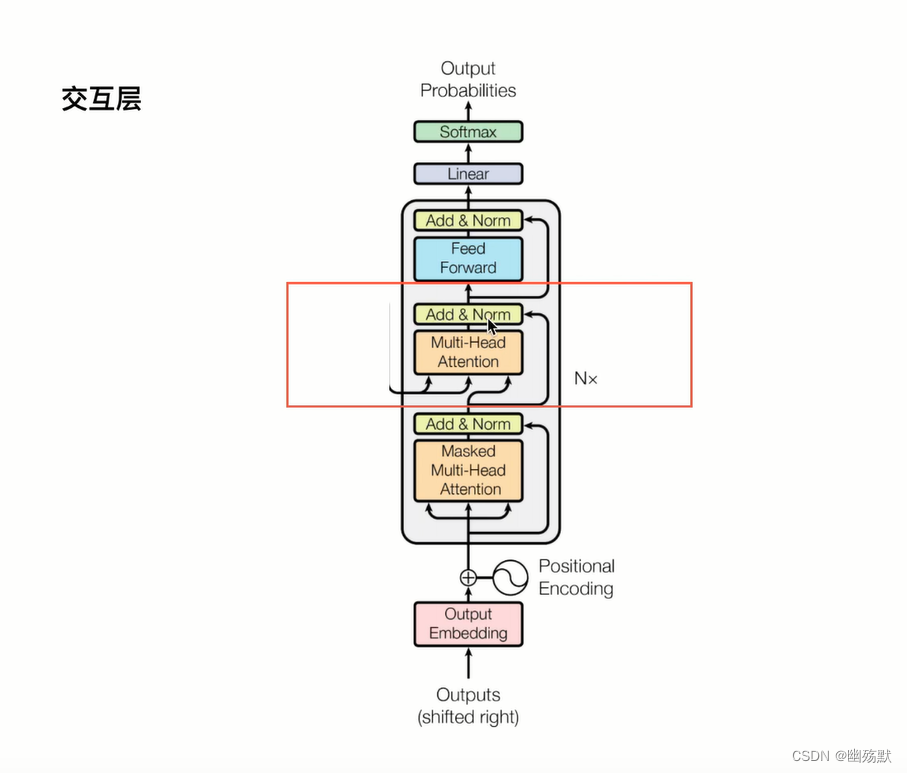
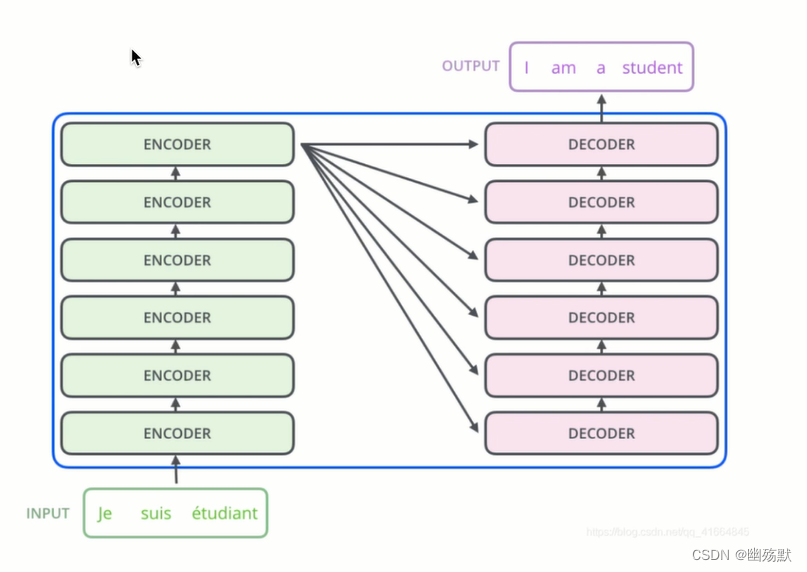
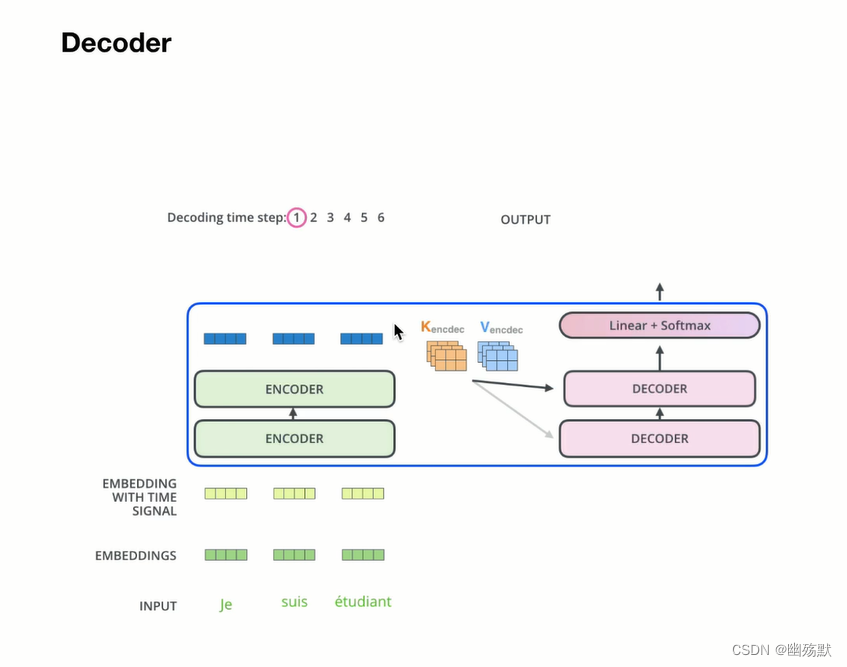
Encoder的每一个输出和每一个Decoder都做交互。