1. 引言
随机森林是集成学习中的一颗瑞士军刀,它是一种强大的机器学习算法,常用于分类和回归任务。随机森林集合了“三个臭皮匠,顶个诸葛亮”的智慧,通过组合多个决策树的预测结果,来提高模型的鲁棒性和性能。
2. 随机森林的原理
2.1 决策树简介
在介绍随机森林之前,我们先来了解一下决策树。决策树是一种常用的分类和回归算法,它通过不断对特征进行划分,构建一棵树状结构来进行预测。每个非叶节点表示对一个特征的划分,每个叶节点表示一个类别或预测值。
2.2 随机森林的构建过程
随机森林的构建过程分为两个主要阶段:随机选择特征和随机选择样本。
随机选择特征:在每个决策树的节点,随机选择一部分特征来进行划分。这样做的目的是减少特征之间的相关性,增加每棵树之间的差异性,从而提高整体模型的性能。
随机选择样本:在每个决策树的训练过程中,从原始训练集中随机有放回地抽取一部分样本来进行训练。这被称为自助采样(Bootstrap Sampling)。通过自助采样,每棵树都会有一部分数据没有被选中,从而增加了集成模型的多样性,防止过拟合。
2.3 随机森林的预测
对于分类问题,随机森林通过投票法(硬投票)来决定最终的预测类别。每棵决策树都会给出一个预测结果,最终的预测结果为多数投票得出的类别。
对于回归问题,随机森林通过平均法来决定最终的预测值。每棵决策树都会给出一个预测结果,最终的预测结果为所有决策树预测值的平均值。
3. 随机森林的优势
3.1 高度鲁棒性
随机森林通过集成多个决策树的结果,对异常值和噪声具有很好的鲁棒性。单个决策树可能会过拟合,但是多个决策树的组合可以有效地减少过拟合的风险。
3.2 可解释性
相比于一些复杂的深度学习模型,随机森林是一种相对简单的算法,易于理解和解释。决策树可以可视化,帮助我们理解模型的决策过程。
3.3 特征重要性评估
随机森林可以通过特征重要性评估每个特征对于模型性能的贡献程度。这个信息可以帮助我们选择重要特征,进行特征工程,提高模型的性能。
3.4 并行计算
随机森林的训练过程可以并行计算,因为每棵树都是独立训练的。这使得随机森林在大规模数据集上具有较高的计算效率。
4. 随机森林的实战项目
代码如下:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器
rf_model = RandomForestClassifier(n_jobs=-1) # n_jobs=-1表示使用所有的CPU核心
# 加入网格搜索和交叉验证
from sklearn.model_selection import GridSearchCV
# 设置参数
param_grid = {
"n_estimators": [100, 200, 300, 400, 500],
"max_depth": [3, 5, 7, 9],
"max_features": [2, 3, 4],
"criterion": ["gini", "entropy"]
}
# 创建网格搜索对象
grid_search = GridSearchCV(estimator=rf_model, param_grid=param_grid, cv=3)
# 训练模型
grid_search.fit(X_train, y_train)
# 查看最优参数
print("最优参数:", grid_search.best_params_)
print("最优分数:", grid_search.best_score_)
print("最优模型:", grid_search.best_estimator_)
print("最优模型在测试集上的分数:", grid_search.best_estimator_.score(X_test, y_test))
# 使用最优模型进行预测
y_pred = grid_search.best_estimator_.predict(X_test)
# 查看准确率
print("准确率:", accuracy_score(y_test, y_pred))
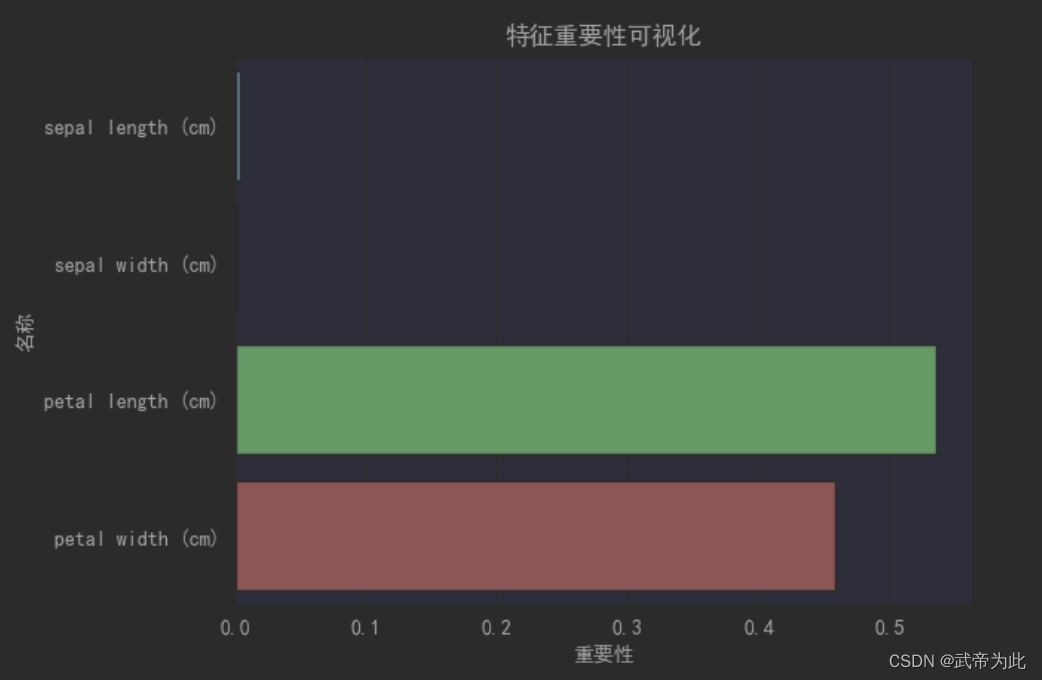
# 查看特征重要性
feature_importance = pd.Series(grid_search.best_estimator_.feature_importances_, index=iris.feature_names)
print(feature_importance)
import matplotlib.pyplot as plt
import seaborn as sns
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 可视化特征重要性
sns.barplot(x=feature_importance, y=feature_importance.index)
plt.xlabel("重要性")
plt.ylabel("名称")
plt.title("特征重要性可视化")
plt.show()
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True, cmap="Blues")
plt.xlabel("预测值")
plt.ylabel("真实值")
plt.title("混淆矩阵")
plt.show()
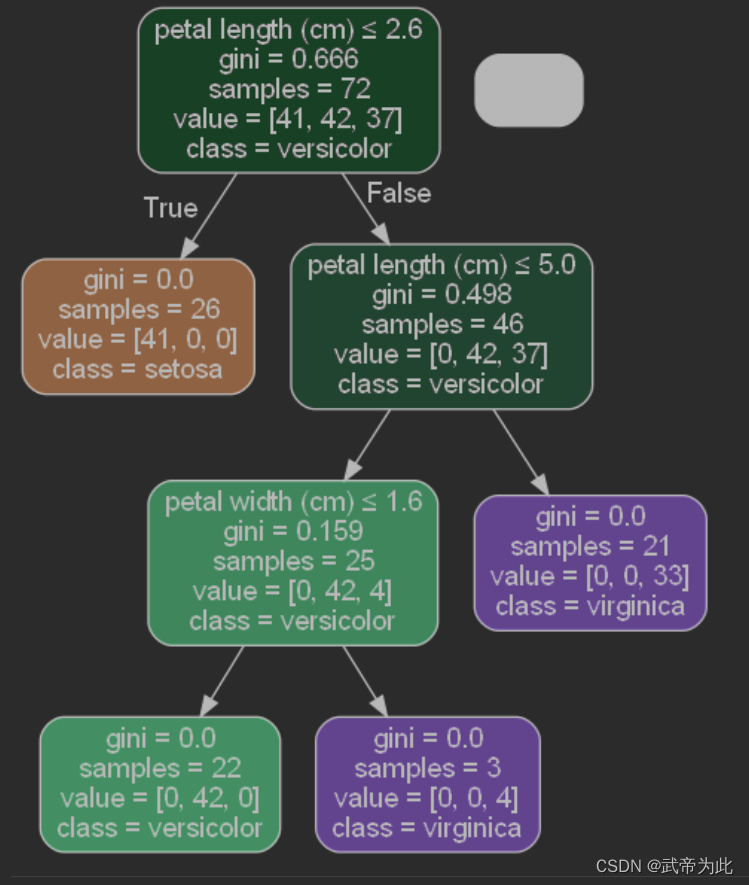
from sklearn.tree import plot_tree
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 可视化决策树
plt.figure(figsize=(20, 20))
plot_tree(grid_search.best_estimator_[0], feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()



5. 总结
随机森林是一种强大的集成学习算法,具有高度鲁棒性、可解释性和特征重要性评估等优势。