一. 背景
1.1 什么是微服务应用
微服务应用由一组具有自治性的服务所组成,每一个服务只提供一类服务,这些服务一起协作以提供复杂的业务功能。相比于传统的单体应用,微服务应用是高度分布式的。如下图所示,即为一个典型的微服务应用:
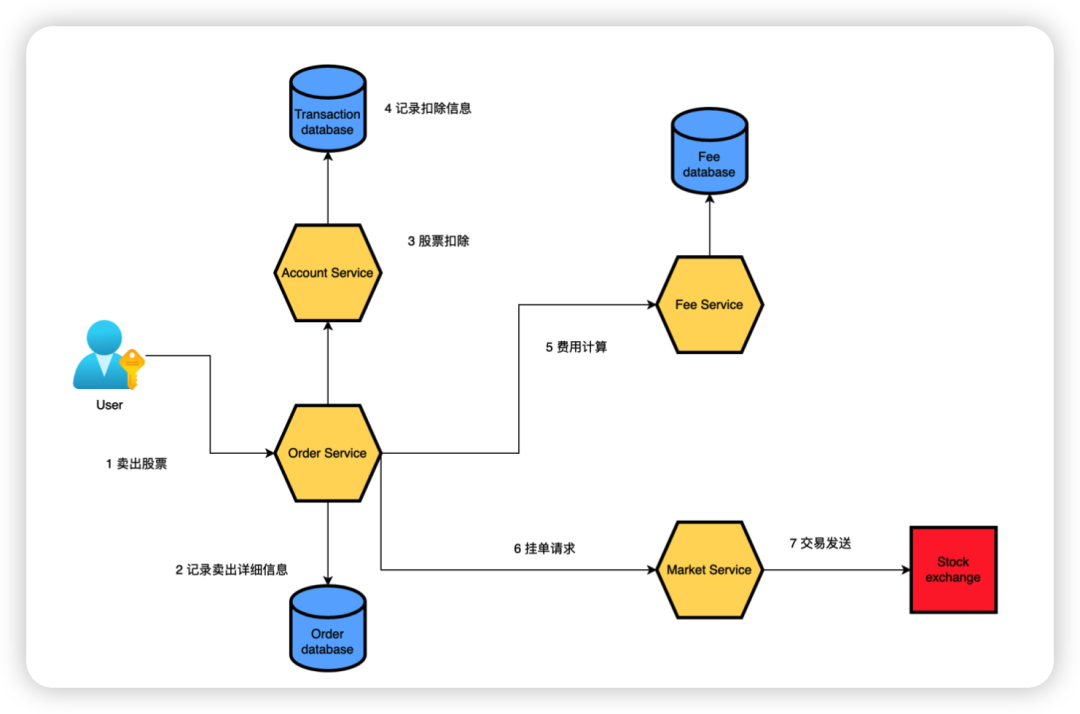
如上图所示,微服务一般具有以下几个大的特征:
自治性(Autonomy)
健壮性 (Resilience)
透明性 (Transparency)
自动化 (Automation)
一致性 (Alignment)
本篇文章我们重点聊一下透明性特征。在微服务应用中,当错误发生的时候,工程师需要及时地被告知。在微服务应用中,一个请求会跨越多个微服务,而这些微服务可能由不同的团队来开发。
这就需要每一个微服务具有透明性和可观测性,来保证工程人员在运营过程中,能够观测和诊断问题。在实际的系统开发和运营过程中,一般需要收集大量的数据来确保微服务的健康度,这些数据一般会涉及:
(1)业务、运营和基础设施的指标
(2)应用日志
(3)请求追踪
1.2 可观测性 (Observability)
可观测性平台的四大支柱包含:指标、追踪、日志和可视化。
1.2.1 指标类数据
指标类数据一般指的是定期收集的一类数据,数据类型为数字,通常我们会关注最小值、最大值、平均值和百分位值。指标类数据通常能够反应系统和应用的效能,比如某个微服务资源利用超过阈值的时候,可以触发告警,以帮助DevOps人员诊断问题和采取进一步地行动。
1.2.2 追踪
追踪(Tracing)是相关的分布式事件组成的序列。一般我们在网关层产生一个唯一的请求ID,这个请求ID会跨越所有的请求参与者,所以追踪其实就是一组带有请求ID的日志的组合。每一个记录带有追踪和调试的信息,比如入口时间、延迟信息等。
1.2.3 日志
日志指的是带有时间戳的事件,它可以包含各种信息,比如请求的确认信息、请求失败产生的错误信息等。
1.2.4 可视化
可视化能够帮助你更好的理解所收集的数据,能够最大地提高你洞察系统的能力。在工程团队中,除了自动化以提高运营效率外,很多问题的发现需要人工干预,从而相关的仪表板实时展示数据是非常有用的功能。
总的来说,在微服务应用下,搭建可观测性平台是一项挑战性的任务。我们需要知道全局信息。我们需要从独立的信息中组装全局的视图,以帮助运维人员掌握全局。本文借助于国产大数据分析平台鸿鹄来一步一步展示如何搭建可观测性平台。
二. 鸿鹄介绍
鸿鹄提供了从数据的导入、解析、存储、分析计算到数据可视化的一系列开箱即用的服务。每个数据处理阶段的能力都较为完善和强大。
数据采集和导入部分,可以轻松对接Vector/Kafka等数据源,也可接收标准REST API, HTTP等各类API的数据推送。
数据分析部分,采用标准的SQL查询语言,对于大部分技术人员来说,容易上手且技能通用,平台内置了100多种标量函数和表函数、视图、查找表等;并支持跨库和异构数据关联,可以满足各类业务分析需求。
可视化部分,提供大量开箱即用的图表类型,丰富的输入选择和钻取功能,多样化的图表协作编辑体验。
值得一提的是,鸿鹄的自主研发的读时建模引擎,可以快速导入和存储异构数据,支持动态调整数据模型和分析参数,无需固化模型和分析流程。当业务分析场景有变化时,只需调整SQL分析语句,快速响应。
经过初步的调研了解,鸿鹄基本符合我们搭建可观测性场景的需求。
三. 解决方案
3.1 系统架构
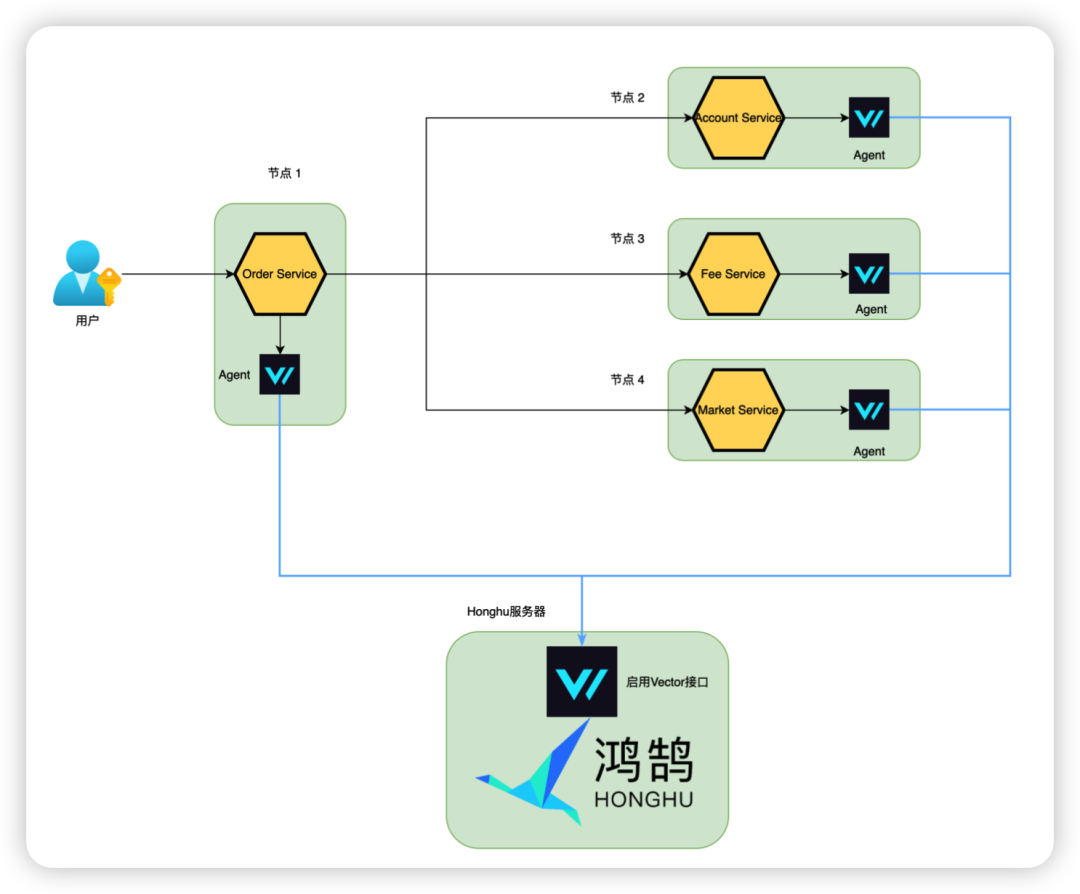
基于鸿鹄简单易用的数据采集功能,可以非常容易地搭建如上的日志采集系统,方案说明如下:
每一个微服务会动态地部署到Kubernetes的节点上,每个微服务的输出会以kubernetes_logs格式存放在运行的节点上。
Vector Agent以DaemonSet的形式部署在每个节点上
鸿鹄内置了Vector接口,配置打开即可
Vector Agent对日志进行解析、丰富和转换后,最终会持续地拉日志到鸿鹄
3.2 数据接入
鸿鹄具备多种数据接入功能,内置的Vector和Kafka数据接入功能,大大方便了企业收集数据,导入鸿鹄分析平台进一步挖掘数据价值的便利性。基于以上的采集系统,具体操作步骤如下:
3.2.1 启用鸿鹄数据收集接口
3.2.1.1 进入:鸿鹄 -> 数据导入 -> 从外部数据源导入
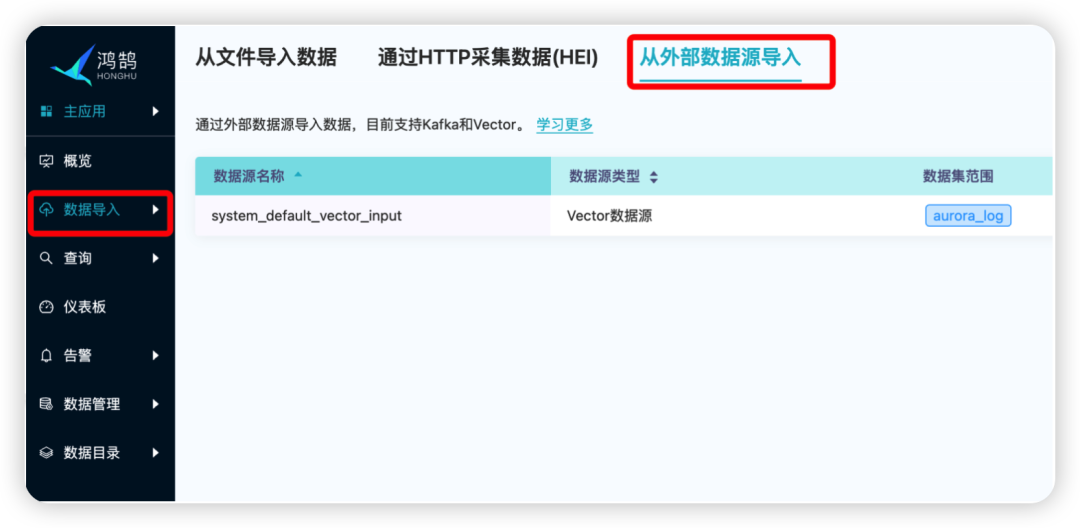
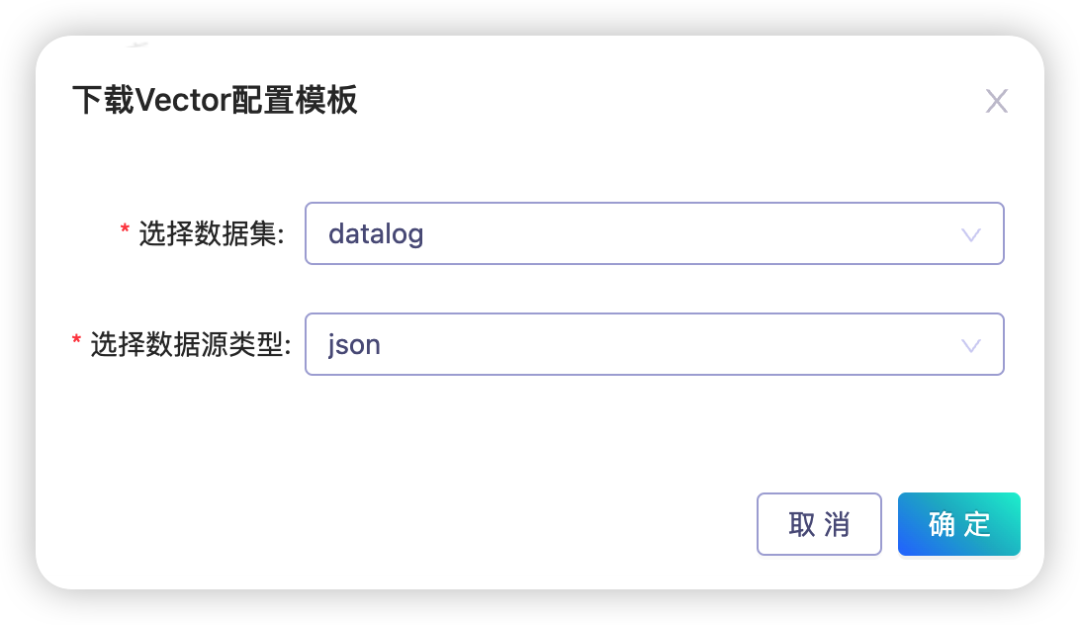
3.2.1.2 配置Vector接口,选择数据集范围(本文会创建datalog数据集)
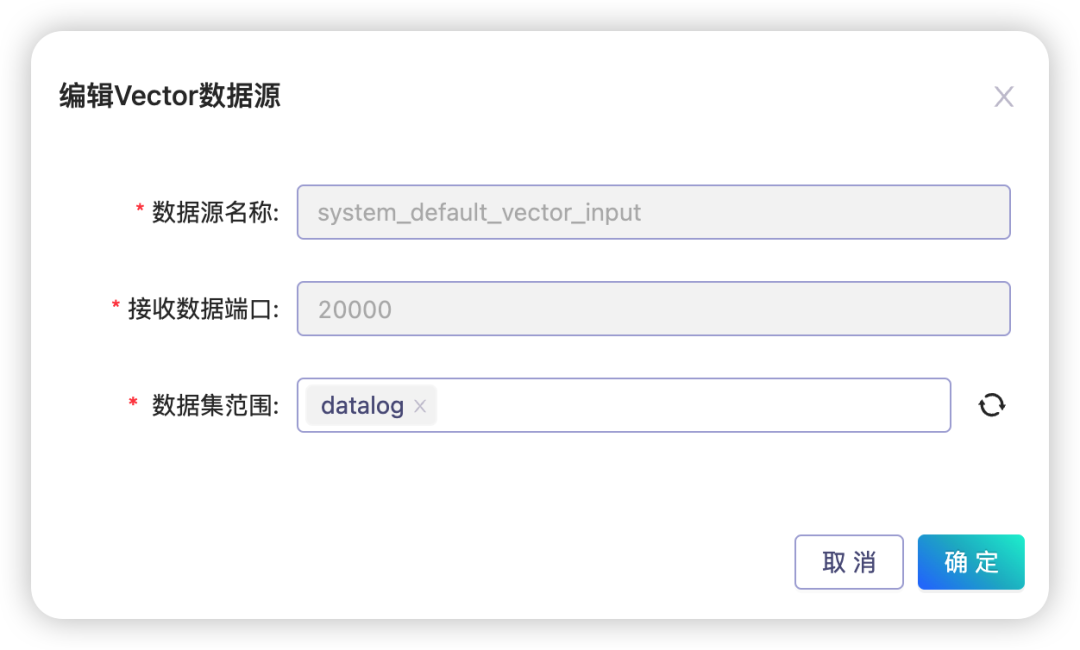
3.2.1.3 选择数据集和数据源类型,生成和下载Vector配置模版,以备后续配置Vector使用
3.2.2 配置及安装Vector
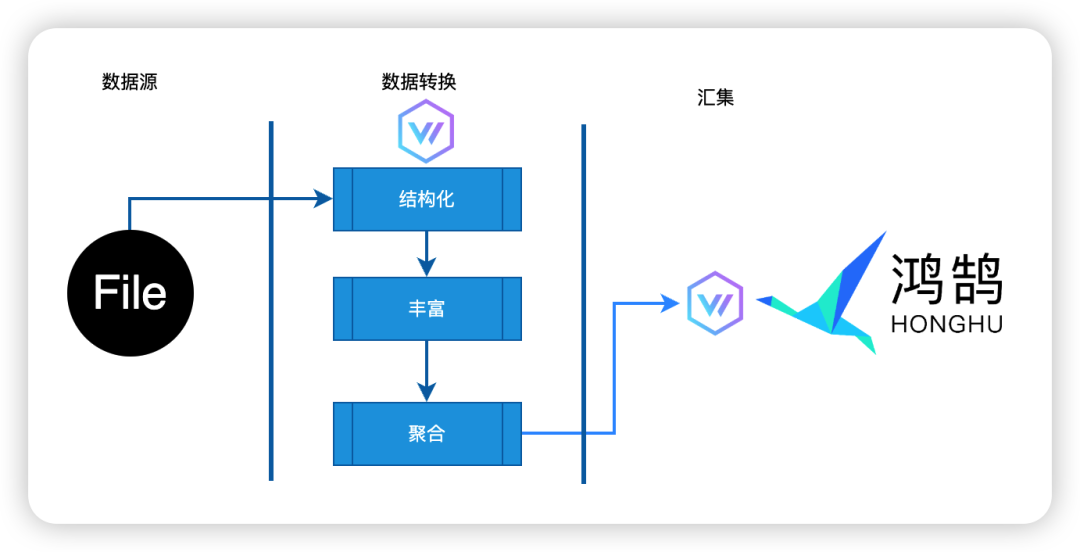
按照Vector的设计(如上图),Data Pipeline分为三个阶段:确定数据源、对数据做转换和数据汇集。以下是实际运行的配置文件(考虑到信息安全性,对部分做了脱敏处理)。这个配置主要包含了确定采集的数据源、数据如何被加工转换(多行处理、如何进一步解析和抽取数据、丰富数据以满足鸿鹄的需求)和数据最终汇集到鸿鹄,相信大家不难理解。

有了Vector的配置文件,就可以安装Vector了。本文的方案需要采集运行在Kubernetes上的微服务的日志,Vector将会用Helm命令来安装,具体命令如下:

如果需要详细了解Vector Helm chart,可参考 Vector Helm Chart(https://github.com/vectordotdev/helm-charts/tree/develop/charts/vector)
3.2.3 验证数据
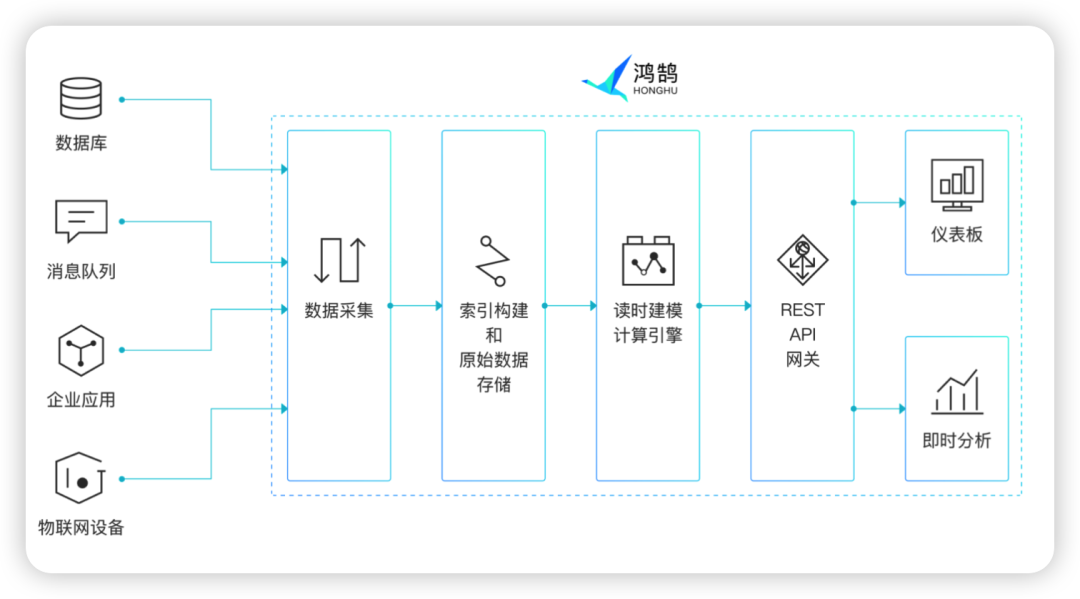
数据进入到鸿鹄之后,如下图所示,系统会对数据进行索引构建和原始数据存储,之后用户即可制作仪表板和即时分析。
当我们的数据,进入鸿鹄后,可以打开鸿鹄做查询确认。
打开鸿鹄-》查询-》高级查询,执行简单的SQL,即可看到即时的数据:


3.3 应用场景
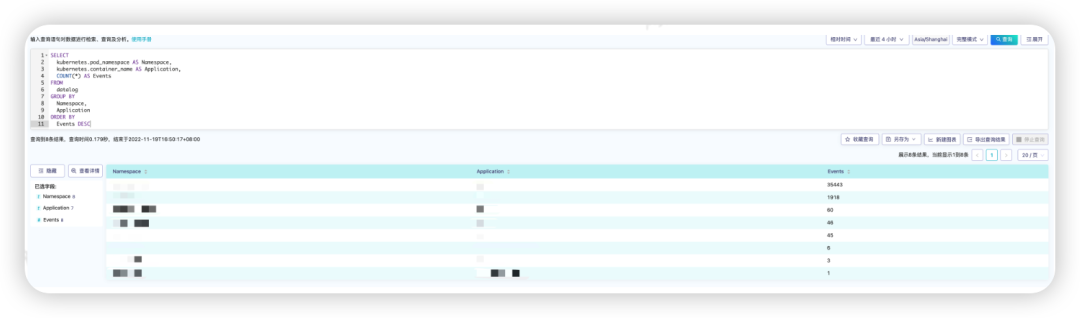
3.3.1 统计各个服务发生的所有事件
3.3.2 统计外部请求
在统计一些指标时,经常需要用时间段来分类统计。鸿鹄在这个的处理逻辑非常得方便,只要对时间进行一定的转换,然后基于转换后的时间,直接聚类分析即可。
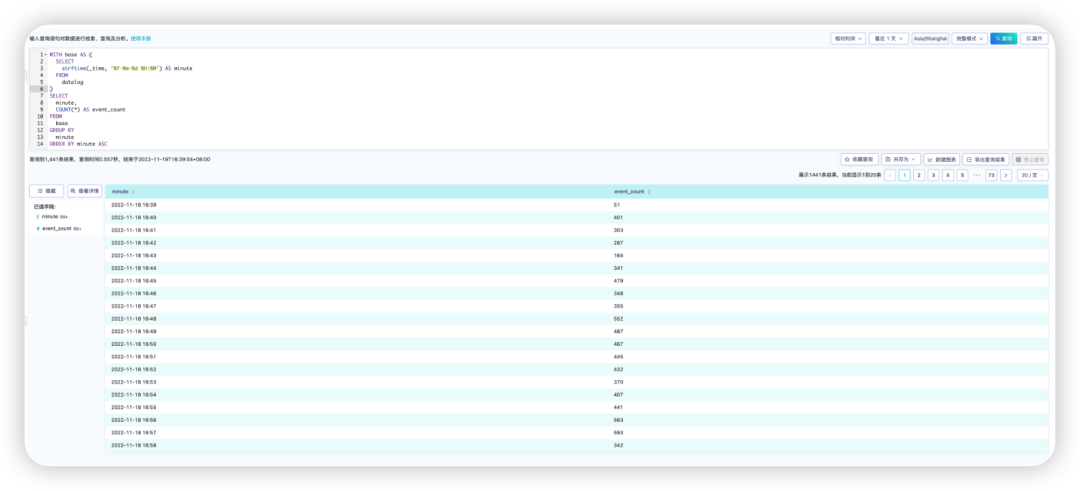
3.3.3 统计请求的处理时间
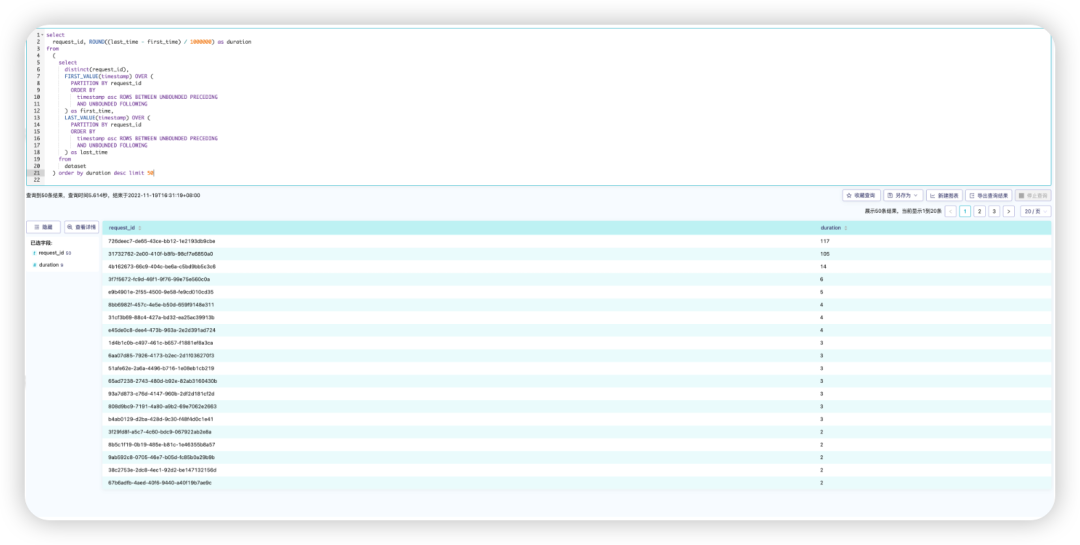
基于微服务应用,每个请求会跨越一个或者多个容器,计算请求的处理时间,需要叠加一个或者多个容器的处理时间。我们的应用在一开始就考虑了这一点,请求在进入应用网关的时候,就会被分配一个request_id, 随后request_id会记录在各种应用的日志中。基于这个实现,利用鸿鹄提供的窗口函数,基于request_id聚类事件后,大致可以计算出每个request的处理时间。
3.3.4 API网关日志的输出
微服务系统中,网关至关重要。目前主流的网关都是基于Nginx和Envoy的各种实现。我们在业务部署中,这两种类型的网关都会涉及。本文只涉及如何监控Nginx网关,以后有机会可以谈谈如何用鸿鹄来监控基于Envoy的网关。对于Nginx,鸿鹄已经有现成的案例,制作仪表板只要导入仪表盘的Nginx配置文件即可。
进入 鸿鹄 --> 仪表板 --> 新建仪表板 --> 导入配置文件即可
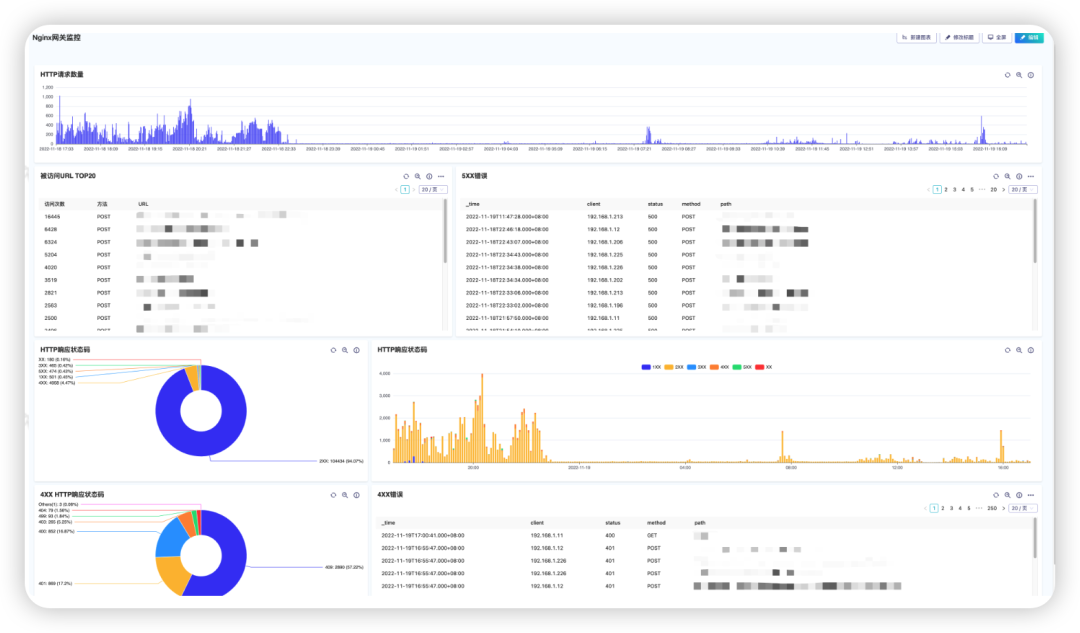
3.3.5 最终效果图
3.3.5.1 Nginx网关监控
3.3.5.2 应用监控
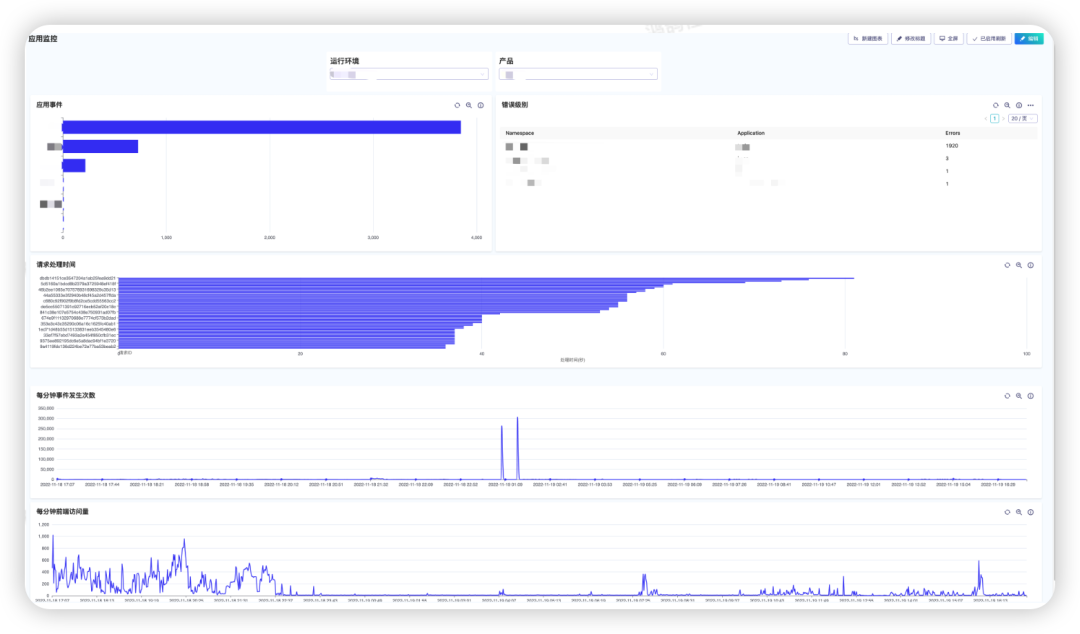
四. 使用感受
经历了安装、数据导入、数据分析和数据可视化的整个过程中,鸿鹄系统在国产化大数据产品中,给人耳目一新的感觉。相比其它同类产品,鸿鹄优势体现在:
产品的KISS原则:鸿鹄大数据系统设计简单,用户上手方便。从数据导入、分析和可视化来看,系统内聚性好,大部分情况下,用户无需查看文档,即可开始分析数据。
强大的分析功能:鸿鹄采用扩展的SQL语句来处理结构化、半结构化和非结构化的数据,能够利用标量函数和表函数对原始数据进行丰富和转换,帮助用户深度挖掘数据的价值。
适应数据分析业务的需要:鸿鹄系统提供了读时建模功能,从业务角度来说满足了一份原始数据,可以满足不同业务部门的分析需求。
鸿鹄大数据分析平台,随着社区版的发布、用户和生态的不断扩大,产品功能必然会越来越丰富 -- 不忘初心,以成鸿鹄之志。
![[学习笔记]全面掌握Django ORM](https://img-blog.csdnimg.cn/4f98ea8bb9ac4ffb8e20480c9d042b3e.png)