参考资料:全面掌握Django ORM
1.1 课程内容与导学
学习目标:独立使用django完成orm的开发
学习内容:Django ORM所有知识点
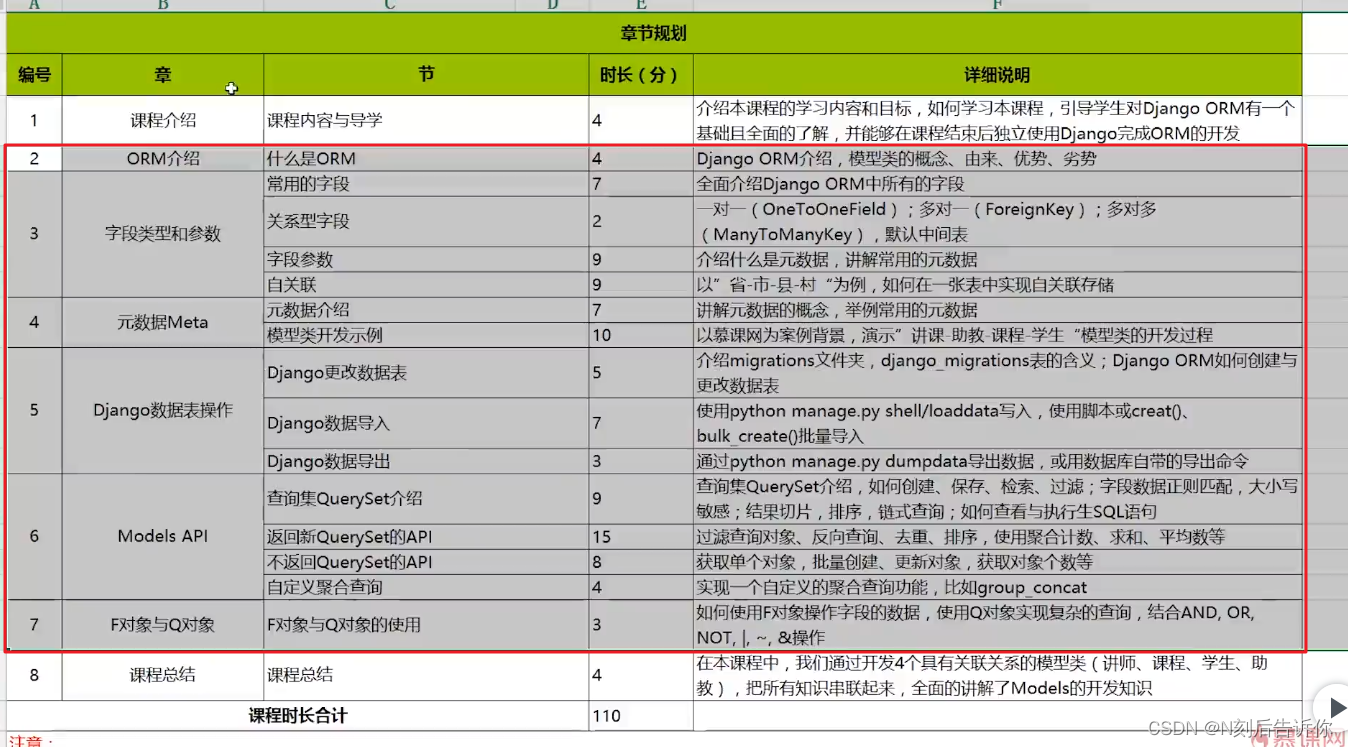
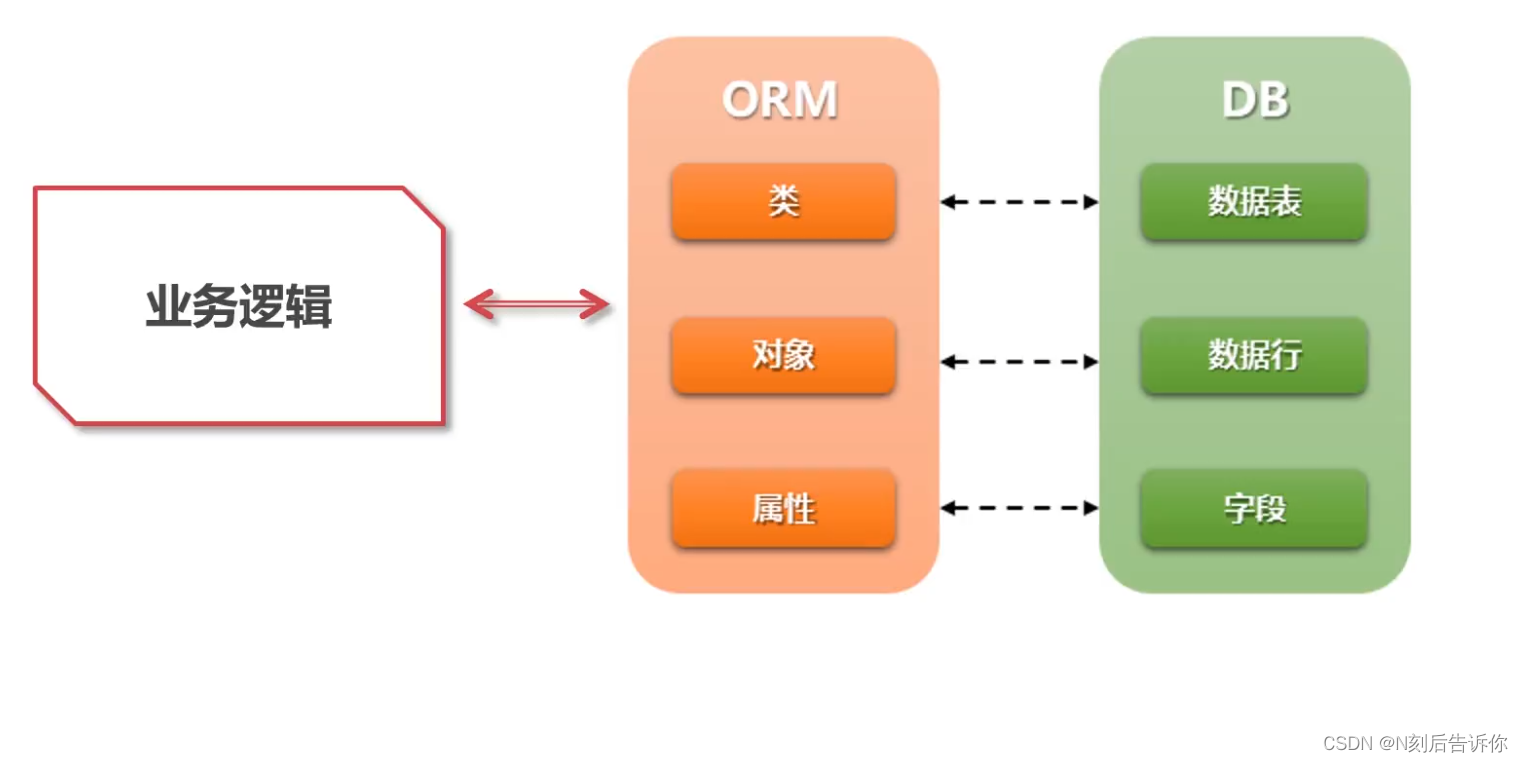
2.1 ORM介绍
ORM:Object-Relational Mapping
Django的ORM详解
在django中,应用的文件夹下面会自动建一个models.py文件。
- 模型类的优势与劣势
优势:让开发人员专注于业务逻辑处理,提高开发效率。不需要在业务逻辑代码中编写原生sql语句了。用操作对象方式来操作数据库。
缺点:一定程度上牺牲程序执行效率。orm写久了可能会忘记怎么写sql。
3.1 常见的字段类型
- 在项目的settings.py中设置数据库连接信息
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": "imooc",
"USER": 'root',
'PASSWORD': 'xxx',
'HOST': '127.0.0.1'
}
}
- models.py文件中
from django.db import models
# Create your models here.
class Test(models.Model):
'''测试学习用'''
Auto = models.AutoField() # 自增长字段
BigAuto = models.BigAutoField() # 允许的记录更大
# 二进制数据
Binary = models.BinaryField() # 存入二进制数据
# 布尔型
Boolean = models.BooleanField() # 允许为空的布尔型
NullBoolean = models.NullBooleanField() # 不允许为空的布尔型
# 整型
PositiveSmallInteger = models.PositiveSmallIntegerField() # 正整数,允许5个字节
SmallInteger = models.SmallIntegerField() # 6个字节大小的整数
PositiveInteger = models.PositiveIntegerField() # 10个字节大小正整数
Integer = models.IntegerField() # 11个字节大小
BigInteger = models.BigIntegerField() # 20个字节大小的整型
# 字符串类型
Char = models.CharField() # 对应varchar, 通常指定max_length
Text = models.TextField() # longtext, 不需要指定长度
# 时间日期类型
Date = models.DateField() # 年月日
DateTime = models.DateTimeField() # 年月日时分秒
Duration = models.DurationField() # int,底层通过python的timedelta实现
# 浮点型
Float = models.FloatField()
Decimal = models.DecimalField() # 需要指定整数有多少位,小数有多少位
# 其他字段
Email = models.EmailField() # 邮箱
Image = models.ImageField() # 图片
File = models.FileField() # 文件
FilePath = models.FilePathField() # 文件路径
URL = models.URLField() # 地址
UUID = models.UUIDField() # 通用唯一识别码
GenericIPAddress = models.GenericIPAddressField() # IP地址
3.2 关系型字段
- 一对一(OneToOnefield)
- 多对一(ForeignKey)
- 多对多(ManyToManyField),默认或自定义中间表
class A(models.Model):
onetoone = models.OneToOneField(Test)
class B(models.Model):
foreign = models.ForeignKey(A)
class C(models.Model):
manytomany = models.ManyToManyField(B)
3.3字段参数
-
- 所有字段都具有的参数
db_column = "age" # 修改在数据库表中的字段的默认名
primary_key = True # 设置主键,默认是False
verbose_name = "11个字节大小" # 设置别名/备注
unique = True # 设置字段的唯一键属性,这个数据在表中必须唯一
null = True # 数据库层面,数据库中的数据是否可以为空
blank = True # 前端表单提交的时候,数据是否可以为空
db_index = True # 表示给字段建立索引
help_text = "xxx" # 在表单中显示的说明
editable = False # 不允许用户进行编辑
-
- 个别字段才有的参数
max_length = 100 # CharFiled通常一定要指定长度
unique_for_date = True # 时间日期类型才有的字段参数,表示这个字段的日期必须唯一
unique_for_month = True # 时间日期类型才有的字段参数,表示这个字段的月份必须唯一
auto_now = True # 更新当前记录的时间,更新记录时更新的时间
auto_now_add = True # 增加记录时的当前时间,新插入一条数据,插入的时间
max_digits = 4 # 表示总共有多少位数
decimal_places = 2 # 表示小数点有多少位
-
- 关系型字段的参数(最重要也是最常见的两个)
class A(models.Model):
'''
用于外键关联中的反向查询,可以通过父表查询到子表的信息
子表是A,父表是Test
如果需要通过Test查询到模型类A中的数据,可以使用related_name
'''
onetoone = models.OneToOneField(Test, related_name="one")
class B(models.Model):
'''
on_delete
外键所管理的对象被删除时,进行什么操作
1.models.CASCADE:模拟SQL语言中的ON DELETE CASCADE约束,将定义有外键的模型对象同时删除!(该操作为当前Django版本的默认操作)
2.models.PROTECT:阻止上面的删除操作,但是弹出ProtectedError异常
3.models.SET_NULL:将外键字段设为null,只有当字段设置了null=True时,方可使用该值
4.models.SET_DEFAULT: 将外键字段设置为默认值,只有当字段设置了default参数时,方可使用
5.models.DO_NOTHING: 什么也不做
6:SET(): 设置位一个传递给SET()的值或者一个回调函数的返回值。注意大小写。
'''
foreign = models.ForeignKey(A, on_delete=models.CASCADE)
foreign = models.ForeignKey(A, on_delete=models.PROTECT())
foreign = models.ForeignKey(A, on_delete=models.SET_NULL, null=True, blank=True)
foreign = models.ForeignKey(A, on_delete=models.SET_DEFAULT, default=0)
foreign = models.ForeignKey(A, on_delete=models.DO_NOTHING)
foreign = models.ForeignKey(A, on_delete=models.SET)
3.4 自关联
一个模型类的记录关联到他自己的另一条记录。
例如省市区的实现
- 创建自关联的模型类
models.py文件中
class AddressInfo(models.Model):
'''
自关联的模型类有两种写法:
1. “self”
2. 自己模型类的名字
'''
address = models.CharField(max_length=200, null=True, blank=True, verbose_name="地址")
pid = models.ForeignKey('self', null=True, blank=True, verbose_name="自关联", on_delete=models.CASCADE)
# pid = models.ForeignKey("AddressInfo", null=True, blank=True, verbose_name="自关联")
def __str__(self):
'''
给不同的模型对象返回可读的字符串
:return:
'''
return self.address
- 开发视图函数
views.py文件中
from django.shortcuts import render
from django.views.generic import View
from django.http import JsonResponse
from .models import AddressInfo
# Create your views here.
class IndexView(View):
'''主页'''
def get(self, request):
return render(request, "address.html")
class AddressAPI(View):
def get(self, request, address_id): # 接受
if int(address_id) == 0:
address_data = AddressInfo.objects.filter(pid__isnull=True).values('id', 'address')
else:
address_data = AddressInfo.objects.filter(pid__id=int(address_id)).values('id', 'address')
area_list = []
for a in address_data:
area_list.append({'id': a['id'], 'address': a['address']})
return JsonResponse(area_list, content_type='application/json', safe=False)
- 配置url路由
urls.py文件中
from django.contrib import admin
from django.urls import path, re_path
from course.views import IndexView, AddressAPI
urlpatterns = [
re_path("^admin/", admin.site.urls),
re_path(r'^$', IndexView.as_view(), name='index'),
re_path(r'^address/(\d+)$', AddressAPI.as_view(), name='address'),
]
- 写好前端代码
在templates文件夹下面创建address.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>地址信息</title>
</head>
<body>
<select name="" id="pro">
<option value="">请选择省</option>
</select>
<select name="" id="city">
<option value="">请选择市</option>
</select>
<select name="" id="dis">
<option value="">请选择县</option>
</select>
<script src="/static/jquery-3.7.0.min.js"></script>
<script>
address = function (a,b){
$.get('/address/' + a, function (dic){
$.each(dic, function(index, item){
b.append('<option value="' + item.id + '">' + item.address + '</option>')
})
})
};
$(function (){
pro = $('#pro'); // 省
city = $('#city'); // 市
dis = $('#dis'); //县
// 查询省信息
address(0, pro);
// 根据省的改变查询市的信息
pro.change(function(){
city.empty().append('<option value="">请选择市</option>');
dis.empty().append('<option value="">请选择市</option>');
address(this.value, city)
})
// 根据市的改变查询县的信息
city.change(function(){
dis.empty().append('<option value="">请选择县</option>');
address(this.value, dis)
})
})
</script>
</body>
</html>
- 在admin.py中注册数据类模型
from django.contrib import admin
from course.models import AddressInfo
# Register your models here.
admin.site.register(AddressInfo)
- 通过manage.py创建用户
createsuperuser
4.1 元数据介绍
Django Meta元数据类属性解析
每个模型类下面都有一个子类:Meta
这个类就是定义元数据的地方
用于定义数据库或者数据表相关的信息
如设置表明,设置排序,设置唯一键等
from django.db import models
class AddressInfo(models.Model):
'''
自关联的模型类有两种写法:
1. “self”
2. 自己模型类的名字
'''
address = models.CharField(max_length=200, null=True, blank=True, verbose_name="地址")
pid = models.ForeignKey('self', null=True, blank=True, verbose_name="自关联", on_delete=models.CASCADE)
# pid = models.ForeignKey("AddressInfo", null=True, blank=True, verbose_name="自关联")
note = models.CharField(max_length=200, null=True, blank=True, verbose_name='说明')
def __str__(self):
'''
给不同的模型对象返回可读的字符串
:return:
'''
return self.address
class Meta:
# 定义元数据
db_table = 'address'
# ordering = ('pid',) # 指定按照什么字段排序
verbose_name = '省市县地址信息' # 模型类的复数名
verbose_name_plural = verbose_name
# abstract = True # 定义当前模型是否是抽象类,是否用于继承
# permissions = (('定义好的权限','权限说明'),) # 二元元组,如((have_read_permission', '有读的权限'))
# managed = False # 默认为True,是否按照Django既定的规则管理模型类
unique_together = ('address', 'note') # 一元元组或二元元组((), ()),联合唯一键
# app_label = "" # 模型类在哪个应用
# db_tablespace # 定义数据库表空间的名字
后面会有模型类开发示例
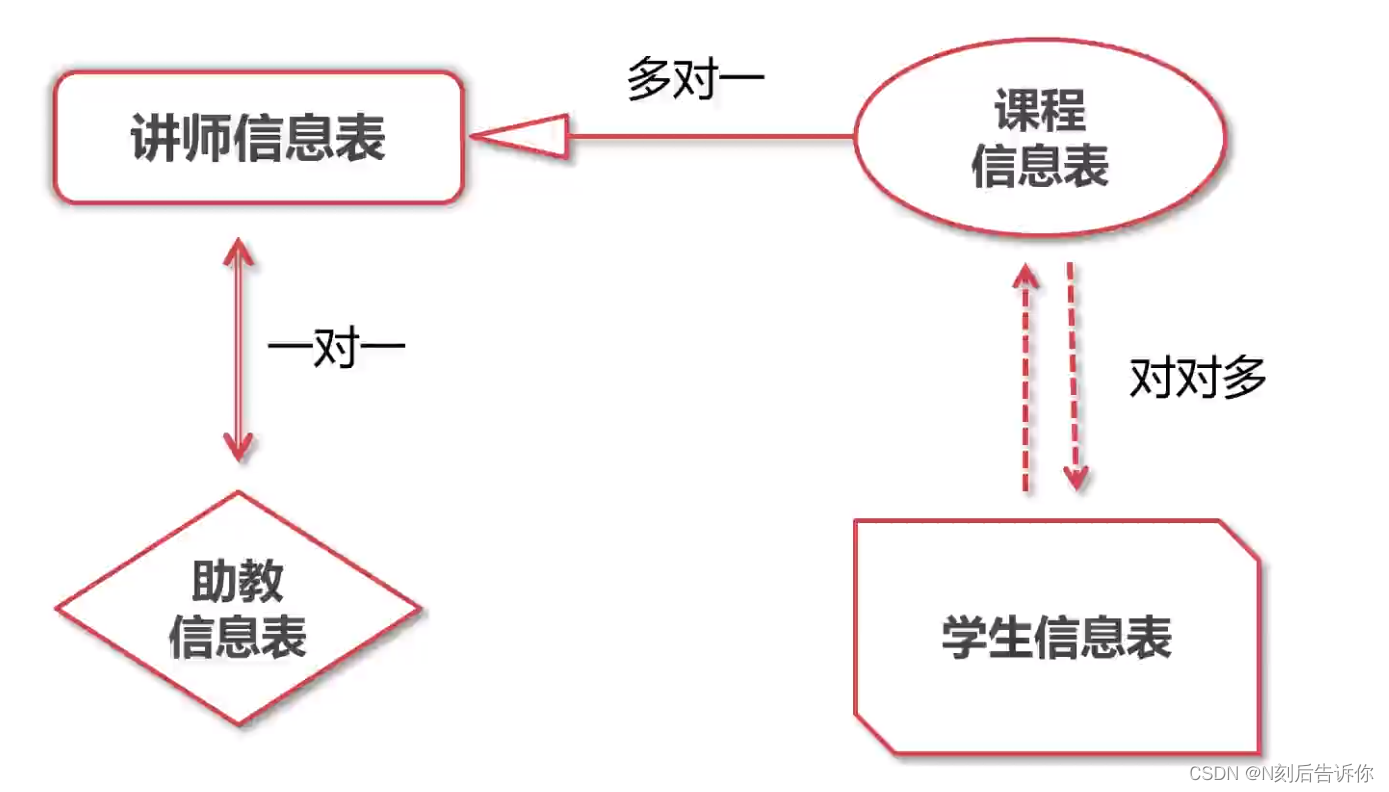
4.2 模型类开发示例
- 讲师信息表
- 课程信息表
- 学生信息表
- 助教信息表
讲师信息表和课程信息表是多对一关系:一个讲师可能发布多个课程。
课程与学生是多对多关系:一个课程可以多个学生学习,一个学生可以学习多个课程
助教和讲师是一对一关系
对课程而言,讲师是父表
对学生而言,课程是父表
对助教而言,讲师是父表
外键字段是写在子表中的
多对多关系会生成中间表
from django.db import models
# Create your models here.
class Teacher(models.Model):
'''讲师信息表'''
nickname = models.CharField(max_length=30, primary_key=True, db_index=True, verbose_name='昵称')
introduction = models.TextField(default="这位同学很懒,木有签名的说", verbose_name="简介")
fans = models.PositiveIntegerField(default='0', verbose_name="粉丝数")
create_at = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
updated_at = models.DateTimeField(auto_now=True, verbose_name="更新时间")
class Meta:
verbose_name = "讲师信息表"
verbose_name_plural = verbose_name
def __str__(self):
return self.nickname
class Course(models.Model):
'''课程信息表'''
title = models.CharField(max_length=100, primary_key=True, db_index=True, verbose_name='课程名')
teacher = models.ForeignKey(to=Teacher, null=True, blank=True, on_delete=models.CASCADE, verbose_name='课程讲师')
type = models.CharField(choices=((1, "实战课"), (2, "免费课"), (0, "其他")), max_length=1, default=0,
verbose_name="课程类型")
price = models.PositiveSmallIntegerField(verbose_name="价格")
volume = models.BigIntegerField(verbose_name='销量')
online = models.DateField(verbose_name="上线时间")
created_at = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
updated_at = models.DateTimeField(auto_now=True, verbose_name='更新时间')
class Meta:
verbose_name = "课程信息表"
verbose_name_plural = verbose_name
def __str__(self):
return f"{self.get_type_display()} - {self.title}" # get_type_display是django-orm中自带的函数,用于获取枚举属性的字符串
class Student(models.Model):
'''学生信息表'''
nickname = models.CharField(max_length=30, primary_key=True, db_index=True, verbose_name='昵称')
course = models.ManyToManyField(to=Course, verbose_name='课程')
age = models.PositiveSmallIntegerField(verbose_name='年龄')
gender = models.CharField(choices=((1, '男'), (2, "女"), (0, "保留")), max_length=1, default=0, verbose_name='性别')
study_time = models.PositiveIntegerField(default='0', verbose_name='学习时长(h)')
created_at = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
updated_at = models.DateTimeField(auto_now=True, verbose_name='更新时间')
class Meta:
verbose_name = '学生信息表'
verbose_name_plural = verbose_name
def __str__(self):
return self.nickname
class TeacherAssistant(models.Model):
'''助教信息表'''
nickname = models.CharField(max_length=30, primary_key=True, db_index=True, verbose_name='昵称')
teacher = models.OneToOneField(Teacher, null=True, blank=True, on_delete=models.SET_NULL, verbose_name='讲师')
hobby = models.CharField(max_length=100, null=True, blank=True, verbose_name='爱好')
created_at = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
updated_at = models.DateTimeField(auto_now=True, verbose_name='更新时间')
class Meta:
verbose_name = "助教信息表"
db_table = "courses_assistant"
verbose_name_plural = verbose_name
def __str__(self):
return self.nickname
5.1 Django更改数据表
makemigrations是生成数据库要生成的内容,可以在项目的migrations文件夹下面找到对应的py文件。
而migrate是执行我们刚刚生成的文件,并将执行的过程存放到数据库的django_migrations表中。
所以如果要删除模型类,需要
- 删除模型类代码。
- 删除migrations文件夹下对应的py文件。
- 删除django_migrations对应的记录。
- 删除数据表
5.2 Django数据导入
4种导入方式:
- 利用manage.py shell
manage.py shell
# 假设需要在讲师信息表种插入一条数据
from course.models import Teacher # 导入模型类
t = Teacher(nickname = "Jack") # 创建一个Teacher对象
t.save() # 保存
不符合实践,只能一条条导入
- 脚本实现批量导入
orm_data.py脚本
import os
import sys
import random
import django
from datetime import date
# 在imooc项目中运行脚本
project_path = os.path.dirname(
os.path.dirname(os.path.abspath(__file__))) # 'D:\计算机学习\Python\Python小项目\gx\djangoProject\djangoProject'
sys.path.append(project_path) # 将项目路径添加到系统搜寻路径当中
os.environ['DJANGO_SETTINGS_MODULE'] = 'imooc.settings' # 设置项目的配置文件
django.setup() # 初始化一个django环境,便于orm操作
from course.models import Teacher, Course, Student, TeacherAssistant
def import_data():
"""使用Django ORM导入数据"""
# 讲师数据 create()
Teacher.objects.create(nickname='Jack', introduction='Python工程师', fans=666)
Teacher.objects.create(nickname='Allen', introduction='Java工程师', fans=123)
Teacher.objects.create(nickname='Henry', introduction='Golang工程师', fans=818)
# 课程数据 bulk_create()
Course.objects.bulk_create([Course(title=f'Python系列教程{i}', teacher=Teacher.objects.get(nickname="Jack"),
type=random.choice((0, 1, 2)),
price=random.randint(200, 300), volume=random.randint(100, 10000),
online=date(2018, 10, 1))
for i in range(1, 5)])
Course.objects.bulk_create([Course(title=f'Java系列教程{i}', teacher=Teacher.objects.get(nickname="Allen"),
type=random.choice((0, 1, 2)),
price=random.randint(200, 300), volume=random.randint(100, 10000),
online=date(2018, 6, 4))
for i in range(1, 4)])
Course.objects.bulk_create([Course(title=f'Golang系列教程{i}', teacher=Teacher.objects.get(nickname="Henry"),
type=random.choice((0, 1, 2)),
price=random.randint(200, 300), volume=random.randint(100, 10000),
online=date(2018, 1, 1))
for i in range(1, 3)])
# 学生数据 update_or_create()
# 先通过nickname去查数据
# 存在的话就更新defaults指明的数据字典,不存在就创建新的
Student.objects.update_or_create(nickname="A同学", defaults={"age": random.randint(18, 58),
"gender": random.choice((0, 1, 2)),
"study_time": random.randint(9, 999)})
Student.objects.update_or_create(nickname="B同学", defaults={"age": random.randint(18, 58),
"gender": random.choice((0, 1, 2)),
"study_time": random.randint(9, 999)})
Student.objects.update_or_create(nickname="C同学", defaults={"age": random.randint(18, 58),
"gender": random.choice((0, 1, 2)),
"study_time": random.randint(9, 999)})
Student.objects.update_or_create(nickname="D同学", defaults={"age": random.randint(18, 58),
"gender": random.choice((0, 1, 2)),
"study_time": random.randint(9, 999)})
# 正向添加
# 销量大于等于1000的课程
Student.objects.get(nickname="A同学").course.add(*Course.objects.filter(volume__gte=1000))
# 销量大于5000的课程
Student.objects.get(nickname="B同学").course.add(*Course.objects.filter(volume__gt=5000))
# 反向添加
# 学习时间大于等于500小时的同学
Course.objects.get(title='Python系列教程1').student_set.add(*Student.objects.filter(study_time__gte=500))
# 学习时间小于等于500小时的同学
Course.objects.get(title='Python系列教程1').student_set.add(*Student.objects.filter(study_time__lte=500))
# 助教数据 get_or_create()
# 存在就get查询,不存在就create创建
TeacherAssistant.objects.get_or_create(nickname="助教1", defaults={"hobby": "慕课网学习",
"teacher": Teacher.objects.get(nickname="Jack")})
TeacherAssistant.objects.get_or_create(nickname="助教2", defaults={"hobby": "追慕女神",
"teacher": Teacher.objects.get(
nickname="Allen")})
TeacherAssistant.objects.get_or_create(nickname="助教3", defaults={"hobby": "减肥减肥",
"teacher": Teacher.objects.get(
nickname="Henry")})
return True
if __name__ == '__main__':
if import_data():
print("数据导入成功!")
- fixtures 提供能够被Django的serialization识别的序列化文件 -> model,然后被存进数据库
- 通过dumpdata命令导出所有数据
# 通过dumpdata命令导出数据
python manage.py dumpdata > imooc.json
这个命令必须在命令行敲,不能通过工作进入manage.py再敲
- 删除助教信息表数据
- 通过fixtures导入数据
# 通过loaddata命令导入数据
python manage.py loaddata imooc.json
在加载数据的过程中,最有可能的报错是提示导出的数据文件data.json中编码不是utf-8,需要把data.json文件转为utf-8格式,然后在加载数据到mysql中。
修改文件编码的方式可以通过notepad–。
- 数据库层面导入数据
5.3 Django导出数据
- 通过dumpdata命令导出数据
- 在pycharm链接的数据库种导出
- 通过navicat等数据库管理软件导出
6.1 查询集介绍
objects是模型类的对象管理器
.all是取出所有结果
class IndexView(View):
'''主页'''
def get(self, request):
# 1.查询、检索、过滤
teachers = Teacher.objects.all()
print(teachers) # <QuerySet [<Teacher: Allen>, <Teacher: Henry>, <Teacher: Jack>]>
teacher2 = Teacher.objects.get(nickname='Jack') # get()只能返回一条结果,多条会报错,所以传递的通常是主键或者唯一键
print(teacher2, type(teacher2)) # Jack <class 'course.models.Teacher'>
teacher3 = Teacher.objects.filter(fans__gte=500) # 返回QuerySet,可以是多条结果
for t in teacher3:
print(f"讲师姓名{t.nickname}--粉丝数{t.fans}")
'''
讲师姓名Henry--粉丝数818
讲师姓名Jack--粉丝数666
'''
# 2.字段数据匹配,大小写敏感
teacher4 = Teacher.objects.filter(fans__in=[666, 1231])
print(teacher4) # <QuerySet [<Teacher: Jack>]>
teacher5 = Teacher.objects.filter(nickname__icontains='A') # 前面含i表示大小写不敏感
print(teacher5) # <QuerySet [<Teacher: Allen>, <Teacher: Jack>]>
# 3.结果切片、排序、链式查询
print(Teacher.objects.all()[:1]) # <QuerySet [<Teacher: Allen>]>
teacher6 = Teacher.objects.all().order_by('-fans') # 默认升序,前面带-表示降序
print(teacher6) # <QuerySet [<Teacher: Henry>, <Teacher: Jack>, <Teacher: Allen>]>
print(Teacher.objects.filter(fans__gte=500).order_by('nickname')) # 链式反应表示我们可以对返回的查询集继续使用API
# 4.看执行的原生SQL
print(str(Teacher.objects.filter(fans__gte=500).order_by('nickname').query)) # 直接打印查询集.query即可
"""select * from (SELECT `course_teacher`.`nickname`, `course_teacher`.`introduction`, `course_teacher`.`fans`,
`course_teacher`.`create_at`, `course_teacher`.`updated_at` FROM `course_teacher`
WHERE `course_teacher`.`fans` >= 500 ORDER BY `course_teacher`.`nickname` ASC) ct
"""
return render(request, "address.html")
6.2 返回新QuerySet的API
两大类API。
6.2.1 all(), filter(), order_by(), exclude(), reverse(), distinct(): 去重
s1 = Student.objects.all().exclude(nickname='A同学') # 排除A同学的类对象
for s in s1:
print(s.nickname, s.age)
s2 = Student.objects.all().exclude(nickname='A同学').reverse() # 反向排序,必须先在模型类的Meta子类中设置ordering
for s in s2:
print(s.nickname, s.age)
更改模型类的元数据不需要重新生成数据表
6.2.2 extra(): 实现字段别名, defer(): 排除一些字段, only(): 选择一些字段
s3 = Student.objects.all().extra(select={'name': "nickname"}) # 将nickname字段名改成name
for s in s3:
print(s.name)
6.2.3. values(), values_list() 获取字典或元组形式的QuerySet
print(TeacherAssistant.objects.values('nickname', 'hobby'))
# <QuerySet [{'nickname': '助教1', 'hobby': '慕课网学习'}, {'nickname': '助教2', 'hobby': '追慕女神'}, ...]>
print(TeacherAssistant.objects.values_list('nickname', 'hobby'))
# <QuerySet [('助教1', '慕课网学习'), ('助教2', '追慕女神'), ('助教3', '减肥减肥')]>
print(TeacherAssistant.objects.values_list('nickname', flat=True)) # 只取一个字段时,可以使用flat=True
# <QuerySet ['助教2', '助教3', '助教1']>
6.2.4. dates(), datetimes() 根据时间日期获取查询集
print(Course.objects.dates('created_at', 'month', order='DESC'))
# <QuerySet [datetime.date(2023, 11, 1), datetime.date(2023, 9, 1), datetime.date(2023, 7, 1)]>
print(Course.objects.datetimes('created_at', 'month', order='DESC')) # 可筛选的范围更多,年月日时分秒都可以
6.2.5. union(): 并集, intersection(): 交集, difference(): 补集
p_240 = Course.objects.filter(price__gte=240)
p_260 = Course.objects.filter(price__lte=260)
print(p_240.union(p_260))
print(p_240.intersection(p_260))
print(p_240.difference(p_260))
6.2.6. select_related(): 一对一、多对一查询优化
Django基础(29): select_related和prefetch_related的用法与区别
courses = Course.objects.all()
for c in courses:
print(f"{c.title}--{c.teacher.nickname}--{c.teacher.fans}")
配置项目的settings,配置日志,让它可以在终端输出所有debug信息
先在settings.py文件中导入logging模块
再在最下面配置好所有的日志管理器
# settings.py中
LOGGING = {
'version': 1, # 日志级别
# 日志处理器
'handers': {
'console': {
'class': 'logging.StreamHandler',
},
},
# 日志管理器
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'level': 'DEBUG' if DEBUG else 'INFO',
},
}
}
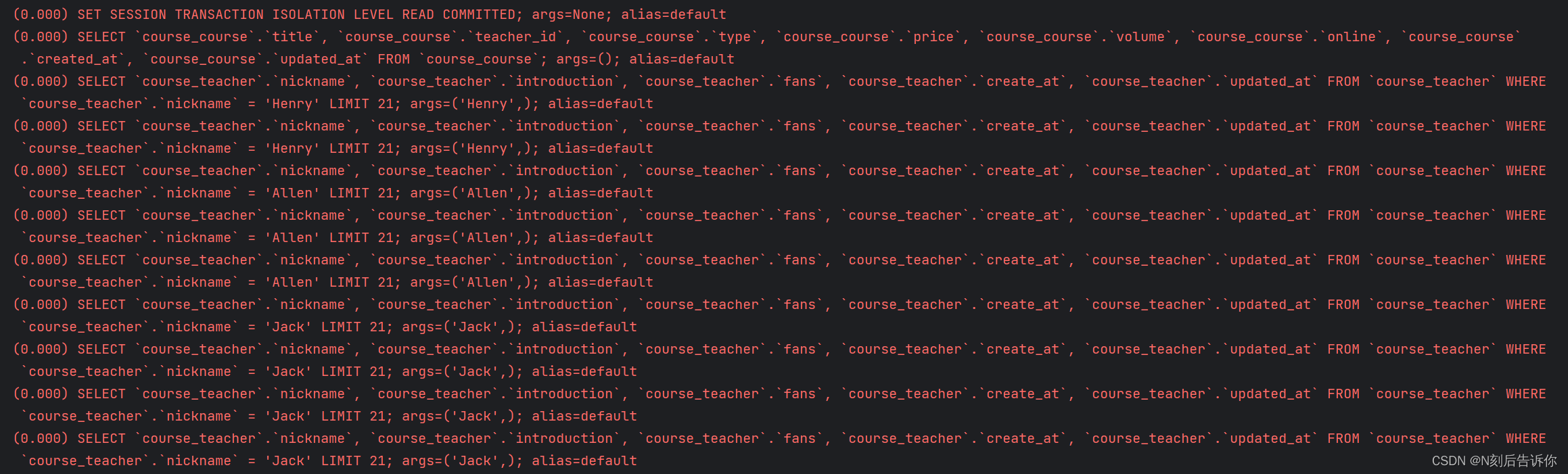
可以看到,先查了course表,然后再根据外键查了9次Teacher表
能不能在查询子表的时候将父表的数据一次性查询出来呢?减少查询次数?
通过select_related,并传入参数teacher

这里面的差异主要是使用 select_related 把原本两条 SQL 命令合并到一条中 SQL 命令中因此只执行了一次数据库查询。如果您查看此时原始的 SQL 命令,会看到 Django 利用了左连接(LEFT JOIN)相关知识 。
6.2.7 prefetch_realated():多对多查询优化
students = Student.objects.filter(age__lt=40)
for s in students:
print(s.course.all())

prefetch_related()可以优化多对多查询
students = Student.objects.filter(age__lt=30).prefetch_related('course')
for s in students:
print(s.course.all())
return render(request, 'address.html')

6.2.8 反向查询:通过父表查询子表信息
print(Teacher.objects.get(nickname='Jack').course_set.all())

可以通过给子表设置related_name,方便反向查询
class Course(models.Model):
'''课程信息表'''
title = models.CharField(max_length=100, primary_key=True, db_index=True, verbose_name='课程名')
teacher = models.ForeignKey(to=Teacher, null=True, blank=True, on_delete=models.CASCADE, related_name='teac' verbose_name='课程讲师')
print(Teacher.objects.get(nickname='Jack').teac.all())
子表名_set和通过related_name实现的效果是一样的
6.2.9 annotate(): 使用聚合计数、求和、平均数
from django.db.models import Count, Avg, Max, Min, Sum
# 按teacher分组,组内按volume求和
print(Course.objects.values('teacher').annotate(vol=Sum('volume')))
6.2.10 raw:执行原生的SQL
6.3 不返回QuerySet的API
大致分为5种类型:
6.3.1 获取对象get(),get_or_create(),first(),last(),latest(),earliest(),in_bulck()
使用latest和earliest时,必须在模型类的元数据中设置get_latest_by字段作为判断最近和最早的依据,如
class Course(models.Model):
'''课程信息表'''
title = models.CharField(max_length=100, primary_key=True, db_index=True, verbose_name='课程名')
teacher = models.ForeignKey(to=Teacher, null=True, blank=True, on_delete=models.CASCADE, related_name='teac', verbose_name='课程讲师')
type = models.CharField(choices=((1, "实战课"), (2, "免费课"), (0, "其他")), max_length=1, default=0,
verbose_name="课程类型")
price = models.PositiveSmallIntegerField(verbose_name="价格")
volume = models.BigIntegerField(verbose_name='销量')
online = models.DateField(null=True, blank=True, verbose_name="上线时间")
created_at = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
updated_at = models.DateTimeField(auto_now=True, verbose_name='更新时间')
class Meta:
verbose_name = "课程信息表"
get_latest_by = 'created_at'
verbose_name_plural = verbose_name
in_bulck()批量返回对象,需要根据主键来返回列表
print(Course.objects.in_bulk(['Python系列教程4', 'Golang系列教程1']))
# {'Golang系列教程1': <Course: 1 - Golang系列教程1>, 'Python系列教程4': <Course: 2 - Python系列教程4>}
6.3.2 创建对象 create():创建; bulk_create():批量创建;update_or_create():创建或更新
6.3.3 更新对象 update():更新;update_or_create(): 更新或创建
Course.objects.filter(title='Java系列教程2').update(price=300)
6.3.4 删除对象 delete() 使用filter过滤
Course.objects.filter(title='test').delete()
6.3.5 其他操作 exists(), count(), aggregate() 判断是否存在,统计个数,聚合
print(Course.objects.filter(title='test').exists())
print(Course.objects.filter(title='Java系列教程2').exists())
print(Course.objects.count())
print(Course.objects.count())
print(Course.objects.aggregate(Max('price'), Min('price'), Avg('price')))
annotate一般是对分组后的结果进行统计,而aggregate是对整个数据表数据进行统计
6.4 自定义聚合查询
使用默认API并不能实现所有查询功能,比如分组查询功能中的字符串拼接。
如何自定义聚合查询:实现group_concat
重写已有的聚合函数类aggregate,重载父类的构造方法来实现
class GroupConcat(models.Aggregate):
"""自定义实现聚合功能,实现GRUOP_CONCAT功能"""
function = 'GROUP_CONCAT'
template = '%(function)s(%(distinct)s%(expressions)s%(ordering)s%(separator)s)'
def __init__(self, expression, distinct=False, ordering=None, separator=',', **extra):
super(GroupConcat, self).__init__(expression,
distinct='DISTINCT ' if distinct else '',
ordering=' ORDER BY %s' % ordering if ordering is not None else '',
separator=' SEPARATOR "%s"' % separator,
output_field=models.CharField(), **extra)
courses = Course.objects.values('teacher').annotate(t=GroupConcat('title', distinct=False,
ordering='title ASC',
separator='-'))
# GROUP_CONCAT ( title ORDER BY title ASC SEPARATOR '-')
“”“
{'teacher': 'Allen', 't': 'Java系列教程1-Java系列教程2-Java系列教程3'}
{'teacher': 'Henry', 't': 'Golang系列教程1-Golang系列教程2'}
{'teacher': 'Jack', 't': 'Python系列教程1-Python系列教程2-Python系列教程3-Python系列教程4'}
”“”
7.1 F对象与Q对象的使用
7.1.1 F对象的使用:操作字段的数据
- 假设要实现对课程表的所有课程的价格-11
Course.objects.update(price=F('price') - 11)
- 假设要获取课程销量小于价格二十倍的对象
print(Course.objects.filter(volume__lte=F('price') * 20))
# <QuerySet [<Course: 1 - Golang系列教程2>, <Course: 2 - Java系列教程1>, <Course: 2 - Java系列教程3>, <Course: 2 - Python系列教程4>]>
必须是相同类型的字段
7.1.2 Q对象的使用:结合AND,OR, NOT,|,~,&实现复杂的查询
-
假设要查询所有销量大于5000的java课程
-
假设要查询所有go语言或者销量小于1000
print(Course.objects.filter(Q(title__icontains="java") & Q(volume__gte=5000)))
print(Course.objects.filter(Q(title__icontains="golang") | Q(volume__lte=1000)))