"And if forever lasts till now Alright"
为什么要有git?
想象一下,现如今你的老师同时叫你和张三,各自写一份下半年的学习计划交给他。

可是你的老师是一个极其"较真"的人,发现你俩写的学习计划太"水"了,根本没上心,因此将你俩的计划又打发回去给你们了,叫你们再重写一份。 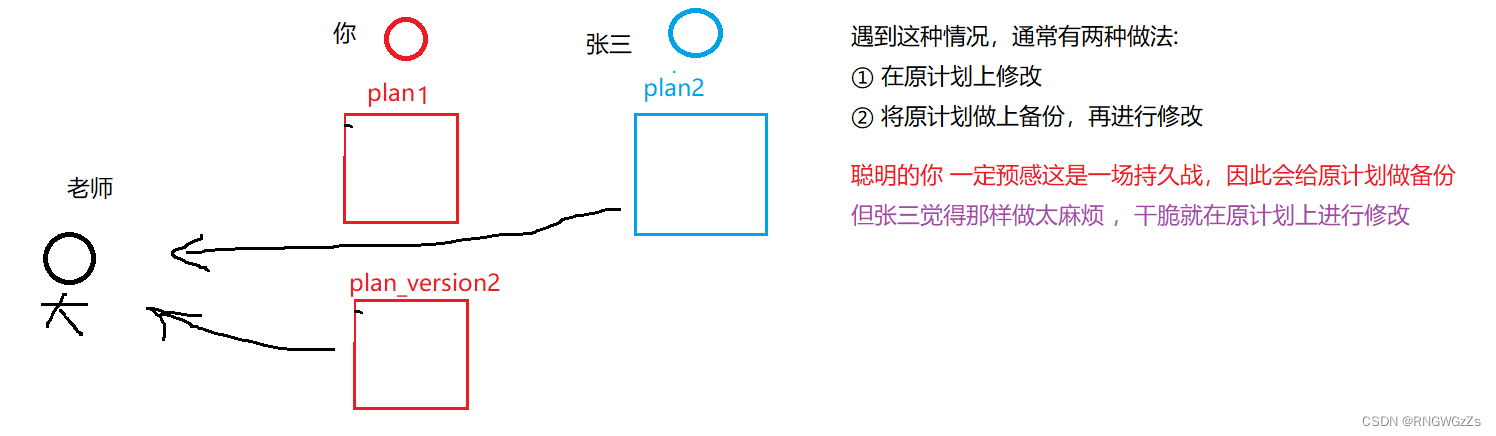
老师一看,你这俩人,第二次写的比第一次还烂!赶快拿回去重写。于是乎,你俩的计划又被打了回去。 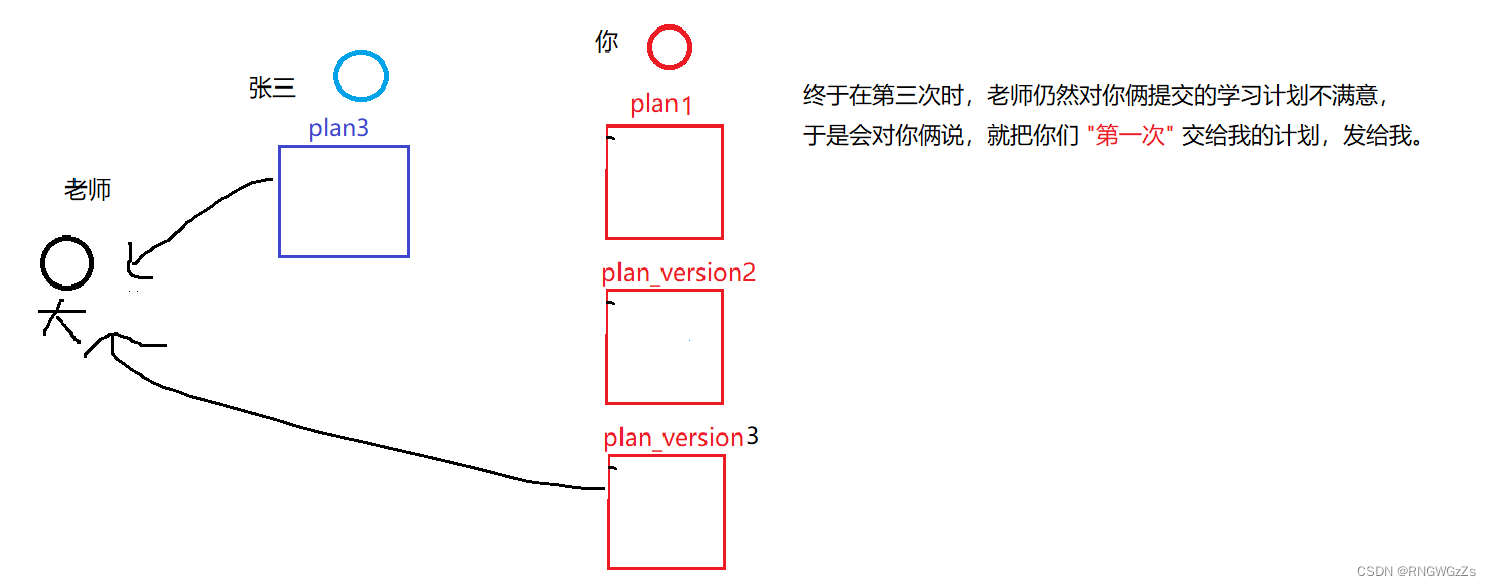
此时,你暗自窃喜,因为你做了第一次更改的备份,那么直接把plan1发给老师,任务即可完成了。可是到了张三这里,就让他叫苦连连,经过多次在原计划上的修改,早就忘了第一次的计划是什么版本了。
所以,上述的"你",其实就在做版本管理。为了方便”版本回溯",我们只得不停地在做复制拷贝,产出的⽂件就越来越多,可是⽂件多不是问题,问题是: “随着版本数量的不断增多,你还记得这些版本各⾃都是修改了什么吗?”
因此,为了能够更⽅便我们管理这些不同版本的⽂件,便有了 "版本控制器"。所谓的版本控制器,就是能让你了解到⼀个⽂件的历史,以及它的发展过程的系统。
⽬前最主流的版本控制器就是Git。Git可以控制电脑上所有格式的⽂件,例如doc、excel、dwg、dgn、rvt等等。对于我们开发⼈员来说,Git最重要的就是可以帮助我们管理软件开发项⽬中的源代码⽂件!
——前言
一、Git安装
(1) Windows
我们可以打开: git官网。
点击Downloads,选择自己机器适配的环境。

下载完成后,根据默认指示安装即可。

(2) Centos 7.x环境下

# 安装git
sudo yum install -y git git下载完成之后,通过: git --version查看。 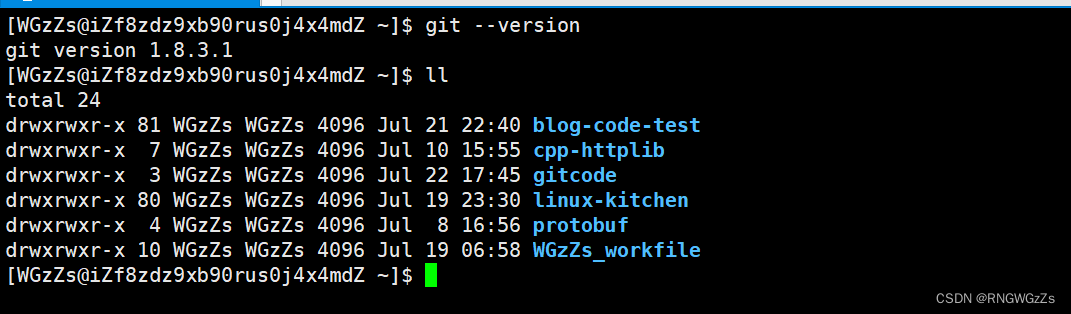
二、git的基本操作
(1) 初始化仓库
创建本地仓库:
# 创建一个目录
mkdir gitcode
# 创建仓库
git init
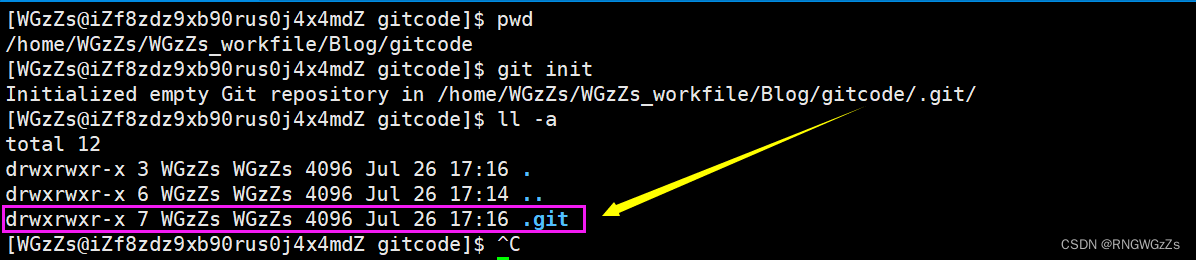
此时,我们就会发现在该路径下多了一个隐藏文件".git",".git"目录是Git用来跟踪管理仓库的,因此万不可手动修改里面的内容,导致Git仓库无法管理。当然".git"文件里都有些什么呢?在之后会细讲。
配置Git身份:
当安装Git后⾸先要做的事情是设置你的⽤⼾名称和e-mail地址,这是⾮常重要的。
配指命令:
# [--global]:意为全局配置
git config [--global] user.name "Your Name"
git config [--global] user.email "email@example.com"
# 把 Your Name 改成你的昵称
# 把 email@example.com 改成邮箱的格式,只要格式正确即可 因为在一台机器上,也许存在多个Git本地仓库,其中 --global 是⼀个可选项,如果使⽤了该选项,表⽰这台机器上所有的Git仓库都会使⽤这个配置。如果你希望在不同仓库中使⽤不同的 name 或 e-mail ,可以不要 --global 选项,但要注意的是,执⾏命令时必须要在仓库⾥。
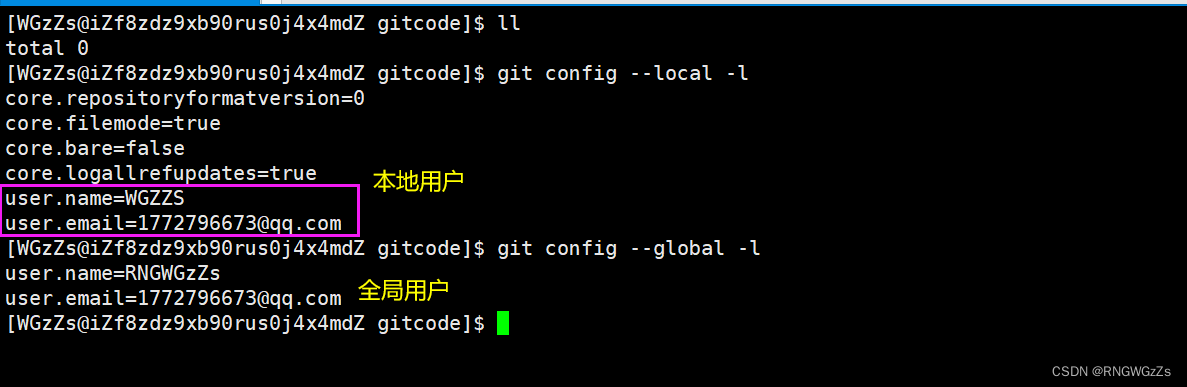
查看配置信息:
上述演示的是配置到本地仓库中的例子。我们可以通过以下命令查看当前Git配置的用户信息。
| 命令 | 作用 |
| git config --system --list | 查看系统config |
| git config --global--list | 当前全局config |
| git confit --local --list | 当前仓库config |
删除用户:
# 删除[全局]本地用户配置
git config [--global] --unset user.name
git config [--global] --unset user.email
global配置:
我们全局配置的信息,会存放在/home/xxx/.gitconfig里

(2) 认识⼯作区、暂存区、版本库
当我们在使用 " git init" 后,我们会发现当前的目录会新增一个隐藏文件".git",这个隐藏文件是什么呢?
● 工作区: 是在电脑上你要写代码或⽂件的⽬录。
● 暂存区(叫stage、index)。⼀般存放在 .git ⽬录下的index⽂件(.git/index)中,我们把暂存区有时也叫作索引(index)。
● 版本库⼜名仓库(repository) 。⼯作区有⼀个隐藏⽬录 .git ,它不算⼯作区,⽽是Git的版本库。这个版本库⾥⾯的所有⽂件都可以被Git管理起来,每个⽂件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
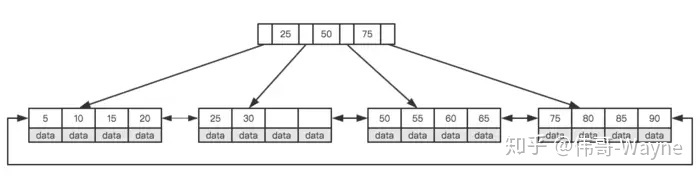
下面一个图展示了这三个区域的关系: 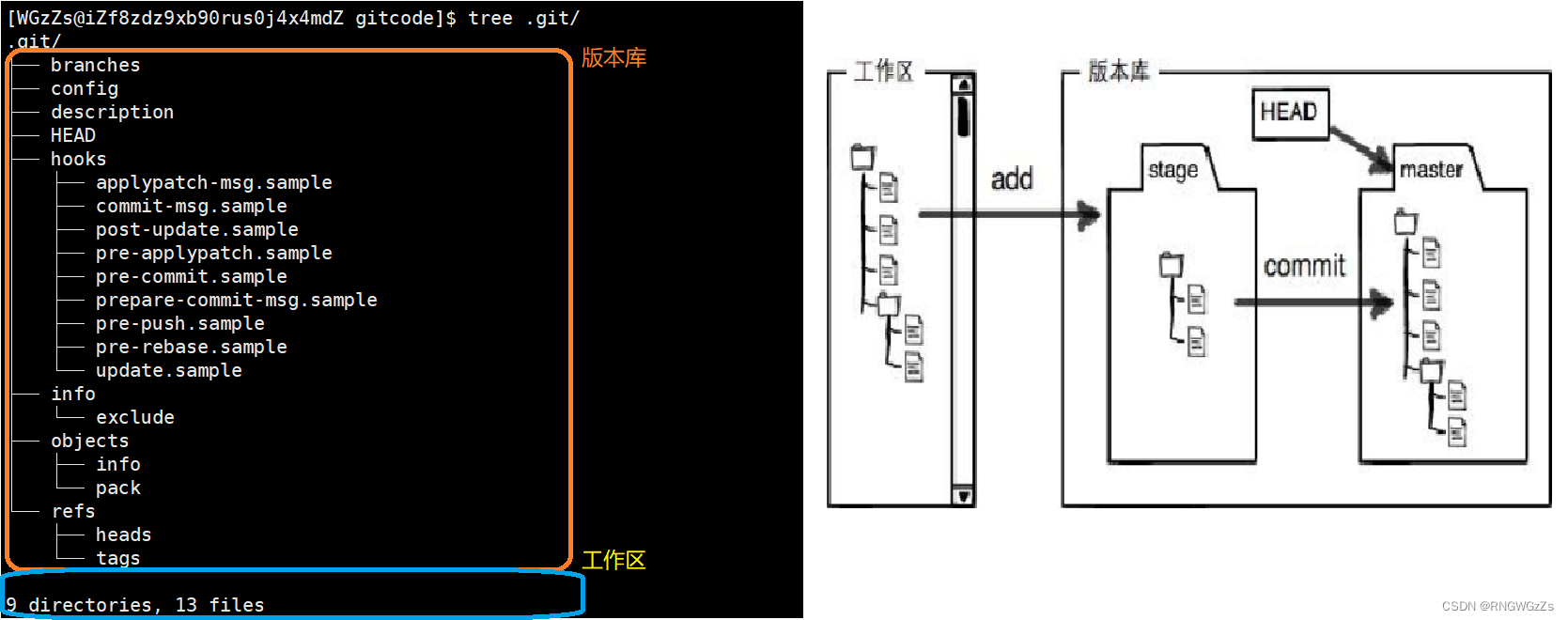
• 图中左侧为⼯作区,也就是当前目录。右侧为版本库,在".git"文件下。Git的版本库⾥存了很多东西,其中最重要的就是暂存区(因为这是一个新的Git仓库,没有任何历史信息,所以不存在暂存区)。
如何理解三个区的关系(为什么需要git三板斧)?
在创建Git仓库时,Git会为我们默认创建一个唯一的master分支,以及指向master的一个指针HEAD。(关于什么是分支,之后会细讲)。
当对工作区修改的文件(增删文件,修改文件内容……),执行 “git add”命令时,暂存区的目录的文件索引会被更新。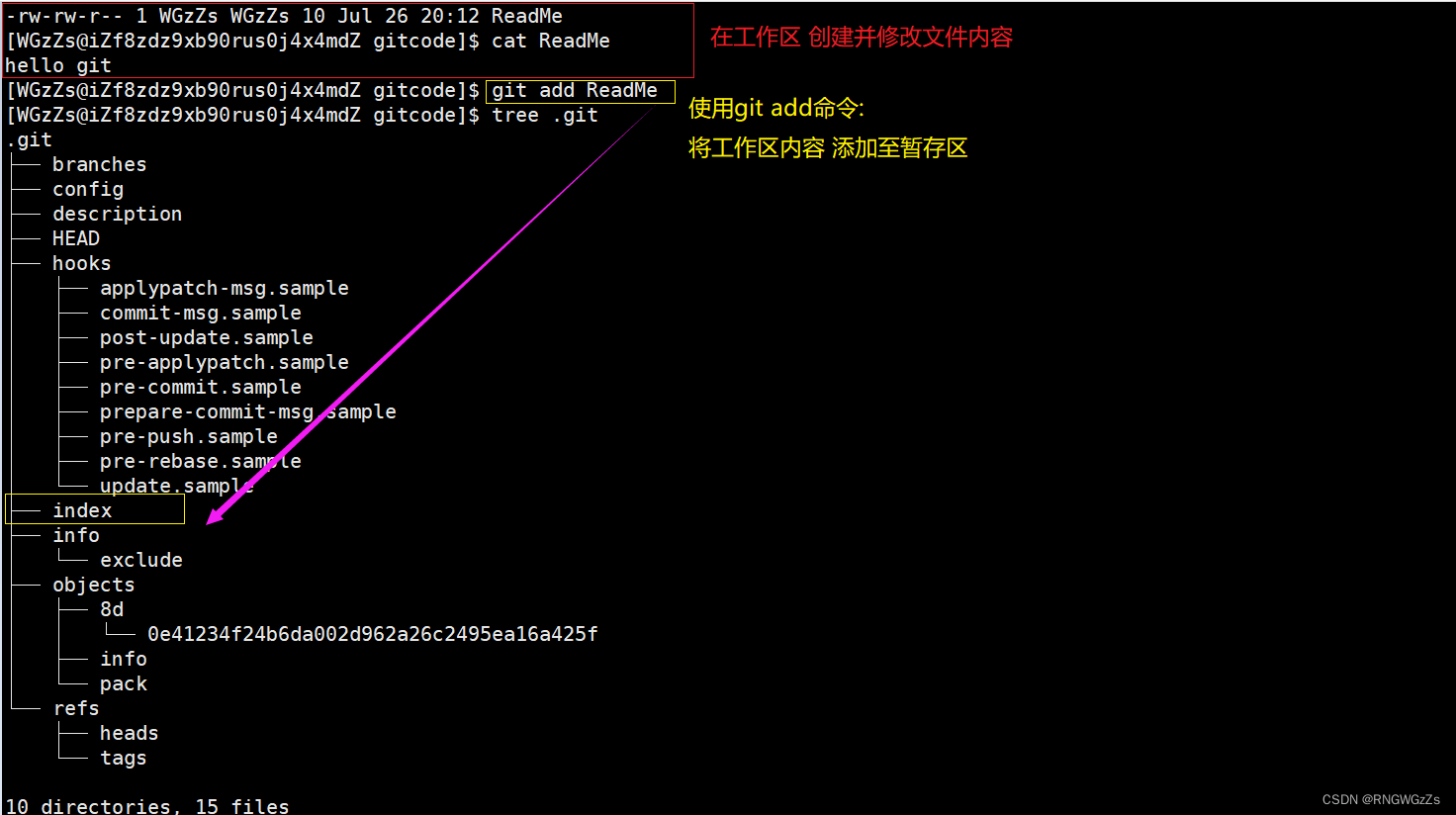
当执⾏提交命令“git commit”时,master分⽀会做相应的更新,可以简单理解为暂存区的⽬录
树才会被真正写到版本库中。
由上述例子我们得知:新建或粘贴进⽬录的⽂件,并不能称之为向仓库中新增⽂件,⽽只是在⼯作区新增了⽂件。必须要通过使⽤"git add"和"git commit"命令才能将⽂件添加到仓库中进⾏管理!!!
(3) 使用Git添加文件
添加文件场景一:
在之前我们已经添加了Readme文件了,现在我们再继续在工作区创建几个文件,一并进行添加到暂存区。
# 添加⼀个或多个⽂件到暂存区
git add [file1] [file2] ...
# 添加指定目录到暂存区
git add [dir]
# 添加当前⽬录下的所有⽂件改动到暂存区
git add .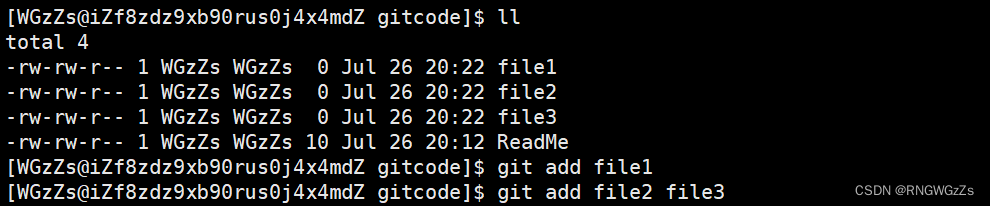
再使用git commit 命令将暂存区内容添加到本地仓库中:
# 提交暂存区全部内容到本地仓库中
git commit -m "message"
# 提交暂存区的指定⽂件到仓库区
git commit [file1] [file2] ... -m "message"注: "git commit" 携带-m,类似于一种备注。这一步是由用户自己完成,这部分内容绝对不能省略,并要好好描述,是⽤来记录你的提交细节,是给我们⼈看的。 
我们可以看到,自己所添加的文件通通被add到暂存区中,然后⼀次性commit暂存区的所有修改。
Git管理日志查看:
截止目前位置,我们成功将本地代码提交到了本地仓库,并且能被Git管理起来。也许你会说,"诶,你说的都不对啊!我咋没看到提交的地方在哪里呢?"。我们可以使用日志命令,查看历史的提交记录:
# 显⽰从最近到最远的提交⽇志,并且可以看到我们commit时的⽇志消息
git log
# 美化版git log
git log --pretty=oneline
需要说明的是,"4c35dfd627241ff..."、“a1806786780b1e0...”,这样的很长的字符串是每次我们进行“git commit”提交到本地仓库后,生成的commit id(版本号)。(当然这是它们内部计算生成出来的数字,自然不是本篇的探讨范畴)。
再谈.git文件:
① HEAD指针到底指向的是什么?
我们完成了上述"添加文件"的操作后,再次来查看一下".git"文件: 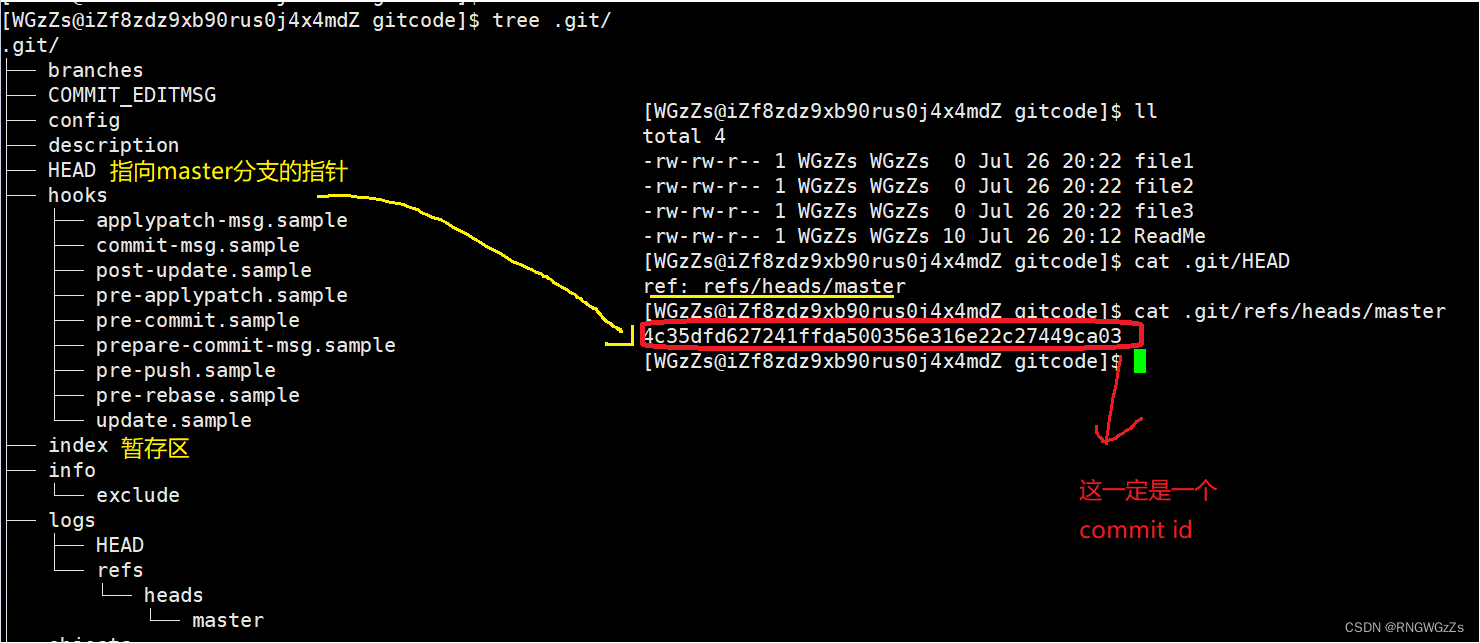
我们再通过git log日志查看:
我们发现,"refs/head/master"里保存的就是最新进行 "git commit"操作的 commit id。
② objects对象是什么?
objects为Git的对象库,⾥⾯包含了创建的各种版本库对象及内容。当执⾏"git add"命令时,暂存区的⽬录树被更新,同时⼯作区修改(或新增)的⽂件内容被写⼊到对象库中的⼀个新的对象中。我们通过tree命令查看 objects时,它将commit id分成了两个部分,其前2位是⽂件夹名称,后38位是⽂件名称。
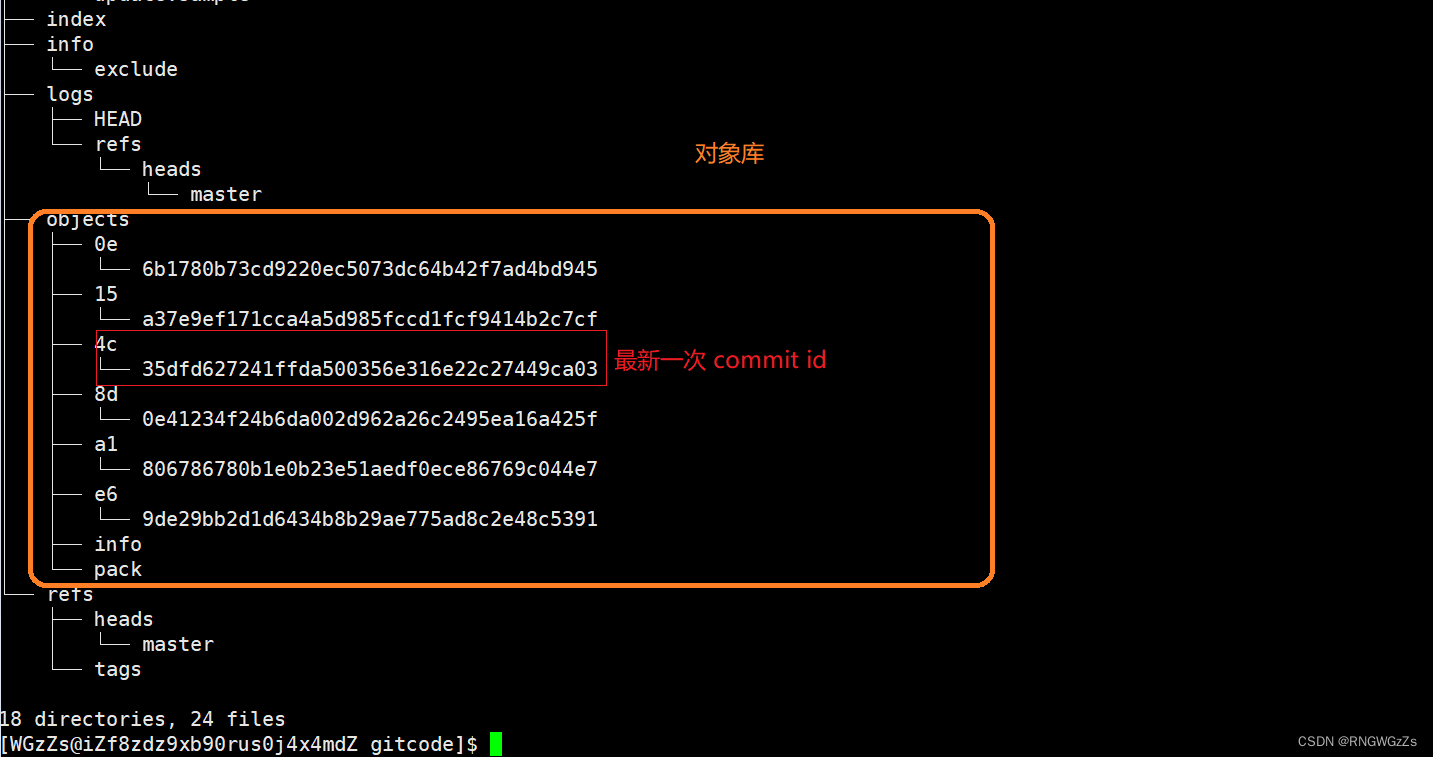

如果我们直接使用cat 这个commit id去查看里面的内容,是不行的,因为该类⽂件是经过算法加密过的。
# 查看objects的内容
git cat-file -p(pretty) commit_id
其中还有一行 "tree 15a37e9ef171cca4a5d985fccd1fcf9414b2c7cf",我们使用同样的方法打开,并且继续分别打开ReadM和file1。

这是我们对ReadMe做的修改,并且被Git记录了下来。
小结一下:
在本地的git仓库中,有⼏个⽂件或者⽬录很特殊:
• index:暂存区,"git add"后会更新该内容。
• HEAD:默认指向master分⽀的⼀个指针。
• refs/heads/master:⽂件⾥保存当前 master 分⽀的最新 commit id 。
• objects:包含了创建的各种版本库对象及内容,可以简单理解为放了git维护的所有修改。
(4) 使用Git修改文件
Git⽐其他版本控制系统设计得优秀,因为Git跟踪并管理的是修改,⽽⾮⽂件。如何理解修改呢?你在一个文件内"新增一行",“减少一行”,“更改了某个字符”……
现在我们对ReadMe文件进行修改: 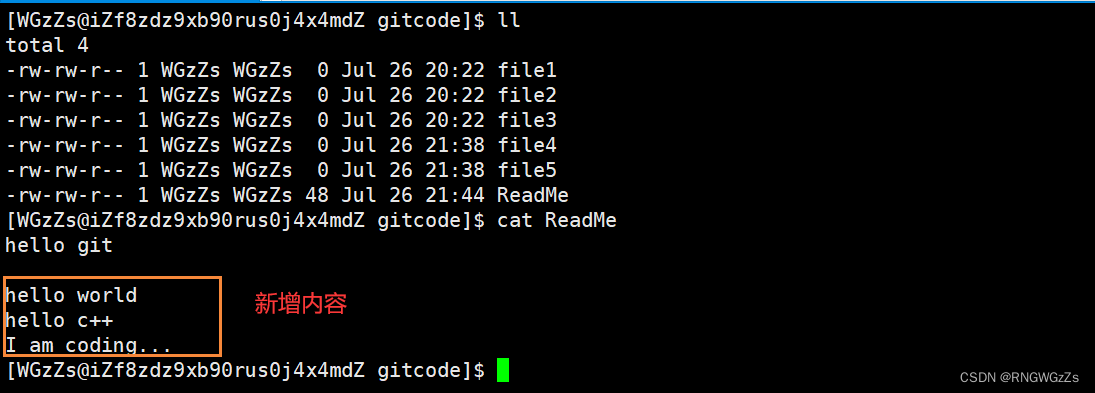
查看工作区操作状态:
那么此时,咱们工作区中的ReadMe文件和仓库中的ReadMe文件一定是不同的。我们怎么知道呢?因为这是我自己修改的更改的,那么我肯定知道。但是你总不能保证哪一天,一个懵懂的二五仔跑来你的本地仓库中更改了某个文件,而你不知道。
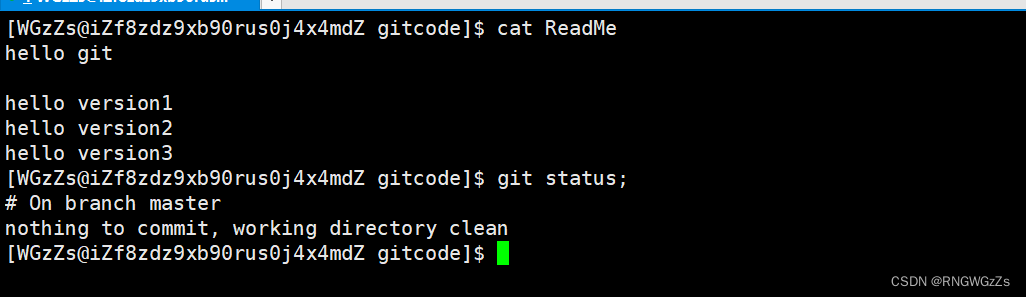
我们可以使用 "git status"命令⽤于查看在你上次提交之后是否有对⽂件进⾏再次修改。
 上面的结果告诉我们,ReadMe是被修改的,但是还没有被add 和 commit。
上面的结果告诉我们,ReadMe是被修改的,但是还没有被add 和 commit。
查看不同区的文件差异:
可是,我们仅仅是知道哪个文件被修改就为止了嘛?当然不是!是的,你通过 "git status"查到了自己的哪个文件被动过了,可是动的哪里?增加了那里?删除了哪里?你是一概不知的。也许你维护着一个文件,几行代码,唔凭借你超强的记忆力,能够分析出现如今的内容,哪些地方给动过了。然而如果是一分上百行上千行的代码呢?如果你发现不仅仅一个文件通过 "git status"查到被修改过了呢?很显然,你压根只能摇摇头,双手一摊,爱莫能助……
# ⽤来显⽰工作区和暂存区⽂件的差异
git diff [file]
# ⽤来显⽰⼯作区和版本库⽂件的差异
git diff HEAD -- [file]
# ⽤来显⽰暂存区和版本库⽂件的差异
git diff --cachedgit diff输出的内容:
diff --git a/ReadMe b/ReadMe
#"8d0e412..d4eeb06"表示两个文件的哈希值 || 100:表示普通文件 644:表示文件权限
index 8d0e412..d4eeb06 100644
# "--- a/ReadMe" 表示修改前的文件|| "+++ b/ReadMe" 修改后的文件
--- a/ReadMe
+++ b/ReadMe
# "-"表示修改前,"1"表示第一行开始
# "+"表示修改后,"1,5"表示第一行开始至第五行
# 这里"+" 表示这一行增加了什么...
@@ -1 +1,5 @@
hello git
+("空行")
+hello world
+hello c++
+I am coding... 知道了对ReadMe做了什么修改后,再把它提交到本地仓库就放⼼多了。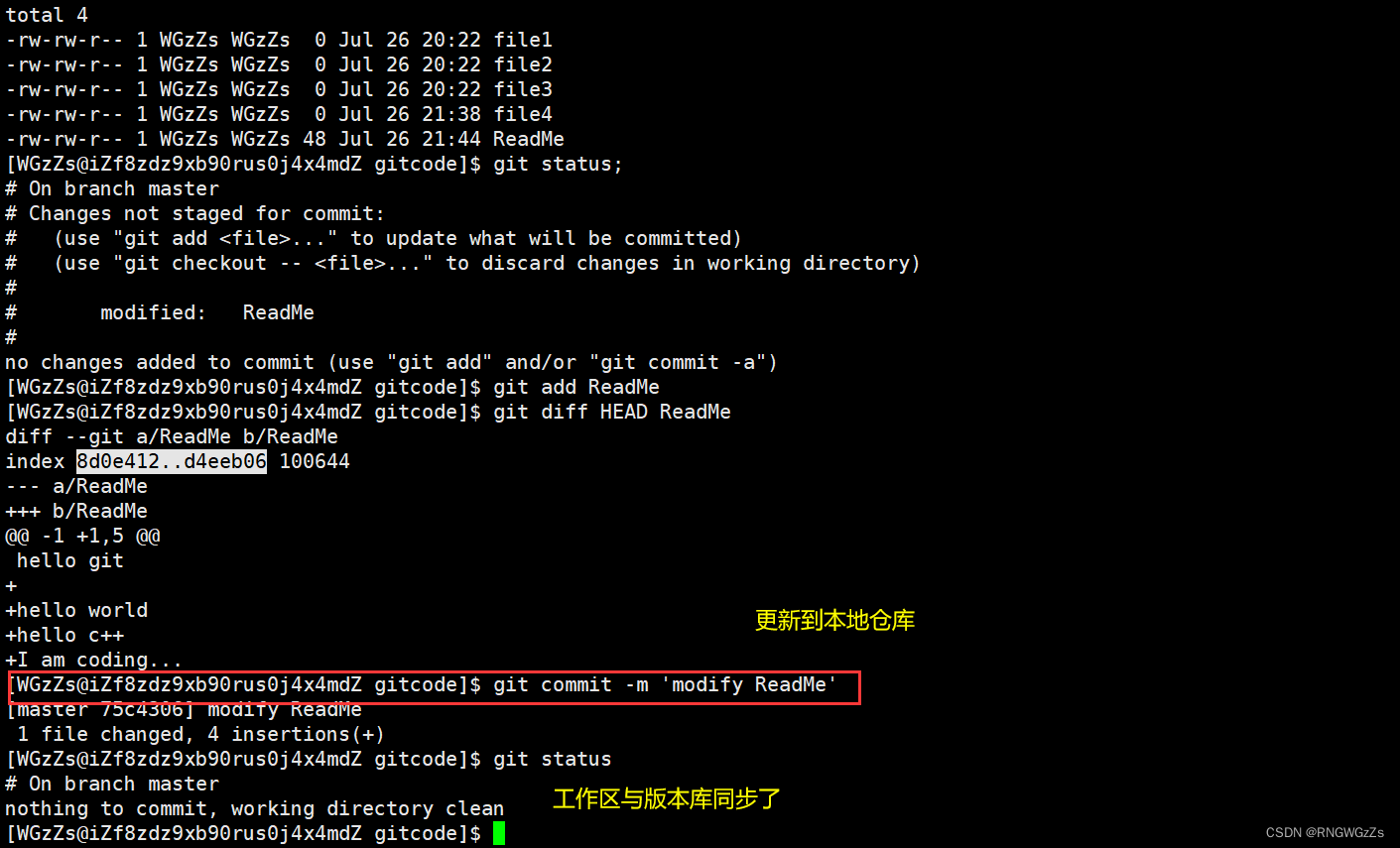
(5) 使用Git版本回退
不知道你是否还记得前言的例子,那则小故事说明了版本管理的重要性。Git能够管理⽂件的历史版本,这也是版本控制器重要的能⼒。如果哪天,你发现需要回退到某个"历史版本",重新来过,这个时候就需要版本回退的功能了。
值得注意的是,"回退"的本质,其实只是着眼于将版本库中的文件内容进行回退,至于工作区或者暂存区是否也能进行回退,那取决于命令参数。
# 执行版本库中的回退
git reset| 参数 | 作用 |
| --mixed | 为默认选项,使⽤时可以不⽤带该参数。该参数将 "暂存区”的内容退回为指定提交版本内容,“⼯作区” ⽂件保持不变。 |
| --soft | 参数对于⼯作区和暂存区的内容都不变,只是将版本库回退到某个指定版本。 |
| --hard | 参数将 "暂存区" 与 "⼯作区" 都退回到指定版本。切记⼯作区有未提交的代码时不要⽤这个命令,因为⼯作区会回滚,你没有提交的代码就再也找不回了,所以使⽤该参数前⼀定要慎重。 |
| HEAD | ◦ 可直接写成commitid,表⽰指定退回的版本 ◦ HEAD^上⼀个版本 ◦ HEAD^^上上⼀个版本 ... ◦ HEAD^2上上⼀个版本 ... |
我想以这样的形式,你一定难以理解这个版本究竟是怎样进行回退的,这些参数是怎样运作的。所以为了方便测试回退功能,我们先做⼀些准备⼯作:
更新3个版本的ReadMe,并分别进⾏3次提交。

现如今,我们发现版本3有问题,想回到版本2,想基于版本2重新进行代码编写。由于我们这里是想要让工作区的ReadMe文件回到版本2,因此携带的参数必须是 "--hard"。 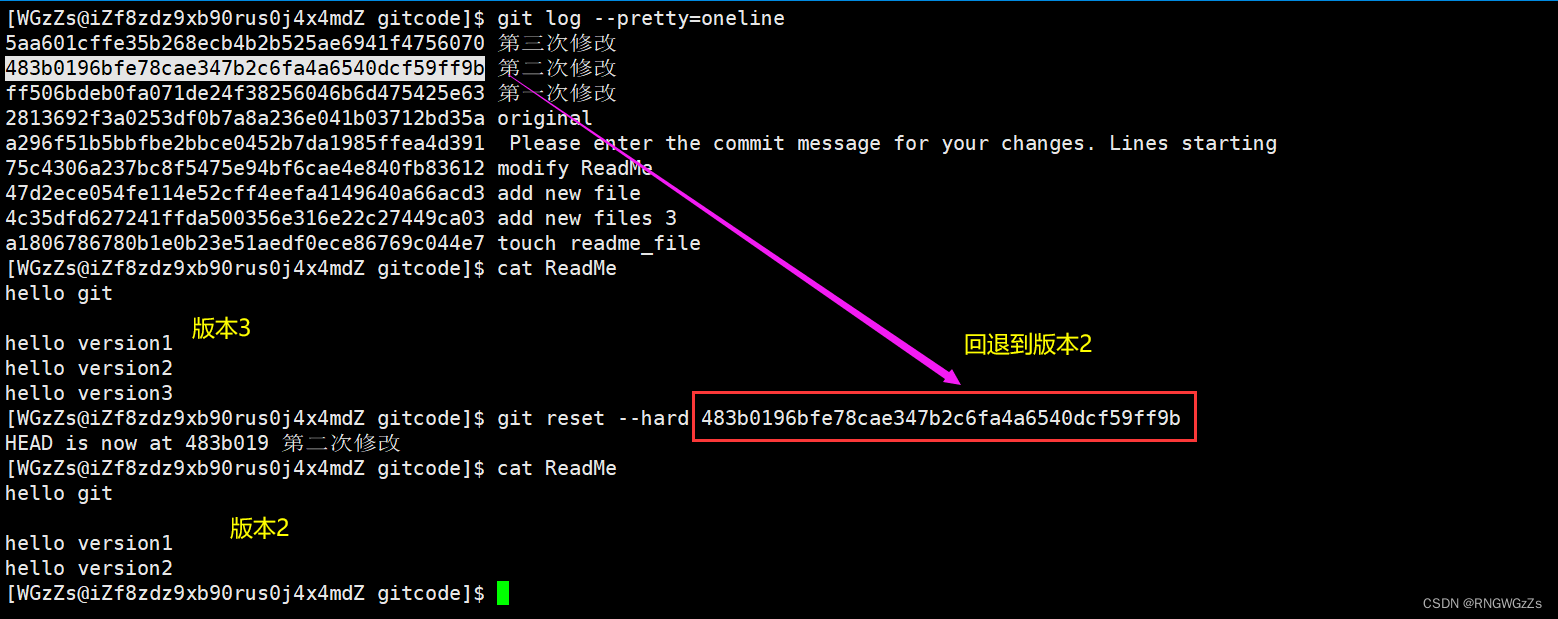
版本回退之后,我们再次使用git log查看日志,这时候我们会惊奇地发现,发现 HEAD 指向了版本2。
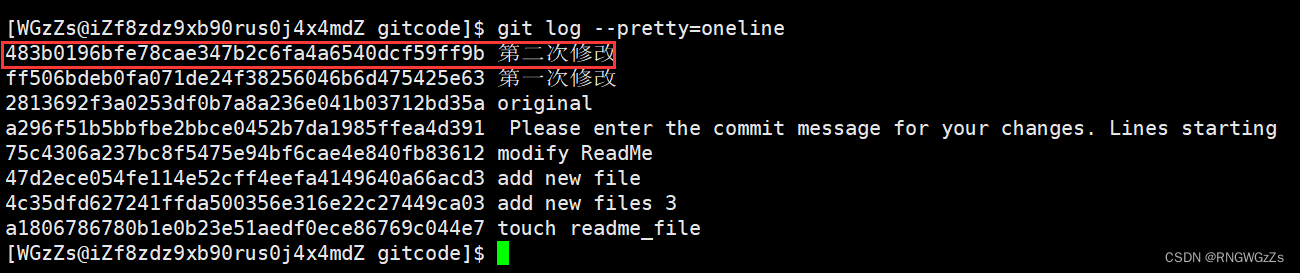
但此时,我又发现版本3毕竟花费了我几十秒钟的心血,现在我又想把版本回退到3上去。但此时,用git log查只能查到版本2的commit id,也就意味着版本3的commit id已经"弄丢了"。(不过在我们这一台机器上其实在回退之前是记录到了版本3的commit id的,按照回退版本2的方式,也就可以回退到版本3了)。为此,Git还提供了一个命令用于补救这种情况。
# 该命令⽤来记录本地的每⼀次命令
git reflog
这个"5aa601c"是个啥?显然是一个commit id,但是是它的一部分而已。是的,Git在版本回退的时候,也可以使用部分commit id来代表目标版本。

这样我们的版本3也就回来了。
事实上,reflog并不是任何场景都下都能找到你丢失的commit id,如果开发时间够长,导致commit id早就丢失了,此时又想退回到该版本,其实是不可能的。
小结一下:
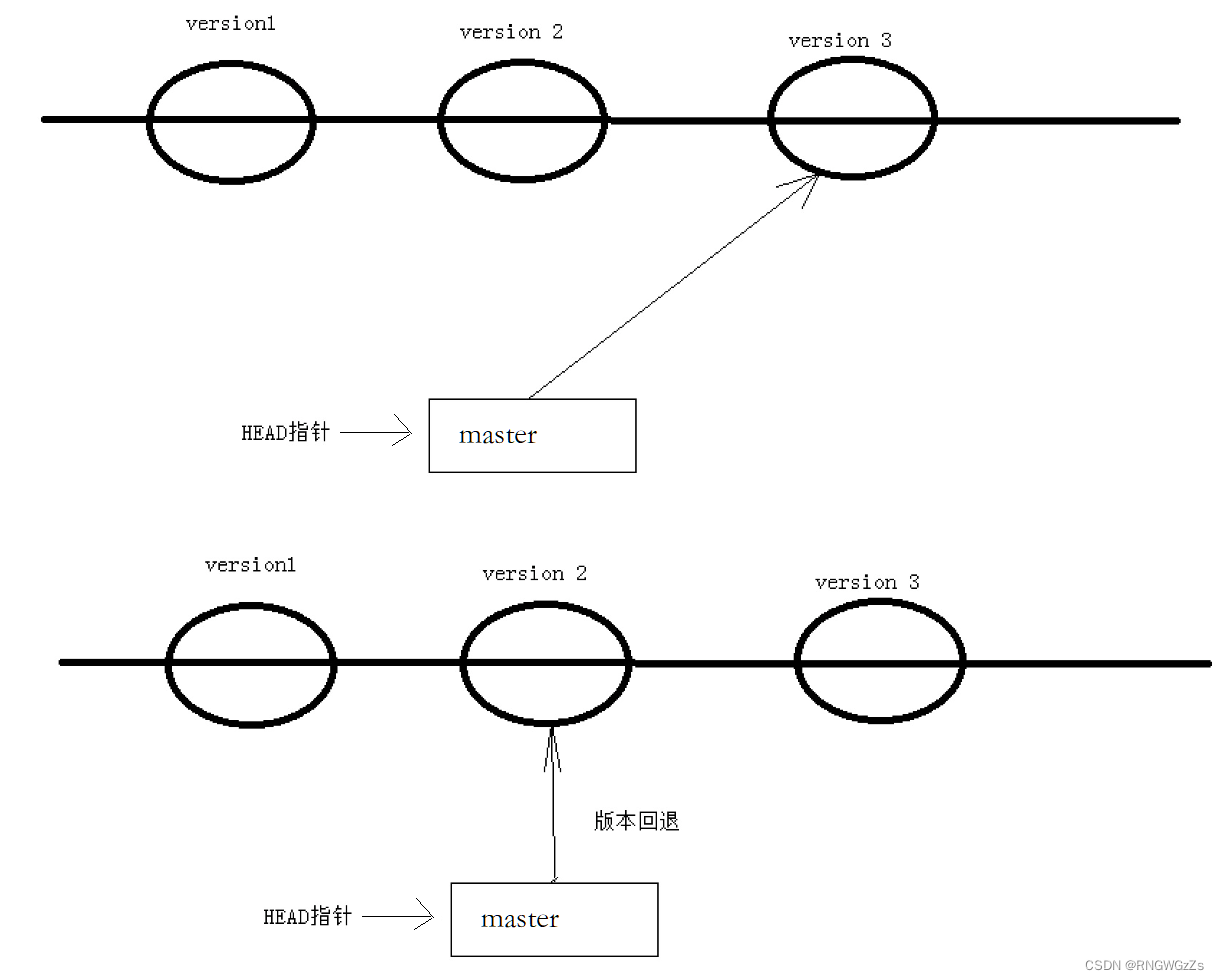
我想到了现在,恐怕你对Git中版本回退的操作有了一定的理解。这个图能很到位地解释各个参数的功能,以及回退后的内容是什么。

如何理解版本回退?
当然,上面费那么多口舌是针对Git如何进行版本回退。那么Git的内部是如何实现版本你回退的呢?
Git的版本回退速度⾮常快, 因为Git在内部有个指向当前分⽀(这里就指master)的HEAD指针, refs/heads/master ⽂件⾥保存当前分⽀的最新操作的commit id。当我们进行版本回退的时候,可以简单的理解为,Git仅仅是给 refs/heads/master 中存储⼀个特定的version。像这样:
(6) 使用Git撤销修改
现在我们正在工作区,在长时间高压下把代码写得越来越烂,想恢复到上一个版本。这时候我们该怎么做呢?
情况一: 对于工作区代码,还没有进行add操作 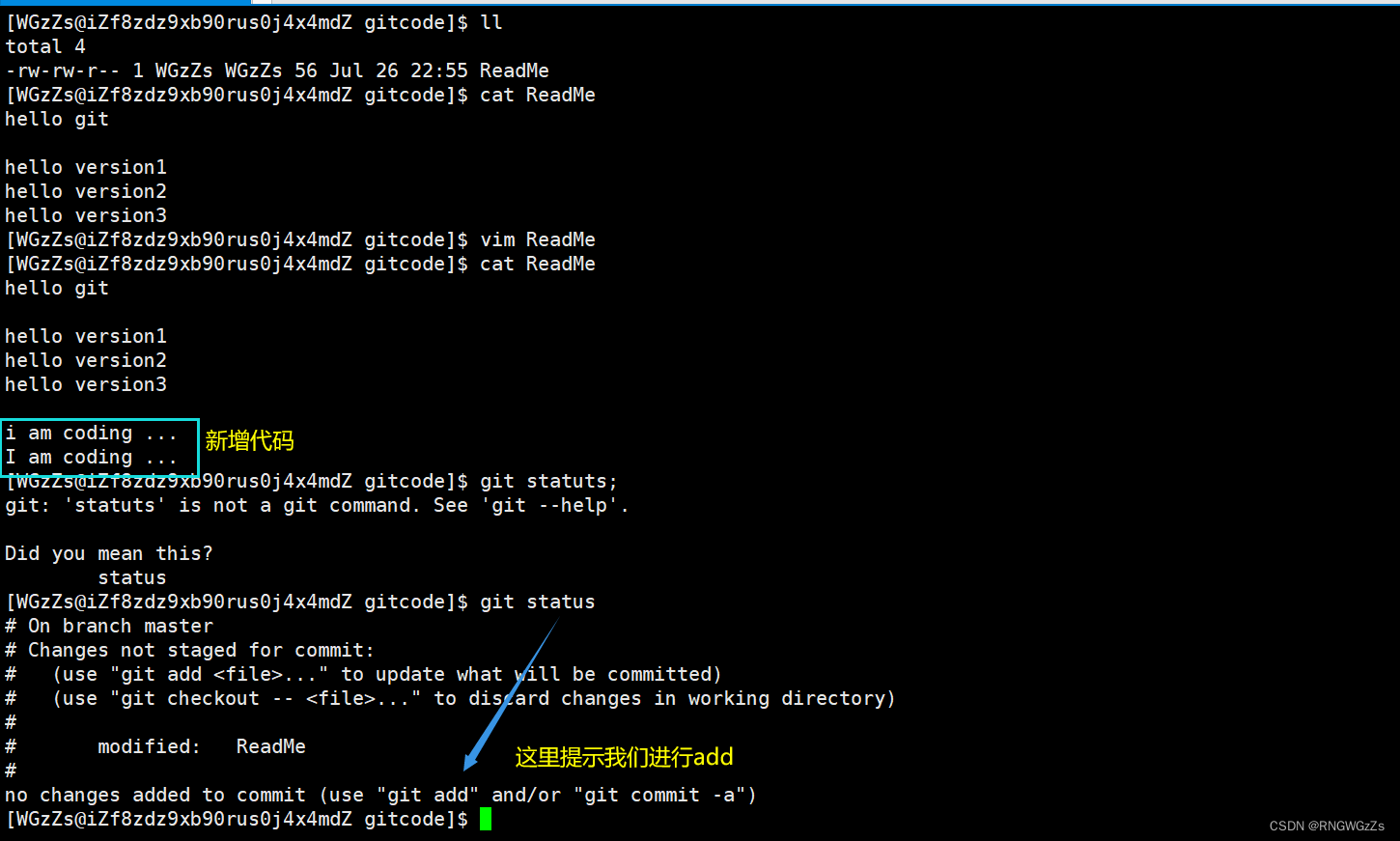
对于这种情况,采取的最好方式,删除你增加的代码即可。
唔,这显然只能针对你几天只敲了那可怜的几行代码,如果你连续干了三天,写了上千行代码呢?你怎么知道该删哪些?保留哪些?"噢 ! 之前不是有个 "git diff"命令,用来查看不同版本的文件内容的差异嘛?emm这个好。"于是乎,你盯着那个 " git diff "的输出在那里仔细比对啊,仔细删啊,可不能删除问题啊,毕竟改完代码后,反而多出来个bug又是一个费时间的活路……
Git为我们提供了更好的方式,我们可以使⽤:
# 让⼯作区的⽂件回到最近⼀次"ad"或"commit"时的状态
git checkout -- [file]
切记: 不能省略"--",否则就是另一个命令。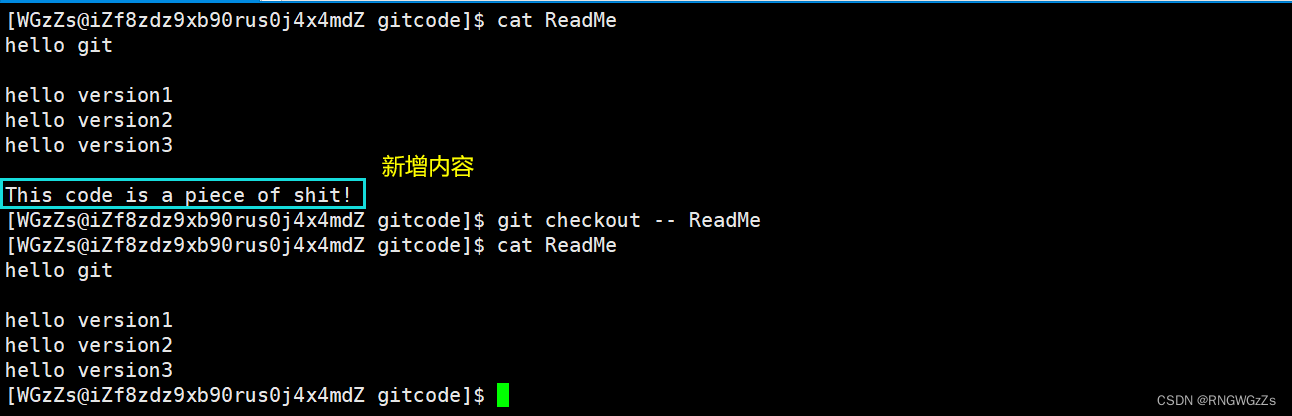
情况二: 已经add了,但还没有commit
当我们把工作区的文件”add”后还是保存到了暂存区呢?怎么撤销呢? 让我们来回忆一下,"git reset"的其中一个参数"--mixed",可以将暂存区的内容退回到指定版本的内容,并且保证工作区的内容不变。所以,接下来我们只需要让,暂存区的内容回退即可。
让我们来回忆一下,"git reset"的其中一个参数"--mixed",可以将暂存区的内容退回到指定版本的内容,并且保证工作区的内容不变。所以,接下来我们只需要让,暂存区的内容回退即可。 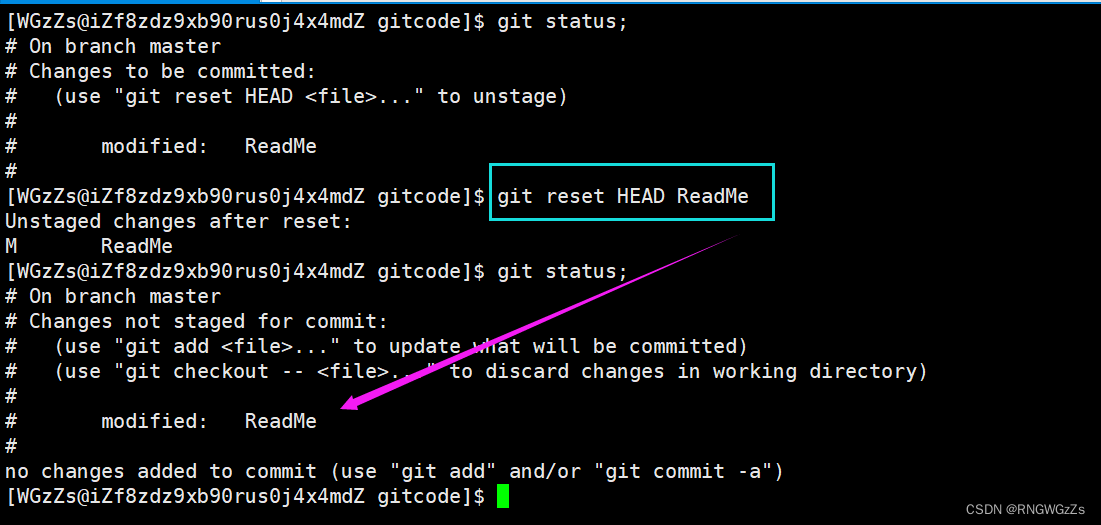
此时,我们就会发现现在的暂存区的干净的,只是工作区需要修改。还记得工作区如何进行撤销修改吗? 这不就是场景一嘛?(这里不做过多演示了)。
情况三: 已经add,已经commit了
此刻的文件已经存放在版本库里了?该咋办? 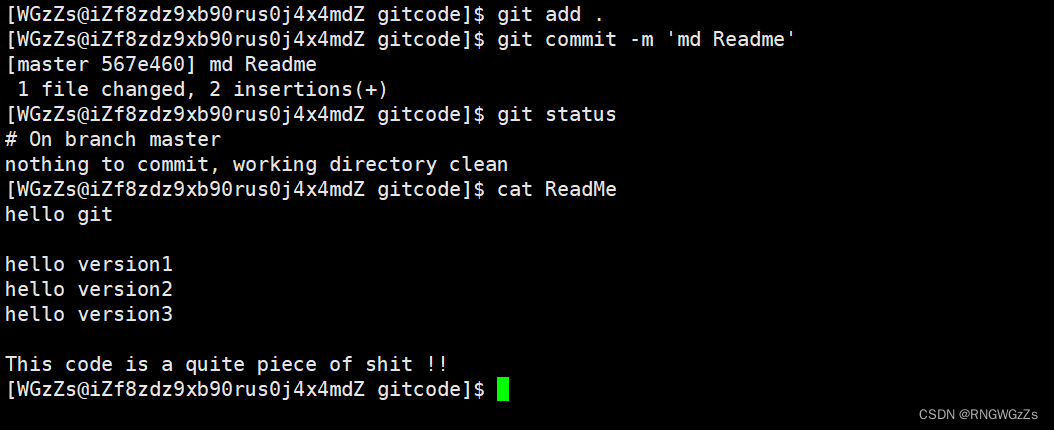
emm,这时候你还是老大老实地按照版本回退的方式吧。可是我怎么知道它的上一个版本呢?这不用怕,每一个objects对象内都会有一个parent指针指向该版本的上一个版本是谁。

我们需要让工作区、暂存区、版本库都回到上一个版本:
git reset --hard HEAD^ ReadMe
当然,这么放肆、张狂地使用 --hard的唯一条件前提是,你还没有将你本地仓库的代码推送到远端仓库(也就是git三板斧的最后一步 "git push")。否则,你总会吸取教训,为你的无知、轻狂付出代价。
(7) 使用GIt删除文件
在Git中,删除也是⼀个修改操作,在这里我们删除一个已经commit了的文件。 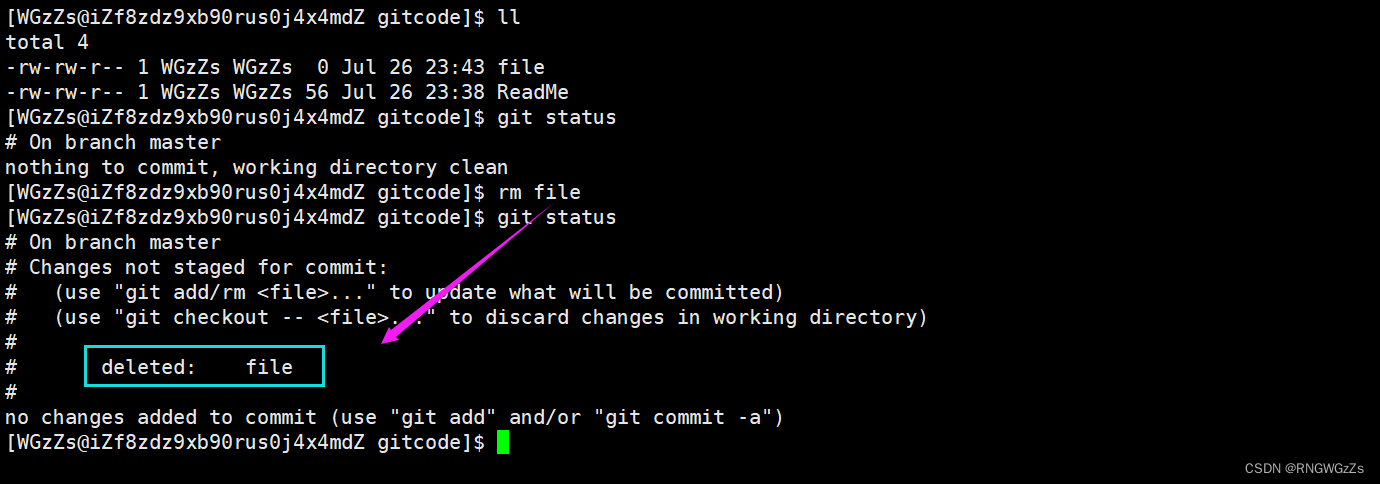
你会发现,你这样删除其实是没有卵用的,git status 命令会⽴刻告诉你哪些⽂件被删除了。
此时,⼯作区和版本库就不⼀致了,要删⽂件,⽬前除了要删⼯作区的⽂件,还要清除版本库的⽂件,这样才能保证一致性。
如果是误删:
使用之前提到过的命令 " git checkout -- file",恢复删除的文件。

如果就是要删除该文件:
因为这样做,只是删除了工作区的部分,还需要将该文件从暂存区、版本库中移除,并且 commit。 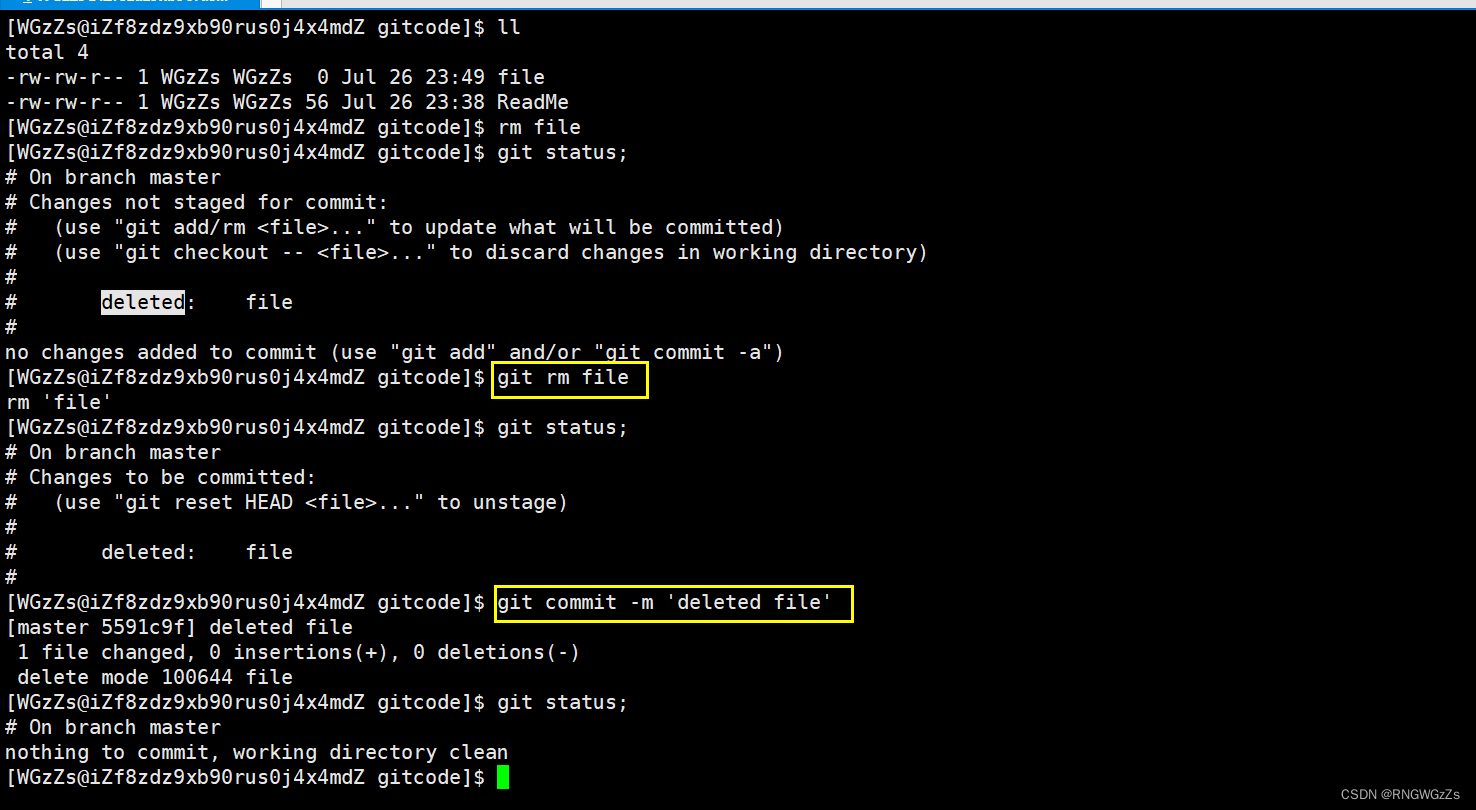
这样这个文件也算是成功删除了。
三、分支管理
本章开始介绍Git的杀⼿级功能之⼀:分支。
(1)如何理解分支?
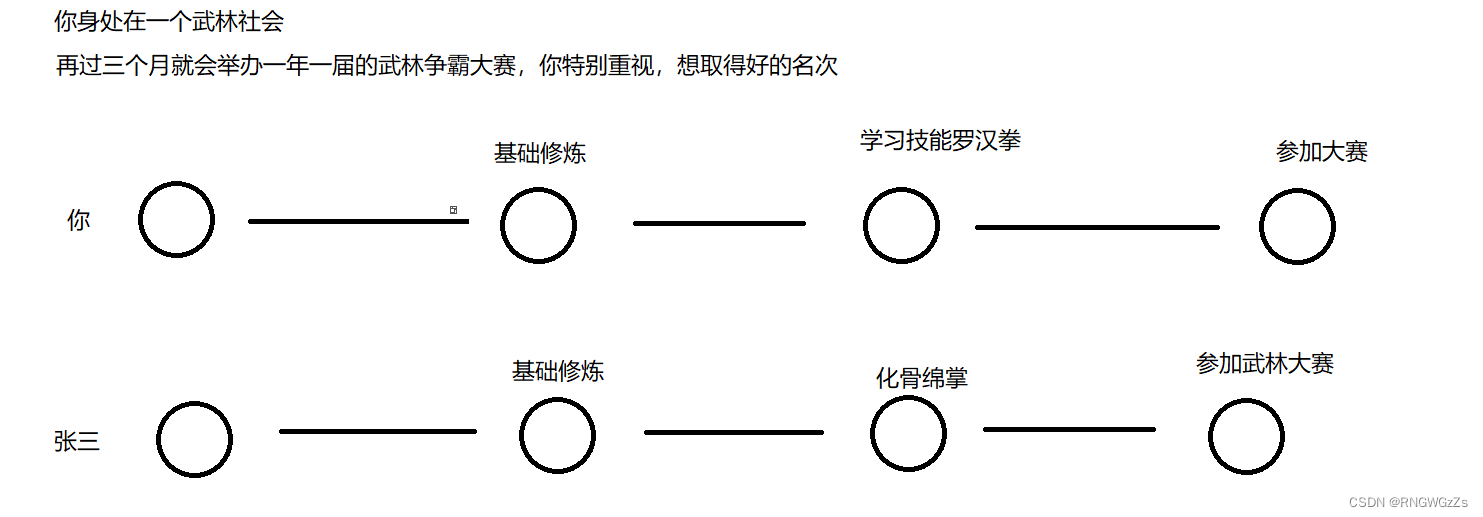 此时你会发现,同样是三个月的准备时间,你同另外一个也想参与这场大赛的张三一样,做着相同的准备工作。
此时你会发现,同样是三个月的准备时间,你同另外一个也想参与这场大赛的张三一样,做着相同的准备工作。
直到有一天,你觉醒了,拥有分身的技能。 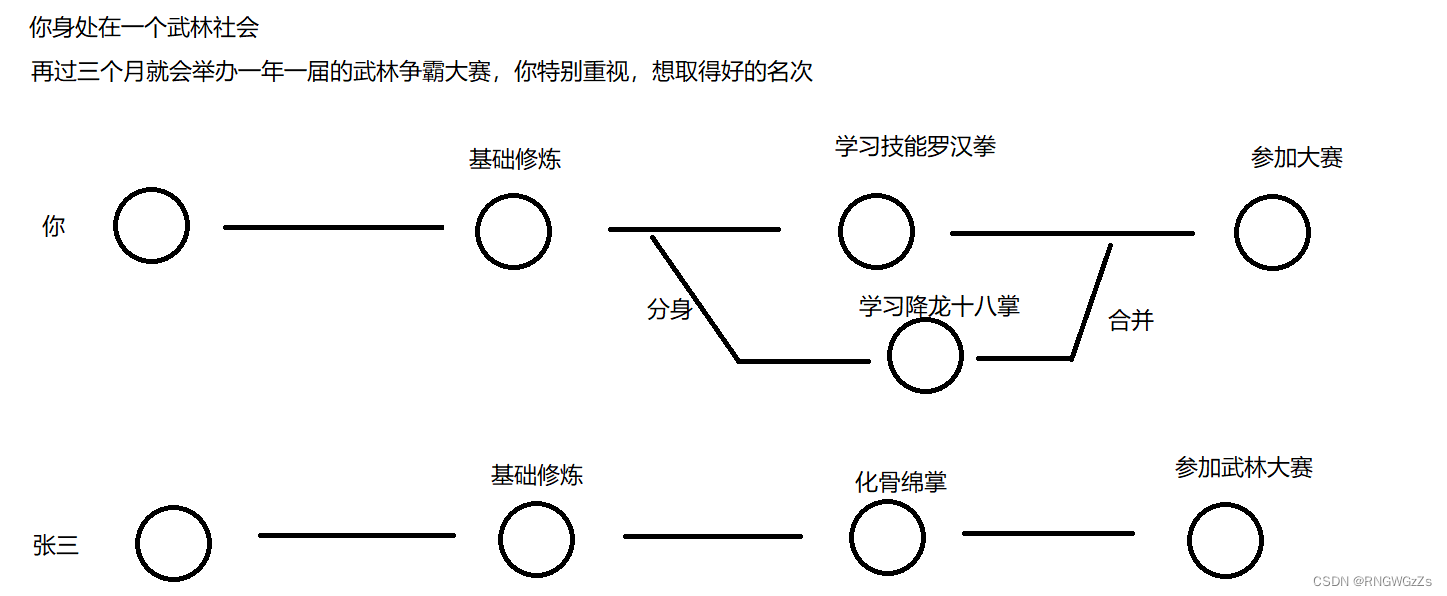
由此,在正式参与该大赛之前,你可以习得比张三多出来的一个技能,增加赢得比赛的可能性。
我们在回到版本回退那里,因为每一次Git提交,就会保存每一次操作的comit id,方便回退查找。于是乎,这条由Git管理的时间线上,会出现多个版本目录。截止目前为止,没有出现创建其他分支的情况,所以这一条时间线里,在Git里这一条分支叫主分支,即master分支。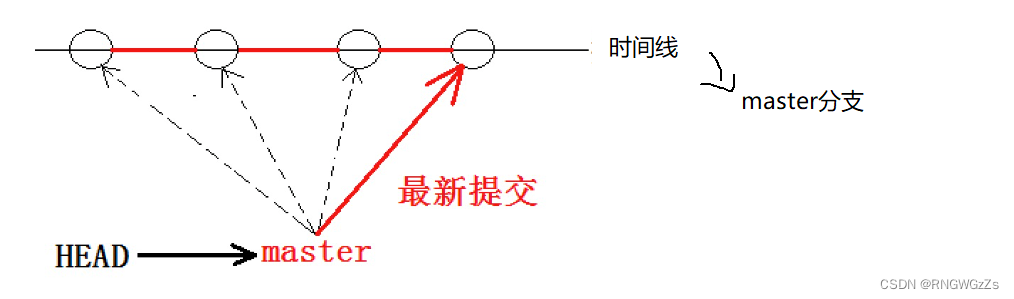 所以,HEAD指针压根不是指向的提交的最新版本,而是指向的"当前分支",当前分支也就是master,而真正指向最新一次提交的才是master。每次提交,master分⽀都会向前移动⼀步,这样,随着你不断提交,master分⽀的线也越来越⻓,⽽HEAD只要⼀直指向master分⽀,即可指向当前分⽀。
所以,HEAD指针压根不是指向的提交的最新版本,而是指向的"当前分支",当前分支也就是master,而真正指向最新一次提交的才是master。每次提交,master分⽀都会向前移动⼀步,这样,随着你不断提交,master分⽀的线也越来越⻓,⽽HEAD只要⼀直指向master分⽀,即可指向当前分⽀。
(2) 创建分支
Git支持我们查看或创建分支,下面我们来创建分支。
# 查看分支状态
git branch
# 创建分支
git branch [branch_name] 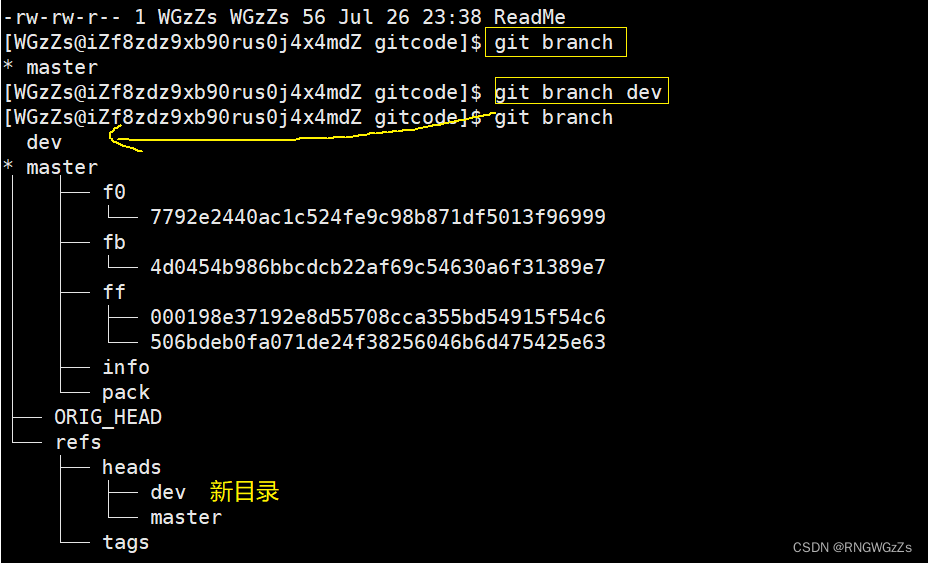
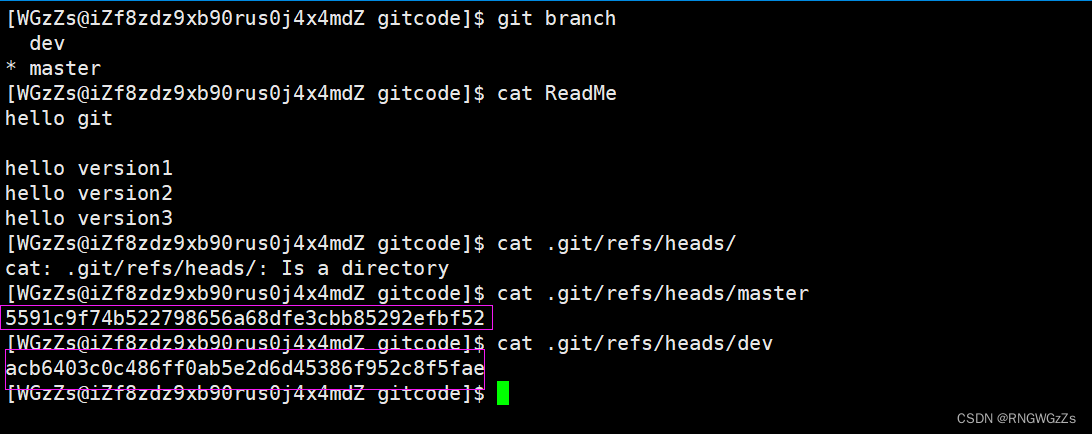
在我们创建完分支后,Git会在 .git/refs/heads 中新增一个指针dev,“*”表示当前正在使用的分支,也就是HEAD指向的分支(master)。
另外,我们查看dev分支结构时发现,dev 和 master指向同⼀个修改。
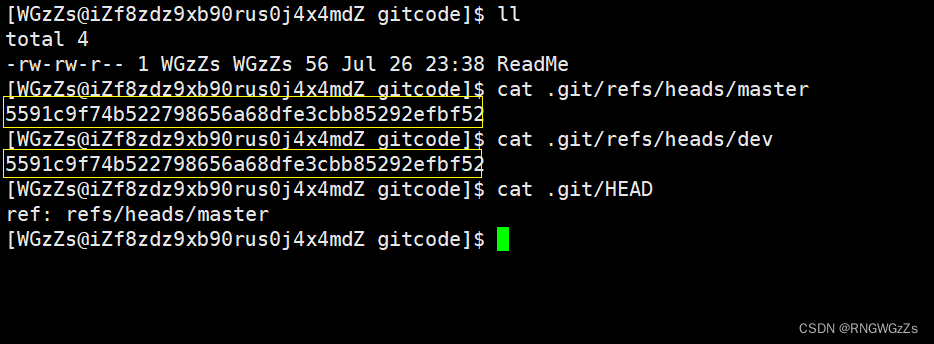
因此,可以这样理解一个分支"dev"的创建:
(3) 切换分支
创建分支不是让它来走秀场的,我们应该如何使用分支,在分支环境下进行开发呢?
# 切换分支
git checkout [branch_name] --> != git checkout -- file_name(这是撤销修改)
# 切换分支+创建
git checkout -b [branch_name]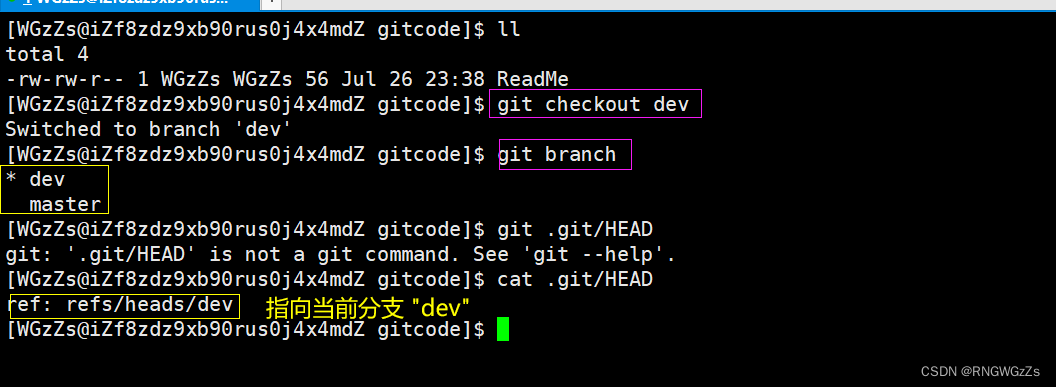
现如今,我们的HEAD指针指向了当前分支“dev”。
分支上的新增文件:
我们现在开始在dev修改 ReadMe文件,并且进行添加、提交操作。 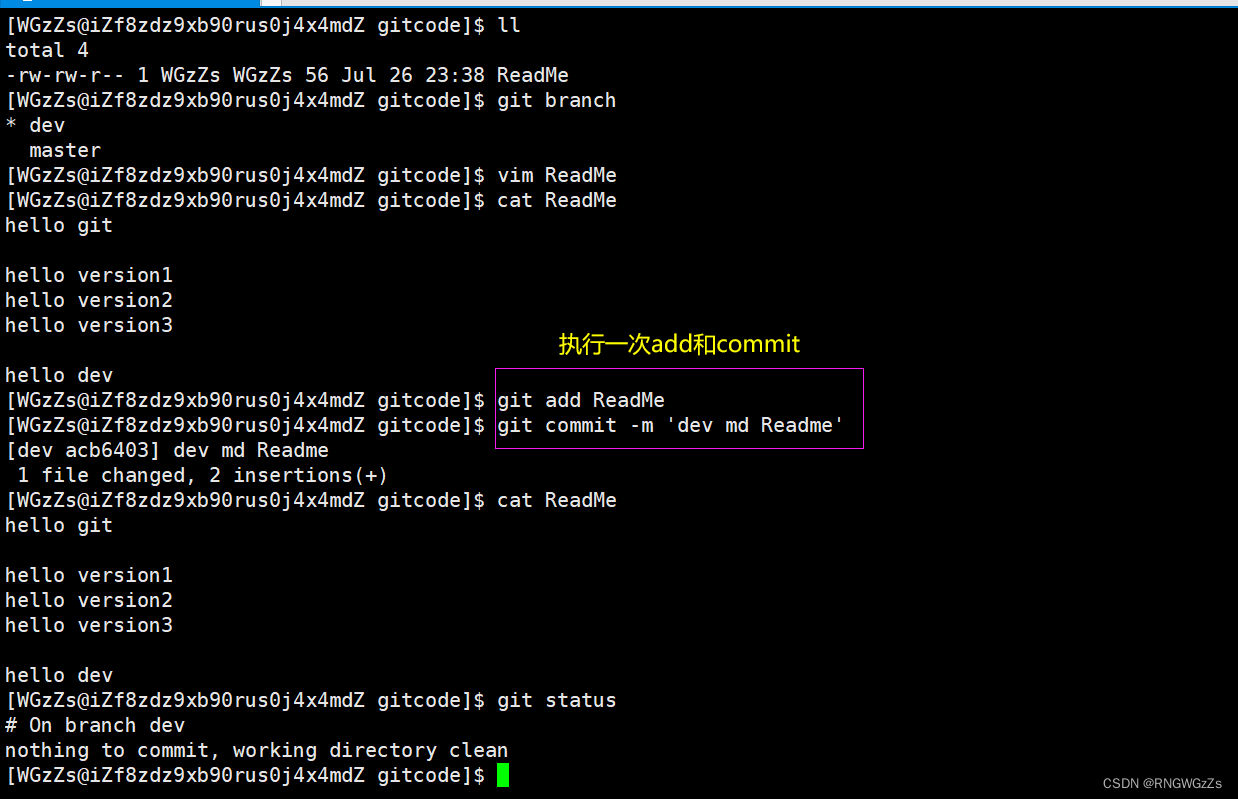
我们现在回退到master分支上,再来查看Readme文件,我们会发现之前更新修改的ReadMe文件还是原先的样子,可是dev上的ReadMe文件已经是被修改了的。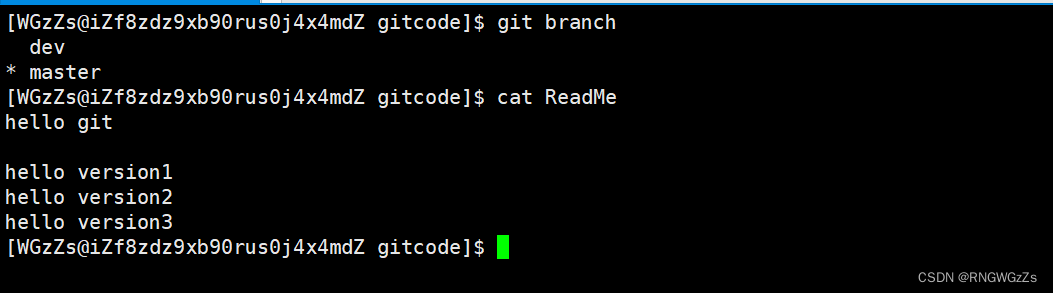
那么能给出解释的唯一理由就是,现在这两个ReadMe文件一定不是同一个对象!!
看到这⾥就能明⽩了,因为我们是在dev分⽀上提交的,⽽master分⽀此刻的提交点并没有变,此时的状态如图如下所⽰。
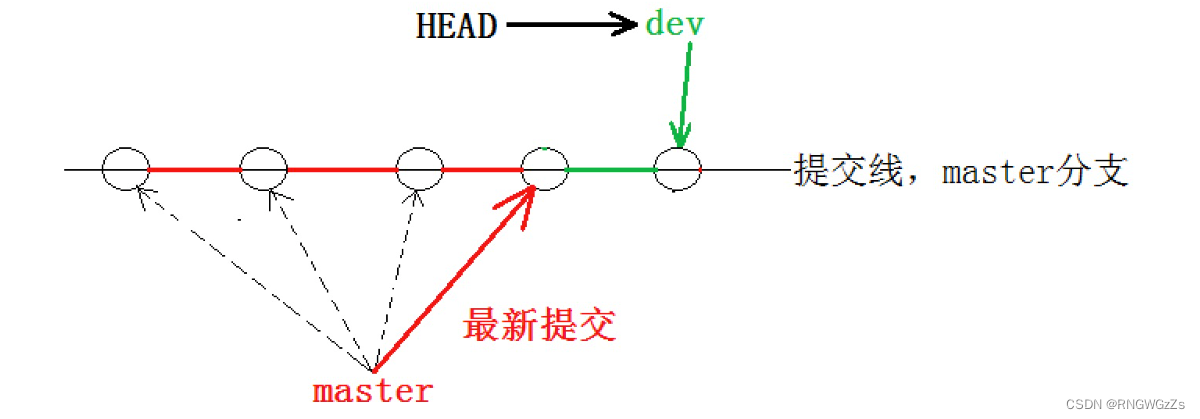 当切换到master分⽀之时,HEAD就指向了master,当然看不到提交了!
当切换到master分⽀之时,HEAD就指向了master,当然看不到提交了!
(4) 合并分支
紧跟上一个问题,现如今我的master分支看不到dev提交的新版本,而我们需要做的就是,将“dev”分支合并到“master”分支上。
# 命令⽤于合并指定分⽀到当前分⽀
git merge [branch_name]
# 非快进模式
git merge --no-ff [branch_name]
● Fast-forward代表“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度⾮常快。当然,也不是每次合并都能Fast-forward。
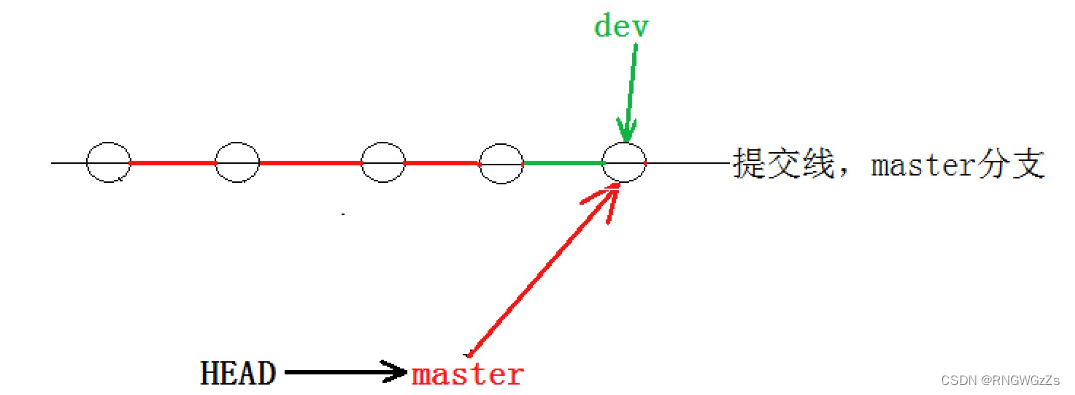
(5) 删除分支
在分支和主分支合并完成后,对我们来说dev分支其实就没啥用了。那么dev分支就应该没删除掉。
注:如果当前正处于某分⽀下,就不能删除当前分⽀
# 删除分支
git branch -d [branch_name]
# 强制删除分支(没有merge的分支)
git branch -D [branch_name]
此时的状态如图如下所⽰。
因为创建、合并和删除分⽀⾮常快,所以Git⿎励你使⽤分⽀完成某个任务,合并后再删掉分⽀,这和直接在master分⽀上⼯作效果是⼀样的,但过程更安全。
(6) 合并冲突
有时候,并不是你想合并就能合并成功的,有时候可能会遇到代码冲突的问题。我们现在先创建并切换到新分支dev1上去。

在 dev1 分⽀下修改 ReadMe ⽂件,更改⽂件内容如下,并进⾏⼀次提交:

之后,我们切换到master分支上,很显然我知道该ReadMe文件仍然是不会受到dev1修改的影响的。并且我们会在master分支上对ReadMe文件进行修改,并进行提交。

 现在, master 分⽀和 dev1 分⽀各⾃都分别有新的提交,变成了这样:
现在, master 分⽀和 dev1 分⽀各⾃都分别有新的提交,变成了这样:
这种情况下,Git只能试图把各⾃的修改合并起来,但这种合并就可能会有冲突:

当文件发生冲突时,查看⽂件内容时,Git会⽤<<<<<<<,=======,>>>>>>>来标记出不同分⽀的冲突内容,内容如下: 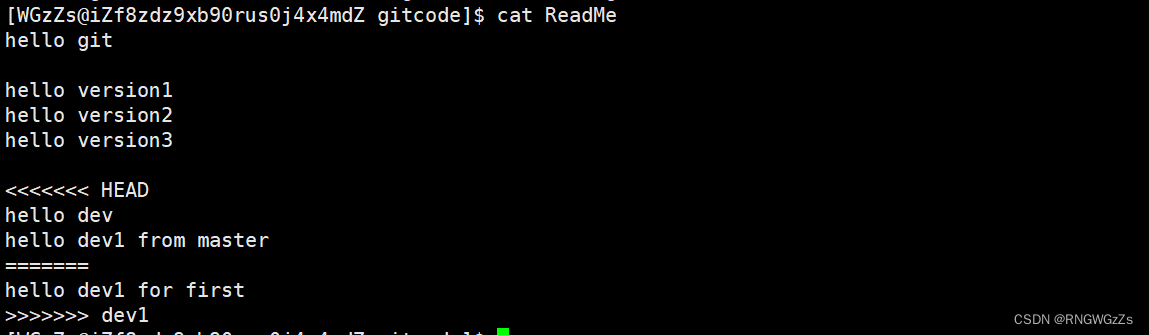
此时我们必须要⼿动调整冲突代码,并需要再次提交修正后的结果!!(再次提交很重要,切勿忘记)。
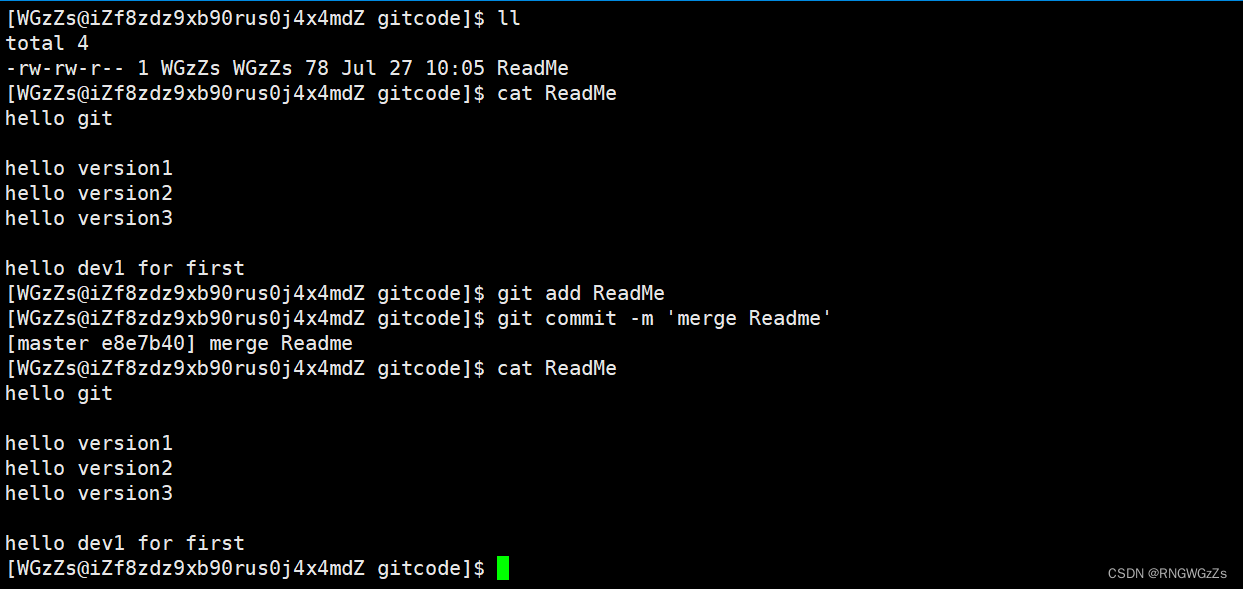
当然这里的手动删除,是保留两个版本commit的其中一个。到这⾥冲突就解决完成,此时的状态变成了。 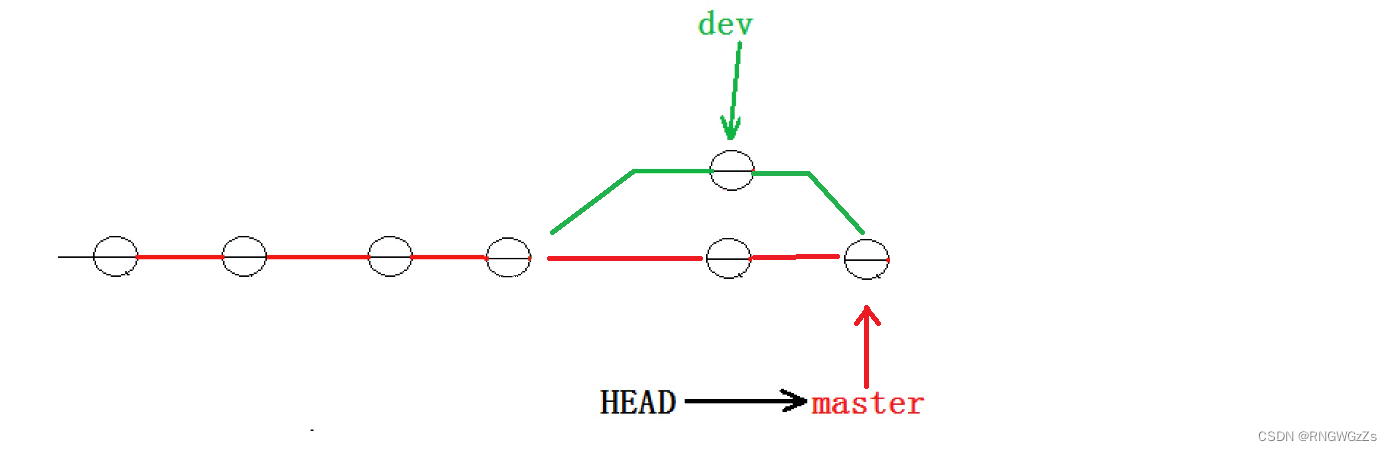
git log查看分支:
# 看到分⽀的合并情况
git log --graph --pretty=oneline --abbrev-commit
最后,不要忘记dev1分⽀使⽤完毕后就可以删除了。
(7) 分支管理策略
通常合并分⽀时,如果可能,Git会采⽤ Fast forward 模式。还记得如果我们采⽤ Fast
forward 模式之后,形成的合并结果是什么呢?回顾⼀下。
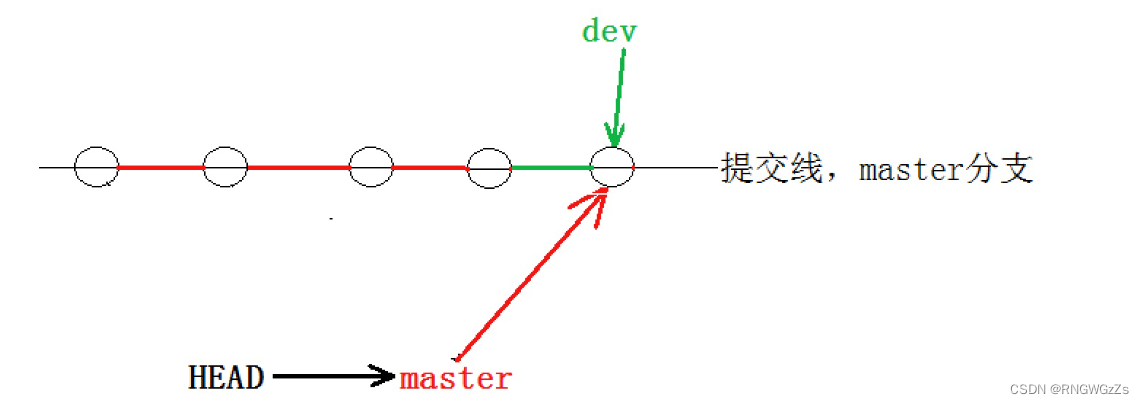
在这种 Fast forward 模式下,删除分⽀后,查看分⽀历史时,会丢掉分⽀信息,看不出来最新提交到底是merge进来的还是正常提交的。
但在合并冲突部分,我们也看到通过解决冲突问题,会再进⾏⼀次新的提交,得到的最终状态为:
那么这就不是 Fast forward 模式了,这样的好处是,从分⽀历史上就可以看出分⽀信息。
例如我们现在已经删除了在合并冲突部分创建的 dev1 分⽀,但依旧能看到master其实是由其他分⽀合并得到。
使用--no-ff参数合并分支:
Git⽀持我们强制禁⽤ Fast forward 模式,那么就会在merge时⽣成⼀个新的 commit ,这样,从分⽀历史上就可以看出分⽀信息。
我们需要先创建一个分支的dev2,并切换⾄新的分⽀: 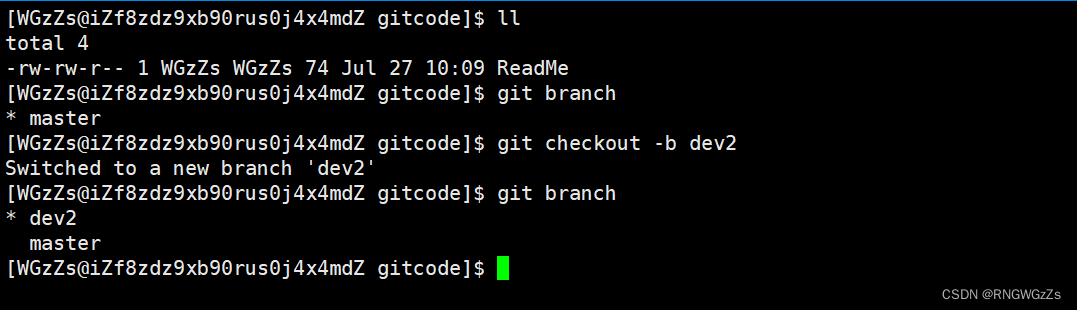
修改 ReadMe ⽂件,并提交⼀个新的 commit: 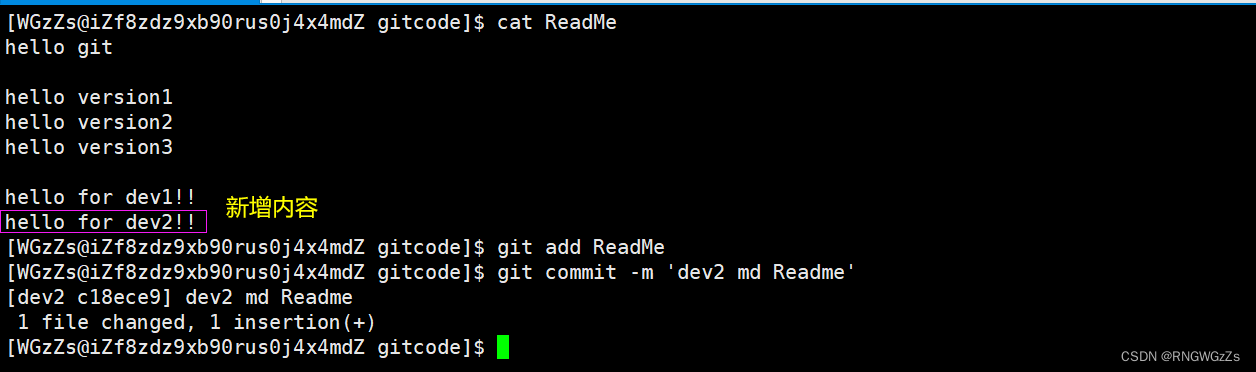
切回到master分支进行合并:
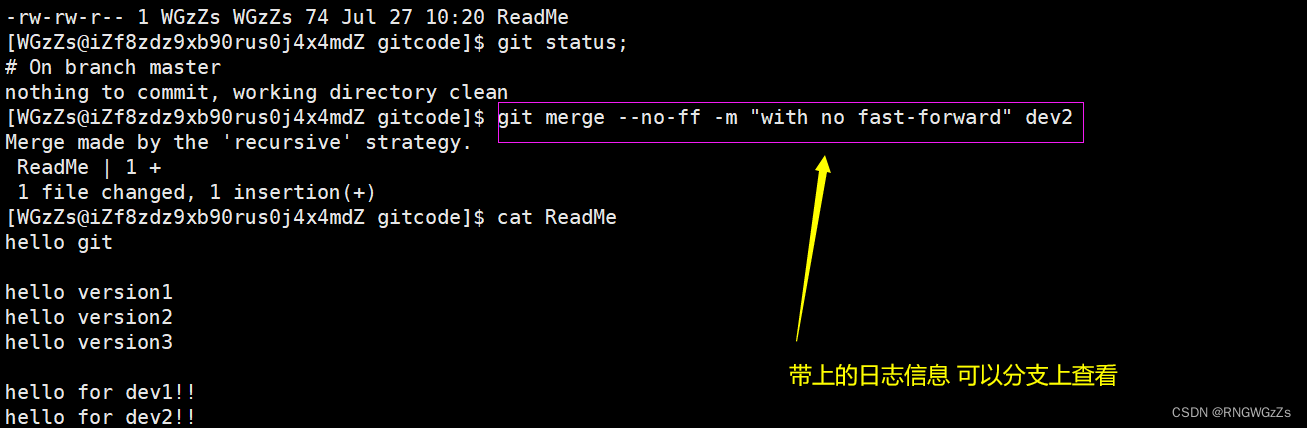
 可以看到,不使⽤ Fast forward 模式,merge后就像这样:
可以看到,不使⽤ Fast forward 模式,merge后就像这样: 
所以在合并分⽀时,加上”--no-ff“”参数就可以⽤普通模式合并,合并后的历史有分⽀,能看出来曾经做过合并,⽽ fast forward 合并就看不出来曾经做过合并。
分支策略:
在实际开发中,我们应该按照⼏个基本原则进⾏分⽀管理:
⾸先,master分⽀应该是⾮常稳定的,也就是仅⽤来发布新版本,平时不能在上⾯⼲活;
那在哪⼲活呢?⼲活都在dev分⽀上,也就是说,dev分⽀是不稳定的,到某个时候,再把dev分⽀合并到master上。
所以,一个团队合作的分⽀看起来就像这样:
(8) bug与临时分支
假设目前,你正处于dev2分支上进行开发,开发到一半时,突然发现master分支上存在严重的bug,需要被解决。在Git中,每个bug都可以通过⼀个 "新的临时分⽀" 来修复,修复后,合并分⽀,然后将临时分⽀删除。
场景一: 仅仅修改在工作区,没有提交:
# 可以将当前的⼯作区信息进⾏储藏,被储藏的内容可以在将来某个时间恢复出来
git stash
# 查看历史上 Git把stash内容存放记录
git stash list
# 恢复储存的内容,并且会在list中删除掉
git stash pop
# 恢复后,stash内容并不删除
git stash apply
# 删除 stash内容
git stash drop
使用git stash apply stash@{0},指定恢复内容
Git提供了”git stash”命令,可以将当前的⼯作区信息进⾏储藏,被储藏的内容可以在将来某个时间恢复出来。

因为bug出现在master分支上,所以我们得切换回master分支上新建立修复bug的分支。 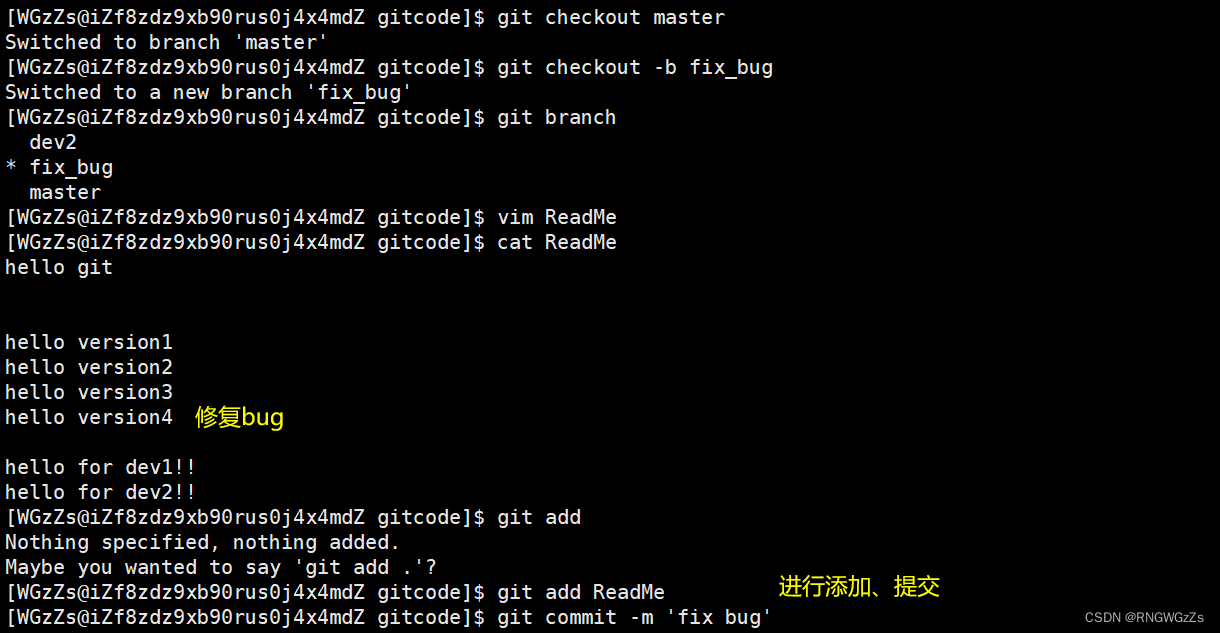
把fix_bug分支上修复的代码合并到master分支,最后并删除fix_bug分支:
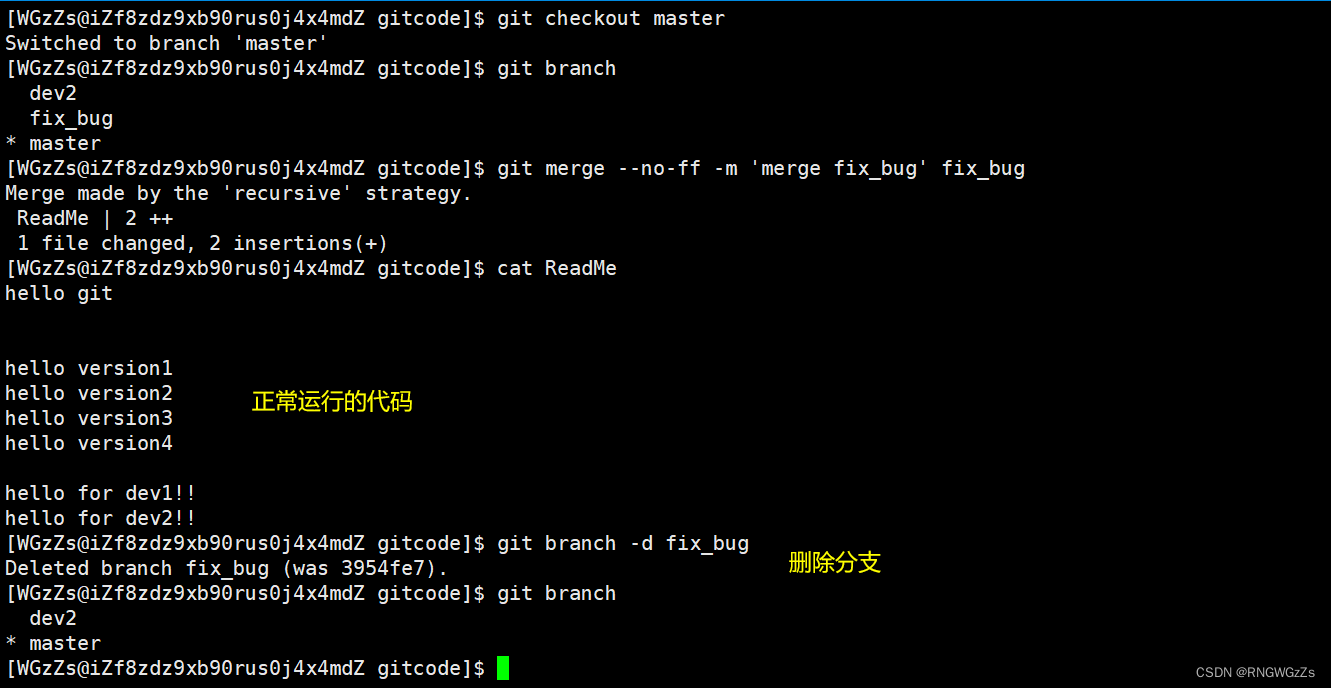
⾄此,bug的修复⼯作已经做完了,我们还要继续回到 dev2 分⽀进⾏开发,⼯作区是⼲净的,刚才的⼯作现场存到哪去了? 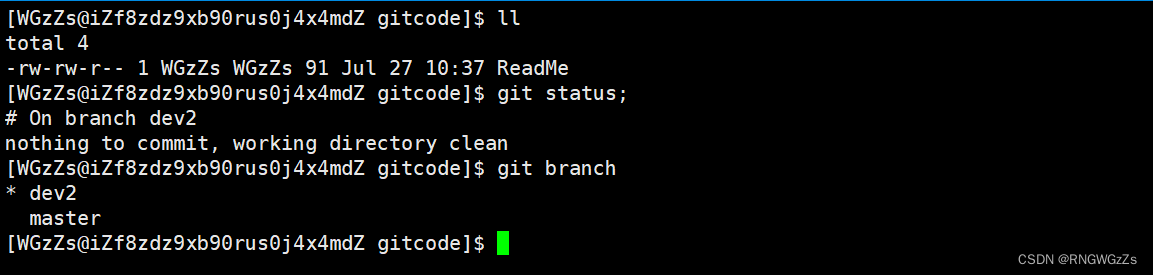
⽤ git stash list 命令查看:

⼯作现场还在,Git把stash内容存在某个地⽅了,但是需要恢复⼀下,如何恢复现场呢?我们可以使⽤ git stash pop 命令,恢复的同时会把stash也删了。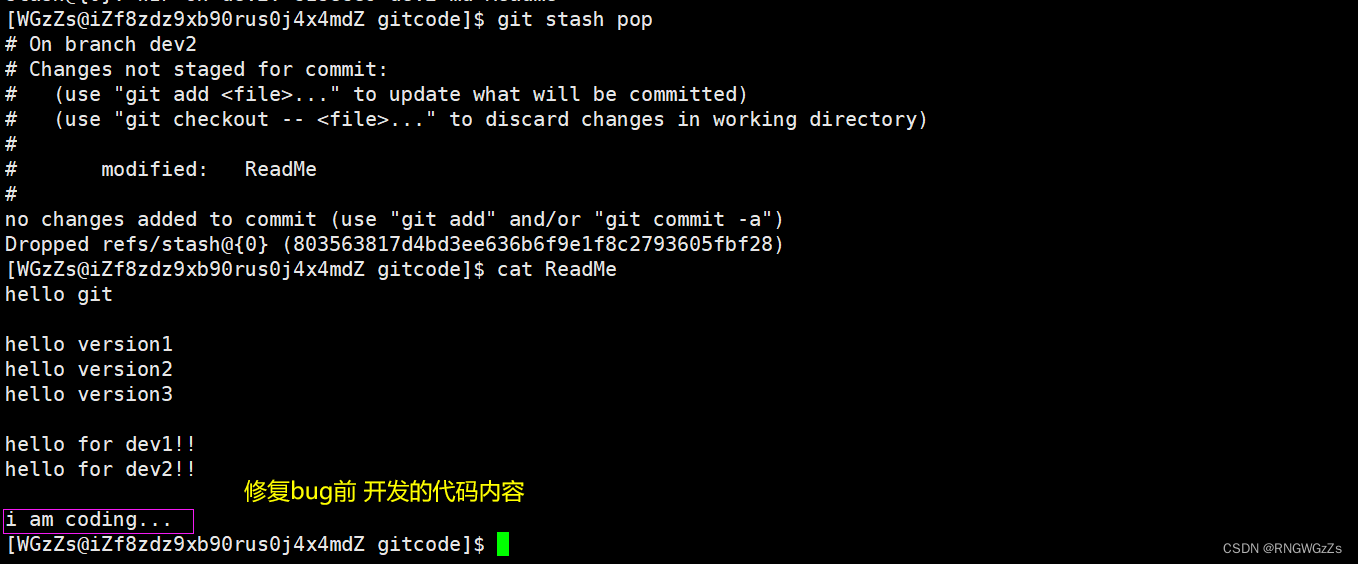
恢复完成后,我们就可以继续开发代码,到后面又添加、提交:

不过呢,我们也可以看到,在dev2查看ReadMe文件时,是看不到修复好bug的新文件是什么,此时的状态图该为:

Master 分⽀⽬前最新的提交,是要领先于新建 dev2 时基于的 master 分⽀的提交的,所以我们在 dev2 中当然看不⻅修复bug的相关代码。而我们最终的目的是让master分支合并到dev2分支上去,于是乎,正常情况下我们现在是会,切回 master 分⽀直接合并即可。
但这样其实是有⼀定⻛险的,因为在合并分⽀时可能会有冲突,⽽代码冲突需要我们⼿动解决(手动解决)。可是现在解决代码冲突的问题是回到了master分支上,并且我们无法保证一次性就能解决掉冲突内容,面对实际中的几百行、甚至几千行代码时,解决的过程中难免⼿误出错,导致错误的代码被合并到 master上。
⼀个好的建议就是:在⾃⼰的分⽀上合并下"master",再让"master"去合并"dev"。这样做的⽬的是有冲突可以在本地分⽀解决并进⾏测试,⽽不影响master。

 我们可以查看一下日志信息:
我们可以查看一下日志信息:

上述的日志信息可以转化为以下两步:

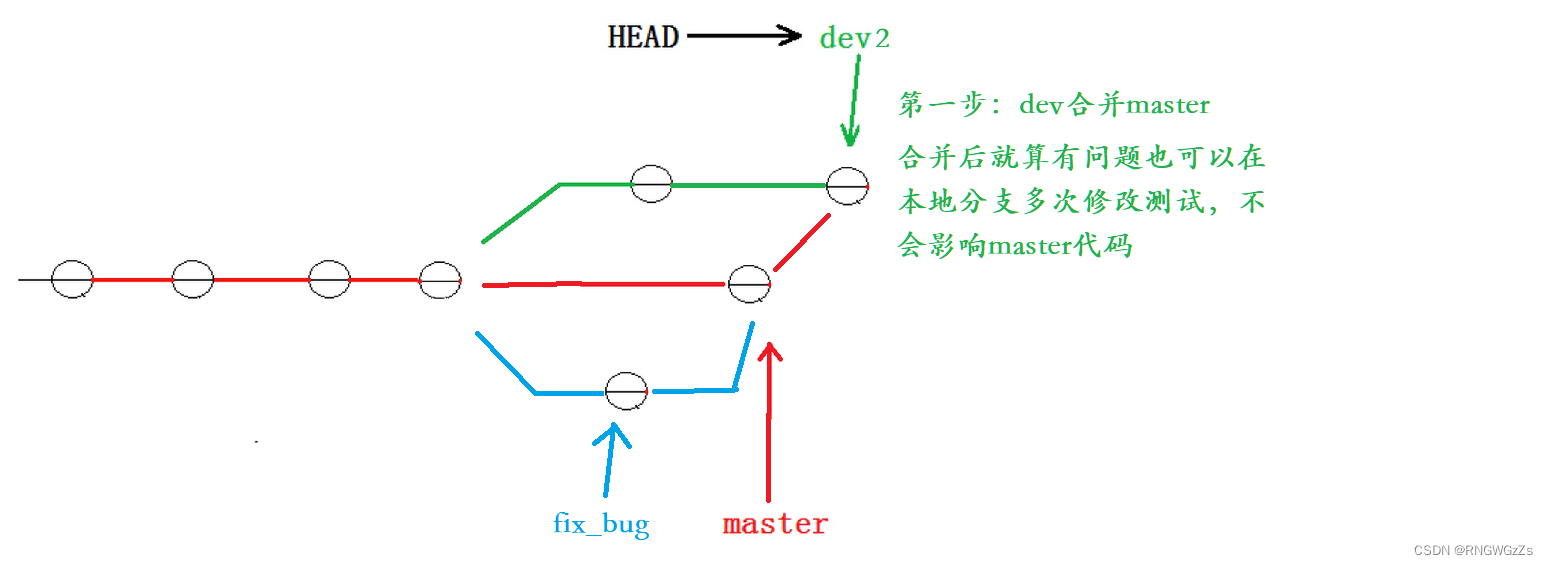

删除临时分支:
# 删除还未合并的分支
git branch -D [branc_name]软件开发中,总有⽆穷⽆尽的新的功能要不断添加进来。
添加⼀个新功能时,你肯定不希望因为⼀些实验性质的代码,把主分⽀搞乱了,所以,每添加⼀个新功能,最好新建⼀个分⽀,我们可以将其称之为"feature"分⽀,在上⾯开发,完成后,合并,最后,删除该"feature"分⽀
但,天有不测风云,常在河边走哪有不湿鞋的。你亲爱的产品经理告诉你,某个已经开发到一半的"feature"分支功能叫停了,虽然你的辛苦白费了,但是这个 feature分支理应要被删除的、销毁的。这时使⽤传统的 git branch -d 命令删除分⽀的⽅法是不⾏的。 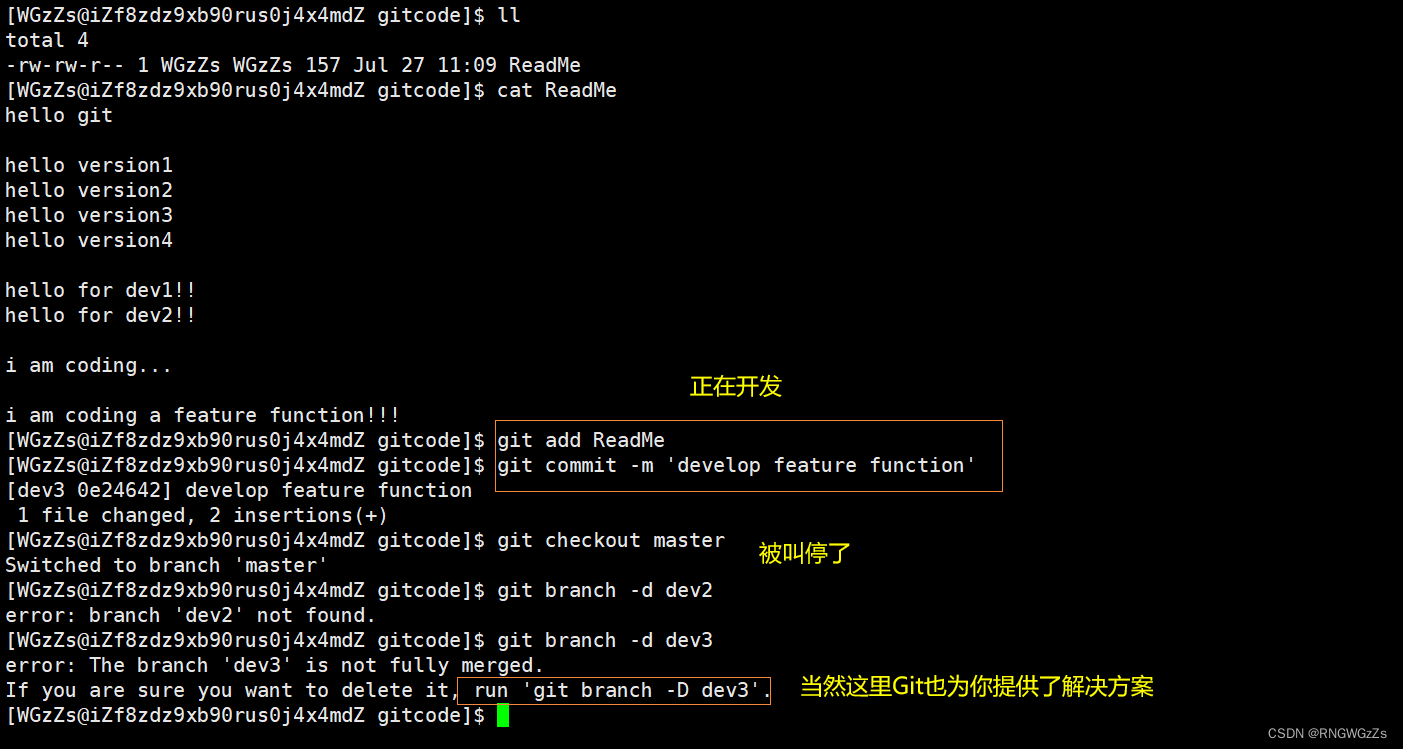
复制粘贴即可。
小结一下:
所以分支到底有什么用呢?假设你准备开发⼀个新功能,但是你还没有完全开发完成,如果⽴刻提交,由于代码还没写完,不完整的代码库会导致别⼈不能⼲活了。如果等代码全部写完再⼀次提交,⼜存在丢失每天进度的巨⼤⻛险。
现在有了分⽀,就不⽤怕了。你创建了⼀个属于你⾃⼰的分⽀,别⼈看不到,还继续在原来的分⽀上正常⼯作,⽽你在⾃⼰的分⽀上⼲活,想提交就提交,直到开发完毕后,再⼀次性合并到原来的分⽀上,这样,既安全,⼜不影响别⼈⼯作。
并且Git提供高效的分支创建、切换和删除,帮助我们提高开发效率。
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~