1. 导包:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
import numpy as np
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
from sklearn.metrics import precision_score, recall_score, f1_score2. 导入数据:
# 导入数据
file = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data',
header=None)
df=file
# 提取DataFrame中所有行的第2列及之后所有列的操作,将其转换为一个NumPy数组
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y) # 类标整数化df是一个DataFrame对象,loc是用于按标签选择数据的方法。[:, 2:]表示选择所有行(冒号表示
所有行)和从第2列到最后一列的所有列。values将所选数据转换为NumPy数组。
LabelEncoder()是scikit-learn库中的一个类,用于标签编码。它将一组文本或分类标签转换为从0
开始的连续整数值。fit_transform()方法将原始的标签y进行拟合和转换。拟合操作会根据数据中
出现的标签自动构建编码映射关系。转换操作将原始标签转换为对应的编码值。最终,变量y将包
含编码后的标签值。fit_transform()方法同时执行了拟合和转换操作。如果你只需要进行转换,
可以使用transform()方法。另外,LabelEncoder()适用于单个列的标签编码。如果你的数据有多
个列,你可能需要考虑使用OneHotEncoder()或其他编码方法来处理分类特征。
LabelEncoder()类的示例代码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 假设有一个标签列表
labels = ['cat', 'dog', 'cat', 'bird', 'dog']
# 使用LabelEncoder进行标签编码
encoded_labels = le.fit_transform(labels)
print(encoded_labels)
# [0 1 0 2 1]
3. 划分训练集合测试集
# 划分训练集合测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
# 建立pipeline
pipe_svc = Pipeline([('scl', StandardScaler()), ('clf', SVC(random_state=1))])
pipe_svc.fit(X_train, y_train)
y_pred = pipe_svc.predict(X_test)train_test_split是scikit-learn库中的一个函数,用于将数据集划分为训练集和测试集。它可以根
据指定的比例或样本数量,在保持数据分布的同时随机划分数据。
在代码中,X是特征数据集,y是对应的标签数据集。test_size=0.20表示将数据划分为80%的训练
集和20%的测试集。random_state=1用于设置随机种子,以确保每次运行时划分结果一致。
划分结果将分别存储在X_train、X_test、y_train和y_test这四个变量中,分别表示训练集的特
征、测试集的特征、训练集的标签和测试集的标签。
Pipeline函数是scikit-learn库中的一个类,用于创建一个管道(Pipeline)对象,将多个数据处理
步骤组合在一起。管道对象可以方便地将多个数据预处理和模型训练步骤组织成一个整体,简化了
机器学习流程的编码和管理。它具有以下几个作用:
①数据流水线:管道可以将多个数据处理步骤按顺序组合起来,形成一个数据流水线。每个步骤都
可以是一个数据预处理操作,如特征缩放、特征选择、特征提取等。
②参数共享:通过管道,可以在每个步骤中共享参数。例如,可以在数据标准化和模型训练步骤中
共享相同的参数设置,避免手动调整多个步骤的参数。
③代码简化:使用管道可以将多个处理步骤整合到一个对象中,简化了代码的编写和维护。通过调
用管道对象的方法,可以一次性完成整个流程,而不需要分别调用每个步骤。
⑤模型持久化:将整个流水线作为一个模型对象进行持久化保存。可以将整个管道保存到磁盘上,
方便后续的部署和使用。
在代码中,管道的第一个步骤是StandardScaler(),"scl" 是指对数据进行缩放的预处理步骤。
"StandardScaler" 是一个用来对数据进行标准化的预处理器,它将数据的每个特征按照一定的方式
进行缩放,使得数据符合均值为0,方差为1的标准正态分布。这个步骤的目的是通过数据的标准
化,提高模型的训练效果。
管道的第二个步骤是SVC(random_state=1),即支持向量机分类器。这里使用了默认参数,
random_state=1是为了设置随机种子,以确保每次运行时的结果一致。"clf"代表分类器
(classifier)的意思。通过调用clf来访问该分类器的功能和属性。
pipe_svc.fit(X_train, y_train)调用管道对象的fit方法,使用训练集X_train和对应的标签
y_train对模型进行训练。接下来,使用训练好的模型对测试集X_test进行预测,得到预测结果
y_pred。这里的测试集特征数据也会经过与训练集相同的标准化处理。
4. 混淆矩阵、召回率、精确率、F1度量
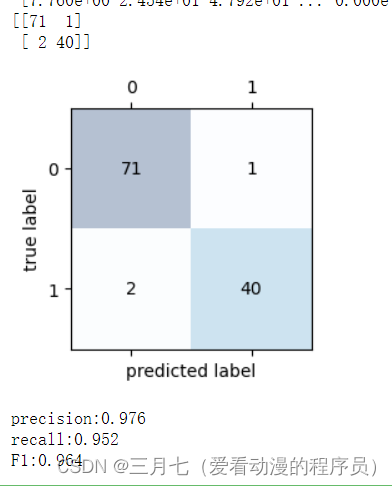
# 混淆矩阵并可视化
confmat = confusion_matrix(y_true=y_test, y_pred=y_pred) # 输出混淆矩阵
print(confmat)
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j, y=i, s=confmat[i, j], va='center', ha='center')
plt.xlabel('predicted label')
plt.ylabel('true label')
plt.show()
# 召回率、准确率、F1
print('precision:%.3f' % precision_score(y_true=y_test, y_pred=y_pred))
print('recall:%.3f' % recall_score(y_true=y_test, y_pred=y_pred))
print('F1:%.3f' % f1_score(y_true=y_test, y_pred=y_pred))confusion_matrix是scikit-learn库中的一个函数,用于计算分类模型在测试集上的混淆矩阵.
在代码中,y_true参数表示真实的标签值,y_pred参数表示模型预测的标签值。通常,真实的标签
值是测试集的真实标签,而预测的标签值是模型在测试集上的预测结果。
通过plt.subplots(figsize=(2.5, 2.5))创建一个图表对象,指定了图表的大小为2.5x2.5英寸,
使用ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)在图表上绘制混淆矩阵。
cmap=plt.cm.Blues指定了使用蓝色调色板进行颜色映射,alpha=0.3设置了绘图的透明度。
通过使用两个嵌套的循环遍历混淆矩阵的每个元素,然后使用ax.text()函数在对应的位置添加文
本标签。x=j和y=i设置了文本标签的位置,s=confmat[i, j]设置了文本标签的内容,即混淆矩阵
的对应元素值。va='center'和ha='center'表示文本标签在单元格中居中显示。
5. 运行结果