1. 输入字符串s,按要求把s输出到屏幕,格式要求:宽度为30个字符,星号字符*填充,居中对齐。如果输入字符串超过30位,则全部输出。
例如:键盘输入字符串s为"Congratulations”,屏幕输出 ∗ ∗ ∗ ∗ ∗ ∗ ∗ C o n g r a t u l a t i o n s ∗ ∗ ∗ ∗ ∗ ∗ ∗ *******Congratulations******* ∗∗∗∗∗∗∗Congratulations∗∗∗∗∗∗∗
s = input('请输入一个字符串:')
print('{:*^30}'.format(s))
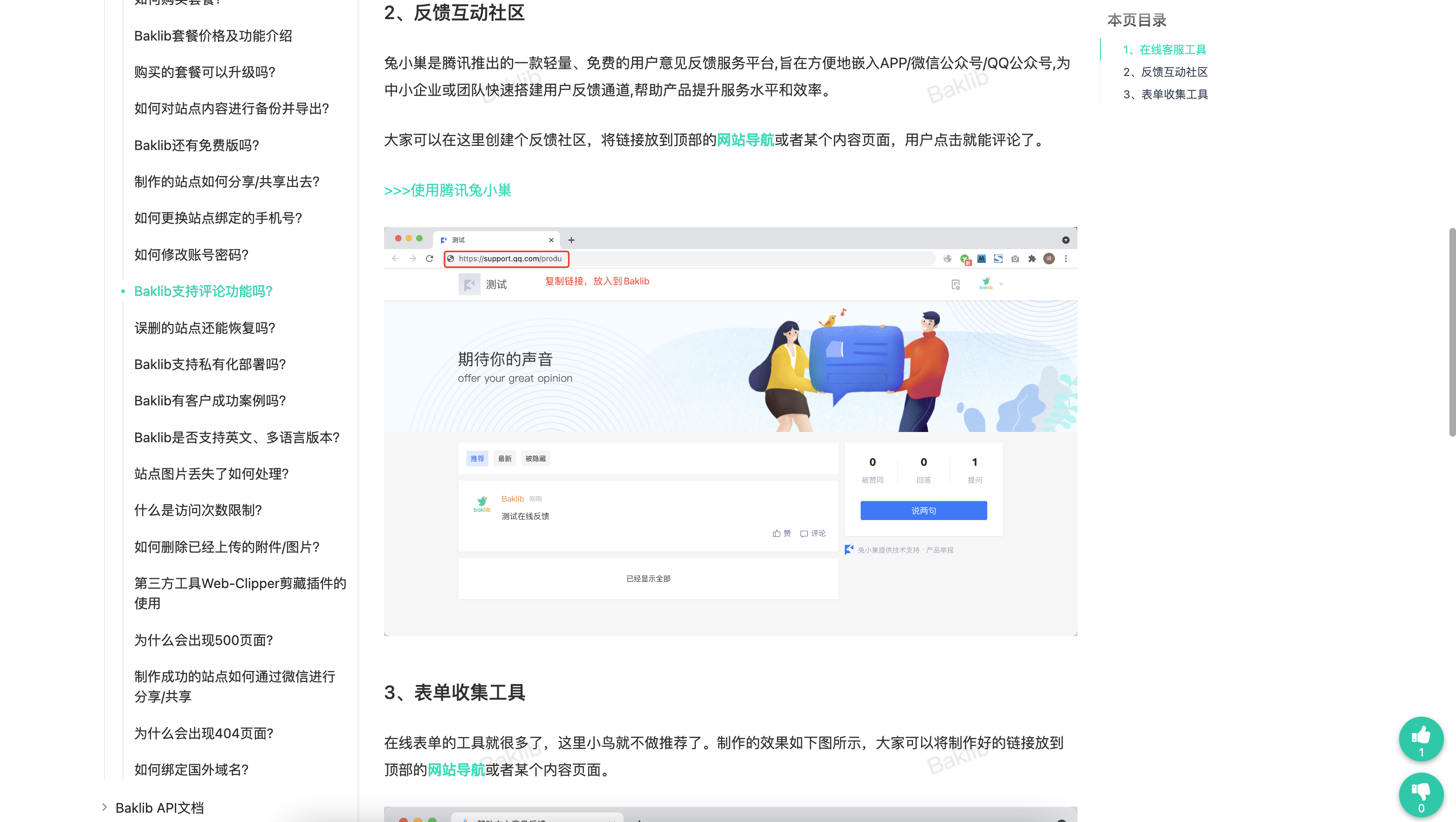
| 引导符号 | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| : | * | ^ (居中对齐) | 30 | - | - | - |
2. 随机选择一个手机品牌屏幕输出
import random
branlist = ['三星','苹果','vivo','OPPO','魅族']
random.seed()
name = brandlist[random.randint(0,4)]
print(name)
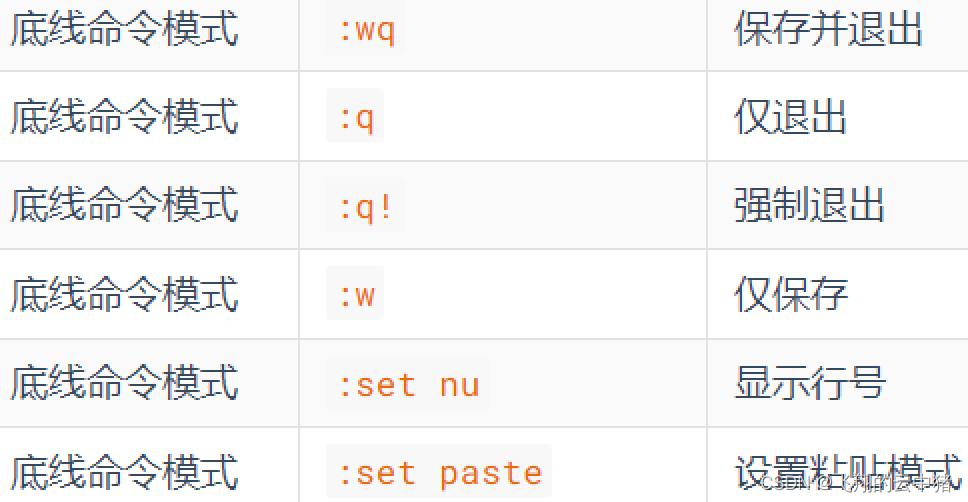
random():随机生成下一个实数,它在[0,1)范围内。
seed():改变随机数生成器的种子seed.
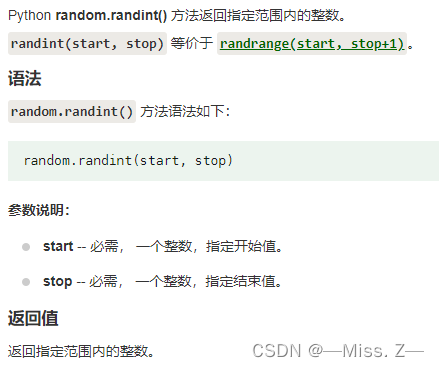
randint():返回指定范围内的整数
3. 键盘输入正整数n,按要求把n输出到屏幕,格式要求:宽度为30个字符,艾特字符@填充,右对齐,带千位分隔符。如果输入正整数超过30位,则按照真实长度输出。
例如:键盘输入正整数n位5201314,屏幕输出@@@@@@@@@@@@@@@@@@@@@5,201,314
n=eval(input("请输入正整数:"))
print("{0:@>30,}".format(n))
| 引导符号 | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| : | @ | > (右对齐) | 30 | , | - | - |
用法:{0:}
描述:冒号后面可以跟对变量的一些格式用法,而在冒号前面则跟对应数字,如果数字是0,那么该{}对应于.format()括号里面第一个变量;以此类推,数字是1,则对应于第二个变量。
# 第一个例子
name = 'zh'
age = 18
print('我叫{1:}, 我{0:.1f}岁了.重要的事情说三遍,我{0:}岁了,我的名字是{1:}'.format(age, name))
# 输出:我叫zh, 我18.0岁了.重要的事情说三遍,我18岁了,我的名字是zh
# 第二个例子
num = 425
print("对应的二进制数:{0:b}\n八进制数:{0:o}\n十六进制数:{0:x}".format(num))
#输出:
#对应的二进制数:110101001
#八进制数:651
#十六进制数:1a9
# 现在format()括号里面不需要传入三个相同的变量num,一个变量就直接搞定。
当有多个变量时,:前一定要有数字,单个变量一般省略0不写
4. 从键盘输入4个数字,各数字采用空格分隔,对应为变量x0,x1,y0,y1。计算两点(x0,y0)和(x1,y1)之间的距离,屏幕输出这个距离,保留1位小数。
例如:屏幕输入:3 4 8 0 屏幕输出:6.4
ntxt = input("请输入4个数字(空格分隔):")
nls = ntxt.split('')
x0 = eval(nls[0])
y0 = eval(nls[1])
x1 = eval(nls[2])
y1 = eval(nls[3])
r = pow(pow(x1-x0, 2) + pow(y1-y0, 2), 0.5)
print("{:.1f}".format(r))
split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
pow():计算并返回x的y次方的值
| 引导符号 | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| : | - | - | - | - | .1(保留1位小数) | f |
5. 从键盘输入一个1~26之间的数字,对应于英文字母表中的索引,在屏幕上显示输出对应的英文字母。
例如:请输入一个数字:1
输出大写字母:A
s = eval(input("请输入一个数字:"))
ls = [0]
for i in range(65,91): #十进制65~90为大写字母;十进制97~122为小写字母
ls.append(chr(i))
print("输出大写字母:{}".format(ls[s]))
eval(str):用来计算在字符串中的有效Python表达式,并返回一个对象
chr(x):将一个整数转换为一个字符
list.append(obj):在列表末尾添加新的对象
6. 将字符串中每个单词的首字母都变成大写
例如:After Fresh Rain In Mountains Bare
line = "After fresh rain in mountains bare"
print(line.title())
title():返回“标题化”的字符串,就是说所有单词都是以大写开始
7. 请将列表lis内的重复元素删除,并输出。
例如:若列表为[2,8,3,6,5,3,8],输出为[2, 3, 5, 6, 8]。
lis = [2,8,3,6,5,3,8]
new_lis = list(set(lis))
print(new_lis)
set(s):转换为可变集合
集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素
list(s):将序列 s 转换为一个列表
8. 列表中有四个元素,将其倒序输出
animals = ['cow','duck','cat','dog']
animals.reverse()
print(animals)
reverse():倒序输出列表中的元素
9.循环获得用户输入,直到用户输入Y或者y字符退出程序
while True:
s = input("请输入信息:")
if s == "y" or s == "Y":
break

10. 获取用户输入的一组数字,采用逗号分隔输入,输出其中的最大值
示例:
请输入一组数据,以逗号分隔:8,78,54,520,21,34
520
data = eval(input("请输入一组数据,以逗号分隔:"))
print(max(data))
总结
format()格式化
format是字符串内嵌的一个方法,用于格式化字符串。以大括号{}来标明被替换的字符串。
它通过{}和:来代替特殊字符%。
语法:{<参数序号>:<格式控制标记>}
使用方法有两种:b.format(a)和format(a,b)。
基本用法:
- 按照{}的顺序依次匹配括号中的值
s = "{} is a {}".format('Tom', 'Boy')
print(s) # Tom is a Boy
- 通过索引的方式去匹配参数
s1 = "{1} is a {2}".format('Tom', 'Lily', 'Girl')
print(s1) # Lily is a Girl
# 字符串中索引的顺序可以打乱,并不影响匹配。
s = "{1} is a {0}".format('Boy', 'Tom', )
print(s) # Tom is a Boy
- 通过参数名来匹配参数
s = "{name} is a {sex}".format(name='Tom', sex='Boy')
print(s) # Tom is a Boy
# 同理,如果参数已经确定,可以直接利用{}进行格式化引用。
name = 'Tom'
sex = 'Girl'
s = f"{name} is a {sex}" # 以f开头表示在字符串中支持大括号内的python表达式 此用法3.6之后支持
print(s) # Tom is a Boy
- 混搭使用
可以通过索引,参数名来混搭进行匹配。
s = "My name is {}, I am {age} years old, her name is {}".format('Liming', 'Lily', age=10)
print(s) # My name is Liming, I am 10 years old, her name is Lily
!注意:
①命名参数必须写道最后,否则会编译报错!
s = "My name is {}, i am {age} year old, She name is {}".format('Liming', age=10, 'Lily')
print(s) #SyntaxError: positional argument follows keyword argument
②不可以索引和默认格式化混合使用。
s = "{} is a {0}".format('Boy', 'Tom', )
print(s) # ValueError: cannot switch from automatic field numbering to manual field specification==
format()方法的槽除了包含参数序号,还可以包括格式控制信息
| 引导符号 | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| : | 用于填充的单个字符 | < 左对齐 > 右对齐 ^ 居中对齐 | 槽的设定输出宽度 | 数字的千分位分隔符,适用于整数和浮点数 | 浮点数小数部分的精度或字符串的最大输出长度 | 整数类型b,c,d,o,x,X 浮点数类型e,E,f,% |
内置函数
chr()

eval()

title()

random()

seed()

radint()
split()

pow()
pow()函数是Python的内置函数,它计算并返回x的y次方的值。
语法:pow(x, y, z)
- x:底数(不可省略的参数)
- y:指数(不可省略的参数)
- z:取余数字(可省略的参数)。当z存在时,函数返回值等于 pow(x, y)%z
!注意:
- z参数省略时,返回值是x的y次方
- z参数省略时,x和y的值可以是整数和浮点数
当x或y存在浮点数时,pow()函数的返回结果也是浮点数,否则为整数。 - 参数z不能为0
- 参数z存在时,x和y只能是整数
set()

list()

reverse()

列表去重的三种方法
- 利用集合去重(列表 -> 集合 -> 集合)
lis = [2,8,3,6,5,3,8]
new_lis = list(set(lis))
print(new_lis) # new_list = [2,8,3,6,5]
- 新建一个空列表,使用append()加入未重复元素
lis = [2,8,3,6,5,3,8]
lis1 = []
for data in lis: #循环取值
if data not in lis1: #判断数值在新列表中是否已存在
lis1.append(data)
print(lis1)
- 使用列表推导式
lis = [2,8,3,6,5,3,8]
lis1 = []
[lis1.append(data) for data in lis if data not in lis1]
print(lis1)#[1, 2, 3, 4, 5]