这里写目录标题
- 前言
- 方法
- 1 基于CNN的方法
- Slow-fast:
- 2 基于Vision-Transformer的方法
- Video TimeSformer :
- Video Swin Transformer :
- 3、基于自监督的方法
- VideoMAE:
- 4、基于多模态的方法
- Intern video:
前言
常用行为识别数据集包括:HMDB-51、UCF101、AVA、Kinetics等…
主流前沿的行为识别算法主要包括四类:第一类是基于 CNN 的算法,是比较经典的算法,在落地应用场景中很常见;第二类是基于 vision transformer 的算法,这是最近两年比较火的一类方法;第三类是基于自监督的方法;第四类是基于多模态大模型的方法。
为更好比较现有SOTA算法的检测性能,本博客将针对以上四类算法中表现较优模型进行介绍。
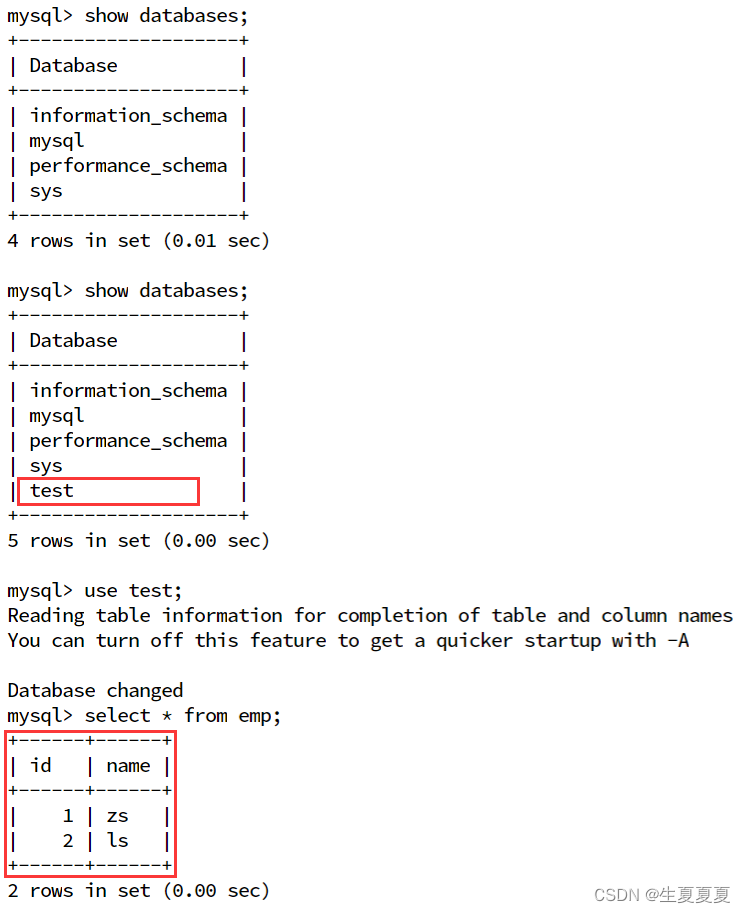
| 类型 | 算法模型 | 年份 | 代码 |
|---|---|---|---|
| 基于CNN | SlowFast Networks for Video Recognition | 2021 | https://github.com/facebookresearch/SlowFast |
| 基于transformer | Video TimeSformer | 2022 | https://github.com/facebookresearch/TimeSformer |
| 基于transformer | Video Swin Transformer | 2022 | https://github.com/SwinTransformer/Video-Swin-Transformer |
| 基于自监督 | VideoMAE | 2022 | https://github.com/MCG-NJU/VideoMAE |
| 基于多模态 | Intern Video | 2021 | https://github.com/opengvlab/internvideo |
方法
1 基于CNN的方法
Slow-fast:
arxiv.org/pdf/1812.03982v3.pdf
模型结构:
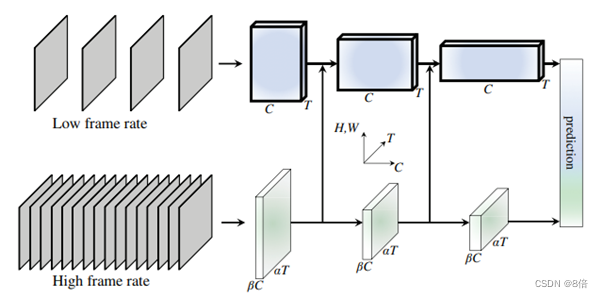
Slow-fast为以两种不同帧率运行的单一流结构,其中:(1)Slow路径,以低帧率运行,用于捕捉由图像或稀疏帧提供的空间语义信息;(2)Fast路径,以高帧率运行,以较好的时间分辨率捕捉快速变化的运动。两条路径齐头并进、相辅相成,能够对行为识别产生很好的检测效果。
算法流程:
1、输入视频流同时进入Slow、Fast路径。
2、Slow路径(2D/3D卷积)按照t的大时间步幅设置,对输入视频提取图像空间特征。(无单独时间下采样层)
3、Fast路径(2D/3D卷积)按照T=t/α的小时间步幅设置,对输入视频提取特征。(无单独时间下采样层)
4、在每个阶段的两个通路之间附加“横向单向连接”,包括:通道时间转换、时间跨越采样、时间步长卷积,将Fast路径的特征融合到Slow路径中。
5、对每个路径的输出进行全局平均池化,并连接池化后的特征向量,输入全连接分类器,实现动作分类。
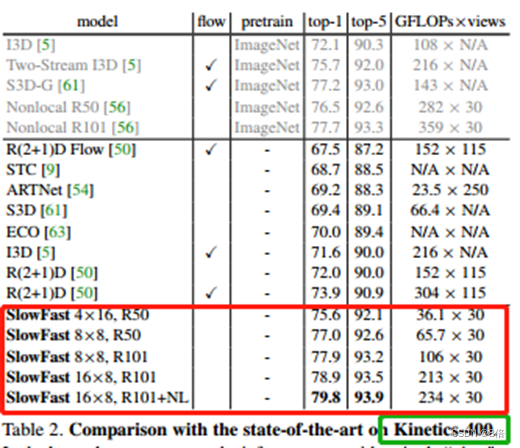
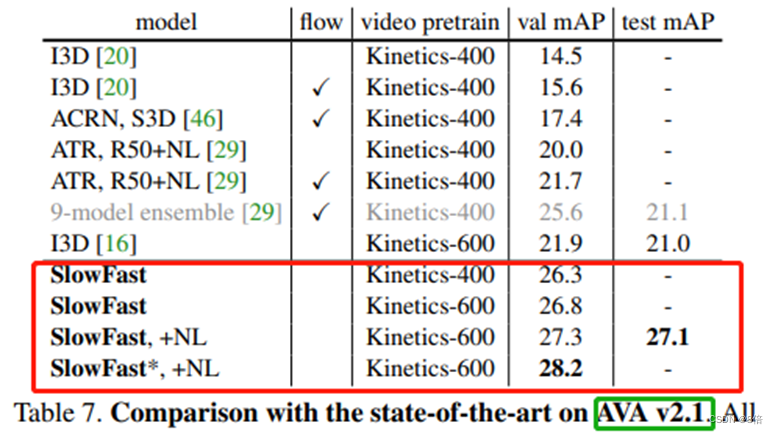
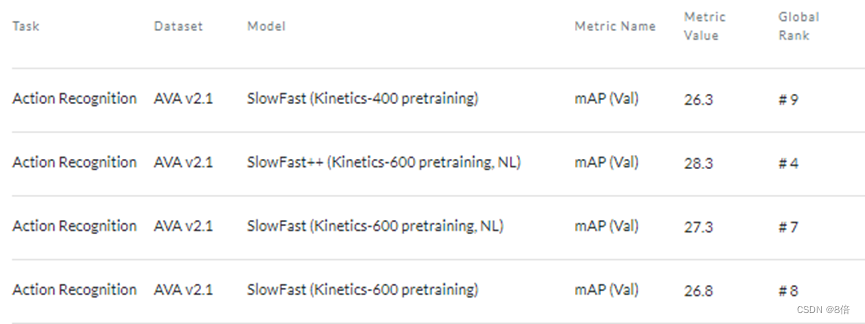
算法性能:
在无任何预训练情况下。
算法总结:
1、Slow-Fast提出了一种新的检测结构,能够以慢速帧频和快速帧频提取视频中的有效信息。
2、Slow-Fast 的整体计算复杂度低,但准确度很高。在 CVPR 2019 上的 AVA 视频检测挑战赛中排名第一
3、实际运用时可配合不同的Backbone进行特征提取
2 基于Vision-Transformer的方法
当前视频行为识别的SOTA模型,都是基于Vision-Transformer的方法。
Video TimeSformer :
arxiv.org/pdf/2102.05095v4.pdf
在vision transformer的基础上,在时间维度进行了attention,将图像分类拓展到了视频分类。
模型结构:
模型由三部分组成,主要是模型输入、attention模块、分类器。
算法流程:
1、从视频片段中等分抽取F帧图像打包为一个序列作为模型的输入。(比如一个2s,fps为24的视频片段,当F = 8时,就取[ 0 , 6 , 12 , 18 , 24 , 30 , 36 , 42 ]这几帧作为一个序列来输入)。
2、将序列中每一帧图像进行resize、crop和Patch切割,同时在序列始端加入可学习变量z,用于最后分类。将处理后序列通过position embedding层,输出基础特征。
3、attention模块采用时间注意力与空间注意力分开的attention方式,对所得到的基础特征进行增强。
4、将可学习变量z增强后的对应输出送入分类器,实现视频行为分类。
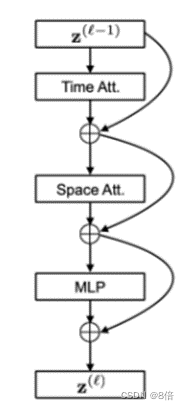
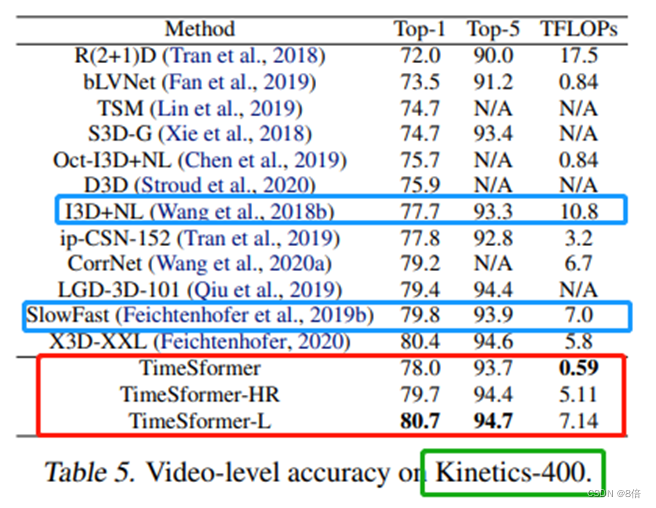
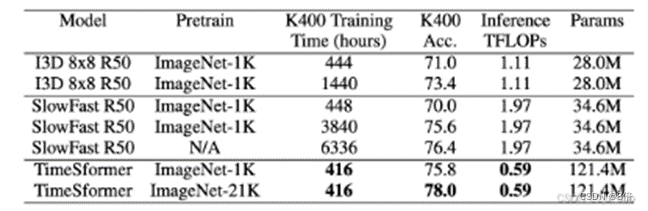
算法性能:
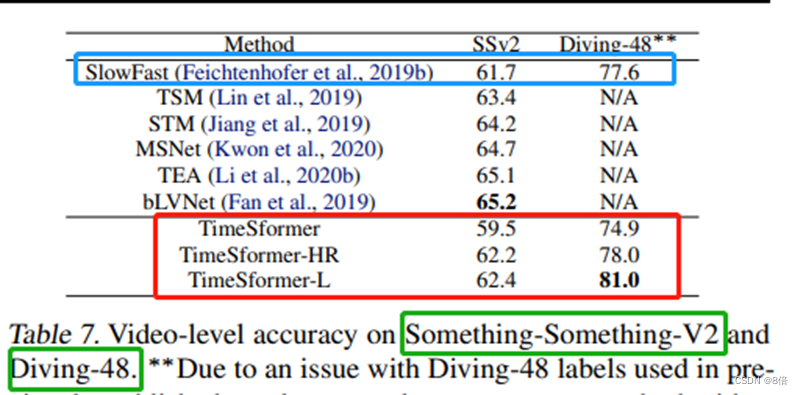
算法总结:
1、虽然TimeSformer相比CNN方法参数量远大于其他模型,但需要的训练时间更少,准确率也更高。
2、在更大的数据集上进行pretrain后,模型的效果会变得更好。
Video Swin Transformer :
原文
Video Swin Transformer是基于Swin Transformer应用在视频领域的升级版本,其模型结构与Swin Transformer基本一致,只是多了一个时间的维度,做attention和构建window的时候略有区别。
模型结构:
模型由两部分组成,主要是backbone、head。
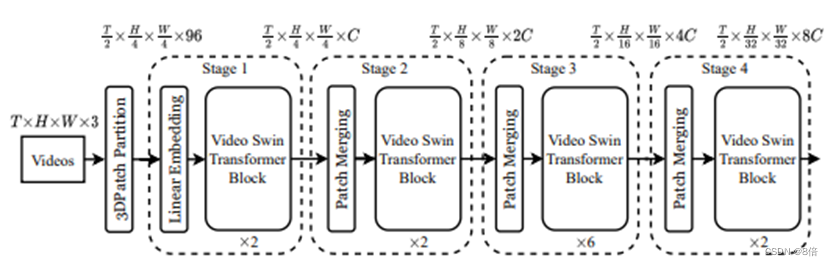
算法流程:
1、对输入视频进行采样得到T帧(一般为等间隔采样)
2、输入送进添加了时间维度patch size的Patch Partition,然后进入Linear Embedding模块(3D-Conv),实现特征提取。
3、输出经过多个video swin transformer block和patch merging。其中video swin transformer将对同一个window内的特征通过attention进行特征融合,patch merging则是用来改变特征的shape。
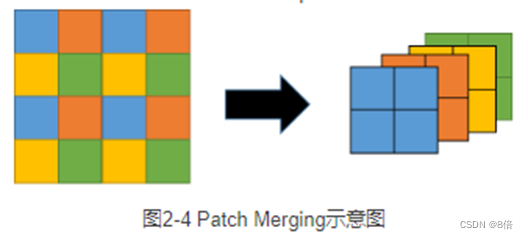
4、最后通过Head(即一层FC)对输入视频进行分类。
算法性能:
模型介绍了四个不同版本的Video Swin Transformer,这些模型变体的体系结构超参数如下:

作者在三个数据集上进行了测试,分别是kinetics-400,kinetics-600和something-something v2,每个数据集上都有着state-of-art的表现。
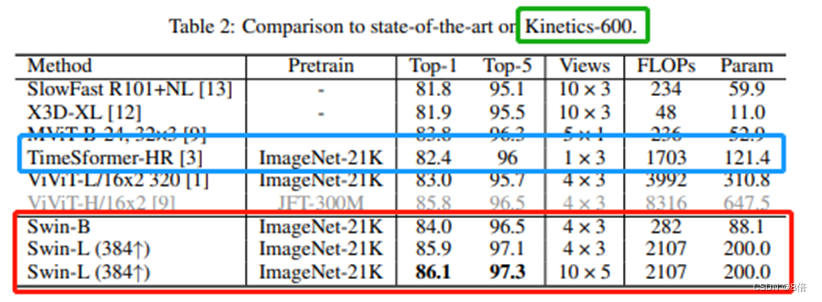
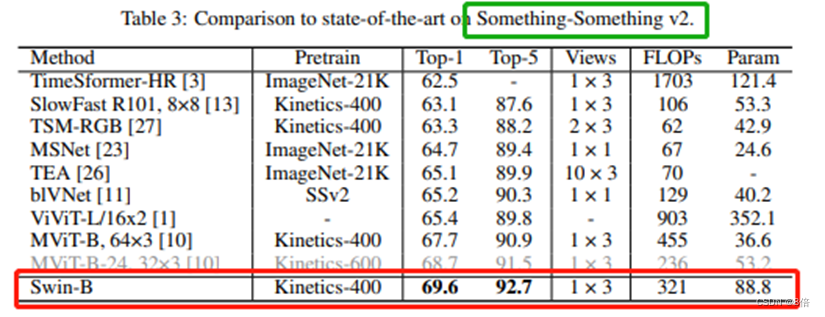
算法总结:
1、采样输入过程限制了模型处理和训练数据时长相差太多的视频。通常视频分类任务的视频会在10s左右,太长的视频很难分到一个类里。
2、算法原理较简单,基本与Swin transformer差异不大。只是将分割的方式是从 2D扩展到了3D帧。
3、基于自监督的方法
当前直接基于视频分类的方法,其性能已经达到上限。使用自监督的方法,可以继续提升视频分类的性能。
VideoMAE:
原文
VideoMAE是MAE模型(图像领域特征学习效果很好的模型)对时空数据的简单扩展。MAE主要思想是:掩去一部分图像块,用剩余的图像块去恢复整幅图。包含一个encoder和一个decoder,encoder在训练完成之后,可以作为图像特征提取的模型。
受到ImageMAE的启发,作者提出定制视频数据的掩蔽和重建。
模型结构:
VideoMAE: 由三个核心组件组成:cube embedding、encoder(VIT)和decoder
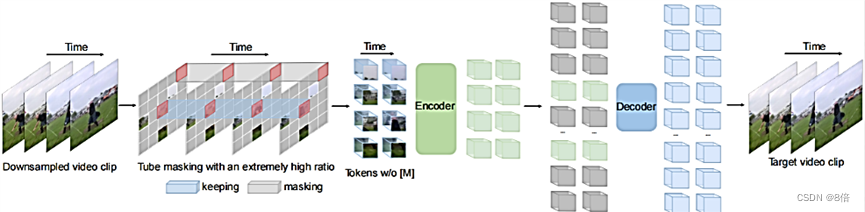
算法流程:
1、从原始视频中随机采样一个由t个连续帧组成的视频片段,然后使用带有时序间隔采样将视频片段压缩为T帧。
2、对采样得到的视频片段,通过cube embedding进行像素块嵌入,以减小输入数据的时空维度大小,缓解视频数据的时空冗余性。
3、进行tube mask掩码,掩码后未被掩蔽的token送入Encoder中。
4、encoder通过原始ViT结合时空联合自注意力机制,对输入token进行特征提取。
5、最后通过decoder恢复图像。
算法性能:
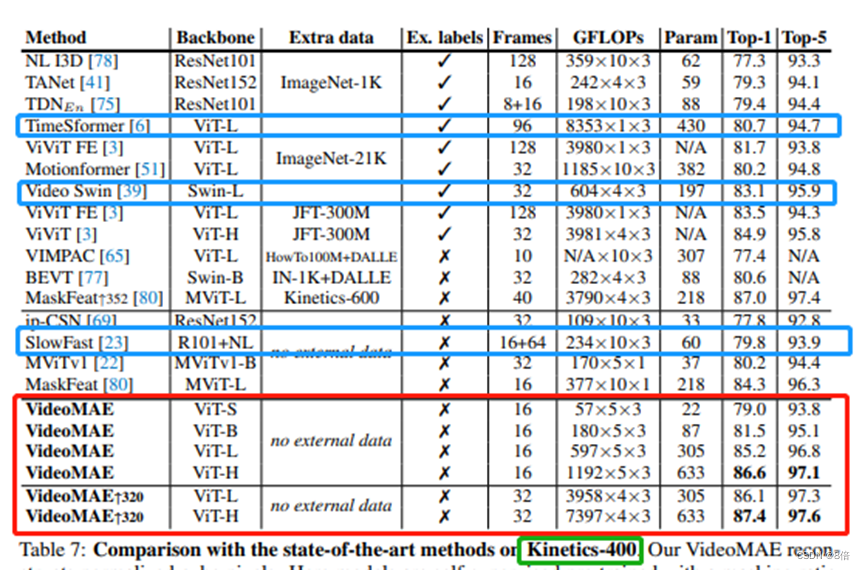
算法总结:
1、采用一种自监督的预训练方法,以掩蔽自编码器为基础,提出了一种对于视频的自监督预训练范式。
2、证明了管道式掩码方法的效果要优于随机式掩码,能够减少重建过程中的信息泄漏风险。
3、实验非常耗时,需要大量的显卡。
4、基于多模态的方法
Intern video:
原文
模型结构:
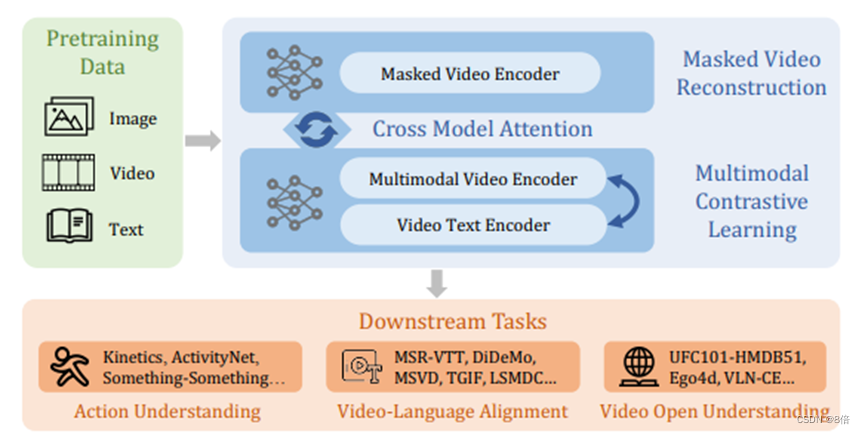
算法流程:
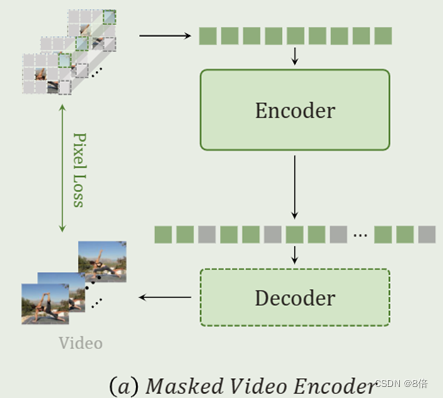
1、遵循VideoMAE的训练方式,使用一个普通的ViT结合联合时空注意机制对视频的时空信息进行建模。
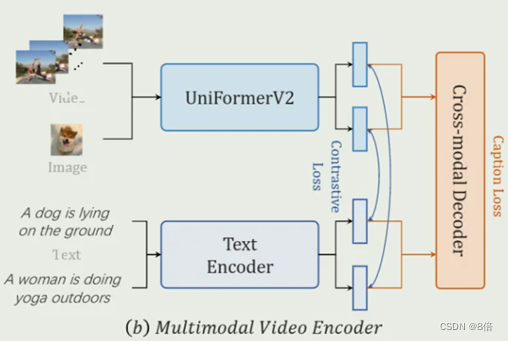
2、同时对视频/图像、文本对比学习和视频字幕任务模型进行预训练。首先,使用基于预训练的CLIP初始化构建多模态结构。使用UniformerV2作为视频编码器,以实现更好、更有效的时间建模。此外,再联合一个额外的Transformer Encoder来实现跨模态学习。
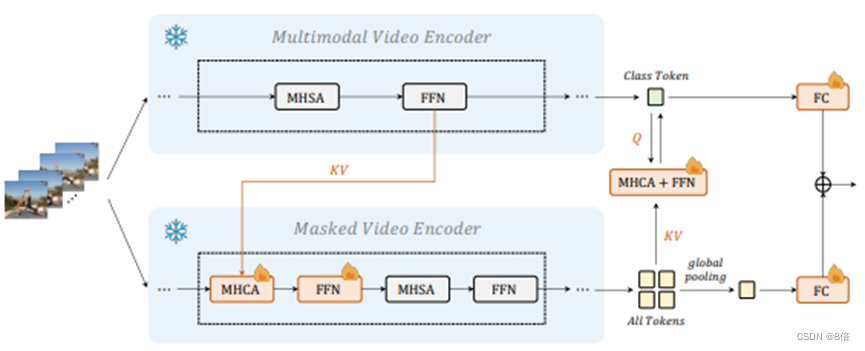
3、训练一个MAE和一个带有监督动作分类的多模态视频编码器作为Post-Pretraining步骤,以便在不同的下游任务中更好地表现。同时,为在MAE和视频语言对比学习的基础上学习统一的视频表示,引入交叉表示学习,并添加跨模型注意模块。
算法性能:

算法总结:
1、InternVideo是一个结合了MAE和多模态对比学习的视频基础模型,能够用于动作理解、视频语言对齐、开放式理解等多种下游任务。
2、与以往SOTA方法比较,其极大地提升了视频基础模型的通用性,在近40个数据集上达到了最先进的性能,涵盖了10个不同的任务。
------tbc-------
有用请点个👍哦~~😀