面试必备:索引能优化查询,那么谈谈索引的优点和缺点?索引原理
简述:
优点:
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能
缺点:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间
就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引的原理
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”。当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
索引是为检索而存在的,就是说索引并不是一个表必须的。表索引由多个页面组成,这些页面一起组成了一个树形结构,即我们通常说的B树, 首先来看下表索引的组成部分:
根极节点,root,它指向另外两个页,把一个表的记录从逻辑上分成非叶级节点Non-Leaf Level(枝),它指向了更加小的叶级节点Leaf Level(叶)。根节点、非叶级节点和叶级节点都位于索引页中,统称为索引叶节点,属于索引页的范筹。这些“枝”、“叶”最终指向数据页Page。根级节点和叶级节点之间的叶又叫数据中间页。根节点对应了sysindexes表的Root字段,记载了非叶级节点的物理位置(即指针);非叶级节点位于根节点和叶节点之间,记载了指向叶级节点的指针;而叶级节点则最终指向数据页,这就是最后的B树。
数据库是怎样访问表数据的:
第一:没有创建任何索引的表。
这种表我们称为堆表,因为所有的数据页都是无序的,杂乱无章的,在查询数据时,需要一条一条记录查询,有时第一条记录就能找到,最坏的情况是在最后一条记录中查找到,但是千万不要认为SQL此时查找到数据后会当成结果立即返回,SQL即使查找到了记录,也会将所有数据遍历一次,这能从最终的执行计划中得知,就是平时说的表扫描,对于没有索引的表也能查询,就是效率会特别低,如果数据量稍大的话。
问题:SQL是如何得知表没有索引呢?
SQL在接到查询请求的时候,会分析sysindexes表中索引标志符(INDID: Index ID)的字段的值,如果该值为0,表示这是一张数据表而不是索引表,SQL就会使用sysindexes表的另一个字段FirstIAM值中找到该表的IAM 页链也就是所有数据页集合。至于什么是IAM,大家可以网上搜索下。
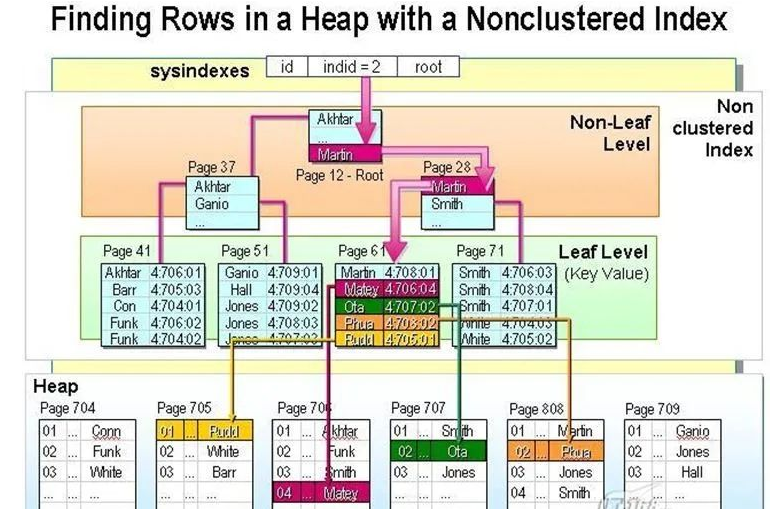
第二:访问创建有非聚集索引的表。
非聚集索引可以建多个,形成B树结构,叶级节点不包含数据页,只包含索引行。如果表中只有非聚集索引,则每个索引行包含了非聚集索引键值以及行定位符(ROW ID,RID),他们指向具有该键值的数据行。RID由文件ID、页编号和在页中行的编号组成。当 INDID的值在2-250之间时,说明表中存在非聚集索引页。SQL调用ROOT字段的值指向非聚集索引B树的ROOT,查找与被查询最相近的值,根据这个值找到在非叶级节点中的页号,在叶级节点相应的页面中找到该值的RID,最后根据这个RID在Heap中定位所在的页和行并返回到查询端。
上篇文章的cityid上建立了非聚集索引,执行Select * From student Where cityid=’0101’时,查询过程是:
1:在sysindexes表查询INDID值为2,说明有非聚集索引;
2:从根出发,在非叶级节点中定位最接近0101的值(枝节点),查到其位于叶级页面的第n页;
3:在叶级页面的第n页下搜寻0101的RID,其RID显示为N∶i∶j,表示cityid字段中名为0101的记录位于堆的第i页的第j行,N代表文件的ID值。
4:在堆的第 i页第j行将该记录返回给客户端。
下图可做参考:
第三:访问创建有聚集索引的表。
聚集索引中,数据所在的数据页是叶级,索引数据所在的索引页是非叶级。原理和上述非聚集索引的查询差不多,由于记录是按聚集索引键值进行排序,即聚集索引的索引键值也就是具体的数据页。这种情况比起非聚集索引要简单很多,因为比非聚集索引少了一层节点查询。
上篇文章的username字段上建立了聚集索引,此时执行Select* From student Where username=’1’时,查询过程是:
1:在sysindexes表查询INDID值为1,说明表中建立了聚集索;
2:从根出发,在非叶级节点中定位最接近1的值(枝节点),再查到其位于叶级页面的第n页;
3:在叶级页面第n页下搜寻值为1的条目,而这一条目就是数据记录本身;
4:将该记录返回客户端。
下图可做参考:

第四:怎样访问既有聚集索引、又有非聚集索引的数据表:
username字段上建立了聚集索引,cityid上建立了非聚集索引,当执行Select * From student Where cityid=’0101’时,查询过程是:
1:在sysindexes表查询INDID值为2,说明有非聚集索引;
2:从根出发,在cityid的非聚集索引的非叶级节点中定位最接近0101的条目;
3:从上面条目下的叶级页面中查到0101的逻辑位置,是聚集索引的指针;
4:根据指针所指示位置,进入位于username的聚集索引中的叶级页面中找到0101数据记录;
5:将该记录返回客户端。
通过上面数据库访问索引的原理,我们就很容易解释聚集索引与非聚集索引的区别了,原理都一样,关键看什么场合应用什么索引了,下一篇我来总结一些不同场合最适合采用什么样的索引,不对之外多多指点。