虽然Apache Kafka正在逐步引入KRaft以简化其一致性方法,但基于Raft构建的系统对于未来的超大规模工作负载显示出更多的潜力。
共识是一致性分布式系统的基础。为了在不可避免的崩溃事件中保证系统的可用性,系统需要一种方式来确保集群中的每个节点保持一致,以便在发生故障时工作可以无缝地在节点之间转移。共识协议(如Paxos、Raft和View Stamped Replication(VSR))通过提供领导者选举、原子配置更改、同步等过程的逻辑,帮助推动分布式系统的弹性。
与所有设计元素一样,分布式共识的不同方法提供了不同的权衡。Paxos是最古老的共识协议,被用于许多系统,如Google Cloud Spanner、Apache Cassandra、Amazon DynamoDB和Neo4j。Paxos通过三阶段、无领导者、多数胜出的协议实现共识。尽管Paxos在确保正确性方面非常有效,但它非常难以理解、实现和推理。这部分是因为它隐藏了许多达成共识的挑战(如领导者选举、重新配置),使得将其分解为子问题变得困难。
Raft(可靠、复制、冗余和容错)可以被看作是Paxos的一种演进,专注于可理解性。Raft可以实现与Paxos相同的正确性,但在现实世界中更容易理解和实现,因此通常可以提供更高的可靠性保证。例如,Raft使用一种稳定的领导形式,简化了复制日志管理,其领导者选举过程更高效。
由于Raft将共识问题的不同逻辑组件进行了分解,例如通过在复制之前将领导者选举作为一个独立的步骤,它是一种灵活的协议,适用于需要在保持正确性和性能的同时扩展到PB级吞吐量的复杂、现代分布式系统,同时对于新的工程师来说,理解起来更简单。 基于这些原因,Raft已经迅速被采用于当今的分布式和云原生系统,如MongoDB、CockroachDB、TiDB和Redpanda,以实现更高的性能和事务效率。
Redpanda是如何实现Raft的
当Redpanda的创始人Alex Gallego确定世界需要一个新的流数据平台来支持那些可能导致Apache Kafka崩溃的GBps+工作负载时,他决定从头开始重写Kafka。成为Redpanda的要求是:1)它需要简单轻量,以减少在大规模可靠运行Kafka集群时的复杂性和低效性;2)它需要最大化现代硬件的性能,以提供大型工作负载的低延迟;3)它需要保证即使在非常大的吞吐量下也能确保数据的安全性。实现Raft为这三个要求提供了坚实的基础:
-
简单性。每个Redpanda分区都是一个Raft组,因此平台中的所有内容都是围绕Raft进行推理,包括元数据管理和分区复制。这与Kafka的复杂性形成对比,Kafka中的数据复制由ISR(同步副本)处理,元数据管理由ZooKeeper(或KRaft)处理,这两个系统必须相互推理。
-
性能。Redpanda的Raft实现可以容忍少数副本的干扰,只要领导者和大多数副本是稳定的。在少数副本响应延迟的情况下,领导者不必等待它们的响应才能继续进行,从而减少对延迟的影响。因此,Redpanda具有更强的容错性,并且可以在大规模上提供可预测的性能。
-
可靠性。当Redpanda接收事件时,它们被写入一个主题分区并追加到磁盘上的日志文件中。然后,每个主题分区形成一个Raft共识组,由一个领导者和若干个跟随者组成,由主题的复制因子指定。在给定2ƒ+1个节点的情况下,Redpanda的Raft组可以容忍ƒ个故障;例如,在一个具有五个节点和复制因子为五的主题的集群中,可以有两个节点失败,主题仍然可以正常运行。Redpanda利用Raft联合共识协议,在重新配置期间提供一致性。
为了实现现代云原生解决方案所需的可扩展性、可靠性和速度,Redpanda还在一些关键方面扩展了核心Raft功能。它在Raft的基础上进行了创新,包括选举过程、心跳生成以及对Apache Kafka ACKS的支持。这些创新确保在所有场景下实现最佳性能,这使得Redpanda比Kafka快得多,同时仍然保证数据的安全性。事实上,Jepsen测试验证了Redpanda是一个没有已知一致性问题的安全系统,并且具有坚实的基于Raft的共识层。
关于KRaft
虽然Redpanda采用了原生的Raft方法,但传统的流数据平台在采用现代共识方法方面一直落后。Kafka本身是一个复制的分布式日志,但在历史上它依赖于另一个复制的分布式日志——Apache ZooKeeper来进行元数据管理和控制器选举。这存在一些问题的原因如下:
- 管理多个系统增加了管理负担;
- 由于元数据处理和双重缓存的低效性,可扩展性受到限制;
- 集群可能变得非常臃肿和资源密集;
事实上,看到ZooKeeper和Kafka节点数量相等的集群并不罕见。这些限制并没有被Apache Kafka的贡献者和维护者忽视,他们正在用自我管理的元数据仲裁系统Kafka Raft(KRaft)替换ZooKeeper。这种基于事件的Raft变体减少了Kafka元数据管理的管理挑战,并且这是Kafka生态系统朝着现代共识和可靠性方法发展的一个有希望的迹象。不幸的是,KRaft并没有解决在Kafka集群中存在两个不同的共识系统的问题。在新的KRaft范式中,KRaft分区处理元数据和集群管理,但复制由代理处理,因此仍然存在这两个不同的平台和由此产生的复杂性的低效性。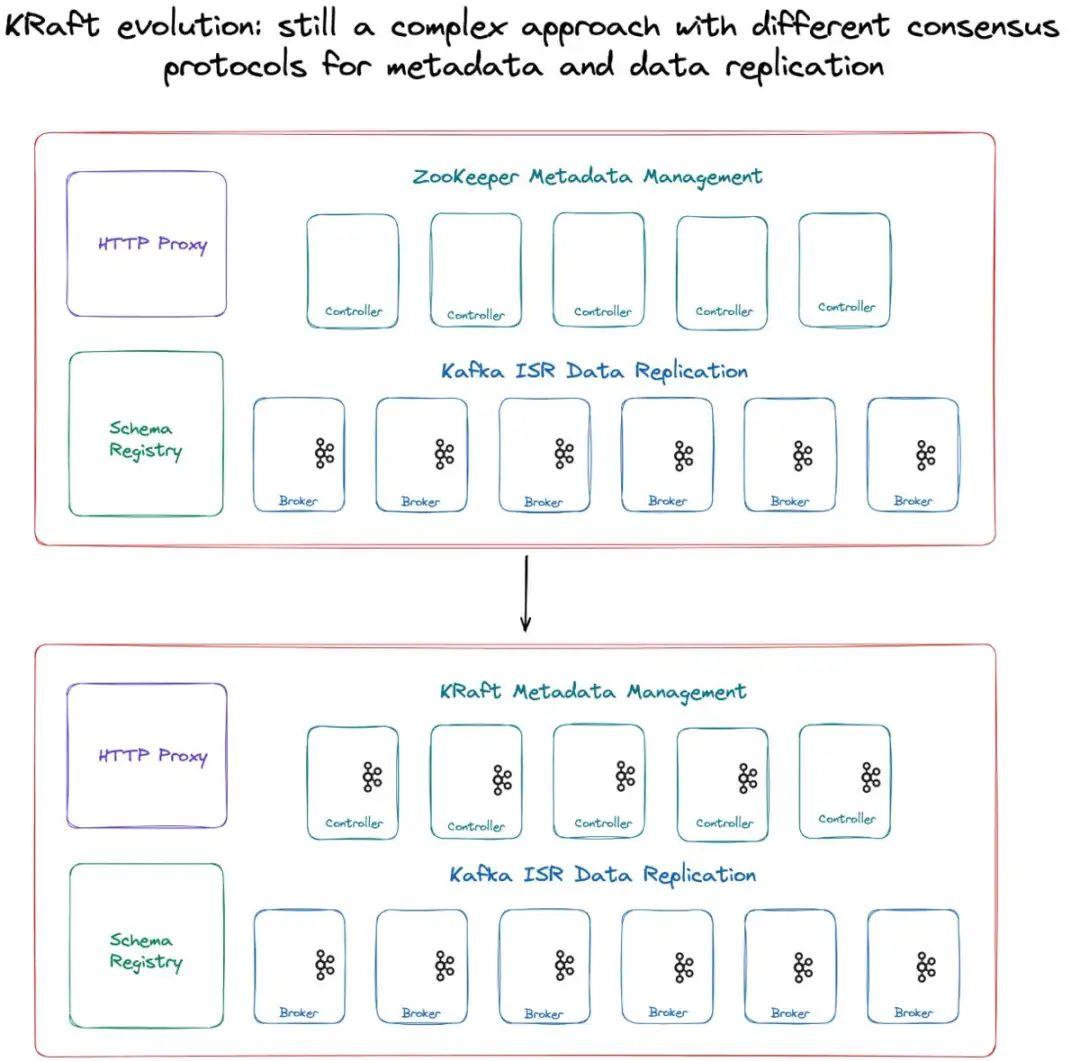
将Raft与性能工程相结合
正如CockroachDB、MongoDB、Neo4j和TiDB等数据行业的领导者所展示的那样,基于Raft的系统提供了更简单、更快速、更可靠的分布式数据环境。Raft正在成为当今分布式数据系统的标准共识协议,因为它与性能工程结合得非常好,进一步提高了数据处理的吞吐量。例如,Redpanda将Raft与高速架构组件结合起来,在处理1GBps的工作负载时,至少比Kafka快10倍的尾部延迟(p99.99),并且只使用三分之一的硬件,而不会影响数据的安全性。传统上,GBps+的工作负载对于Apache Kafka来说是一个负担,但Redpanda可以以两位数毫秒级的延迟支持它们,同时保持经过Jepsen验证的可靠性。这是如何实现的呢?Redpanda是用C++编写的,并使用每核心一个线程的架构,以充分发挥现代芯片和网络卡的最大性能。这些元素共同作用,提升了Raft在分布式流数据平台中的价值。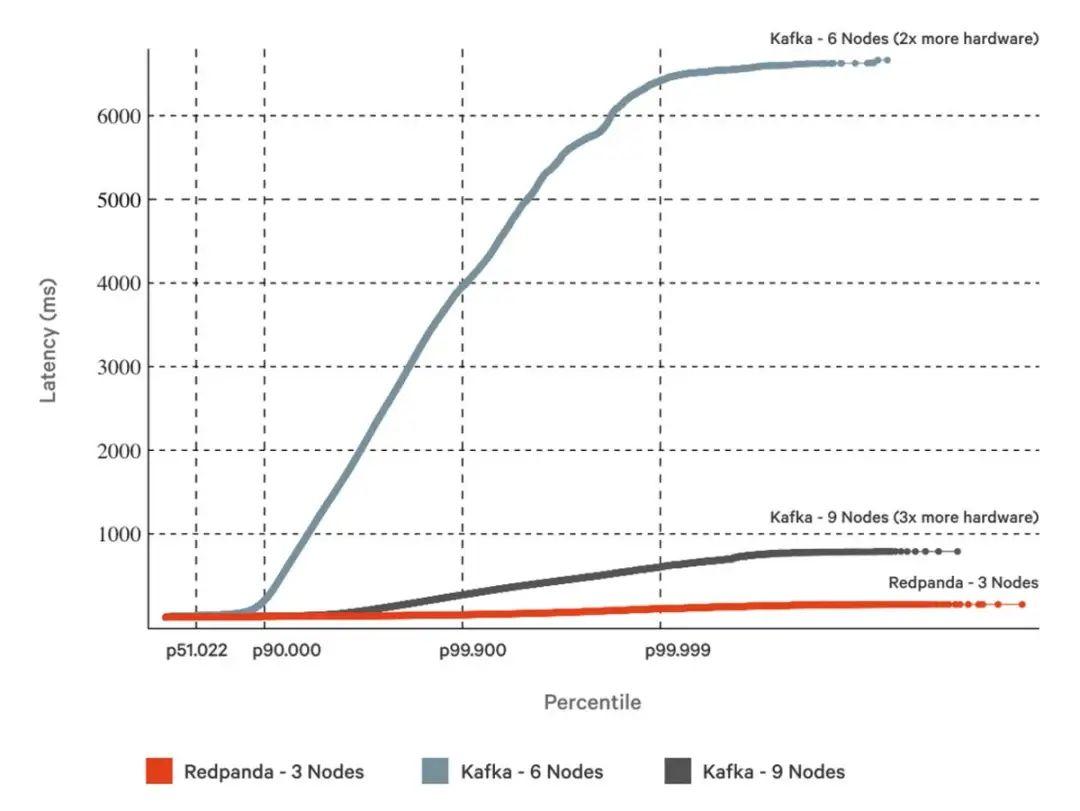 例如,因为Redpanda绕过了Kafka的页面缓存和Java虚拟机(JVM)依赖,它可以将硬件级别的知识嵌入到其Raft实现中。通常,每次在Raft中进行写操作时,都需要进行刷新以确保写入磁盘的持久性。在Redpanda对Raft的乐观方法中,较小的间断性刷新被放弃,而在调用结束时进行较大的刷新。虽然这会在每次调用中引入一些额外的延迟,但它减少了整体系统的延迟并增加了整体吞吐量,因为它减少了刷新操作的总数。虽然在分布式系统中确保一致性和安全性有许多有效的方法(区块链通过工作量证明和权益证明协议非常出色地完成了这一点),但Raft是一种经过验证的方法,并且足够灵活,可以像Redpanda一样进行增强,以适应新的挑战。随着我们进入一个由部分由人工智能和机器学习用例驱动的数据驱动的可能性的新世界,未来掌握在能够利用实时数据流的开发人员手中。 基于Raft的系统,结合C++和每核心一个线程的架构等性能工程元素,正在推动关键任务应用的数据流未来。
例如,因为Redpanda绕过了Kafka的页面缓存和Java虚拟机(JVM)依赖,它可以将硬件级别的知识嵌入到其Raft实现中。通常,每次在Raft中进行写操作时,都需要进行刷新以确保写入磁盘的持久性。在Redpanda对Raft的乐观方法中,较小的间断性刷新被放弃,而在调用结束时进行较大的刷新。虽然这会在每次调用中引入一些额外的延迟,但它减少了整体系统的延迟并增加了整体吞吐量,因为它减少了刷新操作的总数。虽然在分布式系统中确保一致性和安全性有许多有效的方法(区块链通过工作量证明和权益证明协议非常出色地完成了这一点),但Raft是一种经过验证的方法,并且足够灵活,可以像Redpanda一样进行增强,以适应新的挑战。随着我们进入一个由部分由人工智能和机器学习用例驱动的数据驱动的可能性的新世界,未来掌握在能够利用实时数据流的开发人员手中。 基于Raft的系统,结合C++和每核心一个线程的架构等性能工程元素,正在推动关键任务应用的数据流未来。
作者:Doug Flora
更多技术干货请关注公众号“云原生数据库”
squids.cn,目前可体验全网zui低价RDS,免费的迁移工具DBMotion、SQL开发工具等。









![[CrackMe]Brad Soblesky.1.exe和Brad Soblesky.2.exe的逆向及注册机编写](https://img-blog.csdnimg.cn/67980005aa1e479ab18abb7c1aad4dbb.png)