决策树:本质就是一个拥有多个判断节点的树
1,熵
系统越有序,集中,熵值越低;系统越混乱,越分散,熵值越高


在这里的计算中,log2记为1,通常以2为底
2,决策树的划分依据
2.1 信息增益
信息增益:以某特征划分数据集前后的熵的差值

信息增益越大,说明使用特征A来提升数据的纯度越大
2.2 信息增益率
信息增益偏向选择类名更多的特征,为克服该不足,提出信息增益比
C4.5 比ID3 要好的原因:
- C4.5使用了信息增益比,克服了不足
- 采用了后剪枝方法
- 对缺失值的处理
2.3 基尼值和基尼指数
基尼值Gini(D)越小,数据集的纯度越高
信息增益 — ID3决策树
基尼值
基尼指数 — CART
3,CART剪枝
作用:解决过拟合问题
剪枝方法:预剪枝,后剪枝
预剪枝:在生成决策树过程中剪枝
方法:
- 限制叶子节点最少样本数量,如果小于这个样本就不再分了
- 限制树的高度和深度;一旦达到这个深度了就不再分了
- 规定叶子点信息熵阈值,一旦没达到这个阈值就不再分了
后剪枝:在生成了决策树之后
C4.5决策树算法就是采用后剪枝
4,特征提取
定义:将任意数据(如文本或图像)转换为用于机器学习的数字特征
特征提取:文本转换为数字、类别转换为数字
特征提取分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习中讲解)
特征提取API:sklearn.fearure_extraction
4.1字典特征提取
只能处理字典类型的数据,将特征数据转换为one-hot编码的形式
注意:对于值比较少的类别特征使用one-hot编码,如果类别值很多,会对类别进行编号,转换为数字特征即可
from sklearn.feature_extraction import DictVectorizer
def dict_name():
"字典特征提取"
#1,获取数据
data = [{'city':'北京','temperature':100},
{'city':'上海','temperature':60},
{'city':'深圳','temperature':30}]
#2,字典特征提取
#2.1 实例化
transfer = DictVectorize(sparse=False)
#2.2 转换
new_data = transfer.fit_transform(data)
print(new_data)
#2.3 获取具体属性名
names = transfer.get_feature_names()
print('属性名字是:\n',names)
if __name__='__main__':
dict_name()
结果输出:

sparse=True时,输出如下:

每一行是:位置 对应数字
sparse=True只存储了非0的位置数字,节省了内存空间且提高了读取效率
4.2 英文文本特征提取

from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction import DictVectorizer
def english_count_demo():
#获取数据
data = ["life is short,i like python","life is too long,i dislike python"]
#文本特征转换
transfer = CountVectorizer(sparse=True)
new_data = transfer.fit_transform(data)
#查看特征名字
#names = transfer.get_feature_names(spares=True)#会报错,没有参数spares
names = transfer.get_feature_names()
print('特征名字是:\n',names)
print(new_data.toarray())#达到参数spares的效果
print(new_data)
if __name__='__main__':
english_count_name()
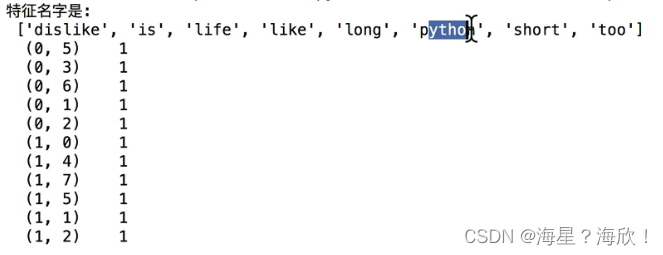
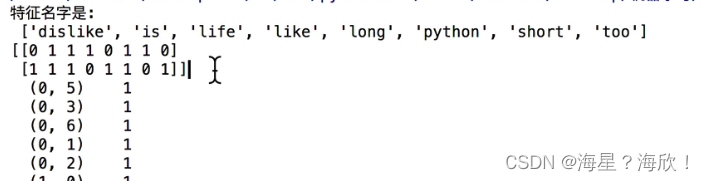
4.3 中文文本特征提取
直接用上面的代码,空格或者标点分隔,代表不同的词
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction import DictVectorizer
def english_count_demo():
#获取数据
data = ["生活苦短,我爱python","生活太长久,我不喜欢python"]
#文本特征转换
transfer = CountVectorizer(sparse=True)
new_data = transfer.fit_transform(data)
#查看特征名字
#names = transfer.get_feature_names(spares=True)#会报错,没有参数spares
names = transfer.get_feature_names()
print('特征名字是:\n',names)
print(new_data.toarray())#达到参数spares的效果
print(new_data)
if __name__='__main__':
english_count_name()

jieba分词:jieba.cut()
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
#对中文进行分词:“我爱北京天安门”--‘我 爱 北京 天安门’
#用jieba对中午字符串进行分词
text = " ".join(list(jieba.cut(text))) #空格分开的形式
return text
def text_chinese_count_demo():
#对中文进行特征提取
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝大部分是死在明天晚上所以每个人不要放弃","我们看到的是过去的明天,或许今天会有所不同,了解某种事物,了解到明天"]
#将文本转换为分好词的形式
text_list = []
for sent in data:
text_list.append(cut_word(seent))
print(text_list)
#1,实例化一个转换器类
transfer = CountVectorizer()
#transfer = CountVectorizer(stop_words=['今天',"明天","后天"])#停用词,觉得这些词语没用不显示
#2,调用fit_transfore
data = transfer.fit_transform(text_list)
print('文本特征抽取的结果是:\n',data.toarray())
print('返回特征名字:\n',transfer.get_feature_names)
if __name__='__main__':
text_chinese_count_demo()
4.4 Tf-idf文本特征提取
Tf-idf主要思想:如果某一个词或者短语在一篇文章中出现的概率高,并且在其他文章中很小出现,则认为该词或者短语具有很好的类别区分能力,适合用来分类。
Tf-idf作用:用以评估一字词对于一个文件集或一个语料库中的某个文件的重要程度
概念:
词频tf:指的是某一个给定的词语在该文件中出现的频率
逆向文档频率idf:是一个词语普遍重要性的度量,某一特定词语的idf是,由总文件数目除以包含该词语的文件数,再将得到的商取以10为底的对数得到
tf 词频
IDF指的是逆向文档频率,表示词是否具有强区分度
TFIDF表示某个词在当前文章中的重要性程度,经常被用于文本分类、垃圾邮件识别等场景中
公式:tf-idf = tf * idf
例子:总共1000个文件,含有某词语的文件10个,
所以tf=10/1000=0.1 , idf = log (1000/10) =2
tf-idf = tf * idf=0.2
API :skl
代码和上面一样,只需要改CountVectorizer为TfidfVectorizer
5,决策树算法api

6,泰坦尼克号乘客生存预测
步骤
1,获取数据 2,数据预处理 3,特征工程 4,机器学习建模 5,模型评估
步骤:获取数据-数据预处理(确定特征值与目标值、缺失值处理、数据集划分)、特征工程(字典特征抽取)、机器学习(决策树)、模型评估
kaggle上的项目与数据
观察数据得到:1,乘客班(1,2,3)2,age列有缺失
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_exyraction import DictVectorizer
#1.获取数据
titan = pd.read_scv("https://labfile.oss.aliyuncs.com/courses/1363/Titanic.csv")
titan
titan.describe()
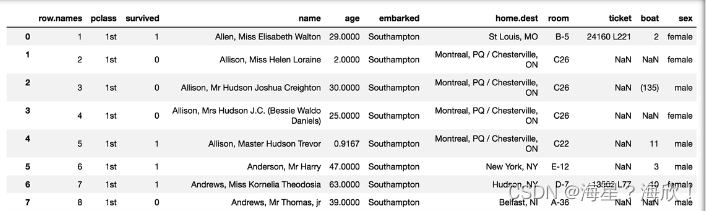
#2.1 确定特征值与目标值
x = titan[['pclass','age','sex']]
y = titan['survived']
x.head()
#2.2 缺失值处理
#age太多缺失,不能进行删除,进行替换
x['age'].fillna(value=titan['age'].mean(),inplace=True)
#2.3数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22,test_size=0.2)
#3 .特征工程(字典特征抽取)
x_train.head()
x_train = x_train.to_dict(orient='records') #转换成字典形式
x_test = x_test.to_dict(orient='records')
transfer = DictVectorizer
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
#4,决策树
estimator = DecisionTreeClassifier()
estimator.fit(x_train,y_train)
#5,模型评估
y_pre = estimator.predict(x_test)
y_pre
ret = estimator.score(x_test,y_test)
print(ret)
7,决策树总结
优点:简单的解释和理解,可视化
缺点:容易发生过拟合-改进:剪枝cart算法、随机森林
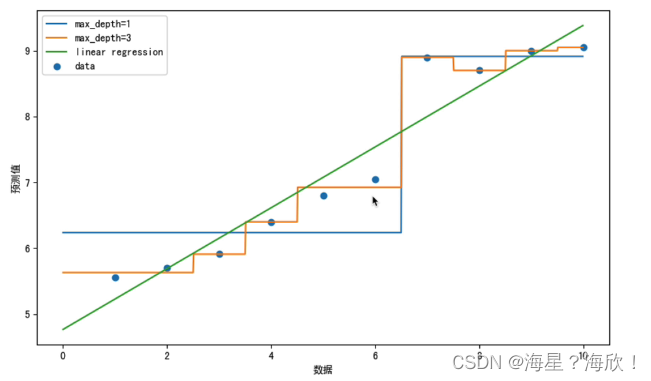
8,回归决策树
分类决策树和回归决策树
前者处理离散数据,后者处理连续性数据
举例说明:
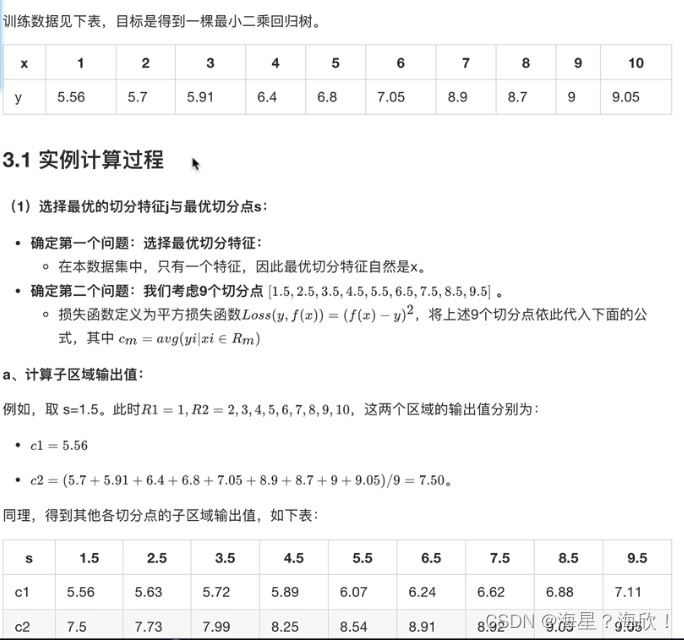
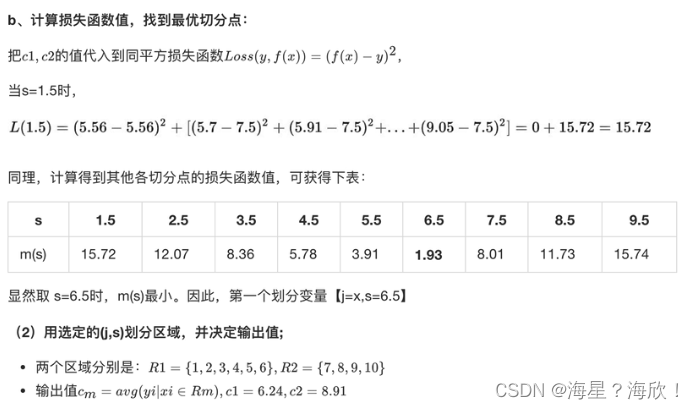
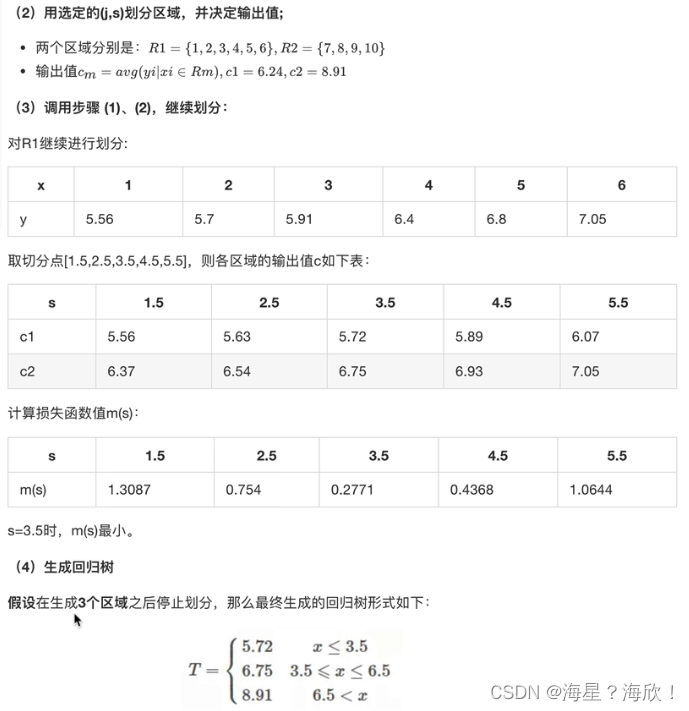
代码实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
#生成数据
x = np.array(list(range(1,11))).reshape(-1,1)
#reshape(-1,1)的意义把原本一维数据转成二维数据,这样方便输入
y = ([5.56,5.70,5.91,6.40,6.80,7.05,8.09,8.70,9.00,9.05])
#模型训练
m1 = DecisionTreeRegressor(max_depth=1)
m2 = DecisionTreeRegressor(max_depth=3)
m3 = LinearRegression()
m1.fit(x,y)
m2.fit(x,y)
m3.fit(x,y)
#模型预测
x_test =np.arange(0,10,0.01).reshape(-1,1)
y_1 = m1.predict(x_test)
y_2 = m1.predict(x_test)
y_3 = m1.predict(x_test)
#结果可视化
plt.figure(figsize=(10,6),dpi=100)
plt.scatter(x,y,label='data')
plt.plot(x_test,y_1,label='max_depth=1')
plt.plot(x_test,y_2,label='max_depth=3')
plt.plot(x_test,y_3,label='LinearRegression')
plt.xlabel('数据')
plt.ylabel('预测值')
plt.legend()
plt.show()