文章目录
- 前言
- 一、SQL语句分类
- 二、SQL语句的书写规范
- 三.数据库操作
- 四、MySQL字符集
- 1、问题①
- 五、UTF8和UTF8MB4的区别
- 六、数据库对象
- 七、数据类型
- 八、表的基本创建
- 1、创建表
- 2、查看表
- 3、删除表
- 4、修改表结构
- 5、复制表的结构
- 九、数据库字典
- 十、表的约束
- 1、非空约束(NOT NULL)
- 2、唯一约束
- 3、主键约束
- 4、外键约束
- 5、检查约束
- 6、默认值
- 7、删除表约束
- 8、存储引擎
- 十一、MySQL的用户授权
- 1、密码策略
- 2、授权和撤销授权
- 十二、MySQL之DML
- 1、INSERT语句
- 2 、REPLACE语句
- 3、UPDATE语句
- 4、DELETE和TRUNCATE语句
- 5、SELECT语句
- 6、多表关联查询
- 十二、SQL函数
- 1、聚合函数
- 2、数值型函数
- 3、字符串函数
- 4、日期和时间函数
- 5、流程控制函数
前言
SQL:结构化查询语言(Stuctured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务:
- 改变数据库的结构
- 更改系统的安全设置
- 增加用户对数据库或表的许可权限
- 在数据库中检索需要的信息
- 对数据库的信息进行更改
以下是本篇文章正文内容
一、SQL语句分类
MYSQL致力于支持全套ANSI/ISO SQL标准。再MYSQL数据库中,SQL语句主要可以划分为以下几类:
DDL(Data Definitio Language):数据定义语言,定义对数据库对象(库、表、列、索引)的操作。
CREATE、DROP、ALTER、RENAME、TRUNCATE等
DML(Data Manipultion Language):数据操作语言,定义对数据库记录的操作。
INSERT、DELETE、UPDATE、SELECT等
DCL(Data Control Language):数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别。
GRANT、REVIKE等
Transaction Control:事务控制
COMMIT、ROLLABACK、SAVEPOINT等
二、SQL语句的书写规范
- 在数据库系统中,SQL语句不区分大小写,但是在大家的认识中还是以大写为主;
- 字符串常量常常区分大小写;
- SQL语句可单行或者多行书写;
- 关键词不可以跨多行或简写;
- 用空格和缩进来提高语句的可读性
- 自居通常位于独立行,便于编辑,提高可读性
- 注释:
/**/:多行注释 “ -- ”: 单行注释 MySQL注释: “ # ”
三.数据库操作
1、查看
MYSQL字符集包括字符集和校对规则两个概念
Latin1支持西欧字符、希腊字符等
gbk支持中文简体字符
big5支持中文繁体字符
utf8几乎支持所有世界国家的字符
SHOW DATABASES
语法:
SHOW DATABASES [ LIKE wild];
如果使用LIKE wild不符合的话,wild字符串可以是一个使用SQL的‘%’和‘_’通配符的字符串
功能:列出MySQL服务器上面的数据库。
MySQL自带数据库:
Information_schema:主要储存了系统中的一些数据库对象信息:如用户表信息、列信息、权限信息、字符集信息、分区信息等等。
perfermance_schema:主要储存数据库服务器的性能参数
mysql:主要储存了系统的用户权限信息以及帮助信息。
sys:5.7新增加,之前版本需要手工导入,这个库是通过视图的形式把information_schma和performance_schma结合起来,查询出更加令人容易理解的数据
test:系统自动创建的测试数据库,任何用户都可以使用的库。
2、创建:
CREATE DATABASE
语法:
CREATE DATABASE [IF NOT EXISTS] 数据库名;
功能:用给定的名字创建了一个数据库
如果数据库已经存在、发生了一个错误。
查看创建数据库:SHOW CREATE DATABASE <数据库名>;
示例:
CREATE DATABASE SCHOOL DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
3、删除
DROP DATABASE
语法:
DROP DATABASE [IF EXISTS] 数据库名;
功能:删除数据库中的所有表和数据库 (切记要小心使用这个命令)
4、切换
使用USE选用数据库
语法:
USE 数据库名称;
功能:把指定数据库作为默认当前数据库使用,用于后续语句。
其他:
查看当前连接的数据库
SELECT DATABASE();
查看数据库版本
SELECT VERSION();
查看当前用户
SELECT User,Host,Password FROM mysql.user;
5、执行相对应系统命令
SYSTEM <命令>
system cls | clear
system date 等
四、MySQL字符集
MySQL字符集包括字符集和校验规则两个概念:
使⽤MySQL命令 SHOW VARIABLES like ‘character%’
使⽤MySQL命令“SHOW COLLATION;”即可查看当前MySQL服务实例⽀持的字符序。
MySQL字符序命名规则是:以字符序对应的字符集名称开头,以国家名居中(或以general居中),以ci、cs或bin结尾。
ci表⽰⼤⼩写不敏感,cs表⽰⼤⼩写敏感,bin表⽰按⼆进制编码值⽐较。
character_set_client:MySQL客户机字符集。
character_set_connection:数据通信链路字符集,当MySQL客户机向服务器发送请求时,请求数据以该字符集进行编码。
character_set_database:数据库字符集。
character_set_filesystem:MySQL服务器文件系统字符集,该值是固定的binary。
character_set_results:结果集的字符集,MySQL服务器MySQL客户机返回执行结果时,执行结果以该字符集进行编码。
character_set_server:MySQL服务实例字符集。
character_set_system:元数据(字段名、表名、数据库名等) 的字符集,默认值为
utf8。
1、问题①
到这里我想提出一个问题,当默认字符集为Latin1的时候,如何将其更改为utf8??????????
解决方法如下所示:
方法:
1、修改my.cnf配置文件,可以修改MySQL默认的字符集,修改完毕后重启MySQL
2、在[mysqld]下面添加
defult-character-set=utf8 #适合5.1及其以前的版本
(mysql 5.5及其以后版本添加character-set-server=utf8)
init_connect = ‘SET NAMES utf8’
3、在[client]下添加
default-character-set=utf8
4、5.8开始,官方建议用utf8mb4(后面会讲解utf8和utf8mb4)
五、UTF8和UTF8MB4的区别
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专⻔⽤来兼容四字节unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,⼀般情况下使⽤utf8也就够了。
既然utf8能够存下⼤部分中⽂汉字,那为什么还要使⽤utf8mb4呢? 原来mysql⽀持的 utf8编码最⼤字符⻓度为 3 字节,如果遇到 4 字节的宽字符就会插⼊异常了。三个字节的 UTF-8最⼤能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多⽂种平⾯(BMP)。也就是说,任何不在基本多⽂本平⾯的 Unicode字符,都⽆法使⽤ Mysql 的 utf8 字符集存储。包括Emoji 表情(Emoji 是⼀种特殊的 Unicode 编码,常⻅于 ios 和 android ⼿机上),和很多不常⽤的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议⼤家使⽤utf8mb4这种编码。
六、数据库对象
数据库对象的命名规则:
必须以字母开头
可以包括数字和三个特殊字符(# _ $)
不要使用MySQL的保留字
同一Schema下的对象不能同名

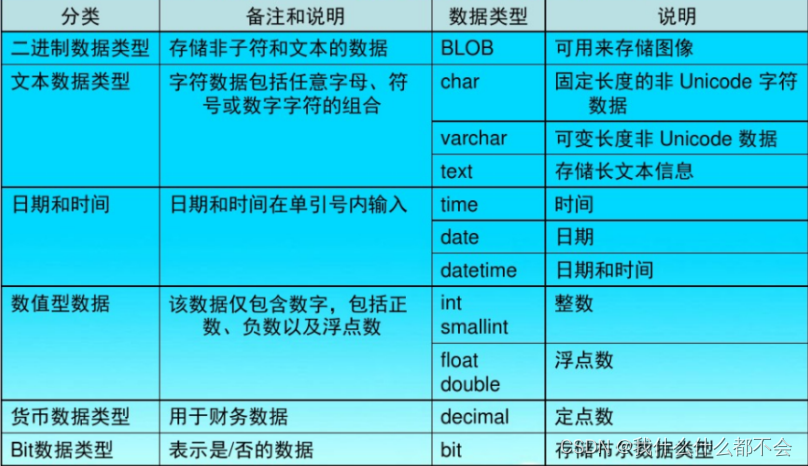
七、数据类型
在 MySQL 中,有三种主要的类型:⽂本、数字和⽇期/时间类型。
Text类型
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定⻓度的字符串(可包含字⺟、数字以及特殊字 符)。在括号中指定字符串的⻓度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变⻓度的字符串(可包含字⺟、数字以及特殊字 符)。在括号中指定字符串的最⼤⻓度。最多 255 个字 符。 注释:如果值的⻓度⼤于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最⼤⻓度为 255 个字符的字符串。 |
| TEXT | 存放最⼤⻓度为 65,535 个字符的字符串。 |
| BLOB | ⽤于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最⼤⻓度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | ⽤于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最⼤⻓度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | ⽤于 BLOBs (Binary Large OBjects)。存放最多4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许你输⼊可能值的列表。可以在 ENUM 列表中列出最⼤ 65535 个值。如果列表中不存在插⼊的值,则插⼊空值。 注释:这些值是按照你输⼊的顺序存储的。 可以按照此格式输⼊可能的值:ENUM(‘X’,‘Y’,‘Z’) |
| SET | 与 ENUM 类似, SET 最多只能包含 64 个列表项,不过 SET 可存储⼀个以上的值。 |
Number类型
| 数据类型 | 描述 |
|---|---|
| TINYINT(size) | -128 到 127 常规。 0 到 255 无符号*。在括号中规定最大位数。 |
| SMALLINT(size) | 32768 到 32767 常规。 0 到 65535 ⽆符号*。在括号中 规定最⼤位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。 0 to 16777215 ⽆符号*。在 括号中规定最⼤位数。 |
| INT(size) | -2147483648 到 2147483647 常规。 0 到 4294967295 ⽆ 符号*。在括号中规定最⼤位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。 0 到18446744073709551615 ⽆符号*。在括号中规定最⼤位 数。 |
| FLOAT(size,d) | 带有浮动⼩数点的⼩数字。在括号中规定最⼤位数。在 d 参数中规定⼩数点右侧的最⼤位数。 |
| DOUBLE(size,d) | 带有浮动⼩数点的⼤数字。在括号中规定最⼤位数。在 d 参数中规定⼩数点右侧的最⼤位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的⼩数点。 |
注意:这些整数类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加UNSIGNED属性,那么范围将从 0 开始,而不是某个负数。
Date类型
| 数据类型 | 描述 |
|---|---|
| DATE() | ⽇期。格式: YYYY-MM-DD 注释:⽀持的范围是从 ‘1000-01-01’ 到’9999-12-31’ |
| DATETIME() | ⽇期和时间的组合。格式: YYYY-MM-DD HH:MM:SS 注释:⽀持的范围是’1000-01-01 00:00:00’ 到 ‘9999-12- 31 23:59:59’ |
| TIMESTAMP() | 时间戳。 TIMESTAMP 值使⽤ Unix 纪元(‘1970-01-01 00:00:00’ UTC) ⾄今的描述来存储。格式: YYYY-MM-DD HH:MM:SS注释:⽀持的范围是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC |
| TIME() | 时间。格式: HH:MM:SS 注释:⽀持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。注释: 4 位格式所允许的值: 1901 到 2155。 2 位格式所允许 的值: 70到69,表⽰从 1970 到 2069 |
常用数据类型
八、表的基本创建
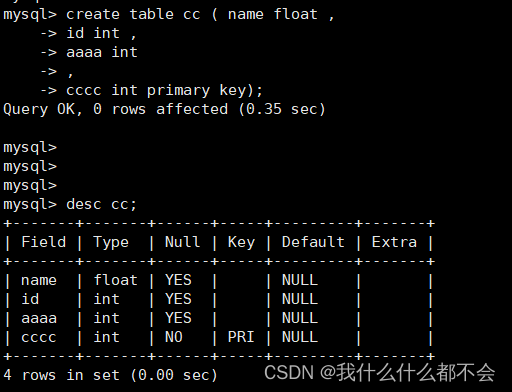
1、创建表
创建表的语句:
标准的建表(table)语法(列定义之间以英文逗号,隔开):
数据表的么行称为一条记录(record),每一列成为一个字段(field)。
主键列:唯一能够表示每一条记录的列。
CREATE TABLE [schma.] table
(column datatype [DEFAULT expr] ,
...
)ENGINE = 储存机制
CREATE TABLE
简单语法:
CREATE TABLE 表名(
列名 列类型,
列名 列类型
);
功能:在当前数据库中创建一张表
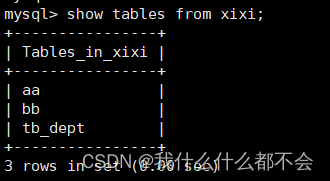
2、查看表
SHOW语句
语法:
SHOW TABLES [FROM 数据库名] [LIKE wild];
功能:显示当前数据库中已有的数据表的信息【结构和创建信息】
DESCRIBE
语法:
{DESCRIBE | DESC}表名[列名];
or
show columns from 表名称;
功能:查看数据表中各列的信息
用“SHOW CREATE TABLE 表名\G”可以查看更全面的表定义信息
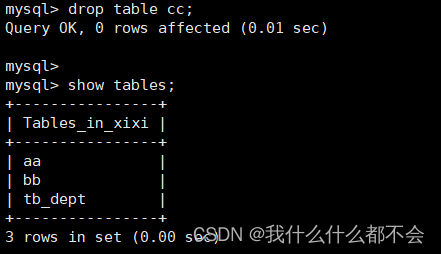
3、删除表
DROP TABLE
语法:
DROP TABLE [ IF EXISTS ] 表名;
功能:删除指定的表
4、修改表结构
修改表类型
ALTER TABLE 表名 MODIFY 列名 列类型;
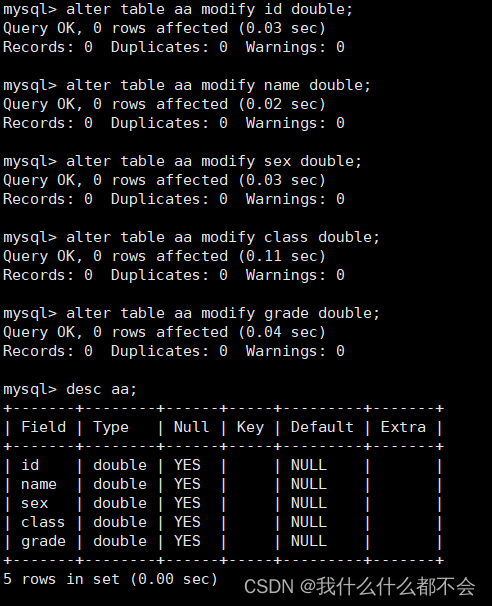
增加列:
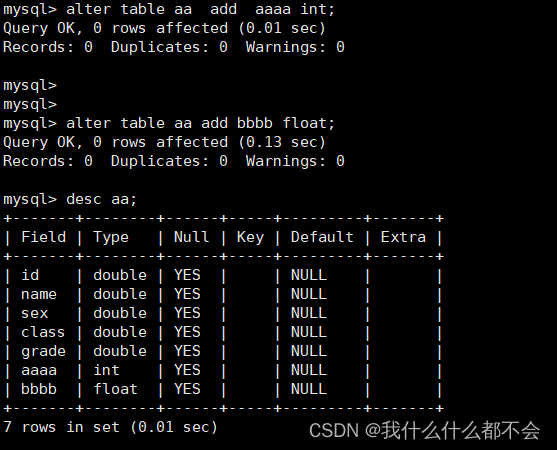
ALTER TABLE 表名 add 列名 列类型;
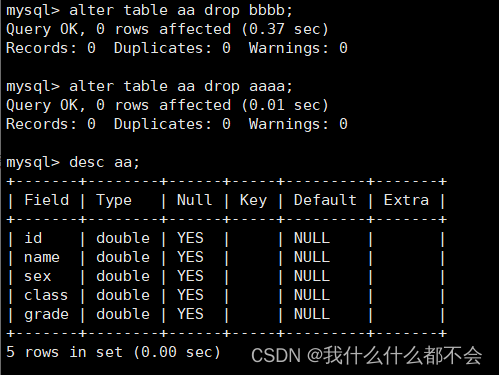
删除列:
ALTER TABLE 表名 DROP 列名;
列改名:
ALTER TABLE 表名 CHANGE 旧列名
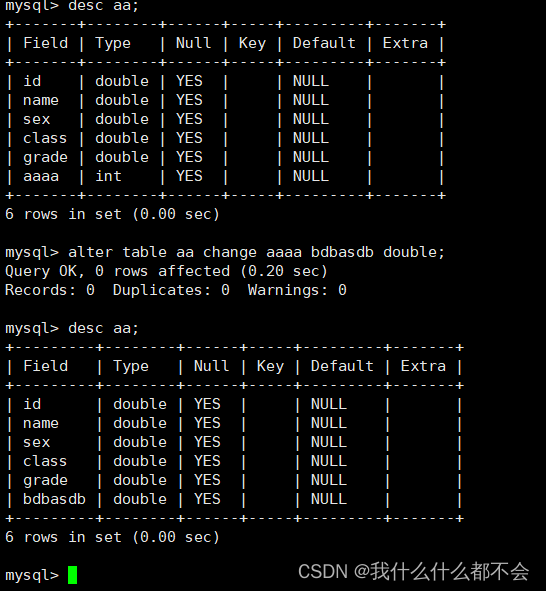
ALTER TABLE 表名 RENAME 新表名
RENAME TABLE 表名 TO 新表名
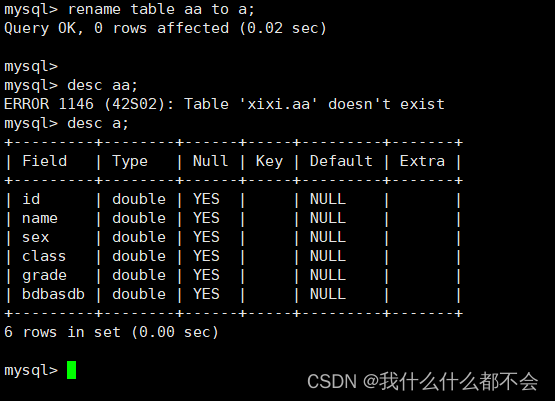
5、复制表的结构
复制一个表结构的实现方法有两种
方法一:在create table语句的末尾添加like子句,可以将源表的表结构复制到新表中,语法格式如下:
create table 新表名 like 源表
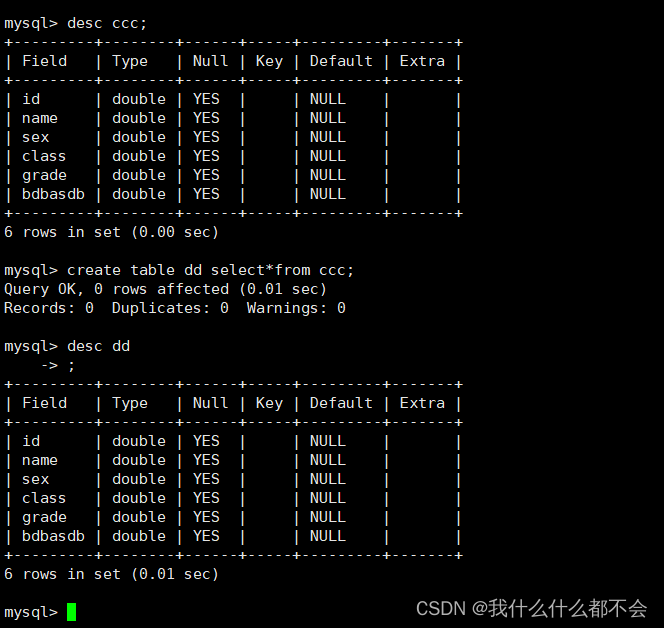
方法二:在create table语句的末尾添加一个select语句,可以实现表结构的复制,甚至可以将源表的表记录并拷贝到新表中,下面的语法格式将源表的表结构以及源表的所有记录拷贝到新表中。
create table 新表名 select * from 源表
方法三:如果已经存在一张机构一致的表,复制数据
insert into 表 select * from 原表;
方法一:
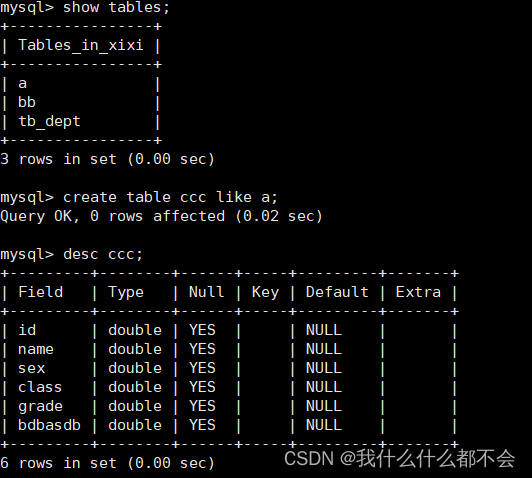
方法二:
九、数据库字典
由information_schema数据库负责维护
tables-存放数据库里所有的数据表、以及每个表所在数据库
schemata-存放数据库里所有的数据库信息
views-存放数据库里所有的视图信息
columns-存放数据库里所有的列信息
triggers-存放数据库里所有的触发器
routines-存放数据库里所有存储过程和函数
key_column_usage-存放数据库所有的主外键
table_constraints-存放数据库全部约束
statistics-存放了数据表的索引
十、表的约束
约束是在表上强制执⾏的数据校验规则。约束主要⽤于保证数据库的完整性。当表中数据有相互依赖性时,可以保护相关的数据不被删除。⼤部分数据库⽀持下⾯几类完整性约束:
- NOT NULL非空
- UNIQUE Key唯一键
- PRIMARY KEY主键
- FOREIGN KEY外键
- CHECK检查
- 默认值约束
约束作为数据库对象,存放在系统表中,也有自己的名字
创建约束的时机:
在建表的同时创建
建表后创建(修改表)
可定义列级或表级约束
有单列约束和多列约束
定义约束的语法:
列级约束:在定义列的同时定义约束
语法:列定义 约束类型,
表级约束:在定义了所有列之后定义的约束
语法:
列定义
[CONSTRAINT 约束名] 约束类型(列名)
约束名的取名规则
推荐采用:表名_列名_约束类型简介
约束可以在创建表时就定义,也可以在创建完后再添加
语法:
alter table 表名 add constraint 约束名 约束类型(要约束的列名)
以下是表的约束示例
1、非空约束(NOT NULL)
- 列级约束,只能使用列级约束语法定义。
确保字段值不允许为空
只能在字段级定义
CREATE TABLE tb_student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(18) NOT NULL
)
NULL
所有数据类型的值都可以是NULL。
空字符串不等于NULL。
0也不等于NULL。
2、唯一约束
- 唯一性约束条件确保所在的字段或者字段组合不出现重复值
- 唯一性约束条件的字段允许出现多个NULL
- 同一张表内可建多个唯一约束
- 唯一约束可由多列组合而成
- 建唯一约束时MySQL会为之建立对应的索引。
- 如果不给唯一约束起名,该唯一约束默认与列名相同。
CREATE TABLE tb_student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(18) UNIQUE NOT NULL
)
3、主键约束
- 主键从功能上看相当于非空且唯一
- 一个表中只允许一个主键
- 主键是表中唯一确定一行数据的字段
- 删除表的约束
- 自动增长和默认值
- 存储引擎
- 主键字段可以是单字段或者是多字段的组合
- 当建立主键约束时,MySQL为主键创建对应的索引
- 主键约束名总为PRIMARY。
CREATE TABLE tb_student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(18)
)
4、外键约束
- 外键是构建于一个表的两个字段或者两个表的两个字段之间的关系
- 外键确保了相关的两个字段的两个关系
- 子(从)表外键列的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空)。
- 当主表的记录被子表参照时,主表记录不允许被删除。
- 外键参照的只能是主表主键或者唯一键,保证子表记录可以准确定位到被参照的记录。
格式FOREIGN KEY (外键列名)REFERENCES 主表(参照列)
CREATE TABLE tb_dept(
dept_id INT PRIMARY KEY,
NAME VARCHAR(18),
description VARCHAR(255)
);
CREATE TABLE tb_employee(
employee_id INT PRIMARY KEY,
NAME VARCHAR(18),
gender VARCHAR(10),
删除表的约束:
dept_id INT REFERENCES tb_dept(dept_id),
address VARCHAR(255)
);
5、检查约束
注意检查约束在8.0之前,MySQL默认但不会强制的遵循check约束(写不报错,但是不生 效,需要通触发器完成)
之后就开始正式支持这个约束了。
create table t3(
id int,
age int check(age > 18),
gender char(1) check(gender in (‘M’,‘F’))
);
6、默认值
可以使用default关键字设置每一个字段的默认值。
创建一张user表
CREATE TABLE `test`.`user`(
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` VARCHAR(225) COMMENT '姓名',
`sex` TINYINT(1) DEFAULT 1 COMMENT '性别 1男 0女',
PRIMARY KEY (`id`)
) ENGINE=INNODB CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
7、删除表约束
删除NOT NULL约束
alter table 表名 modify 列名 类型;
alter table student modify s_name not null;
删除UNIQUE约束
alter table 表名 drop index 惟一约束名;
alter table student drop index unique;
删除PRIMARY KEY约束
alter table 表名 drop primary key;
alter table student drop primary key;
删除FOREIGN KEY约束
alter table 表名 drop foreign key 外键名;
alter table student drop foreign key student_score;
这里假设与成绩表score设置了外键约束
auto_increment :自动增长
为新的行产生唯一的标识
一个表只能优一个auto_increment,且该属性必须为主键的一部分。
auto_increment的属性可以是任何整数类型
default : 默认值
8、存储引擎
MySQL中的数据⽤各种不同的技术存储在⽂件(或者内存)中, 每种技术都使⽤不同的存储机制、索引技巧、 锁定⽔平。这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)
插件式存储引擎是MySQL数据库最重要的特性之⼀, ⽤⼾可以根据应⽤的需要选择如何存储和索引数据、 是否使⽤事务等。
默认情况下,创建表不指定表的存储引擎,则会使用配置文件中的my.cnf中的default-storage-engine=InnoDB指定的InnoDB(配置文件即为 vim /etc/my.cnf当中)
命令如下:
SHOW VAIABLES LIKE ' table_type ';
MyISAM:应用于以读写操作为主, 很少更新 、 删除 , 并对事务的完整性、 并发性要求不⾼的情况
InnoDB:应⽤于对事务的完整性要求⾼,在并发条件下要求数据的⼀致性的情况。现在的默认值。
MERGE: 是⼀组MyISAM表的组合。 可以突破对单个MyISAM表⼤⼩的限制, 并提⾼访问效率
在创建表是, 可以指定表的存储引擎:
CREATE TABLE (...) ENGINE=InnoDB;
创建完整的建表语句为:
CREATE TABLE 表名(
列名 列类型 [ATUO_INCREMENT] [dEFAULT 默认值][列约束]
...
[表约束]
)[ENGINE=表类型] [DEFAULT] CHARSET=字符集;
列类型:该列的数据类的存储类型
AUTO_INCREMENT:自动增尚只能是数值类型的列
DEFAULT 默认值: 设置该列的默认值
约束:对列的一些限制
ENGINE:表类型,也叫表的存储列表
CHARSET:设置表的字符集
查看一个表的数据引擎可以使用 SHOW CREATE TABLE 表名;
mysql> show create table emp;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| emp | CREATE TABLE `emp` (
`empno` int(4) NOT NULL,
`ename` varchar(255) DEFAULT NULL,
`job` varchar(255) DEFAULT NULL,
`mgr` int(4) DEFAULT NULL,
`hiredate` date NOT NULL,
`sai` int(255) NOT NULL,
`comm` int(255) DEFAULT NULL,
`deptno` int(2) NOT NULL,
PRIMARY KEY (`empno`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
十一、MySQL的用户授权
1、密码策略
MySQL升级5.7版本以后,安全性大幅度上升
MySQL5.7为root用户随机生成了一个密码,打印在error_log中,关于error_log的位置,如果是安装的是RPM包,则会默认是/var/log/mysqld.log
awk '/temporaray password/'{print $NF}' /var/log/mysqld.log
#or
grep 'password' /var/log/mysqld.log
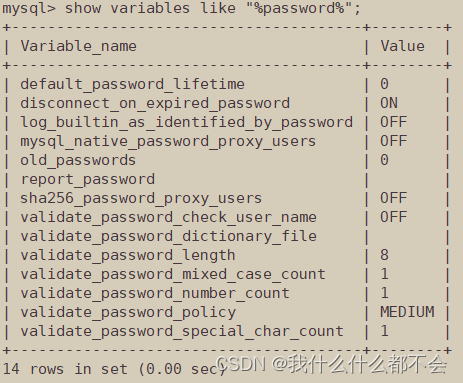
查看当前数据库的密码策略:
SHOW VARIABLES LIKE "%PASSWORD%";
查看密码插件:
SHOW VARIABLES LIKE "VALIDATE_PASSWORD%";
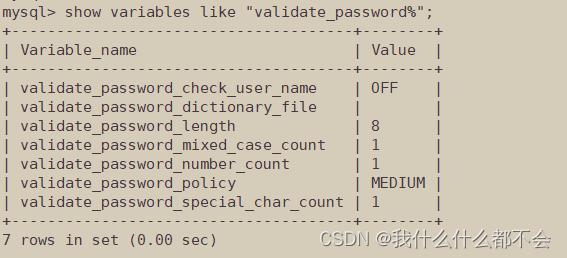
更改密码策略,命令一般为 SET GLOABL Validate_name(表中的东西)=对应的东西就好了
解释说明一个事情,就是当我们新安装了MySQL数据库的时候,系统会默认给你一个复杂的密码,但是你觉得不方便,总想变成自己的密码,中途会遇到不能更改的情况,就是权限不够,刷新权限呢,还是没什么效果,因为没有将系统给你的密码做出该表,就会导致你无法正常使用数据库的一切,因此我们就必须从密码策略开始下手,其中 validate_password_policy 就是全局约束策略的权限,一般我们将这个改为零,剩下的密码复杂度啊,还有密码长度啊,还有数字长度,都可以根据自己的情况进行更改,更改成功后,在设置数据的密码,就会成功了。
提醒几句:1、对于初学者来说,此种修改密码策略的办法可以解决大部分的密码策略问题,很实用;
2、由于我对密码策略的了解比较深,因为以前这个问题也很困扰我,后来才发现这个问题的严重性;
3、对于以后进入公司的人来说,公司的数据库的密码一定是复杂度拉满的,不管是从各个方面来说,一定是优于这个密码
很多倍数的,所以了解此种方法只适合初学,但是要明白这个道理。
修改密码策略示例(临时修改的,方便使用):
方法1:临时修改
更改密码策略为LOW,改为LOW或0
mysql> SET GLOBAL validate_password_policy='LOW';
Query OK, 0 rows affected (0.01 sec)
更改密码长度
mysql> SET GLOBAL validate_password_length=0;
Query OK, 0 rows affected (0.00 sec)
设置大小写、数字和特殊字符均不要求。
mysql> SET GLOBAL validate_password_special_char_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL validate_password_mixed_case_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL validate_password_number_count=0;
Query OK, 0 rows affected (0.00 sec)
查看:
mysql> SET GLOBAL validate_password_length=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| validate_password_dictionary_file | |
| validate_password_length | 0 |
| validate_password_mixed_case_count | 0 |
| validate_password_number_count | 0 |
| validate_password_policy | LOW |
| validate_password_special_char_count | 0 |
+--------------------------------------+-------+
6 rows in set (0.00 sec)
测试:
mysql> drop user test1@localhost;
Query OK, 0 rows affected (0.00 sec)
⽅法2:初始化时不启⽤,只需要在初始化时指定 --initialize-insecure 即可,⽐如:
mysqld -initialize-insecure -datadir=/var/lib/mysql -basedir=/usr
-user=mysql
方法3:修改配置⽂件
在 /etc/my.cnf 配置⽂件中增加:
[mysqld]
validate_password=off
修改完毕,重启服务
2、授权和撤销授权
MySQL中的授权(grant)和撤销授权(revoke)
方法1:create和grant结合
help CREATE USER;
命令:CREATE USER <'用户名'@'地址'> IDENTIFIED BY ‘密码’;
查看用户权限: help SHOW GRANTS;
命令:show grants for '用户名'@'地址';
授权:help GRANT;
方法2:直接grant
收回权限:REVOKE
删除用户:DROP USER username
生产环境授权用户建议:
1、博客,CMS等产品的数据库授权
select,insert,update,delete,create
库生成后收回create权限
2、生产环境主库用户授权
select,insert,update,delete
3、生产环境从库授权
select
创建用户方法(推荐使用方法三):
方法一:CREATE USER语句创建
CREATE USER user1@’localhost’ IDENTIFIED BY ‘123456’;
方法二: INSERT语句创建
INSERT INTO mysql.user(user,host, authentication_string,ssl_cipher,
x509_issuer,x509_subject)
VALUES('user2','localhost',password('ABCabc123!'),'','','');
FLUSH PRIVILEGES;
方法三: GRANT语句创建
GRANT SELECT ON *.* TO user3@’localhost’ IDENTIFIED BY ‘123456’;
FLUSH PRIVILEGES;
语法格式:
grant 权限列表 on 库名.表名 to 用户名@'客户端主机'
[identified by '密码' with option参数];
如:
grant select on testdb.* to common_user@'%'
grant insert on testdb.* to common_user@'%'
grant update on testdb.* to common_user@'%'
grant delete on testdb.* to common_user@'%'
grant select, insert, update, delete on testdb.* to common_user@'%'
grant create on testdb.* to developer@'192.168.0.%';
grant alter on testdb.* to developer@'192.168.0.%';
grant drop on testdb.* to developer@'192.168.0.%';
grant all on *.* to dba@localhost; - dba 可以管理 MySQL 中的所有数据库
show grants; - 查看当前用户(自己)权限
show grants for dba@localhost;
grant all on *.* to dba@localhost;
# 移除权限
# revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可
revoke all on *.* from dba@localhost;
with_option参数
GRANT OPTION: 授权选项
MAX_QUERIES_PER_HOUR: 定义每小时允许执行的查询数
MAX_UPDATES_PER_HOUR: 定义每小时允许执行的更新数
MAX_CONNECTIONS_PER_HOUR: 定义每小时可以建立的连接数
MAX_USER_CONNECTIONS: 定义单个用户同时可以建立的连接数
十二、MySQL之DML
有关数据表的DML操作
- INSERT INTO
- DELETE、TRUNCATE
- UPDATE
- SELECT
- 条件查询
- 查询排序
- 聚合函数
- 分组查询
1、INSERT语句
INSERT INTO TABLE [(column [,column ...])] VALUES(value [,value ..]);
默认情况下,一次插入操作只插入一条信息,也就是一行
一次性插入多条信息:
INSERT INTO table [(column [, column .])]
VALUES(value [, value .]),(value [, value .])
如果为每列都指定值,则表名后不需列出插入的列名
如果不想在表名后列出列名,可以为那些无法指定的值插入null
可以使用如下方式一次插入多行
insert into 表名[(列名,…)]
select 语句——可以非常复杂。
如果需要插入其他特殊字符,应该采用\转义字符做前缀
2 、REPLACE语句
replace语句的语法格式有三种语法格式。
语法格式1:replace into 表名 [(字段列表)] values (值列表)
语法格式2:
replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表
where 条件表达式
语法格式3:
replace [into] 表名 set 字段1=值1, 字段2=值2
REPLACE与INSERT语句的区别:
replace语句的功能与insert语句的功能基本相同,不同之处在于:使⽤replace语句向表插⼊
新记录时,如果新记录的 主键值或者唯⼀性约束 的字段值与已有记录相同,则已有记录先被
删除(注意:已有记录删除时也不能违背外键约束条件),然后再插⼊新记录。
使⽤replace的最⼤好处就是可以将delete和insert合⼆为⼀(效果相当于更新),形成⼀个原⼦
操作,这样就⽆需将delete操作与insert操作置于事务中了
3、UPDATE语句
UPDATE table
SET column = value [, column = value]
[WHERE condition];
修改可以⼀次修改多⾏数据,修改的数据可⽤where⼦句限定,where⼦句⾥是⼀个条件表达式,只有符合该条件的⾏才会被修改。没有where⼦句意味着where字句的表达式值为true。也可以同时修改多列,多列的修改中间采⽤逗号(,)隔开
4、DELETE和TRUNCATE语句
DELETE FROM table_name [where 条件];
TRUNCATE TABLE table_name
完全清空一个表。DDL语句
DROP、TRUNCATE、DALETE的区别
- delete:删除数据,保留表结构,可以回滚,如果数据量⼤,很慢
- truncate: 删除所有数据,保留表结构,不可以回滚,⼀次全部删除所有数据,速度相对很快
- drop: 删除数据和表结构,删除速度最快。
5、SELECT语句
简单的select语句:
简单的SELECT语句:
SELECT {*, column [alias], .}
FROM table;
说明:
- SELECT列名列表。*表示所有列。
- FROM 提供数据源(表名/视图名)
- 默认选择所有行
SELECT语句中的算术表达式:
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
SELECT last_name, salary, salary*12
FROM employees;
-- MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80
SELECT 'This'+'is'; # 转换不成功,结果为0
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
运算符的优先级:
乘法和除法的优先级高于加法和减法
同级运算的顺序是从左到右
表达式中使用括号可强行改变优先级的运算顺序
SELECT last_name, salary, salary*12+100
FROM employees;
SELECT last_name, salary, salary*(12+100)
FROM employees;
NULL值的使⽤:
空值是指不可用、未分配的值
空值不等于零或空格
任意类型都可以支持空值
包括空值的任何算术表达式都等于空
字符串和null进行连接运算,得到也是null.
补充说明:
安全等于<=>
1.可作为普通运算符的=
2.也可以用于判断是否是NULL 如:where salary is NULL/(is not NULL)
->where salary
<=>NULL
示例1:查询emp表奖金为空的员工信息。
select * from emp where comm <=> NULL;
示例2:查询emp表奖金为50000的员工信息
select * from emp where comm <=> 50000;
定义字段的别名:
改变列的标题头
用于表示计算结果的含义
作为列的别名
如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都可以通过为别名添加加双引号
实现。
SELECT last_name as “姓名”, salary “薪水”
FROM employees;
SELECT last_name, salary*12 “年薪”
FROM employees;
重复记录:
缺省情况下查询显示所有行,包括重复行
SELECT department_id
FROM employees;
使用DISTINCT关键字可从查询结果中清除重复行
SELECT DISTINCT department_id
FROM employees;
DISTINCT的作用范围是后面所有字段的组合
SELECT DISTINCT department_id , job_id
FROM employees;
限制所选择的记录: 重点
1、使用WHERE子句限定返回的记录
WHERE子句在FROM 子句后
SELECT[DISTINCT] {*, column [alias], .}
FROM table–[WHEREcondition(s)];
WHERE中的字符串和日期值
字符串和日期要用单引号扩起来
字符串是大小写敏感的,日期值是格式敏感的
SELECT last_name, job_id, department_id
FROM employees
WHERE last_name = "king";
2、WHERE中比较运算符:
SELECT last_name, salary, commission_pct
FROM employees
WHERE salary =1500;
3、其他比较运算符
使用BETWEEN运算符显示某一值域范围的记录
SELECTlast_name, salary
FROM employees
WHERE salary BETWEEN 1000 AND 1500;
4、使用IN运算符
使用IN运算符获得匹配列表值的记录
SELECTemployee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (7902, 7566, 7788);
5、使用LIKE运算符
使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_A%';
6、使用IS NULL运算符
查询包含空值的记录
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
7、逻辑运算符
使用AND运算符
AND需要所有条件都是满足T.
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary =1100–4 AND job_id='CLERK';
8、使用OR运算符
OR只要两个条件满足一个就可以
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary =1100 OR job_id='CLERK';
9、使用NOT运算符
NOT是取反的意思
SELECT last_name, job_id
FROM employees
WHERE job_id NOT IN ('CLERK','MANAGER','ANALYST');
10、使用正则表达式:REGEXP
<列名> regexp '正则表达式'
select * from product where product_name regexp '^2018';
11、数据分组 -GROUP BY
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分
组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。
分组函数忽略空值,。
结果集隐式按升序排列,如果需要改变排序方式可以使用Order by 子句。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
#每个部门的平均工资
SELECT deptno,AVG(sal) FROM TB_EMP GROUP BY deptno
#查每个部门的整体工资情况
#如果select语句中的列未使用组函数,那么它必须出现在GROUP BY子句中
#而出现在GROUP BY子句中的列,不一定要出现在select语句中
SELECT deptno,AVG(sal),MAX(sal),MIN(sal),SUM(sal),COUNT(1)
FROM TB_EMP
GROUP BY deptno #根据部门编号分组
#每个部门每个职位的平均工资
SELECT deptno,job,AVG(sal) FROM TB_EMP GROUP BY deptno,job
12、分组函数重要规则
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表中的字段,要么
出现在组合函数里,
要么出现在GROUP BY 子句中。
GROUP BY 子句的字段可以不出现在SELECT列表当中。
使用集合函数可以不使用GROUP BY子句,此时所有的查询结果作为一组。
13、数据分组 -限定组的结果:HAVING子句
HAVING子句用来对分组后的结果再进行条件过滤。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BYcolumn];
HAVING子句用来对分组后的结果再进行条件过滤。
#查询部门平均工资大于2000的
#分组后加条件 使用having
#where和having都是用来做条件限定的,但是having只能用在group by之后
SELECT deptno,AVG(sal),MAX(sal),MIN(sal),SUM(sal),COUNT(1)
FROM TB_EMP
GROUP BY deptno
HAVING AVG(sal) > 2000
HAVING与WHERE的区别
WHERE是在分组前进行条件过滤, HAVING子句是在分组后进行条件过滤,WHERE子句中
不能使用聚合函数,
HAVING子句可以使用聚合函数。
14、组函数的错误用法
不能在WHERE 子句中限制组.
限制组必须使用HAVING 子句.
不能在WHERE 子句中使用组函数
补充:MySQL 多行数据合并 GROUP_CONCAT
Syntax: GROUP_CONCAT(expr)
示例:fruits表按s_id,将供应水果名称合并为一行数据
mysql> select s_id,group_concat(f_name)
-> from fruits
-> group by s_id;
+------+-------------------------+
| s_id | group_concat(f_name) |
+------+-------------------------+
| 101 | apple,blackberry,cherry |
| 102 | orange,banana,grape |
| 103 | apricot,coconut |
| 104 | berry,lemon |
| 105 | melon,xbabay,xxtt |
| 106 | mango |
| 107 | xxxx,xbababa |
+------+-------------------------+
7 rows in set (0.00 sec)
注意:使用 GROUP_CONCAT()函数必须对源数据进行分组,否则所有数据会被合并成
一行
15、对结果集排序
查询语句执行的查询结果,数据是按插入顺序排列
实际上需要按某列的值大小排序排列
按某列排序采用order by 列名[desc],列名…
设定排序列的时候可采用列名、列序号和列别名
如果按多列排序,每列的asc,desc必须单独设定
16、联合查询
- 中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'
说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能
UNION 去重复
UNION ALL 不去重复
17、查询结果限定
在SELECT语句最后可以用LIMLT来限定查询结果返回的起始记录和总数量。MySQL特有。
SELECT … LIMIT offset_start,row_count;
offset_start:第一个返回记录行的偏移量。默认为0.
row_count:要返回记录行的最大数目。
例子:
SELECT * FROM TB_EMP LIMIT 5; *检索前5个记录*/
SELECT * FROM TB_EMP LIMIT 5,10; *检索记录行6-15 /
18、MySQL中的通配符:
MySQL中的常用统配符有三个:
%:用来表示任意多个字符,包含0个字符
_ : 用来表示任意单个字符
escape:用来转义特定字符
6、多表关联查询
1. inner join:代表选择的是两个表的交差部分。
内连接就是表间的主键与外键相连,只取得键值一致的,可以获取双方表中的数据连接方式。
语法如下:
SELECT 列名1,列名2 . FROM 表1 INNER JOIN 表2 ON 表1.外键=表2.主键
WHERE 条件语句;
2. left join:代表选择的是前面一个表的全部。
左连接是以左表为标准,只查询在左边表中存在的数据,当然需要两个表中的键值一致。语法如
下:
SELECT 列名1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
3. right join:代表选择的是后面一个表的全部
同理,右连接将会以右边作为基准,进行检索。语法如下:
SELECT 列名1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
4.自连接
自连接顾名思义就是自己跟自己连接,参与连接的表都是同一张表。(通过给表取别名虚拟出)
5.交叉连接:不适用任何匹配条件。生成笛卡尔积
6、联合查询
说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能
UNION 去重复
UNION ALL 不去重复
– 中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN (‘CHN’ ,‘USA’);
SELECT * FROM city WHERE countrycode=‘CHN’
UNION ALL
SELECT * FROM city WHERE countrycode=‘USA’
示例1:以内连接的⽅式查询employee和department表,并且employee表中的age字段值
必须⼤于25,即找出公司所有部⻔中年龄⼤于25岁的员⼯。
mysql> select * from employee1 inner join department on
employee1.dep_id=department.id and age>25;
示例2:以内连接的方式查询employee和department表,并且以age字段的升序方式显示
mysql> select * from employee1 inner join department on
employee1.dep_id=department.id and age>25 and age>25 order by age asc;
示例3:以自连接的方式列出所有员工的姓名及其直接上级的姓名
/* 素材
CREATE TABLE emp (
empno int(4) NOT NULL,
ename varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
job varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
mgr int(4) NULL DEFAULT NULL,
hiredate date NOT NULL,
sai int(255) NOT NULL,
comm int(255) NULL DEFAULT NULL,
deptno int(2) NOT NULL,
PRIMARY KEY ( empno ) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO emp VALUES (1001, '甘宁', '文员', 1013, '2000-12-17', 8000, NULL, 20);
INSERT INTO emp VALUES (1002, '黛绮丝', '销售员', 1006, '2001-02-20', 16000, 3000, 30);
INSERT INTO emp VALUES (1003, '殷天正', '销售员', 1006, '2001-02-22', 12500, 5000, 30);
INSERT INTO emp VALUES (1004, '刘备', '经理', 1009, '2001-04-02', 29750, NULL, 20);
INSERT INTO emp VALUES (1005, '谢逊', '销售员', 1006, '2001-09-28', 12500, 14000, 30);
INSERT INTO emp VALUES (1006, '关羽', '经理', 1009, '2001-05-01', 28500, NULL, 30);
INSERT INTO emp VALUES (1007, '张飞', '经理', 1009, '2001-09-01', 24500, NULL, 10);
INSERT INTO emp VALUES (1008, '诸葛亮', '分析师', 1004, '2007-04-19', 30000, NULL, 20);
INSERT INTO emp VALUES (1009, '曾阿牛', '董事长', NULL, '2001-11-17', 50000, NULL, 10);
INSERT INTO emp VALUES (1010, '韦一笑', '销售员', 1006, '2001-09-08', 15000, 0, 30);
INSERT INTO emp VALUES (1011, '周泰', '文员', 1006, '2007-05-23', 11000, NULL, 20);
INSERT INTO emp VALUES (1012, '程普', '文员', 1006, '2001-12-03', 9500, NULL, 30);
INSERT INTO emp VALUES (1013, '庞统', '分析师', 1004, '2001-12-03', 30000, NULL, 20);
INSERT INTO emp VALUES (1014, '黄盖', '文员', 1007, '2002-01-23', 13000, NULL, 10);
INSERT INTO emp VALUES (1015, '张三', '保洁员', 1001, '2013-05-01', 80000, 50000, 50);
方法一:
mysql> select e.ename,m.ename boss_name from emp e
-> left join emp m on e.mgr=m.empno;
+-----------+-----------+
| ename | boss_name |
+-----------+-----------+
| 甘宁 | 庞统 |
| 黛绮丝 | 关羽 |
| 殷天正 | 关羽 |
| 刘备 | 曾阿牛 |
| 谢逊 | 关羽 |
| 关羽 | 曾阿牛 |
| 张飞 | 曾阿牛 |
| 诸葛亮 | 刘备 |
| 曾阿牛 | NULL |
| 韦一笑 | 关羽 |
| 周泰 | 关羽 |
| 程普 | 关羽 |
| 庞统 | 刘备 |
| 黄盖 | 张飞 |
| 张三 | 甘宁 |
+-----------+-----------+
15 rows in set (0.00 sec)
方法2:也可以使用IFNULL
mysql> SELECT e.ename, IFNULL(m.ename, 'BOSS') 领导
-> FROM emp e LEFT OUTER JOIN emp m
-> ON e.mgr=m.empno;
示例4:列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
方法1:
SELECTe.empno,e.ename,d.dname FROM dept d RIGHT JOIN (
SELECT e.empno, e.ename, e.deptno
FROM emp e
INNER JOIN emp m ON e.mgr = m.empno
WHERE e.hiredate < m.hiredate) e
ON d.deptno = e.deptno;
方法2:
mysql> SELECT e.empno, e.ename, d.dname
-> FROM emp e, emp m, dept d
-> WHERE e.mgr=m.empno AND e.hiredate<m.hiredate ANDe.deptno=d.deptno;
示例5:列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
mysql> SELECT *
-> FROM emp e RIGHT OUTER JOIN dept d
-> ON e.deptno=d.deptno;
7、子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。内部嵌套其他select语句的查询,称
为外查询或主查询
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 =、> 、<等
注意:
1、子查询要包含在括号内。
2、将子查询放在比较条件的右侧。
3、单行操作符对应单行子查询,多行操作符对应多行子查询
1、查询姓名和工资,要求工资=最低工资
mysql> select ename,sai from emp
-> where sai=(select min(sai) from emp);
2、查询出高于10号部门的平均工资的员工信息
mysql> SELECT * FROM emp
-> WHERE sai>(SELECT AVG(sai) FROM emp
-> WHERE deptno=10);
3、查询出比10号部门任何员工薪资高的员工信息
mysql> SELECT * FROM emp
-> WHERE sai>(SELECT MAX(sai) FROM emp
-> WHERE deptno=10) AND deptno =10;
mysql> SELECT * FROM emp WHERE sai >ALL(SELECT sai FROM emp
->WHERE deptno = 10) AND deptno = 10;
4、查询出比10号部门任意一个员工薪资高的所有员工信息 : 只要比其中随便一个工资都可以
mysql> SELECT * FROM emp WHERE sai >ANY(
->SELECT sai FROM emp WHERE deptno = 10)
->AND deptno ! = 10;
5、获取员工的名字和部门的名字 select后面接子查询
mysql> SELECT ename,(SELECT dname FROM dept d WHERE d.deptno =
e.deptno ) 部门名 FROM emp e;
6、也可以使用连接查询
mysql> select ename,dname from emp e left join dept d on
->e.deptno=d.deptno;
7、查询emp表中所有管理层的信息 from后面接子查询
mysql> SELECT * FROM emp e,(SELECT DISTINCT mgr FROM emp) mgrtable
->WHEREe.empno = mgrtable.mgr;
十二、SQL函数
1、聚合函数
聚合函数对一组值进行运算,并返回单个值。也叫组合函数。
COUNT(*|列名) 统计行数
AVG(数值类型列名) 平均值
SUM(数值类型列名) 求和
MAX(列名) 最大值
MIN(列名) 最小值
除了COUNT()以外,聚合函数都会忽略NULL值。
| 函数名称 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和、返回指定列的综合 |
| AVG | 求平均值,返回指定列数据的平均值 |
以下列举几个MySQL的面试题目
1、count(1)和count(*)
- 当表的数据量大些时,对表做分析之后,使用count(1)还要比使用()耗时多了!
从执行计划来看,count(1)和count()的效果是一样的。但是在表做过分析之后,count(1)会比count(*)的用时少一些(1w以内的数据量),不过差的不是很多。 - 如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很⼩的。
- 因为count(),⾃ 动 会 优 化 指 定 到 那 ⼀ 个 字 段 。 所 以 没 必 要 去 count(1), ⽤
count(),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
2.count(1) and count(字段)
两者的主要区别是
- count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
- count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
3. count(*) 和 count(1)和count(列名)区别
执⾏效果上:
- count(*)包 括 了 所 有 的 列 , 相 当 于 ⾏ 数 , 在 统 计 结 果 的 时 候 ,
不会忽略列值为NULL - count(1) 包 括 了 忽 略 所 有 列 , ⽤ 1 代 表 代 码 ⾏ , 在 统 计 结 果 的 时 候 ,
不会忽略列值为NULL - count(列名)只包括列名那⼀列,在统计结果的时候,会忽略列值为空(这⾥的空不是只空字符串或者0,⽽是表⽰null)的计数,即某个字段值为NULL时,不统计。
执⾏效率上:
列名为主键,count(列名)会⽐count(1)快
列名不为主键,count(1)会⽐count(列名)快
如果表多个列并且没有主键,则 count(1) 的执⾏效率优于 count(*)
如果有主键,则 select count(主键)的执⾏效率是最优的
如果表只有⼀个字段,则 select count(*)最优。
2、数值型函数
| 函数名称 | 作用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求平方根 |
| POW&POWER | 两个函数的功能相同 ,返回参数的幂次方 |
| MOD | 求余数 |
| CEIL&CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0-1之间的随机数,传入整数参数时,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
3、字符串函数
| 函数名称 | 作用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH | 计算字符长度函数,返回字符串的字节长度,注意两者的区别 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串的字母转换为大写 |
| LEFT(str,len) | 从左侧字截取字符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧截取字符串,返回字符串左边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符串 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序,若expr1小于而expr2,则返回-1,0相等则相反 |
| LOCATE(substr,str[,pos]) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
4、日期和时间函数
| 函数名称 | 作用 |
|---|---|
| CURTIME CURRENT_TIME() CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定⽇期时间的⽇期部分 |
| TIME | 获取指定⽇期时间的时间部分 |
| MONTH | 获取指定⽇期中的⽉份 |
| MONTHNAME | 获取指定⽈期对应的⽉份的英⽂名称 |
| DAYNAME | 获取指定⽈期对应的星期⼏的英⽂名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定⽇期对应的⼀周的索引位置值,也就是星期数,注意周⽇是开始⽇,为1 |
| WEEK | 获取指定⽇期是⼀年中的第⼏周,返回值的范围是否为 0〜52或 1~53 |
| DAYOFYEAR | 获取指定⽈期是⼀年中的第⼏天,返回值范围是1~366 |
| DAYOFMONTH和DAY | 两个函数作⽤相同,获取指定⽇期是⼀个⽉中是第⼏天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个⽇期之间的相差天数,如SELECT DATEDIFF(‘2007-12-31 23:59:59’,‘2007-12-30’) |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00,也就0秒 |
5、流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时返回 v1,当expr = false、null 时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回v2 |
| CASE | 搜索语句 |
流程控制函数的用法:
1、使用IF()函数进行条件判断
mysql> SELECT IF(12,2,3),
-> IF(1<2,'yes ','no'),
-> IF(STRCMP('test','test1'),'no','yes');
+------------+---------------------+--------------------------------------+
| IF(12,2,3) | IF(1<2,'yes ','no') |
IF(STRCMP('test','test1'),'no','yes') |
+------------+---------------------+--------------------------------------+
| 2 | yes | no |
+------------+---------------------+--------------------------------------+
1 row in set (0.00 sec)
2、、使用IFNULL()函数进行条件判断
mysql> SELECT IFNULL(1,2), IFNULL(NULL,10), IFNULL(1/0, 'wrong');
+-------------+-----------------+----------------------+
| IFNULL(1,2) | IFNULL(NULL,10) | IFNULL(1/0, 'wrong') |
+-------------+-----------------+----------------------+
| 1 | 10 | wrong |
+-------------+-----------------+----------------------+
1 row in set, 1 warning (0.00 sec)
IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的
值,如果不为
NULL 则返回第一个参数的值。
IFNULL() 函数语法格式为:
IFNULL(expression, alt_value)
3、、使用CASE value WHEN语句执行分支操作
CASE <表达式>
WHEN <值1> THEN <操作>
WHEN <值2> THEN <操作>
...
ELSE <操作>
END
将 <表达式> 的值 逐一和 每个 when 跟的 <值> 进行比较
如果跟某个<值>想等,则执行它后面的 <操作> ,如果所有 when 的值都不匹配,则执行else 的操作
如果 when 的值都不匹配,且没写 else,则会报错
4、使用CASE WHEN语句执行分支操作
mysql> SELECT CASE WHEN 1<0 THEN 'true' ELSE 'false' END;
+--------------------------------------------+
| CASE WHEN 1<0 THEN 'true' ELSE 'false' END |
+--------------------------------------------+
| false |
+--------------------------------------------+
1 row in set (0.00 sec)
单表查询和多表查询的作业联系题目
一、单表查询
素材: 表名:worker - 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-
7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-
2-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-
6-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六',
'1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-
12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`,
`姓名`, `出生
日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-
9-2');
1、显示所有职工的基本信息。
2、查询所有职工所属部门的部门号,不显示重复的部门号。
3、求出所有职工的人数。
4、列出最高工和最低工资。
5、列出职工的平均工资和总工资。
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、显示所有女职工的年龄。
8、列出所有姓刘的职工的职工号、姓名和出生日期。
9、列出1960年以前出生的职工的姓名、参加工作日期。
10、列出工资在1000-2000之间的所有职工姓名。
11、列出所有陈姓和李姓的职工姓名。
12、列出所有部门号为2和3的职工号、姓名、党员否。
13、将职工表worker中的职工按出生的先后顺序排序。
14、显示工资最高的前3名职工的职工号和姓名。
15、求出各部门党员的人数。
16、统计各部门的工资和平均工资
17、列出总人数大于4的部门号和总人数。
二、多表查询
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
2.为student表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市
海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌
平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州
市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新
市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门
市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡
阳市');
向score表插入记录的INSERT语句如下:
第五章 MySQL备份恢复
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);
3.查询student表的所有记录
4.查询student表的第2条到4条记录
5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
6.从student表中查询计算机系和英语系的学生的信息
7.从student表中查询年龄18~22岁的学生信息
8.从student表中查询每个院系有多少人
9.从score表中查询每个科目的最高分
10.查询李四的考试科目(c_name)和考试成绩(grade)
11.用连接的方式查询所有学生的信息和考试信息
12.计算每个学生的总成绩
13.计算每个考试科目的平均成绩
14.查询计算机成绩低于95的学生信息
15.查询同时参加计算机和英语考试的学生的信息
16.将计算机考试成绩按从高到低进行排序
17.从student表和score表中查询出学生的学号,然后合并查询结果
18.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
19.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
在这里有关于我的单表查询的其他文章的连接,含有答案,可以适合小伙伴们练习
这是多表查询的链接,需要的小伙伴也可以自取,同时也有答案和对应的补充知识点