摘要:本文整理自货拉拉实时研发平台负责人王世涛,在Flink Forward Asia 2022 平台建设专场的分享。本篇内容主要分为六个部分:
- Flink 在货拉拉的使用现状
- Flink 平台化
- 性能优化主题
- 数据准确性主题
- 稳定性主题
- 未来展望
点击查看原文视频 & 演讲PPT
一、Flink 在货拉拉的使用现状

从部署情况、任务使用、业务使用三个层面进行介绍。
- 部署上,我们覆盖了 4 个中心,3 条业务线,使用了混合云的部署方式。
- 任务使用上,我们支持 SQL 和 Jar 包,任务数达到 1800+。
- 业务使用上,我们覆盖了地图、数仓、风控等业务。
二、Flink 平台化
2.1 平台架构

货拉拉的平台是一个前后端的工程,前端支持 SQL 的在线编辑,后端会有 Flink backend 模块对 SQL 进行等价的改写和控制,然后向 Flink 引擎进行提交,我们支持多版本的提交。Flink backend 模块会对原生 Flink 中没有的特性进行适配和优化,这个会在后续介绍的性能优化主题中有所体现。
2.2 指标监控

首先介绍下链路调整的背景,链路调整之前的指标通过 Flink Report 发送到 Gateway,Prometheus 去采集,然后配置 grafana 进行可视化展示,其中 Gateway 和 Prometheus 是我们自己运维的。我们调整了指标采集链路,实现了 Flink Kafka Report 把指标发送到 Kafka,使用 Metrics Report 消费 Kafka 的指标把数据暴露给 Lala Monitor 采集。链路调整之后有以下优点:
- 可以使用新的 Flink 任务去消费 Kafka 的指标,进行预聚合,减少指标的上报量。
- 链路中的 Kafka 和 Lala Monitor 由公司的专业团队运维,可以减少在指标链路上的运维投入。
2.3 分区数据完整性可见性
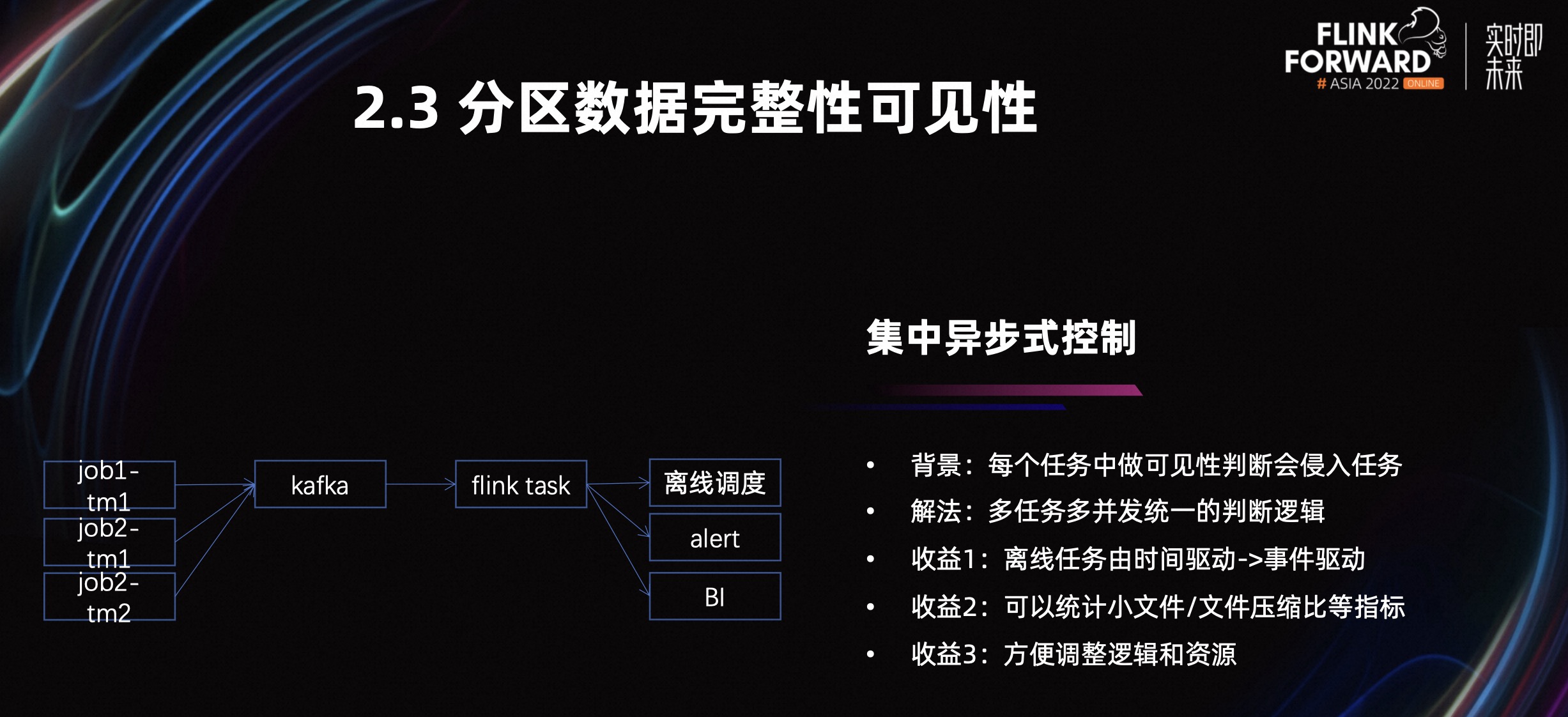
先介绍一下业务背景,我们的上游通过 Flink 任务消费 Kafka 的数据写到 Hive,下游会有离线任务定时调度进行清洗,如果上游任务出现问题或数据出现延迟,下游离线任务感知不到,就会出现数据遗漏的情况。
我们提出的方案是集中异步式的进行数据分区的完整性、可见性判断。在每个任务中把写外部服务的信息组织成事件的形式发送到 Kafka。没有使用指标的形式,因为指标会存在丢失的场景。
然后起一个 Flink 任务去消费 Kafka 事件进行可见性判断。如果可见性和完整性通过,我们会驱动下游进行 ETL。如果在规定时间内没有通过,我们会进行告警。同时我们会统计在写外部服务中存在的小文件和低压缩比的数据,进行配置看板,推动后续任务进行优化。
集中式的判断逻辑相对于在每个任务中侵入的实现逻辑,有以下优点:
-
方便调整逻辑。
-
方便调整资源。

除了上述提到的平台化工作,我们还在工程化部署和开发上做了以上工作。
三、性能优化主题
3.1 经纬度求行政区等归属场景
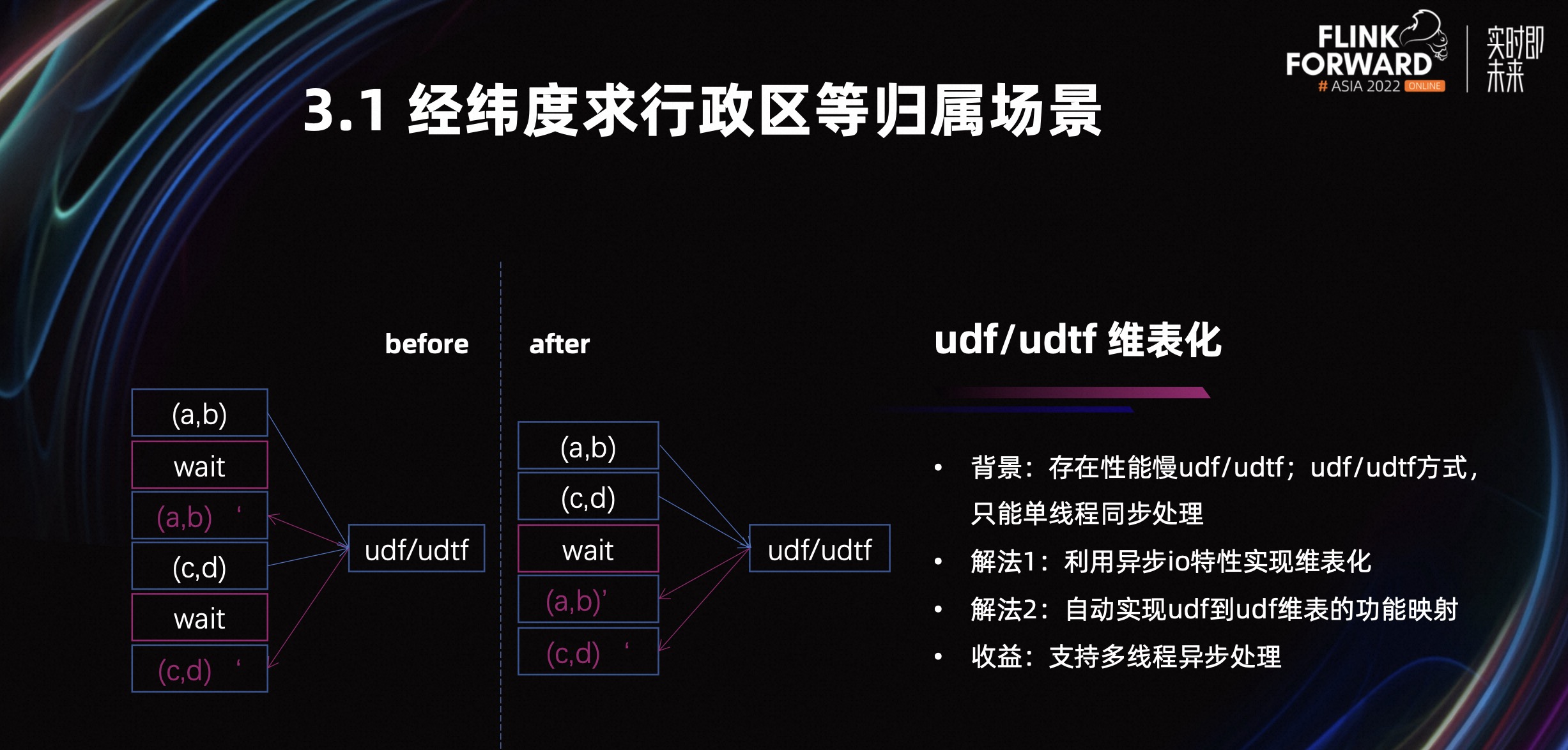
接下来介绍一下,我们在性能优化上做的一些工作。货拉拉是一家比较依赖 LBS 数据的公司,在 LBS 中存在根据经纬度求行政区等归属的业务场景。
优化前,我们使用 UDF 和 UDTF 去求值。UDF 和 UDTF 的求值过程是一个单线程的同步过程,我们的优化方式是把它变成多线程的异步过程。具体的方式是把 UDF 和 UDTF 映射成 Join,利用异步 io 的特性。由于 UDF 和 UDTF 不止一个,我们自动实现了这个功能的映射。
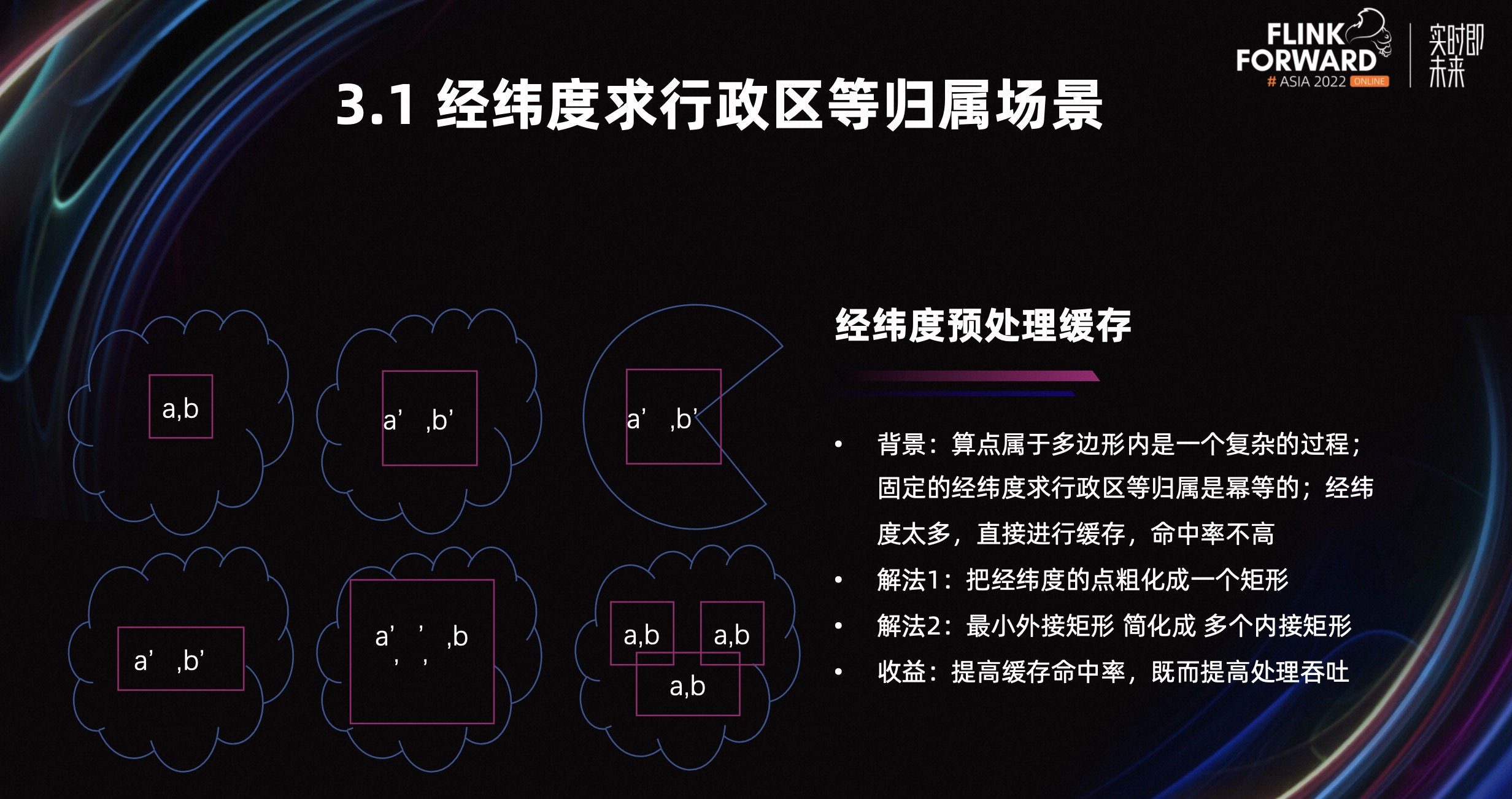
接下来再介绍一下,经纬度求行政区的一些业务特性。
判断一个点是否在多边形内,是一个复杂的过程,因为会涉及到 r-tree 和射线法精准判断的过程,另外,固定的经纬度求行政区是幂等的。这两个特性决定了我们可以使用缓存进行优化。但由于经纬度数据较多,直接缓存的命中率不高,所以我们需要提高缓存命中率。
我们的解决办法是,使用点粗化,对粗化之后的矩形进行缓存。我们从上图可以看到,图和矩形的一些关系。第一张图描述的是一个点在多边形内,第二张图描述的是一个点粗化成正方形后依然在多边形内,第四张图描述的是一个点粗化成长方形后还在多边形内。
如果不停的粗化,会形成一个最大的内接矩形,也就是第五张图。但我们没有求这个最大内接矩形,因为它会是一个比较耗性能的过程。我们退而求其次,求的是多个小的内接矩形。然后判断一个矩形是否在多边形内,不能使用之前的点判断。比如第三张图,它的部分面积不属于这个凹多边形内,所以我们需要换一个求值方式,我们用矩形的方式去求值。
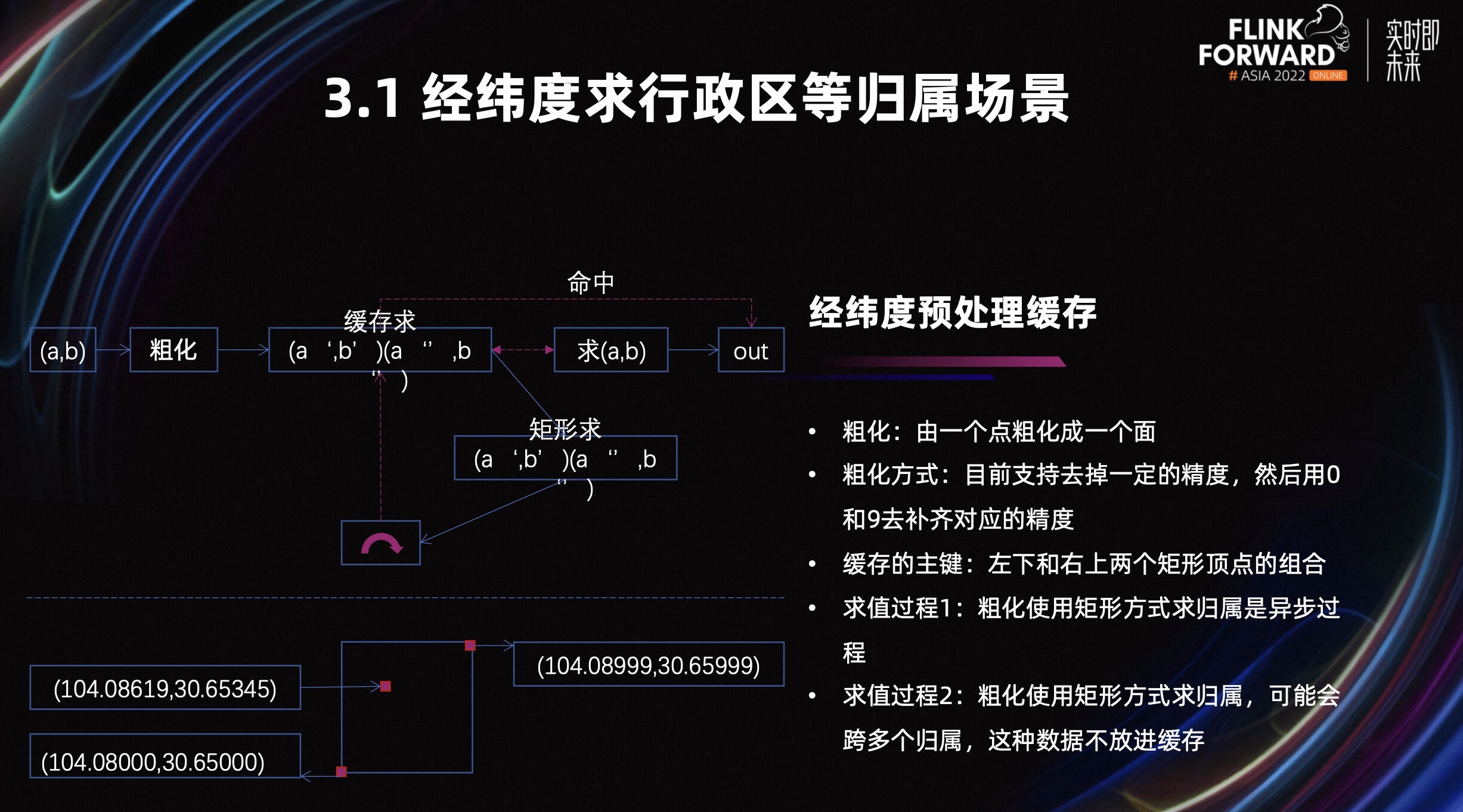
刚刚介绍了经纬度预处理缓存的可行性逻辑,接下来将介绍求值过程。
首先,粗化是由一个点粗化成一个面的过程,我们目前的粗化方式支持去掉一定的精度。看一下上图中左下角,这张图有三个点,中间的点是原始的经纬度数据,我们将后三位数据去掉补 0,就形成了左下角的顶点,去掉补 9 就形成了右上角的顶点,左下角的点和右上角的点就可以描述出一个矩形。缓存的主键是左下角的点和右上角的点的经纬度形组成的 key。
然后我们看一下上图左上角,这张图是求值过程的描述。首先一个经纬度点先进行粗化,之后我们去缓存中看是否命中。如果命中就直接输出,如果没有命中,我们就先用点的方式,快速输出结果,然后异步的用矩形的方式求它的归属。但这里有个判断,因为一个矩形可能会属于多个多边形,这种数据不会被放到缓存中。
3.2 Binlog 数据聚合函数计算场景
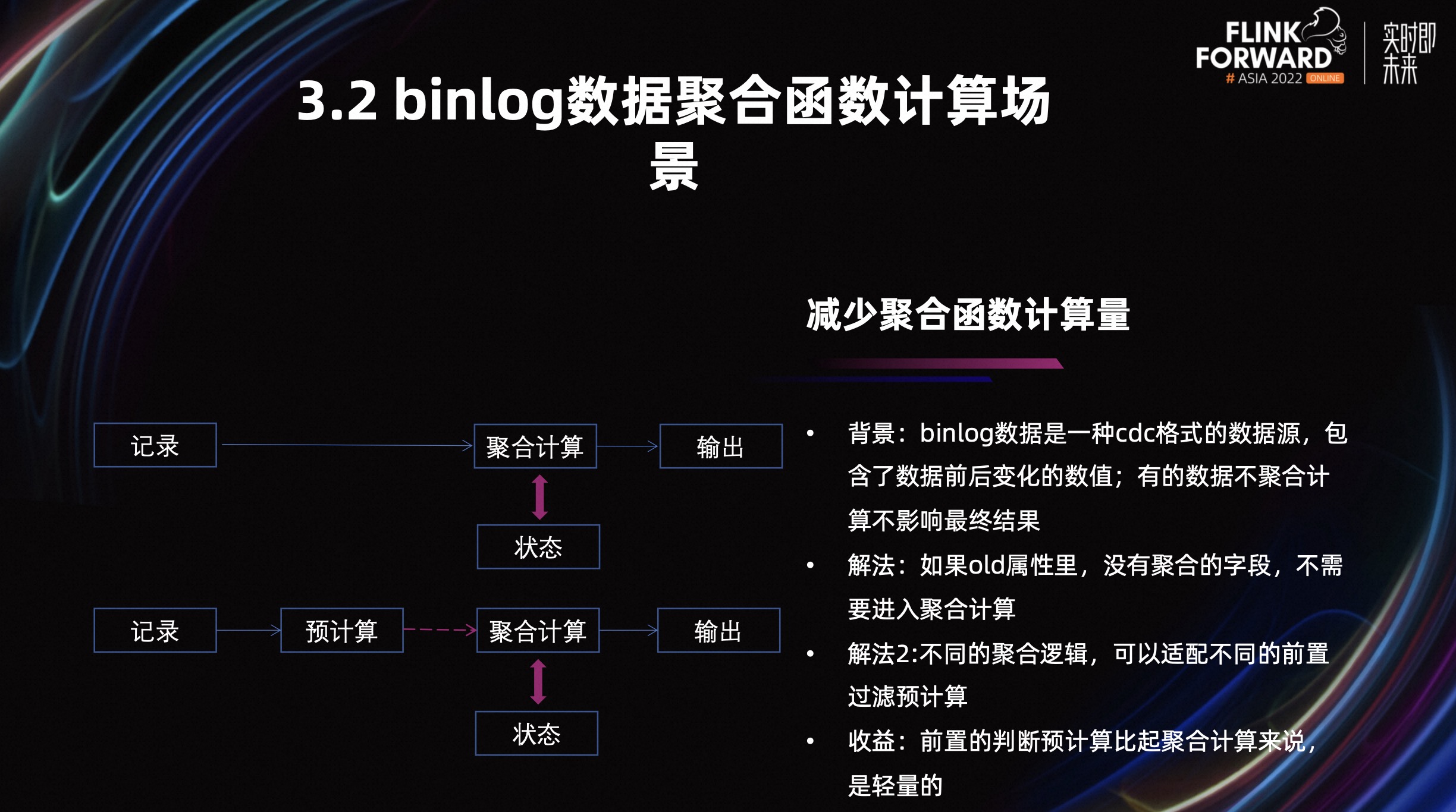
Binlog 是一个 CDC 格式的数据源,其中 old 属性描述了数据变化之前的值。聚合计算的特性是,它计算结果的值即使没发生变化也会计算,也会向下游输出。
如上图左侧所示,我们在聚合计算之前插入了一个预计算。新的聚合逻辑是根据 old 属性中是否带有预计算字段来判断。如果 old 属性中没有聚合字段,我们只需要进行预计算,然后把数据过滤掉,不需要进行聚合计算。因为聚合计算会去访问状态,同时产生回撤流。如果下游的计算比较多,回撤流的影响力还是比较大的。
另外,我们还对不同聚合逻辑的优化规则进行了进一步细化。比如求 max 聚合,如果这条数据是变小的情况,它也可以通过预计算快速过滤掉,没必要进行计算,所以我们的收益是通过比较轻量的预计算代替了比较重的聚合计算。
3.3 连续异步有序 Join
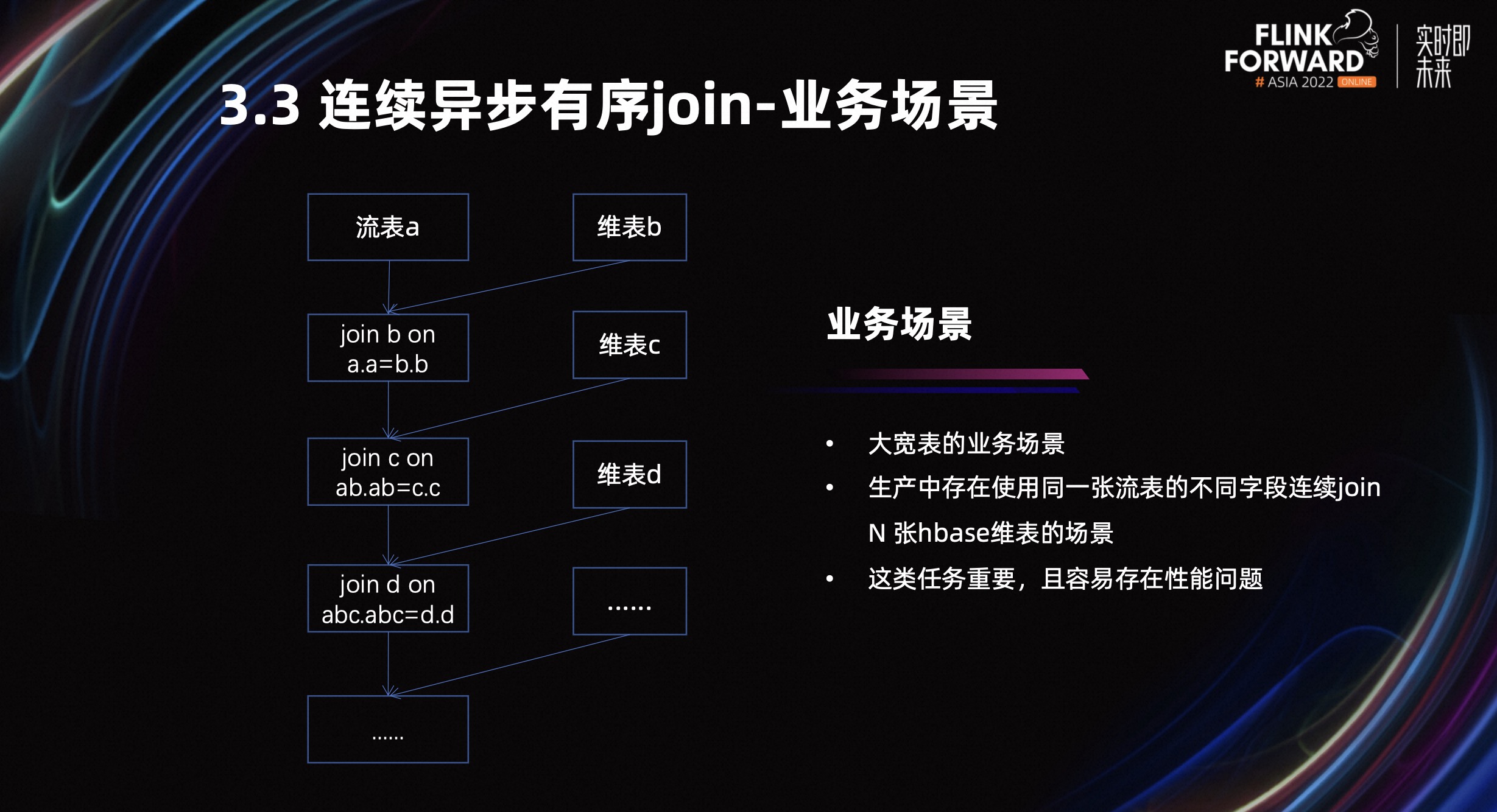
首先介绍一下业务背景,大宽表的业务场景是用流表去 Join 很多张维表,使用不同的 Join 字段去 Join,在我们业务中存在 Join 八张维表的情况。这类任务的特征是它在整体实时任务链路中比较靠前的位置,此外它还容易出现问题,所以我们有必要对这类任务进行优化。
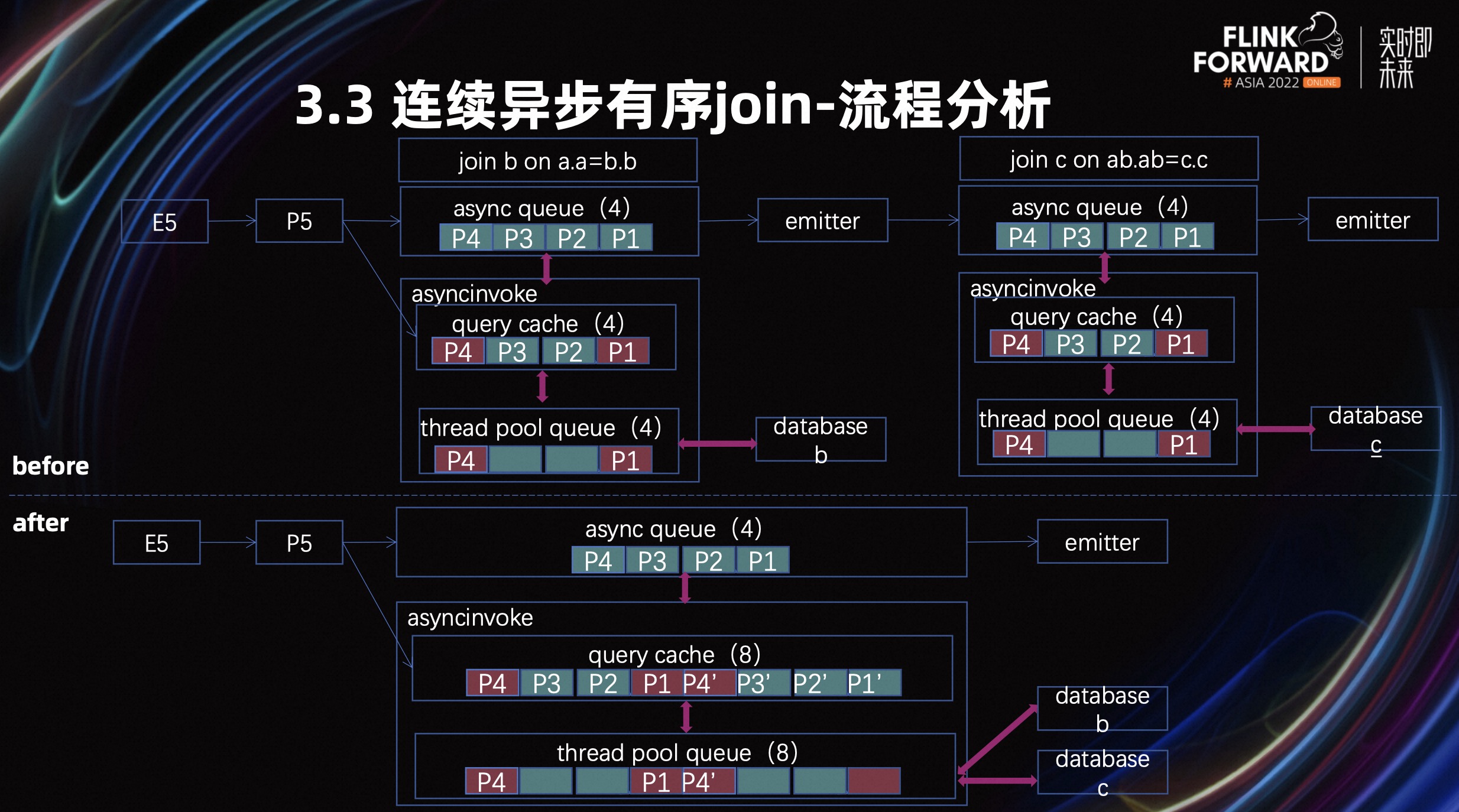
在介绍流程分析之前,我们先来介绍一下,异步 Join 中涉及的三个数据结构。
数据进入异步 Join 之前,它会放到一个异步队列的 queue 中。一般的异步请求会用缓存来提高查询效果,所以会涉及一个查询的 cache 缓存。如果缓存中没命中,它会使用外部的异步客户端或者自定义的线程池向外查询,所以这里还涉及到线程池的队列。
然后我们来描述一下两个 Join 下数据流转的过程。如上图有四条数据,第一个 Join 的 P1 和 P4 没有命中,这个时候它就会触发查询。P2 和 P3 命中,但由于有序的场景不会下发,要等 P1 有结果了,才会把数据整体下发给第二个 Join。第二个 Join 的逻辑也是一样,如果命中就在有序场景下等前面的数据,如果没命中,就触发查询。
我们优化后的流程是,把这两个 Join 的资源进行合并,同时把它们的逻辑也进行了一定的调整,查询缓存会由之前的两个小的缓存合成一个大的,查询的队列也会由两个小的合成一个非常大的,至于异步队列,可以根据需求进行调整。
查询的过程是,把 P1 的第一个 Join 和第二个 Join 的逻辑同时进行。也就是保证 P1 这条数据有序的情况下,P1 的第一个 Join 和第二个 Join 同步处理。

接下来介绍收益分析。因为它的场景比较多,所以我们就根据收益点分享几个场景。它的收益点可以分成三个,分别是串行变并行、在缓存时间和大小淘汰前拿到需要的数据、资源池变大变共享。
- 串行变并行:我们的逻辑进行调整之后,它会把先来的数据中不同的 Join 发出去,这样它的查询就会由之前的串行变成并行。
- 在缓存时间和大小淘汰前拿到需要的数据:如果在淘汰之前就能拿到数据,构造 Flink 的 row 对象,然后 row 对象就会存在异步队列的 queue 中。这个时候即使缓存丢了或者被其他数据冲掉了,也不会受影响,提高了数据的命中率。
- 资源池变大变共享:之前那种两个小的资源池,它的利用率是比较低的。比如可能会存在第一个 Join 中的查询资源很满,第二个 Join 中的查询资源很空的情况。如果进行了资源合并,就会提高它的利用率。通过这个流程调整,可以保证 P1 这条数据在多个 Join 下也能够整体有序。
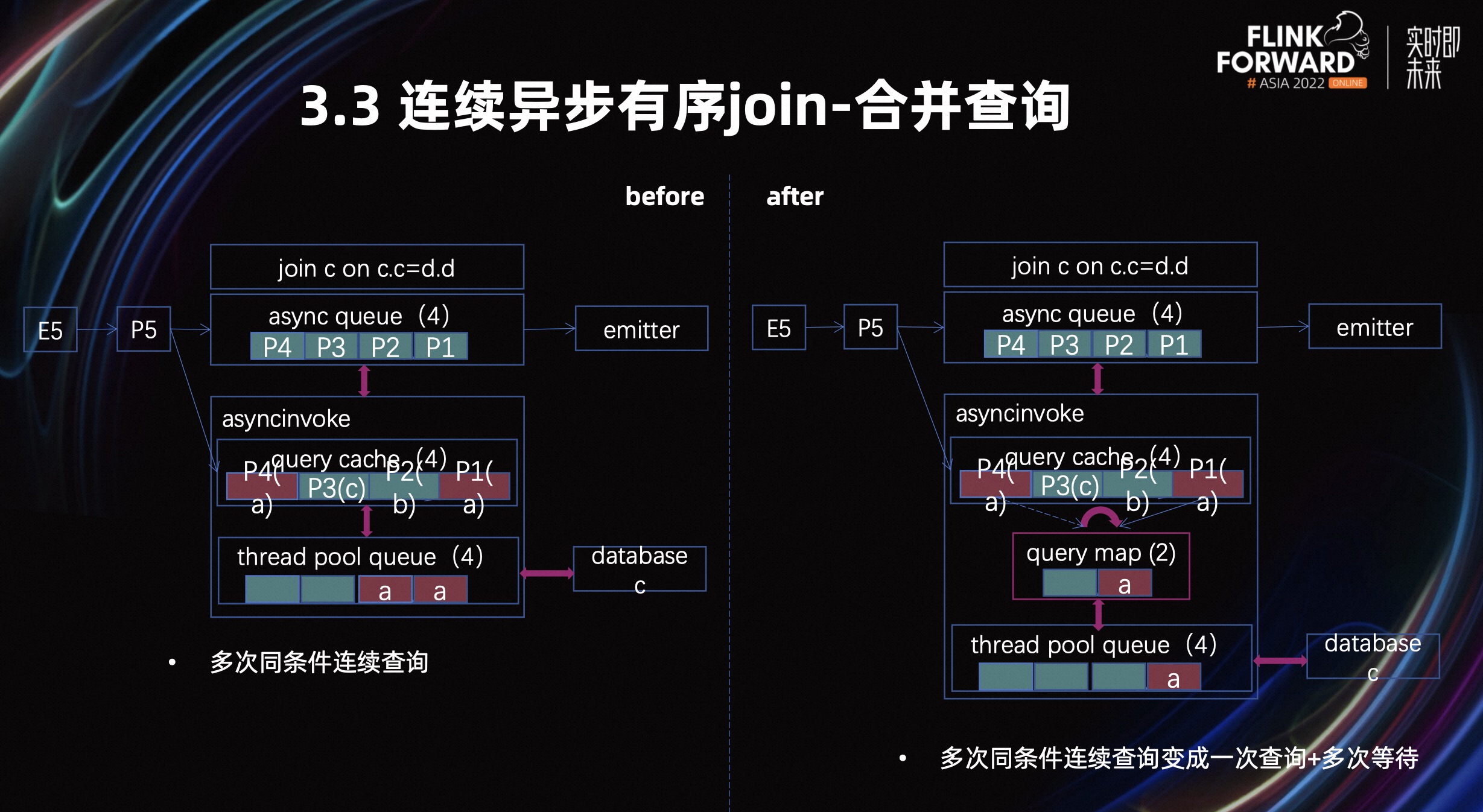
接下来介绍合并查询。优化之前它还是会涉及到三个数据结构,分别是异步队列的 queue,查询缓存的 cache,查询队列的 queue。但我们发现,如果 P1 和 P4 记录都是 a,且它们都没有命中的情况下,它们会去外部请求。这个时候会存在两条同样的条件记录去查外服务,然后我们可以加入比较小的查询缓存来进行缓存等待。
优化之后的流程是,P1 会去查询,P4 发现查询缓存中有 a 这条记录查询,它就不会去查询了,它会等 P1 有结果后直接返回。这样就会从之前的多次同条件查询变成了同条件的一次性查询+多次等待。
3.4 性能优化点

除了前面提到的性能优化点之外,我们还在计算、connector、用法上做了一些工作。
这里特别提一下在缓存上做的工作,前面提到的经纬度缓存其实叫面缓存,即只用两个点描述,但这两个点描述的是一个矩形。还有一个缓存叫线缓存,它主要用在时间的预处理中。比如需要根据 14 位的时间戳去求时间格式,优化前它会用时间格式格式化。其实格式化之后它的数据是有些特征的,它可以用 14 位的起点和终点的时间戳来描述区间。优化之后,我们只需要判断某个点是否在某个区间之内,就能快速读出它格式化之后的结果,而不用格式化的方式。
除了前面提到面缓存和线缓存,我们经常用的还有点缓存。点缓存我们做了两个点,其中一个是 keyby,它可以提高点缓存的命中率,同时我们把这个缓存也推广到了 Binlog 的数据处理中。因为我们经常会从 Binlog 中分解出某些表的数据进行处理,这个时候分解规则一般用正则,但正则的处理比较消耗性能。对于 Binlog 来说,一张库中它的表不会很多,但数据会很多。我们利用这个特征对已经正则匹配过的数据进行缓存。这样它就可以由之前的每次都去正则,变成了从缓存中判断的优化流程。
四、数据准确性主题
4.1 通用版本 Flink Per-partition watermark 问题解决方案
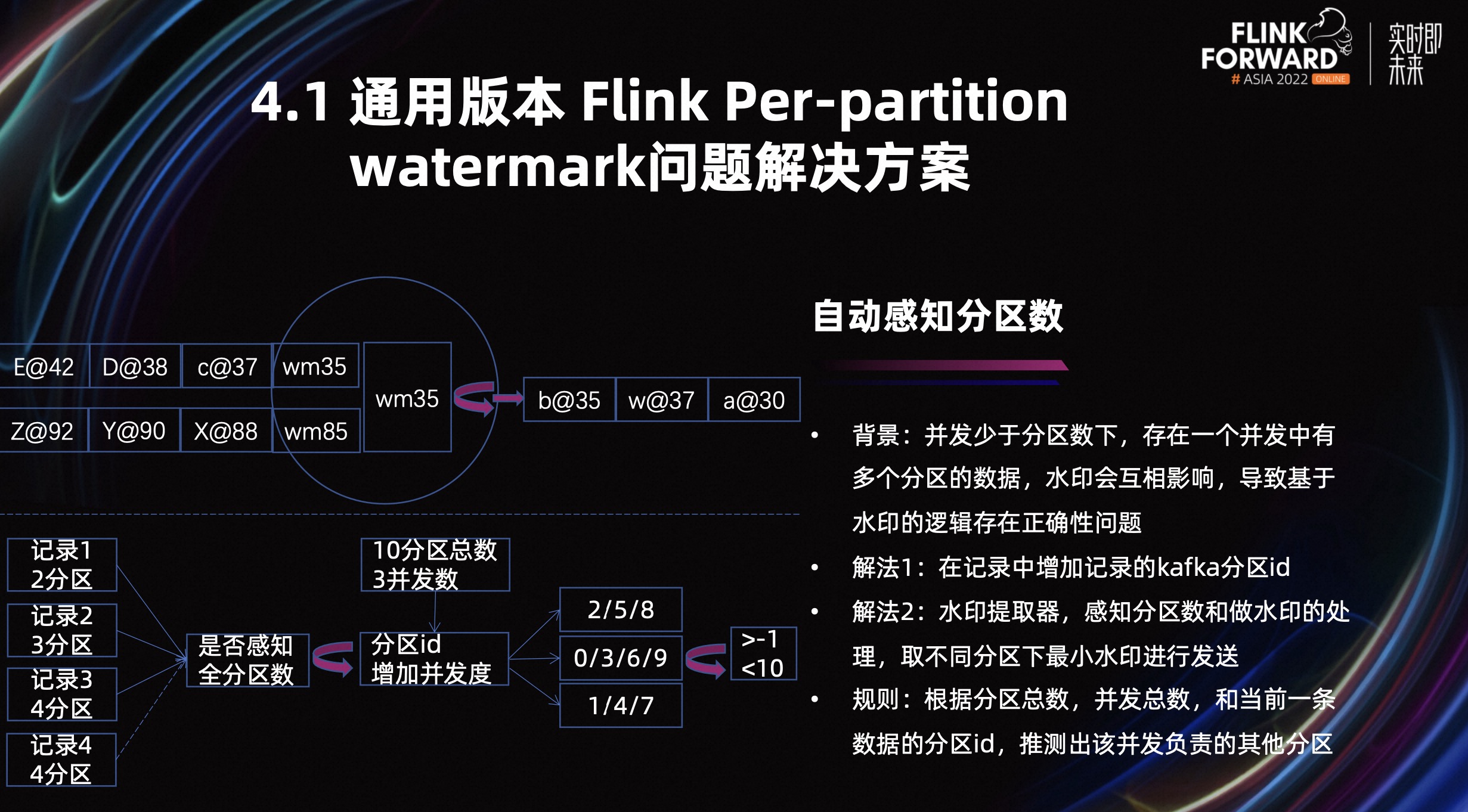
业务背景是,只要任务并发小于 Kafka 的分区数,就会存在单个并发中处理多个 Kafka 分区的场景,多个分区的水印会互相影响,就会导致基于水印的逻辑存在正确性问题。在高版本的开源版本中已经通过 Source 的架构调整解决了这个问题,但我们现在还有部分任务使用 1.9 版本,所以我们使用了自动感知分区和水印控制下发的流程来解决这个问题。
我们的自动感知分区是基于 Flink 和 Kafka 分配的机制来实现的。如上图左下角所示,第一条记录来自分区 ID=2 的记录,任务的并发数是 3,分区总数是 10。然后我们只要 add 这个分区 ID 的并发度,比如 2 加 3 等于 5,再加 3 等于 8,之后就不能再加 3 了,因为 Kafka 的分区上限是 10,当然也不能往下减,因为下限是-1,已经超过下限了。
所以通过一条记录就可以快速推断出并发所负责的分区是 2/5/8 三个分区。同理,也可以推断出分区 ID=3 的记录,所在的并发所获得的分区是 0/3/6/9 四个分区。得到这个分区数后,我们的水印控制逻辑需要等所有分区的水印都到齐,取最小的水印进行下发。
4.2 状态过期+延迟数据聚合数据覆盖
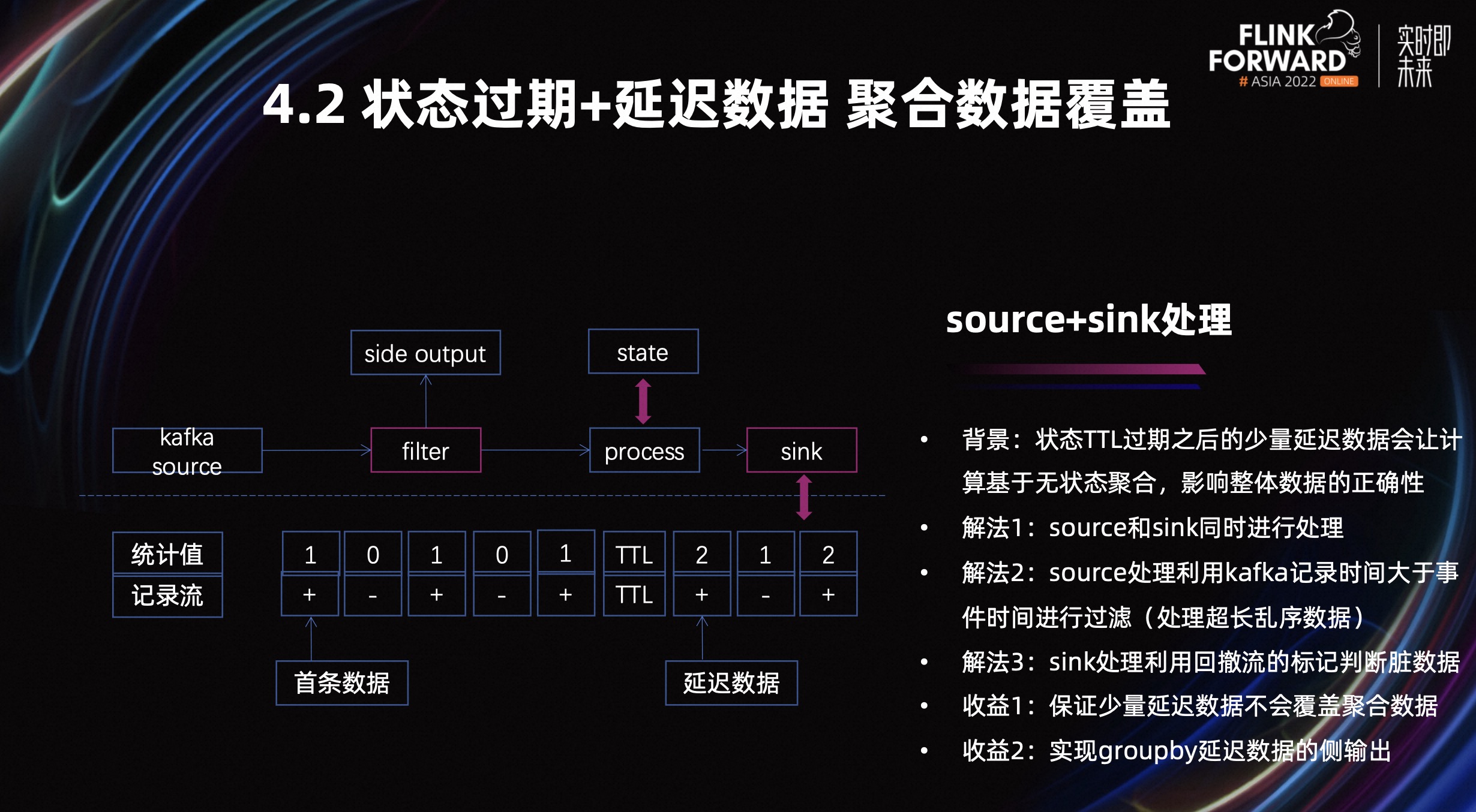
业务背景是,状态 TTL 过期之后还会存在部分延迟数据到来,这些数据会基于无状态聚合计算,计算之后对外部输出,会覆盖掉之前已经计算好的数据。
我们的解决办法是在 Source 和 Sink 同时进行处理,Source 主要是利用 Kafka 记录时间大于事件时间的特性,轻量化的进行过滤,处理超长乱序数据。Sink 是利用回撤流的标记进行统计,判断数据是否为脏数据,如果是脏数据,则不会对外输出,保证数据的准确性。
我们看一下上图左侧部分,回撤流有两个标记,true 和 false。假设 true 表示 1,false 表示-1,第一条数据的统计值是 1,然后每来一条数据就会产生一对回撤流,这个时候它的统计值就会变成 1/0/1/0。但 TTL 过后,再来一条数据的时候它的统计值就变成了 2/1/2/1。所以我们只要判断出现 2/1/2/1 之后的脏数据不对外输出,就可以实现这个功能点了。这样我们就会有两个收益,一个是可以保证少量延迟数据不会覆盖聚合数据,另一个是可以实现 groupby 延迟数据的侧输出。
4.3 数据准确性实现点

数据准确性除了上面提到的内容,我们还在数据过期、传递语意和数据乱序上做了一些工作。特别是数据乱序,我们前面提到了数据晚到,其实还有一种乱序叫超然数据,即发生的数据已经超过了今天,这种场景下,我们也进行了一些适配。
五、稳定性主题
5.1 多场景脏数据容忍
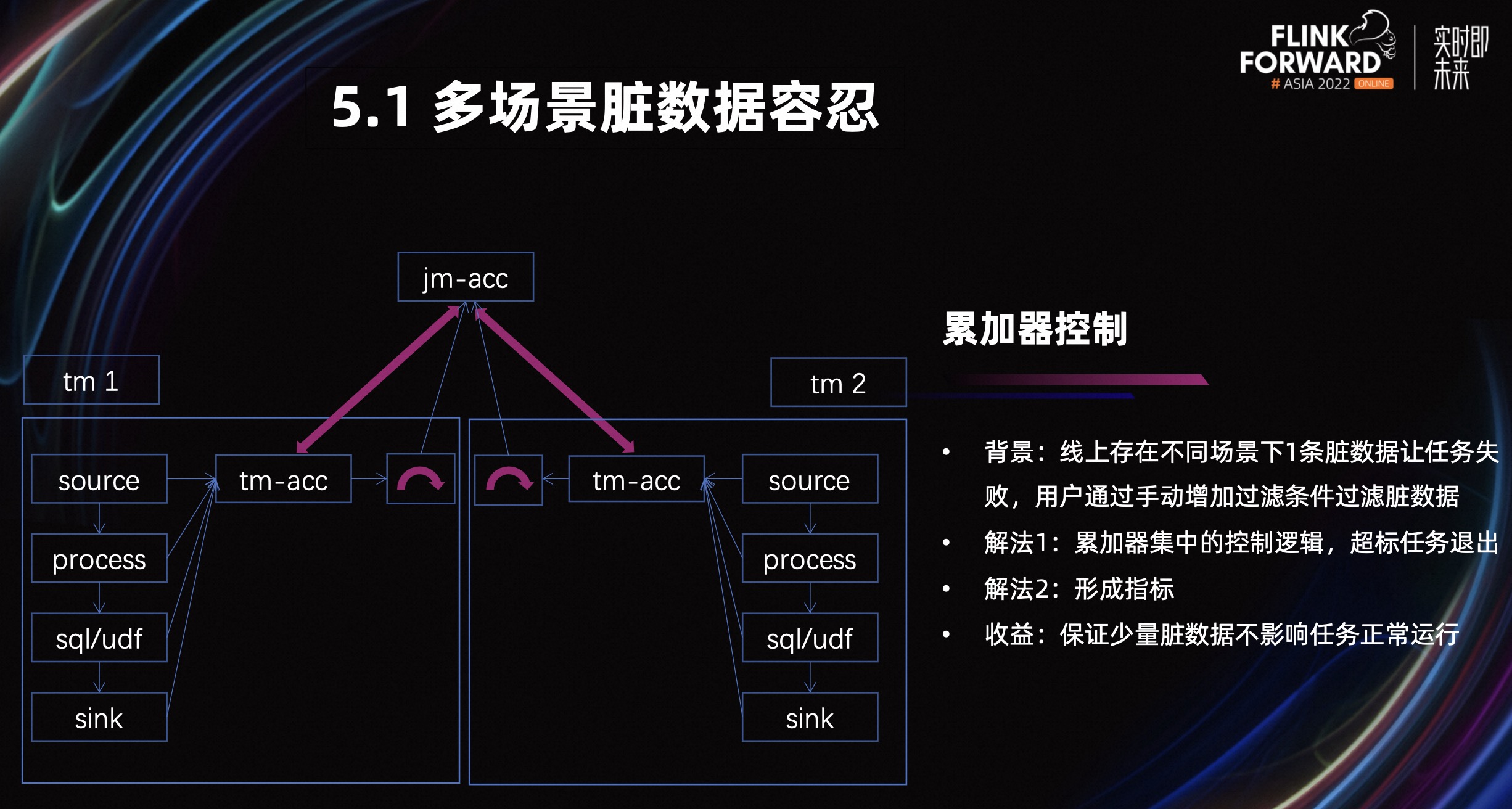
业务背景是,线上任务在不同场景下出现的一条脏数据,让任务失败。然后用户通过手动改 SQL 过滤这个数据,任务恢复。用户可以容忍一定的脏数据,所以我们设计了容忍机制来实现这个场景,这个机制使用累加器控制。
看一下上图,脏数据分布在不同的 TM 或者不同的处理环节中,只要出现脏数据,我们就会对这个全局累加器进行计数,当全局累加器的数值大于阈值,任务就会退出,同时我们还会对这个脏数据形成指标。我们的收益除了可以对指标进行提前预警,还可以保证少量的脏数据不会让任务失败,可以正常运行。
5.2 Sink 稳定性
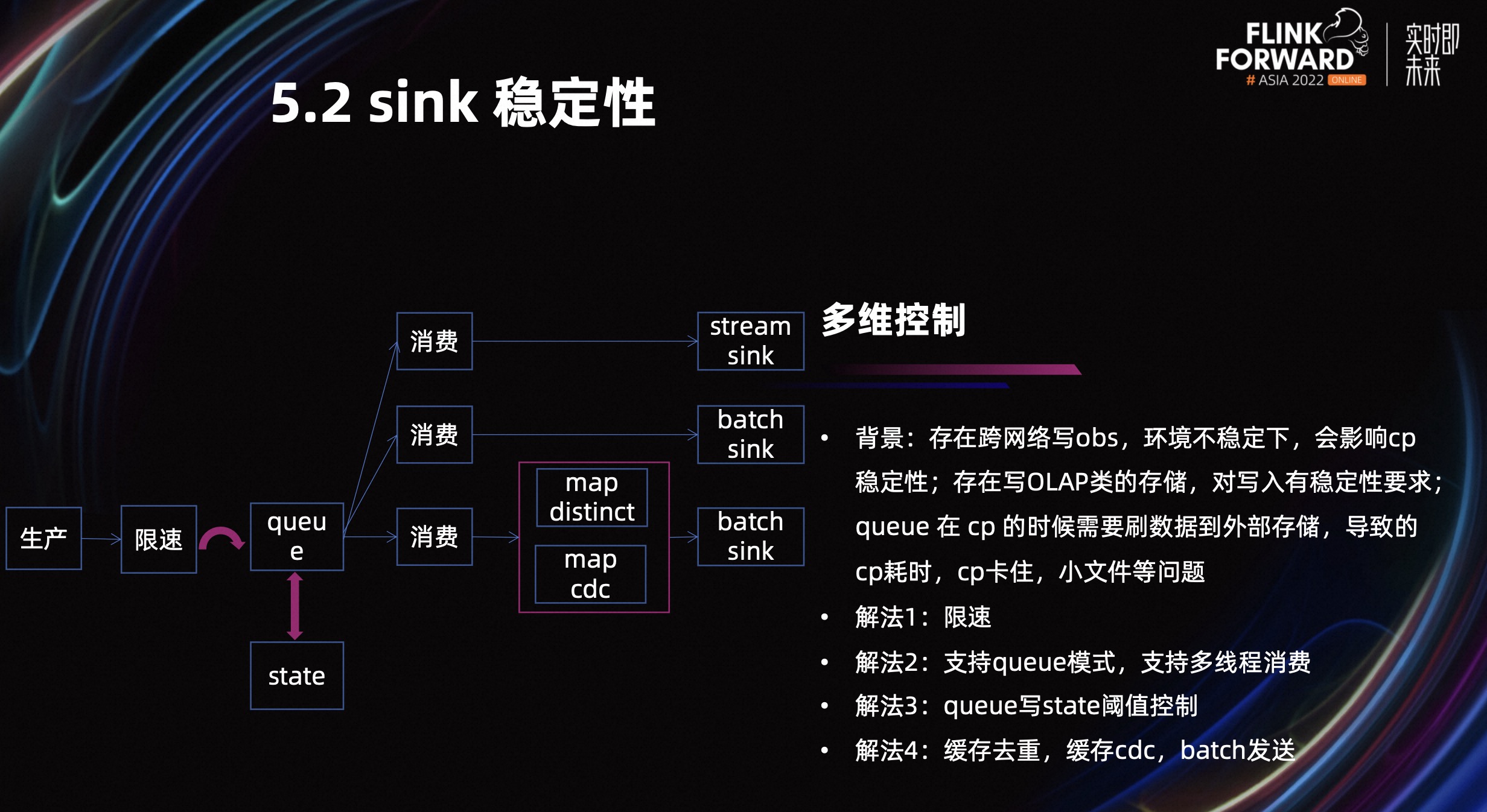
前面介绍过我们使用的是混合云的部署方式,所以会存在跨网络写的情况。我们会写 OBS,也会写 OLAP 引擎,OLAP 引擎对写入要求有一些需求,基于此我们的解决方法有以下四个:
- 第一个,我们会加限速逻辑,保证突发流量,不会对网络和外部服务的冲击。
- 第二个,我们引入了 queue 生产者、消费者的模式。保证在外部服务不稳定的情况下,先把数据缓存在 queue 中,另外 queue 还支持多线程消费。
- 第三个,queue 会存在一个问题,就是在 cp 时,为了保证数据不丢,一定会把 queue 中的数据强刷到外部服务。我们做了一个阈值刷状态,即如果 queue 里的数据比较少,强刷会造成外部小文件或者外部服务事务比较多的情况。所以我们会想把它临时写成状态,后面再从状态恢复,先让 cp 快速完成。
- 第四个,Sink 如果对外部服务写的不好情况,也会让外部不稳定。外部服务不稳定,会导致一个任务或多个任务也不稳定,所以我们在写外部服务上做了一些优化:
- Batch 发送,即不是来一条发一条。
- Batch 去重,特别是对 kv 型,我们只要保留最新的 kv 发送即可,中间累计的数据没必要发送。
- CDC 发送,即上一批次已经发送过数据,这一次批次又形成了同一个数据。对于外部服务来说,这个数据插入与否都不会对结果造成影响,所以这种情况,我们不发送数据。

稳定性上除了前面介绍的内容,我们还在数据问题、环境问题和用法问题上做了一些工作。特别强调一下动态 cp 的这个功能,Flink 提供的 cp 机制是固定的,但在某些场景下我们希望它能做动态,比如在追数据的时候,我们希望 cp 可以调长或者暂时不做,等数据追完再做。还有一个场景是我们在写 Hive 之类的分区文件时,希望在整点后快速把 cp 做完,把数据先刷到外部去,形成快速的完整性,也就是做了一个动态的 cp 调整。
六、未来展望

未来我们将从资源、开发、周边三个方面进行探索:
- 资源方面,我们将推进 Flink on K8S 和 New StateBackend 的预研和投入。Flink on K8S 更多解决的是计算层面的问题,New StateBackend 更多解决的是存储层面的问题。这两个特性相互结合才能够很好的解决云原生下存算分离的问题。
- 开发方面,我们将增强 Flink Backend 的 SQL 改写和控制能力,同时制定一些符合业务需求的 SQL 算子。
- 周边方面,我们将继续探索 CDC 和数据湖的一些工作。目前 CDC 已经有一些 Binlog 的使用方式,数据湖也有一些任务,后面将会继续探索。此外,我们还将基于之前的一些指标监控,以及在运维过程中产生的一些经验,形成智能运维的功能。减少平台开发人员的运维成本和新用户的学习、使用成本。
点击查看原文视频 & 演讲PPT