4. 渲染优化
渲染优化的目的是减少Draw Calls,减少渲染状态切换开销,降低显存占用,降低带宽和GPU负担。在讲解渲染优化之前,先了解渲染性能消耗点。
- Draw Call数量
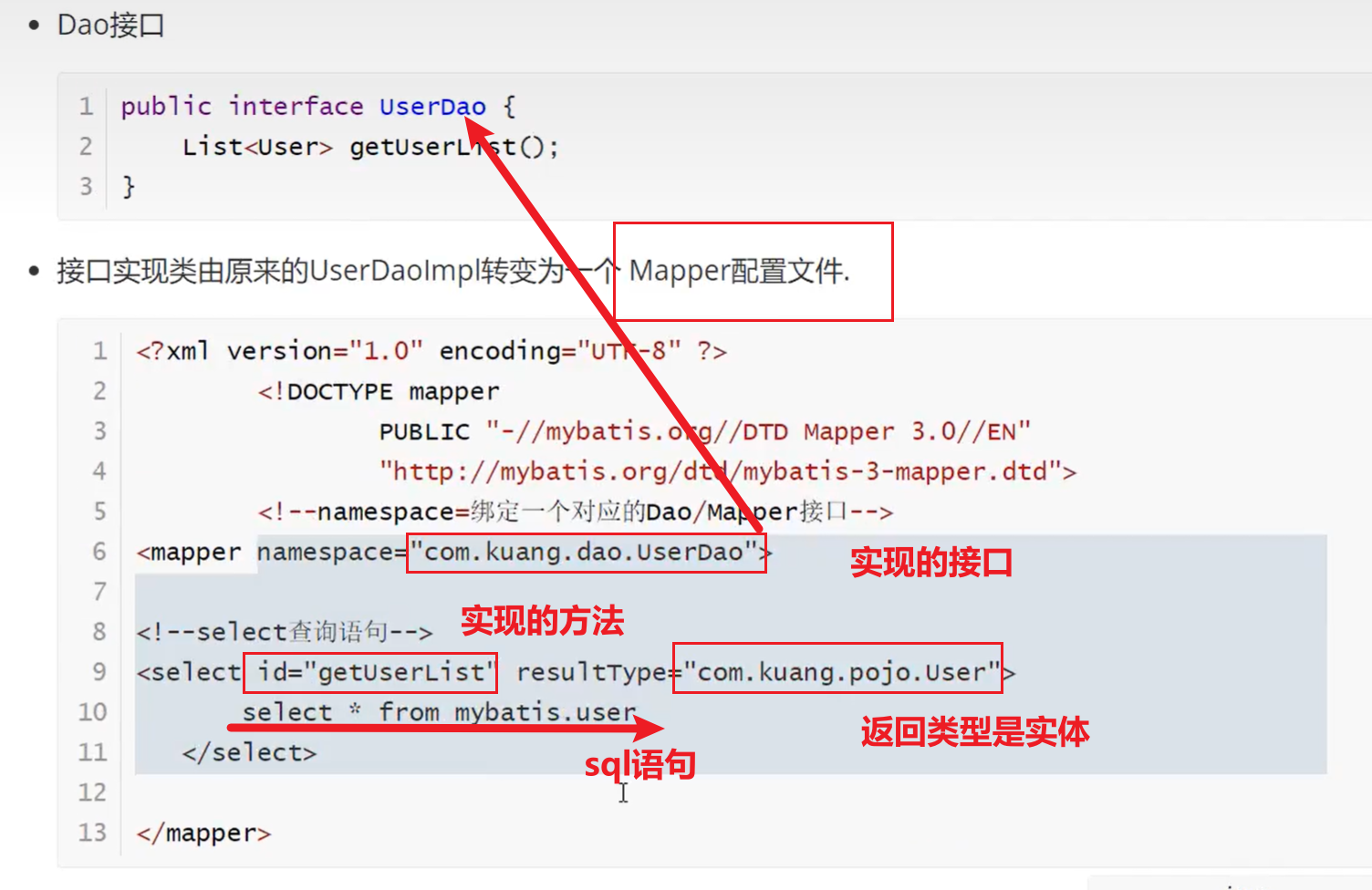
Draw Call有些引擎也称为SetPass Call。一个Draw Call就是游戏调用OpenGL/D3D等图形渲染的绘制API一次(如OpenGL的glDrawArray和glDrawElements)。一次Draw Call完整地跑完了整个渲染管线(下图),期间要涉及的数据/状态/计算很多,绘制前会先创建各种GPU数据,还可能每帧更新这些数据,数据更新又涉及到带宽。
所以,每帧Draw Call数量是衡量渲染性能的关键指标。
- 渲染状态切换
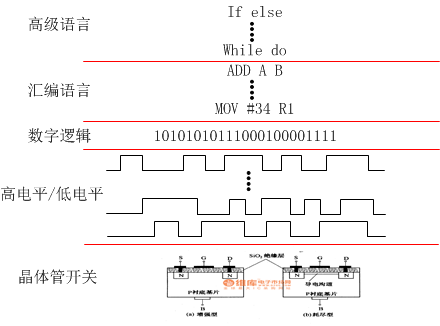
每次Draw Call前会对图形渲染层设置一系列的渲染状态,如是否开启深度测试/是否开启Alpha Test/是否开启Alpha Blend等等。这些状态通过图形渲染的驱动层最终应用到GPU中(下图)。
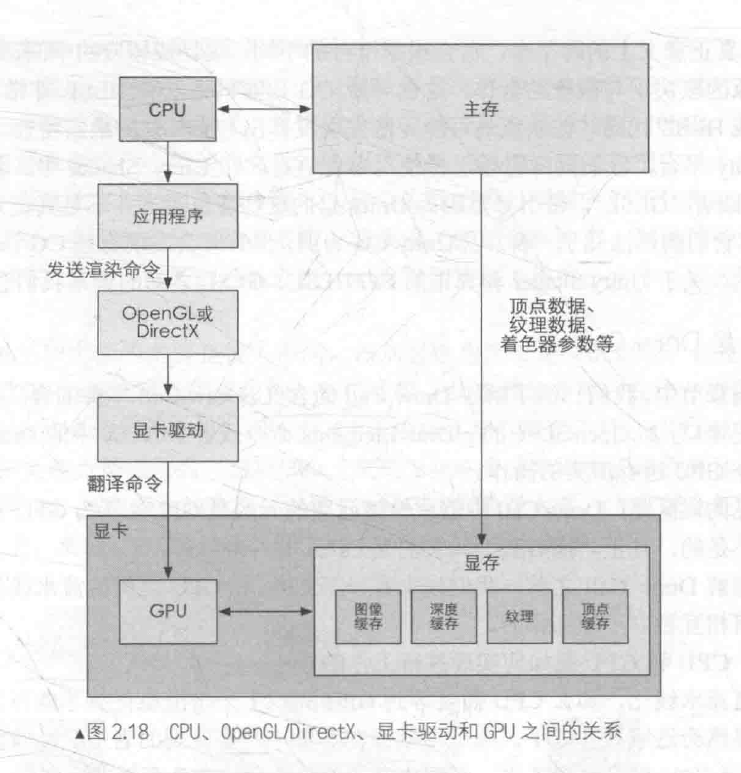
从上图可以看到,应用程序(游戏)发送的渲染指令,会经过OpenGL/DirectX等图形层和显卡驱动层,最终才能应用到GPU硬件。由于当代显卡驱动做了很多工作:状态管理/容错处理/逻辑计算/显存管理等等,属于重度封装,会消耗较多性能。所以,尽可能减少状态切换,是优化渲染性能的重要措施。
- 带宽负载
此处的带宽是指CPU经过主板总线传输数据到GPU的能力,单位通常是GB/s。当然GPU也可通过总线传输数据到CPU,但传输能力远远低于CPU到GPU。
广义的带宽还包括GPU和显存之间,GPU各部件之间的数据传输。
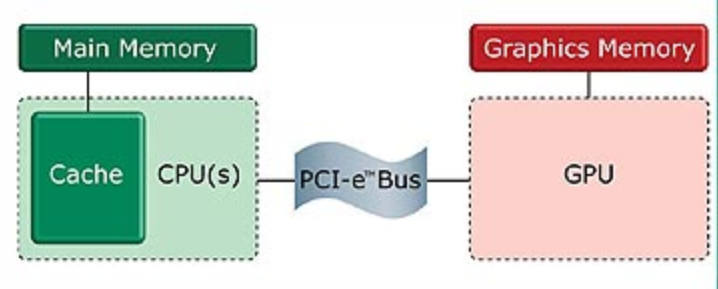
上图所示,CPU和GPU通过PCI-e总线相连,它们之间的传输能力是有上限的,这个上限就是带宽。如果绘制需要传输的数据大于带宽(即带宽负载过高),就会出现画面卡顿/跳帧/撕裂/延迟/黑屏等等各种异常。
- 显存占用
显存即显卡的内存,是集成在GPU内部的专用内存。通常用于存储顶点/索引/纹理/各种Buffer等数据。如果游戏显存占用过高,便会出现显存分配失败,导致画面异常甚至程序崩溃。
- GPU计算量
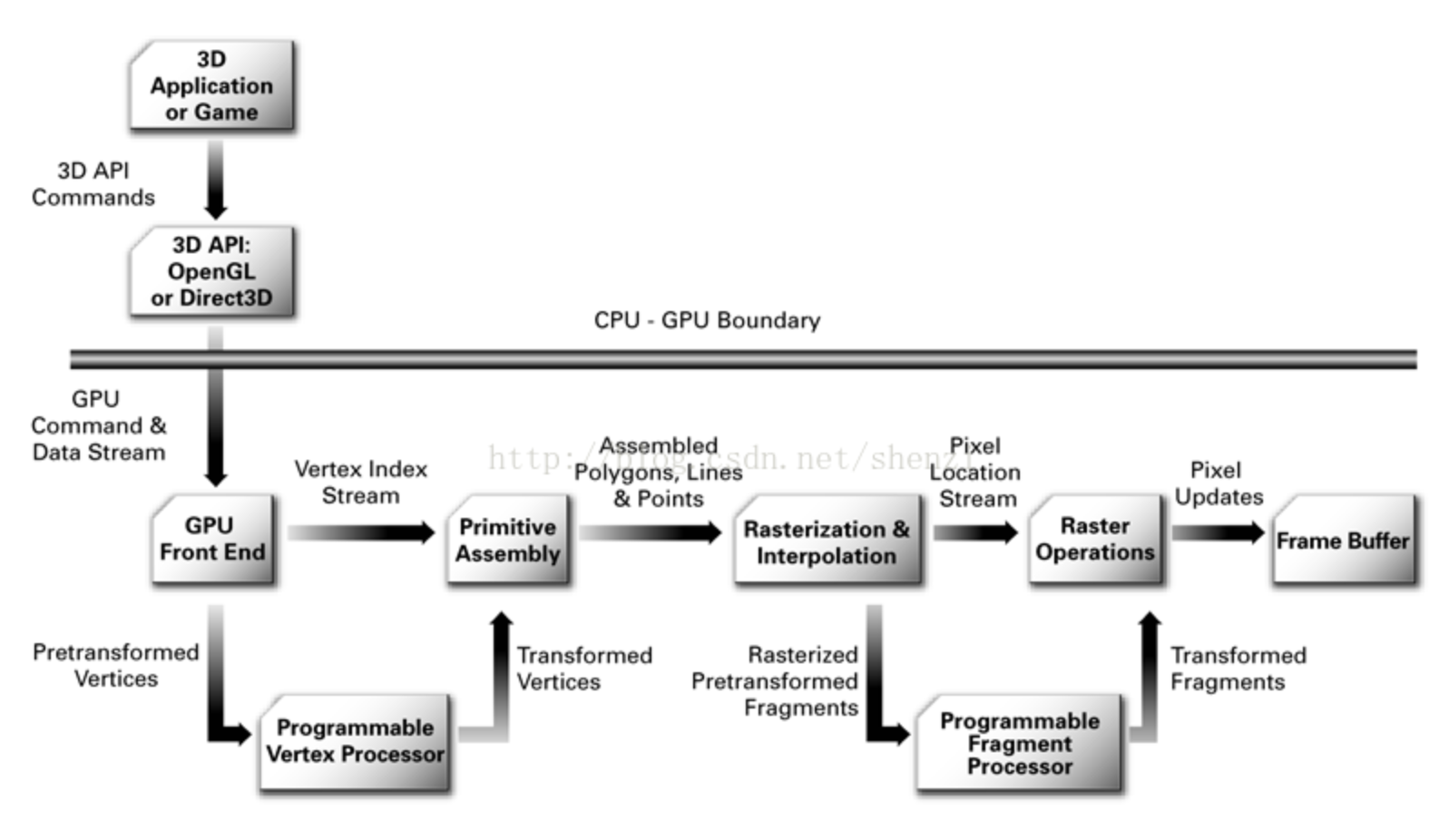
现代显卡基本都支持可编程渲染管线,涉及Vertex Shader/Geometry Shader/Fragment Shader(下图),还涉及光栅化/片元操作。所以,如果Shader过于复杂或者片元过多,会极大提高GPU计算量,降低渲染性能。
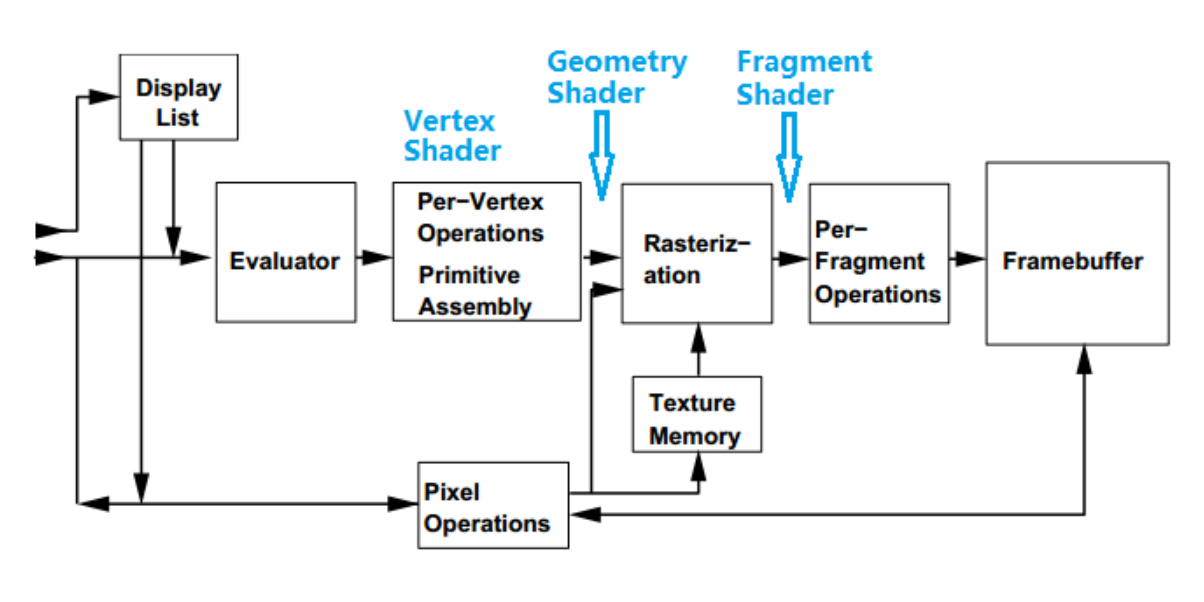
了解渲染具体开销后,就可以用下面的方法着手优化。
4.1 合批(Batch)
合批(Batch)是将若干个模型合成一个模型,从而可以只调用一次Draw Call的优化手段。合批解决的是Draw Call数量问题。合批的条件是所有被合的所有模型都引用同一个材质,否正无法正常合批。
4.1.1 离线合批(Offline Batch)
离线合批就是在游戏运行前,先用工具把相关资源做合批处理,以减轻引擎实时合批的负担。适合离线合批的是静态模型和场景物件。如场景地表装饰面:石头/砖块等等。离线合批方式有:
- 美术利用专业建模工具合批。如3D Max/Maya等。
- 利用引擎插件或工具。如Unity的插件MeshBaker和DrawCallMinimizer,可以将静态物体进行合批。
- 自制离线合批工具。如果第三方插件无法满足项目需求,就要程序专门实现离线合批工具。
4.1.2 实时合批(Runtime Batch)
不同于离线合批,实时合批是游戏引擎在游戏运行期完成的。Unity引擎分为静态合批和动态合批。
-
静态合批(Static Batch)
符合静态合批的条件有两个:一是模型有Static标记(即物体是静态的,不能有移动/动画/物理等),二是引用同一个材质实例。为了提高静态合批的概率,尽可能将场景物件设为静态,并且类似的物件引用相同的材质。
-
动态合批(Dynamic Batch)
动态合批是针对可以运动的模型,但有更苛刻的要求,例如Unity要求:
- 模型少于300个顶点,少于900个顶点属性。
- 不能有镜像Transform。
- 使用同一材质实例(注意:是实例,相同的材质不同的实例,也是不行的)。
- 使用相同的光照图(Lightmaps)。
- 不能用多Pass Shader。
4.1.3 合批副作用
合批优化虽能降低Draw Calls,但也有副作用:
- 增加CPU消耗。需要消耗CPU计算将多个模型合成一个,还涉及材质排序和搜集等操作。
- 增加内存。需要额外开辟内存存储合成的模型。
- 合成的模型顶点数有限制。移动游戏通常用16位索引,若合成的模型超出16位无符号整数的范围,渲染会出现异常。





![[ Linux ] 进程信号递达,阻塞,捕捉](https://img-blog.csdnimg.cn/img_convert/dcda21a42163a97160a2c5354e5c5921.png)



![[附源码]Node.js计算机毕业设计宠物短期寄养平台Express](https://img-blog.csdnimg.cn/43e2893260ea4addac1878d6bf8cc0a9.png)