准备
- 配置环境
- 理解Python代码部分
- mxVision用户指南一份
步骤
-
案例的流程图:

-
图像输入和图像预处理
-
图像输入(appsrc插件)
通过python open和read到的图片数据,用SendData方法传入stream中,appsrc将数据发送给下游元件(图像预处理模块)

-
图像预处理
解码图像数据并resize到416x416像素大小,使用了mxpi_imagedecoder插件和mxpi_imageresize插件


-
-
人脸检测
使用了yolov4的模型,mxpi_tensorinfer、mxpi_objectpostprocessor和mxpi_distributor三个插件用来推理每张图片的人脸区域-
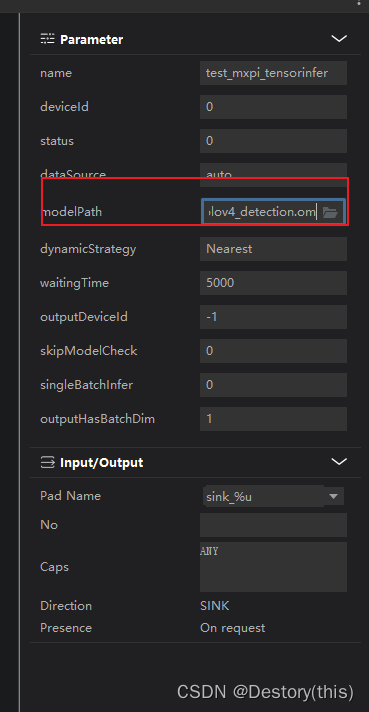
mxpi_tensorinfer 对输入的张量(tensor)进行推理
这里指定了推理模型om文件,输出推理结果。注意这里的路径是相对路径,需要在文件上右键复制出来,如果直接点击右边的文件夹浏览按钮,得到的绝对路径在服务器上运行会出错
-
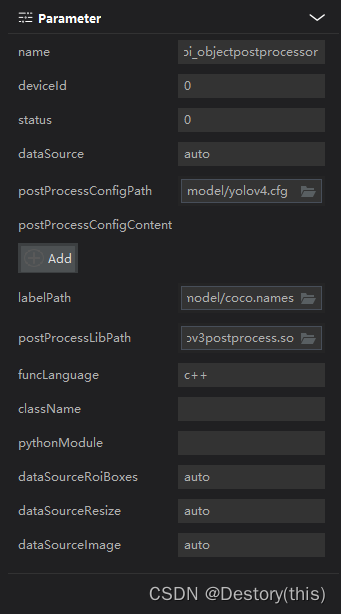
mxpi_objectpostprocessor对tensorinfer插件的输出结果进行后处理
这里需要指定的属性有:后处理配置文件路径postProcessConfigPath、后处理类别标签路径labelPath、后处理动态链接库so文件目录postProcessLibPath
-
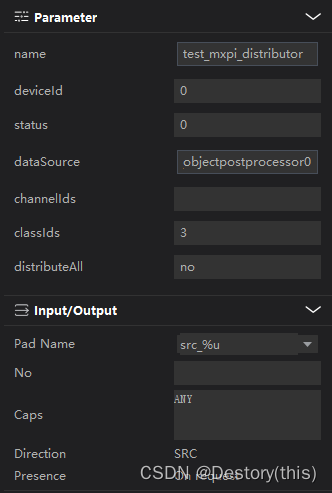
mxpi_distributor发送指定的数据
这里的配置发送的是mxpi_objectpostprocessor0插件,classId为3的数据
-
-
人脸抠像
此时已获得人脸检测结果,再用mxpi_imagecrop插件对图像进行裁剪,抠出人脸区域
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BSG44Uox-1670683842905)(C:\Users\Sfaad\AppData\Roaming\Typora\typora-user-images\image-20221210220004015.png)]](https://img-blog.csdnimg.cn/14b0b5f23d504f0dbf37879d23e2e188.png)
-
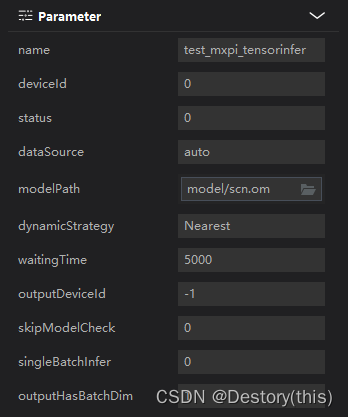
情绪分类
再次使用mxpi_tensorinfer加载另一个推理模型(scn.om),得到情绪识别结果
-
输出结果
结果输入到appsink插件,使用python代码GetResult和GetResultWithUniqueId可以从stream中获取该数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-10Vv1pJ6-1670683842906)(C:\Users\Sfaad\AppData\Roaming\Typora\typora-user-images\image-20221210220505767.png)]](https://img-blog.csdnimg.cn/bdd160d941924ca9a4e27d0d1234d10b.png)
至此,流程编排完成,此时需要点击下方的保存按钮,将可视化的流程图以json形式保存到pipeline文件中去,MindStudio对pipeline文件没有自动保存,也没有提示保存,希望可以优化一下
思考
-
从可视化流程编排上看,stream从appsrc开始,appsink结束,对应的python接口分别为SendData和GetResult;但是阅读完代码,发现没有调用过GetResult,而且在第二次推理结束后,理应对情绪分类结果进行后处理,但是也没有进行。此时才回想起来这段代码:
keyVec = StringVector() keyVec.push_back(b"mxpi_imagedecoder0") # 0.解码原图 keyVec.push_back(b"mxpi_distributor0_0") # 1.人脸位置 keyVec.push_back(b"mxpi_tensorinfer1") # 2.情绪分类结果 infer_result = streamManagerApi.GetProtobuf(streamName, 0, keyVec)原来此处的处理是直接从mxpi_imagedecoder0、mxpi_distributor0、mxpi_tensorinfer1三个插件中获取到数据,这就解释了上篇帖子中为什么使用GetResult接口反而无法正确得到结果
-
mxpi_distributor插件问题
- 按照文档说法,定义此插件的输出需要只配置classIds和dataSource属性或者只配置channelIds属性,也就是说有两种工作模式(文档中未提到如果三个属性都配置了会怎样输出),为什么直接不定义两个单独的插件,分别用来处理两种分发模式呢?
- classIds和channelIds都使用逗号(,)分隔每个输出端口,那么以此应当就能确定输出端口的数量,而在可视化流程编排中,老师的操作是给Input/Output类别下的No属性输入数值1并回车,节点上确实出现了一个输出端口,然后这个数值"1"在窗口上就不再显示了,令人困惑。
- 实际上按照直播课上的方法连接节点后,在保存时distributor报了错误(vertex illegal style);新建一个空的pipeline,直接复制示例中的可视化流程编排节点(毫无疑问时可以运行的),此时distributor的输出自动断开了,且无法连接到下一个插件上(提示不匹配)。就目前所掌握的知识无法定位该问题,在此仅作记录


![[ Linux ] 进程信号递达,阻塞,捕捉](https://img-blog.csdnimg.cn/img_convert/dcda21a42163a97160a2c5354e5c5921.png)



![[附源码]Node.js计算机毕业设计宠物短期寄养平台Express](https://img-blog.csdnimg.cn/43e2893260ea4addac1878d6bf8cc0a9.png)


![[附源码]计算机毕业设计基于人脸识别的社区防疫管理系统Springboot程序](https://img-blog.csdnimg.cn/c0d349988c734addbac9e643657b1bda.png)
