Linux 伙伴系统
- 前言
- 一、rmqueue
- 1.1 流程图
- 1.2 函数原型
- 1.3 通过PCP分配
- 1.4 大阶页面分配
- 二、__rmqueue
- 2.1 流程图
- 三、__rmqueue_pcplist
- 3.1 流程图
- 四、__rmqueue_fallback
- 五、__rmqueue_smallest
- 5.1 源码
- 5.1.1 get_page_from_free_area
- 5.1.2 del_page_from_free_list
- 5.1.3 expend
前言
本文从伙伴系统的页面分配函数 rmqueue() 开始,此函数作用是,从给定的zone中分配2^order的页面,在5.14.2中,rmqueue() 仅仅被 get_page_from_freelist() 调用,get_page_from_freelist() 更是重量级,由页面分配的核心函数 __alloc_pages() 所调用的。以上及下面所有讲到的函数的定义,均在mm/page_alloc.c 中定义。
而暂时仅仅着眼于伙伴系统的核心分配函数:rmqueue()
一、rmqueue
1.1 流程图

1.2 函数原型
static inline struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
preferred_zone,是根据gfp_flags算出来的,是在核心函数__alloc_pages中确定的,表示本次页面分配的请求,最先考虑从那个zone中进行分配,但是这个参数在本函数中不起关键作用,因为函数rmqueue的作用是从指定的zone中分配page,而这个指定的zone是第二个参数,前面讲过,get_page_from_freelist会调用rmqueue,而get_page_from_freelist作用就是遍历所有可用的zone,而preferred_zone是遍历过程的第一个被选中的zone.
zone, rmqueue正是从改zone的free_list中,选择page进行分配
order,指分配多少阶的page,与伙伴系统息息相关
gfp_flags, alloc_flags 都是分配配置,讲到再说
migratetype,迁移类型
1.3 通过PCP分配
/// 代码中省略了CMA相关的部分
if (likely(pcp_allowed_order(order))) {
page = rmqueue_pcplist(preferred_zone, zone, order, gfp_flags, migratetype,
alloc_flags);
goto out;
}
首先通过函数pcp_allowed_order检查是否需要通过PCP进行分配,所谓PCP即Per_CPU方式,即内核将变量缓存给每一个CPU上,不同的CPU都保留有自己的副本,这样不同的CPU可以并发的访问自己的这部分变量而无需上锁。
在之前的内核版本上,只有order==0,即分配1个页面是才会采用PCP方式进行分配,现在时代变了,当order<=3时都会使用PCP方式,pcp_allowed_order代码如下:
// 注意,以下代码我删除了关于透明大页的情况
static inline bool pcp_allowed_order(unsigned int order)
{
if (order <= PAGE_ALLOC_COSTLY_ORDER) // PAGE_ALLOC_COSTLY_ORDER == 3
return true;
return false;
}
如果 order<=3 , 那么将调用rmqueue_pcplis,从pcplist中分配page,此函数我们将在下一小节展开.
1.4 大阶页面分配
/// 代码中省略了CMA相关的部分
if (alloc_flags & ALLOC_HARDER) {
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);
ALLOC_HARDER,含义是尽力分配,因为为了保障其不会失败,将优先从MIGRATE_HIGHATOMIC中进行分配,MIGRATE_HIGHATOMIC是一种迁移类型,但是和迁移关系不大,你可以理解为专门为ALLOC_HARDER标志预留的一部分空间,如果失败,则调用__rmqueue函数走传统的路径进行分配。
问题在于,MIGRATE_HIGHATOMIC的page是怎么来的呢?因为在伙伴系统初始化的时候,会将所有的page定义为MIGRATE_MOVABLE,这是通过函数memmap_init_range实现的:
/**
...
* All aligned pageblocks are initialized to the specified migratetype
* (usually MIGRATE_MOVABLE). Besides setting the migratetype, no related
* zone stats (e.g., nr_isolate_pageblock) are touched.
*/
void __meminit memmap_init_range(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, unsigned long zone_end_pfn,
enum meminit_context context,
struct vmem_altmap *altmap, int migratetype)
{
然后MIGRATE_UNMOVABLE,MIGRATE_RECLAIMABLE类型可以通过后备列表的方式从其他由page的list上“偷”page:
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
但是显然不包括MIGRATE_HIGHATOMIC,其实此类型的page是通过函数reserve_highatomic_pageblock进行分配的,系统最多会给每个zone分配(zone_managed_pages(zone) / 100) + pageblock_nr_pages)个page,即zone管理的内存页的百分之一,并且保底是pageblock_nr_pages个,pageblock可以理解为一个4MB的页块,即对应伙伴系统的最大可分配页,page的迁移类型是按页块为单位进行修改的,修改页块迁移类型的函数是set_pageblock_migratetype。
那么reserve_highatomic_pageblock在什么时候被调用呢?是在get_page_from_freelist()函数之后,我在前言中讲过了。
因此逻辑是这样的,一旦有分配请求包含了ALLOC_HARDER,那么将会尝试从MIGRATE_HIGHATOMIC中申请,但是第一次肯定会失败,,于是就会从正常的流程中申请,成功后就会将所得page所在的pageblock整个加入到MIGRATE_HIGHATOMIC类型的列表中,但是并不能每次都能成功加进入,上线就是(zone_managed_pages(zone) / 100) + pageblock_nr_pages)个。
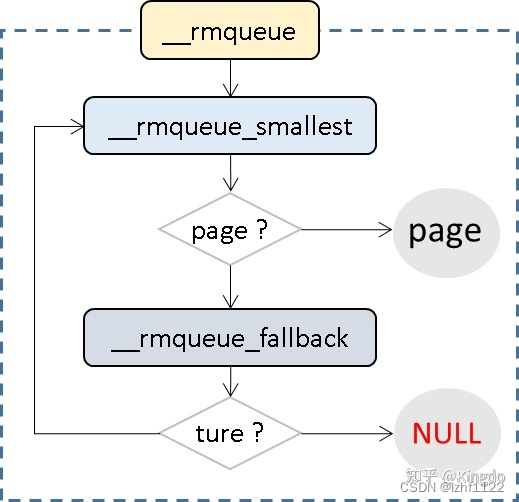
二、__rmqueue
从下面的流程图,可以看到,__rmqueue其实是在循环的执行__rmqueue_smallest,__rmqueue_smallest是真正从伙伴系统中那页面的过程,即对于伙伴系统分割大order,填充给小order过程的实现,也就是伙伴系统的最核心算法。
但是__rmqueue_smallest,只能从指定的迁移类型列表中拿页面,当该迁移类型页面不足时,就需要想其他的迁移类型借,我前面给出的那个二维数组:
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
就表示了,借页面的顺序,如MIGRATE_UNMOVABLE不足时,首先从MIGRATE_RECLAIMABLE中借,然后从MIGRATE_MOVABLE中借。
而__rmqueue_fallback的作用就是,如果能成功接到,就把页面从被借的list放到指定的迁移类型列表中,此时将返回true,然后再执行__rmqueue_smallest,去分割order,分配页面。如果借不到,那么只能返回NULL
2.1 流程图
三、__rmqueue_pcplist
rmqueue_pcplist主要作用是根据order的大小,选择对应的pcp_list,并在调用__rmqueue_pcplist获取page之前上锁,因此我们直接看__rmqueue_pcplist的实现.
3.1 流程图
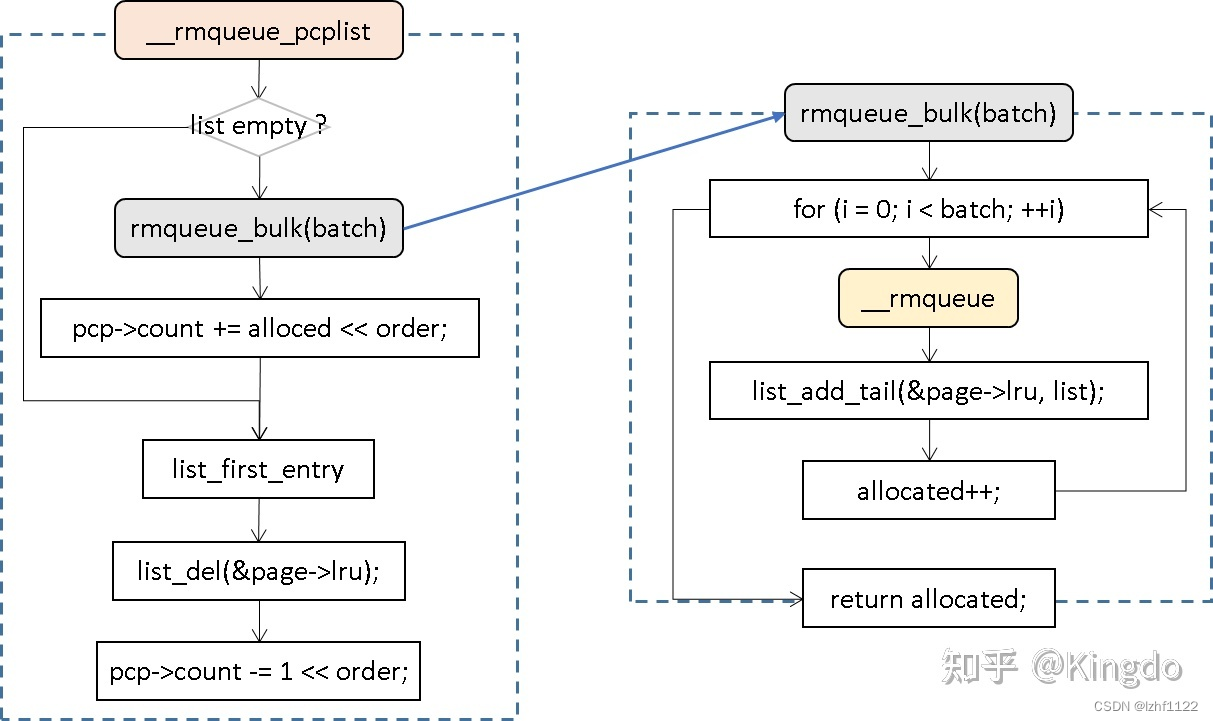
其实逻辑很简单,如果list为空,那么就调用rmqueue_bulk申请一批次的page填充到pcp_list中,主要就是这个逻辑。
而rmqueue_bulk同样也是调用__rmqueue实现的,那我我们现在来分析一下,__rmqueue的两个主要函数__rmqueue_fallback和__rmqueue_smallest
四、__rmqueue_fallback
此函数的作用是,当指定的迁移类型的列中中page不足时,从该迁移类型的后备列表中偷取空闲的page补充到指定的迁移类型列表中。并且系统初始化时,所有的page都是MIGRATE_MOVABLE类型.
而后被列表就是我们两次前面提到的:
/// 需要注意,没考虑CMA的情况
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
可以看到,MIGRATE_UNMOVABLE、MIGRATE_MOVABLE和MIGRATE_RECLAIMABLE是互为后备列表的.
这个函数很长,但是实际上东西不好说,其大原则就是,在偷取page的时候要尽可能把整个pageblock都偷过去,实在买办法也要尽可能偷大的order。
然后要修改整块pageblock的类型,如果不是整块偷的,那么就会出现混合的情况,即同一pageblock的page的位于不同的迁移列表。但是整块的pageblock的类型是统一的,基本上是谁多是谁的类型,比如偷取的部分order>一半,那么就要全部改成对应了的类型。
五、__rmqueue_smallest
5.1 源码
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = get_page_from_free_area(area, migratetype);
if (!page)
continue;
del_page_from_free_list(page, zone, current_order);
expand(zone, page, order, current_order, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
函数非常的短小,整个循环恰好符合了伙伴系统的核心思想,即一层层的的往下拆分,直到合适的order的page.
5.1.1 get_page_from_free_area
即直接从指定迁移类型的list中找到page,如果失败,则寻找的order++;
5.1.2 del_page_from_free_list
负责将其list中拿走,操作包括list_del,list的计数–等;
5.1.3 expend
expend 是负责拆分的函数,即如果从odrer较大的list中选择了一一组page进行拆分,那么拆分后剩余的page将被添加到较低order的list中,注意,我们只需要将每一组的page的首个page添加到free list中即可,如我要获取order0的page,但是是从order3的块中获取的:
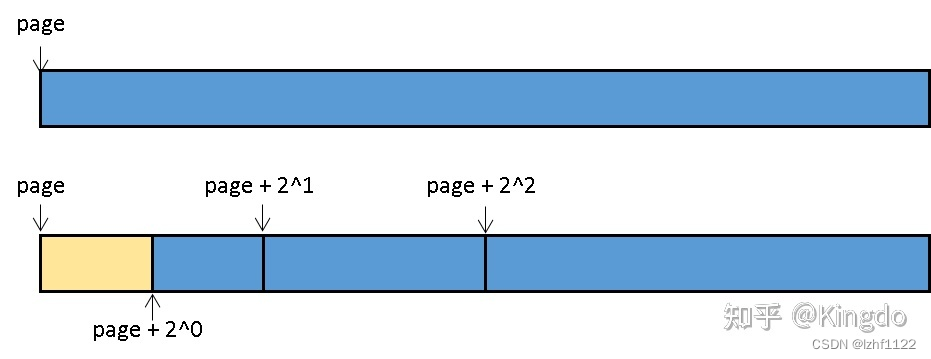
page指向的是order=3的块,page保存在伙伴系统order=3的free_list上,当我们需要以order=0返回page时,就需要把整个块拆分, 并以此将:
- page + 2 ^0 的page添加到 order-0 free_list
- page + 2 ^1 的page添加到 order-1 free_list
- page + 2 ^2 的page添加到 order-2 free_list
extend函数,就是做这件事