让我们来讨论什么是机器学习如下所示:
如果机器在给定任务中的性能随着经验的改善而改善,则可以说机器正在从过去的经验(数据馈入)中学习某些类别的任务。例如,假设一台机器必须预测客户今年是否会购买特定的产品,比如说“防病毒”。机器将通过查看以前的知识/过去的经验来做到这一点,即客户每年购买的产品的数据,如果他每年购买防病毒软件,那么客户今年也很有可能购买防病毒软件。这就是机器学习在基本概念层面的工作方式。
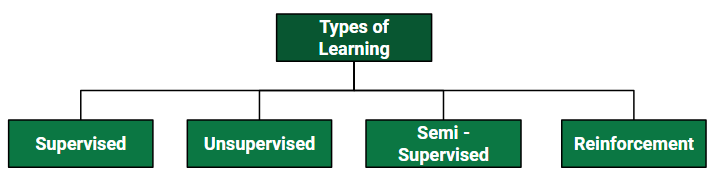
监督学习是指模型在标记的数据集上进行训练。带标签的数据集是同时具有输入和输出参数的数据集。在这种类型的训练和验证学习中,数据集的标记如下图所示。
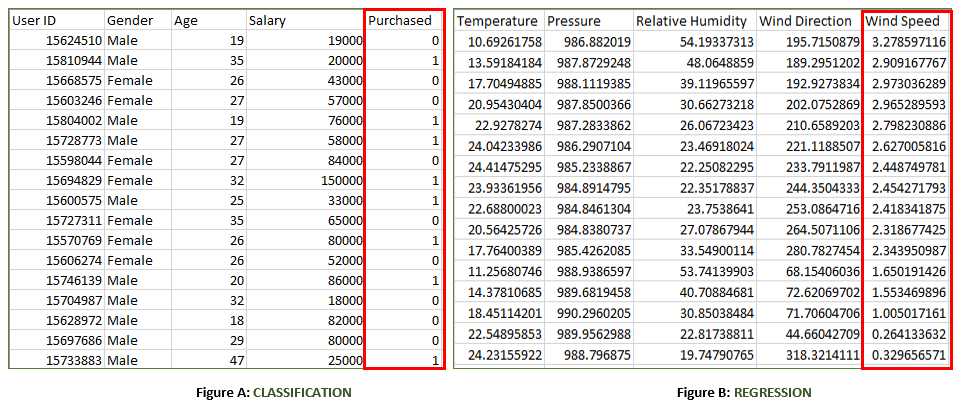
上述两个图都标记了如下数据集:
- 图A:它是一个购物商店的数据集,用于预测客户是否会根据他/她的性别,年龄和工资购买正在考虑的特定产品。
输入:性别、年龄、工资
输出:购买,即0或1; 1表示客户会购买,0表示客户不会购买。 - 图B:这是一个气象数据集,用于根据不同参数预测风速。
输入:露点、温度、压力、相对湿度、风向
输出:风速
训练系统:在训练模型时,数据通常以80:20的比例分割,即80%作为训练数据,其余作为测试数据。在训练数据中,我们为80%的数据提供输入和输出。模型仅从训练数据中学习。我们使用不同的机器学习算法(我们将在接下来的文章中详细讨论)来构建我们的模型。学习意味着模型将建立自己的一些逻辑。
一旦模型准备好了,就可以进行测试了。在测试时,输入来自模型从未见过的剩余20%的数据,模型将预测一些值,我们将其与实际输出进行比较并计算准确性。
监督学习
监督学习是一种机器学习技术,广泛应用于金融、医疗保健、营销等各个领域。它是机器学习的一种形式,其中算法在标记数据上训练,以基于数据输入做出预测或决策。
在监督学习中,算法学习输入和输出数据之间的映射。该映射是从标记的数据集学习的,该数据集由输入和输出数据对组成。该算法试图学习输入和输出数据之间的关系,以便能够对新的、看不见的数据进行准确的预测。
监督学习中使用的标记数据集由输入特征和相应的输出标签组成。输入特征是用于进行预测的数据的属性或特征,而输出标签是算法试图预测的期望结果或目标。
监督学习通常分为两大类:回归和分类在回归中,算法学习预测连续的输出值,例如房价或城市温度。在分类中,算法学习预测分类输出变量或类别标签,例如客户是否可能购买产品。
监督学习的主要优点之一是它允许创建复杂的模型,可以对新数据进行准确的预测。然而,监督学习需要大量的标记训练数据才能有效。此外,训练数据的质量和代表性可能对模型的准确性产生重大影响。
监督学习可以进一步分为两类
回归:在回归中,目标变量是连续值。回归的目标是根据输入变量预测目标变量的值。线性回归、多项式回归和决策树是回归算法的一些示例。
分类:在分类中,目标变量是分类值。分类的目标是根据输入变量预测目标变量的类别或类别。分类算法的一些示例包括逻辑回归、决策树、支持向量机和神经网络。
监督学习类型
监督学习可以进一步分为几种不同的类型,每种类型都有自己独特的特点和应用。以下是一些最常见的监督学习类型:(监督学习中使用的算法)
线性回归
线性回归是一种用于预测连续输出值的回归算法。它是监督学习中最简单和最广泛使用的算法之一。在线性回归中,算法试图找到输入特征和输出值之间的线性关系。基于输入特征的加权和来预测输出值。
逻辑回归
逻辑回归是一种用于预测二进制输出变量的分类算法。它通常用于机器学习应用中,其中输出变量为真或假,例如欺诈检测或垃圾邮件过滤。在逻辑回归中,该算法试图找到输入特征和输出变量之间的线性关系。然后使用逻辑函数对输出变量进行变换以产生0和1之间的概率值。
决策树
决策树是一种用于分类和回归任务的算法。它是一种树状结构,用于对决策及其可能的后果进行建模。树中的每个内部节点代表一个决策,而每个叶节点代表一个可能的结果。决策树可用于建模输入特征和输出变量之间的复杂关系。
随机森林
随机森林是一种集成学习技术,用于分类和回归任务。它们由多个决策树组成,这些决策树一起工作以进行预测。森林中的每棵树都是在输入特征和数据的不同子集上训练的。最后的预测是通过汇总森林中所有树木的预测来做出的。