出品人:Towhee 技术团队
作者:张晨
在探索通用人工智能的多种可能发展方向中,多模态大模型(MLLM)已成为当前备受关注的重要方向。随着 GPT-4 对图文理解的冲击,更多模态的理解成为了学术界的热点话题,这个时代真的来临了吗?
香港中文大学多媒体实验室联合上海人工智能实验室的研究团队提出一个统一多模态学习框架 —— Meta-Transformer,通过统一学习多种模态信息,模型可学会理解 12 种模态,共享网络参数,无需额外训练。
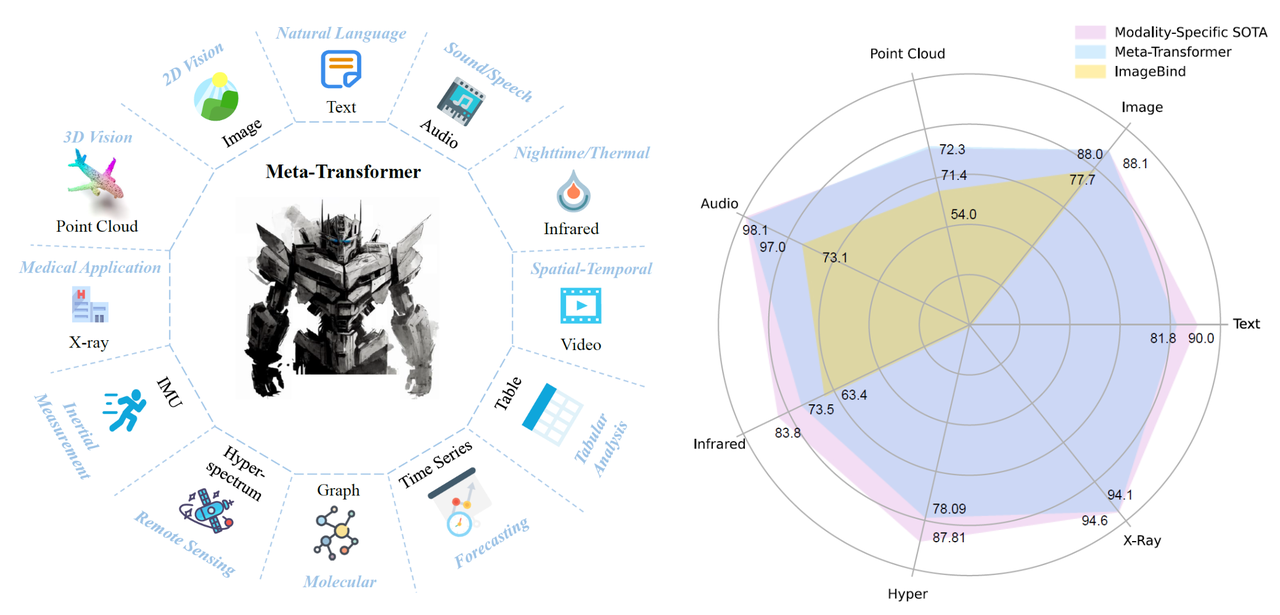 |Meta-Transformer支持的模态,和它与ImageBind的对比
|Meta-Transformer支持的模态,和它与ImageBind的对比
本文探索了 transformer 架构处理 12 种模态的潜力,包括图像、自然语言、点云、音频频谱图、视频、红外、高光谱、X 射线、IMU、表格、图形和时间序列数据,如图所示。
本文讨论了每种模态的 transformer 学习过程,并解决了将它们统一到单个框架中所面临的挑战,并提出了一个名为 Meta-Transformer 的新颖的多模态学习统一框架。 Meta-Transformer 是第一个使用同一组参数同时对来自十几种模态的数据进行编码的框架,从而允许采用更具凝聚力的方法进行多模态学习。 Meta-Transformer 包含三个简单而有效的组件:用于数据到序列 token 化的模态专家 、用于跨模态提取表示的模态共享编码器以及用于下游任务的特定于任务的头。
具体来说,Meta-Transformer 首先将多模态数据转换为共享公共流形空间的 token 序列。然后,具有冻结参数的模态共享编码器提取表示,通过仅更新下游任务头和轻量级 tokenizer 的参数来进一步适应各个任务。最后,可以通过这个简单的框架有效地学习特定任务和通用模态表示。Meta-Transformer 预示着利用 transformer 开发统一多模态智能的广阔前景。
本文对 12 种模式的各种基准进行了广泛的实验。通过专门利用 LAION-2B 数据集的图像进行预训练,Meta-Transformer 在处理来自多种模式的数据方面表现出了卓越的性能,在不同的多模式学习任务中始终取得优于最先进方法的结果。
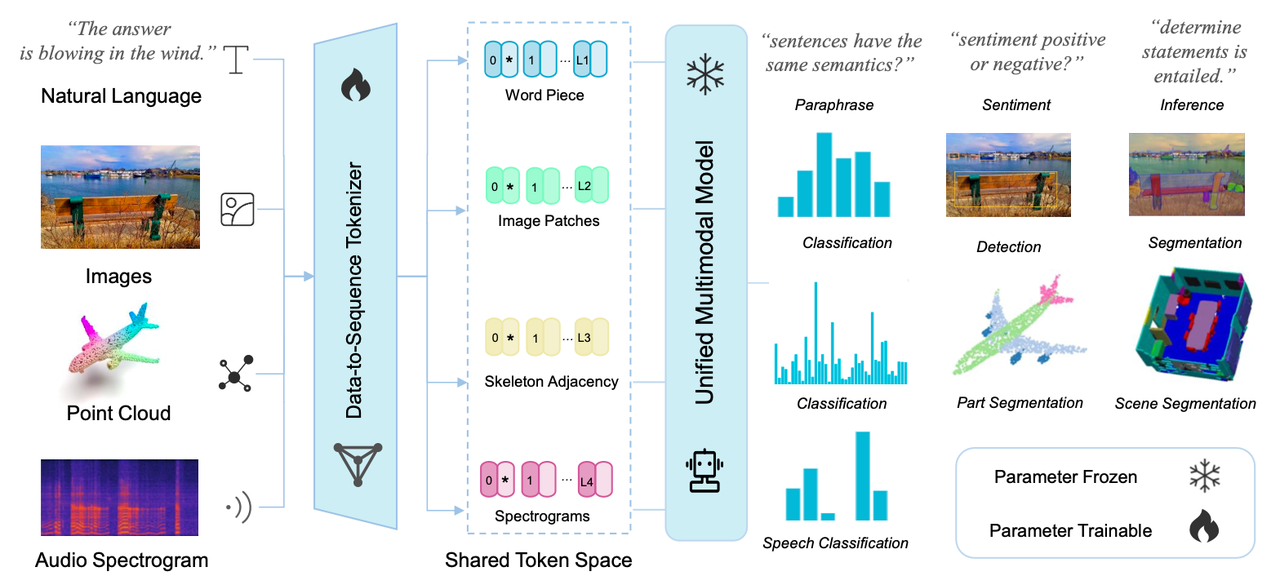 |对于不同模态的数据,基于不同模态的信息特性设计了相应的特征序列构造方式,接着将得到的特征序列输入到预训练后参数冻结的编码器中,由此提取的表征能够在多个模态上解决下游多个任务。
|对于不同模态的数据,基于不同模态的信息特性设计了相应的特征序列构造方式,接着将得到的特征序列输入到预训练后参数冻结的编码器中,由此提取的表征能够在多个模态上解决下游多个任务。
文章也说了Meta-Transformer的一些局限性:
-
复杂性:元Transformer需要大量计算量。高内存成本和繁重的计算负担使其难以扩展模型规模和数据数据规模。 -
方法上:与TimeSformer和Graphormer中的轴向注意力机制相比,Meta-Transformer缺乏时间和结构意识。这种限制可能会影响 Meta-Transformer 在时间和结构建模发挥关键作用的任务中的整体性能,例如视频理解、视觉跟踪或社交网络预测。 -
应用上:Meta-Transformer主要发挥其在多模态感知方面的优势。其跨模态生成的能力仍然未知。
总的来说,本文中探讨了普通 transformer 在统一多模态学习中的潜力,强调了使用 transformer backbone 开发统一多模态智能的良好趋势。在某种程度上,本文支持了transformer在下一代网络中的主导地位。重要的是,CNN 和 MLP 也没有落后。它们在数据 token 化和表示投影中发挥着重要作用。这个过程体现了神经网络的继承法则和人工智能的持续进化。
-
相关链接:
代码地址:https://github.com/invictus717/MetaTransformer
论文地址:https://arxiv.org/pdf/2307.10802v1.pdf
本文由 mdnice 多平台发布