By AWS Team
By AWS Team
前言
随着企业规模的扩大,业务数据的激增,我们会使用 Hadoop/Spark 框架来处理大量数据的 ETL/聚合分析作业,⽽这些作业将需要由统一的作业调度平台去定时调度。
在 Amazon EMR 中,可以使用 AWS 提供 Step Function,托管 AirFlow,以及 Apache Oozie 或 Azkaban 进行作业的调用。但随着 Apache Dolphinscheduler 产品完善、社区日益火爆、且其本身具有简单易用、高可靠、高扩展性、⽀持丰富的使用场景、提供多租户模式等特性,越来越多的企业选择使用该产品作为任务调度的服务。
DolphinScheduler 可以在 Amazon EMR 集群中进行安装和部署,但是结合 Amazon EMR 本身的特点和使用最佳实践,不建议客户使用一个大而全,并且持久运行的 EMR 集群提供整个大数据的相关服务,而是基于不同的维度对集群进行拆分,比如按研发阶段(开发、测试、生产)、工作负载(即席查询、批处理)、对时间敏感性、作业时长要求、组织类型等,因此 DolphinScheduler 作为统一的调度平台,不需要安装在某一个固定 EMR 集群上,而是选择独立部署,将作业划分到不同的 EMR 集群上,并以 DAG(Directed Acyclic Graph,DAG)流式方式组装,实现统一的调度和管理。 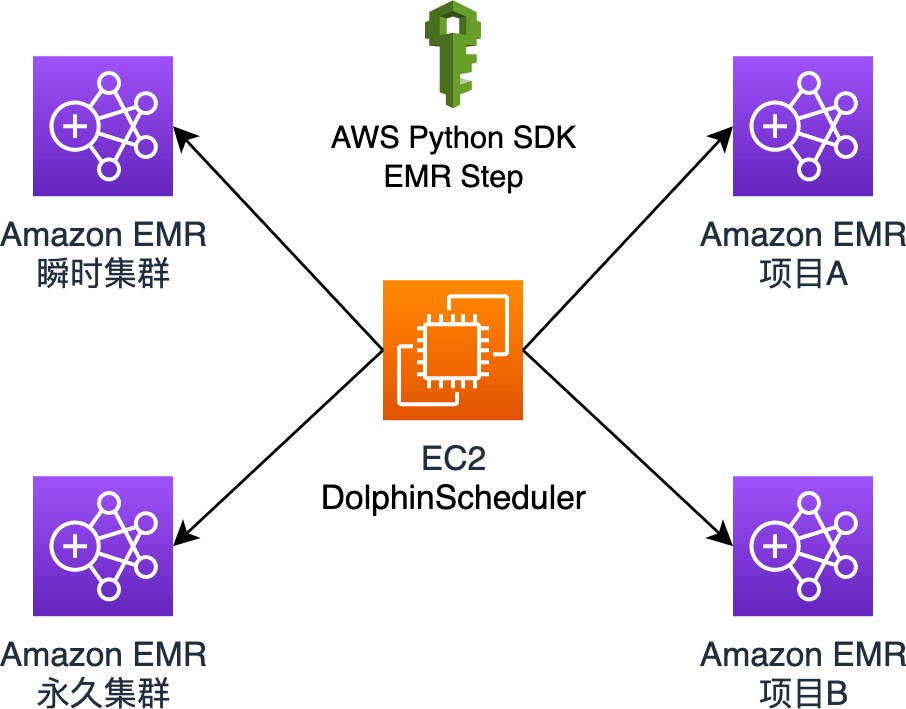
此篇文章将介绍 DolphinScheduler 安装部署,以及在 DolphinScheduler 中进行作业编排,以使用 python 脚本的方式执行 EMR 的任务调度,包括创建集群、集群状态检查、提交 EMR Step 作业、EMR Step 作业状态检查,所有作业完成后终止集群。
Amazon EMR
Amazon EMR 是一个托管的集群平台,可简化在 AWS 上运行大数据框架(如 Apache Hadoop 和 Apache Spark)的过程,以处理和分析海量数据。用户可一键启动包含了众多 Hadoop 生态数据处理,分析相关服务的集群,⽽无需手动进行复杂的配置。
Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度开源系统。适用于企业级场景,提供了⼀个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
特性
简单易用
- 可视化 DAG:⽤户友好的,通过拖拽定义工作流的,运行时控制工具模块化
- 操作:模块化,有助于轻松定制和维护
丰富的使用场景
- 支持多种任务类型:支持 Shell、MR、Spark、SQL 等 10 余种任务类型,支持跨语言
- 易于扩展丰富的工作流操作:⼯作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数
High Reliability
高可靠性:去中心化设计,确保稳定性。原生 HA 任务队列支持,提供过载容错能力。DolphinScheduler 能提供高度稳健的环境。
- High Scalability
高扩展性:支持多租户和在线资源管理。支持每天 10 万个数据任务的稳定运行。
架构图: 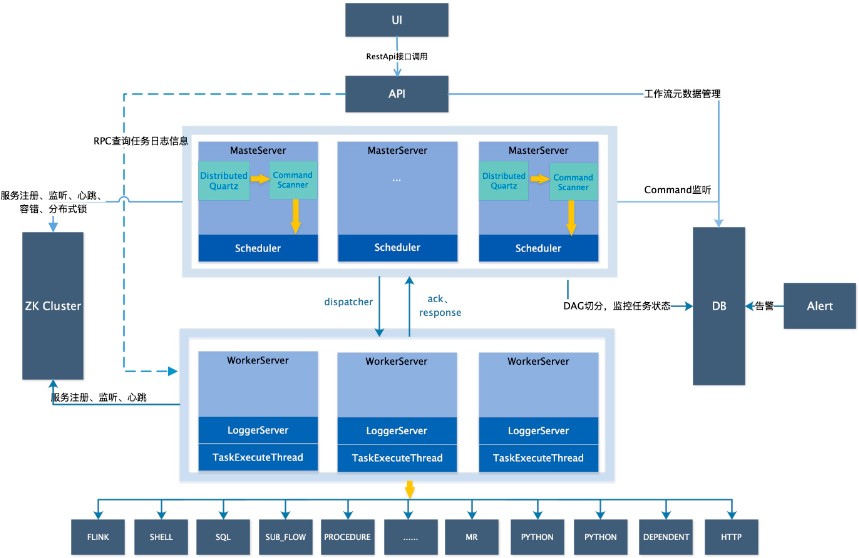
主要可实现:
- 以 DAG 图的方式将 Task 按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
- 支持丰富的任务类型:Shell、MR、Spark、SQL(mysql、oceanbase、postgresql、hive、sparksql)、Python、Sub_Process、Procedure 等
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill 任务等操作
- 支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败
- 支持工作流全局参数及节点自定义参数设置
- 支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑
- 支持任务日志在线查看及滚动、在线下载日志等
- 实现集群 HA,通过 Zookeeper 实现 Master 集群和 Worker 集群去中心化
- 支持对 Master/Worker CPU load,memory,CPU 在线查看
- 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计
- 支持补数
- 支持多租户
安装 DolphinScheduler
DolphinScheduler 支持多种部署方式
- 单机部署:Standalone 仅适用于 DolphinScheduler 的快速体验
- 伪集群部署:伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下 master、worker、api server 都在同⼀台机器上
- 集群部署:集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行⼤量任务情况
如果你是新手,想要体验 DolphinScheduler 的功能,推荐使用 Standalone 方式体验;如果你想体验更完整的功能,或者更大的任务量,推荐使用伪集群部署;如果你是在生产中使用,推荐使用集群部署或者 kubernetes。
本次实验将介绍在 AWS 上以伪集群模式部署 DolphinScheduler。
- 启动⼀台 EC2
在 AWS 公有子网中启动一台 EC2,选用 Amazon-linux2,m5.xlarge 安全组开启 TCP 12345 端口。
- 安装 JDK,配置 JAVA_HOME 环境
java -version
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-b08) OpenJDK 64-Bit Server VM (build 25.362-b08, mixed mode)- 安装启动 Zookeeper
bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/src/apache-zookeeper-3.8.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone- 启动 mysql,这里选用 Aurora Serverless

- 安装 AWS CLI2
aws --version
aws-cli/2.11.4 Python/3.11.2 Linux/5.10.167-147.601.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off- 更新 python 版本到 3.9
python --version
Python 3.9.1- 下载 DolphinScheduler
cd /usr/local/src
wget https://dlcdn.apache.org/dolphinscheduler/3.1.4/apache-dolphinscheduler-3.1.4-bin.tar.gz- 配置用户免密及权限
# 创建用户需使用 root 登录
useradd dolphinscheduler
# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
cd /usr/local/src
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin - 配置机器 SSH 免密登录
# 切换 dolphinscheduler 用户
su dolphinscheduler
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 注意:配置完成后,可以通过运行命令 ssh localhost 判断是否成功,如果不需要输⼊密码就能 ssh 登陆则证明成功- 数据初始化
cd /usr/local/src
# 下载 mysql-connector
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gz
tar -zxvf mysql-connector-j-8.0.31.tar.gz
# 驱动拷贝
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/api-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/alert-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/master-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/worker-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/tools/libs/
# 安装 mysql 客户端
# 修改 {mysql-endpoint} 为你 mysql 连接地址
# 修改 {user} 和 {password} 为你 mysql ⽤户名和密码
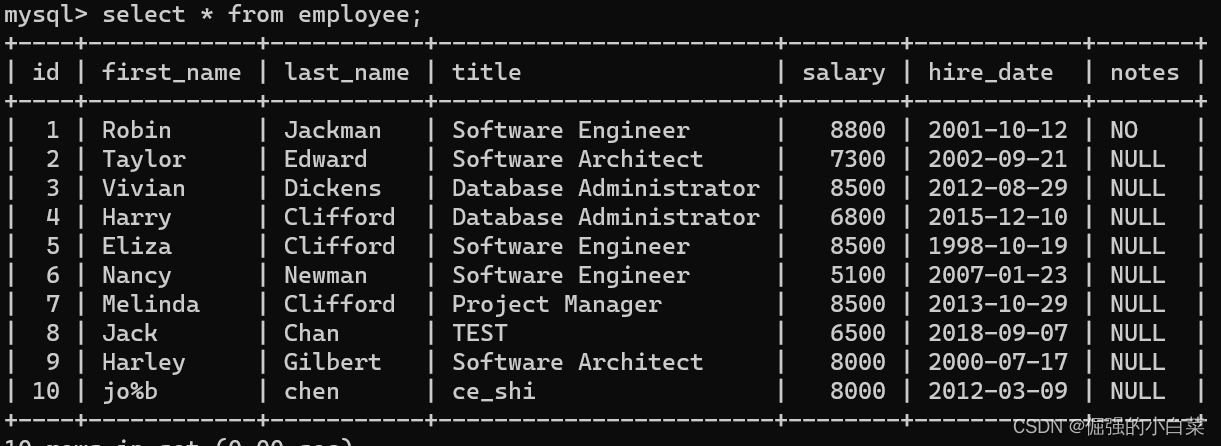
mysql -h {mysql-endpoint} -u{user} -p{password}
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 修改 {user} 和 {password} 为你希望的用户名和密码
mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';
mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';
mysql> FLUSH PRIVILEGES;
修改数据库配置
vi bin/env/dolphinscheduler_env.sh
# Database related configuration, set database type, username and password # 修改 {mysql-endpoint} 为你 mysql 连接地址
# 修改 {user} 和 {password} 为你 mysql ⽤户名和密码,{rds-endpoint}为数据库连接地址
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://{rds-endpoint}/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}
# 执行数据初始化
bash apache-dolphinscheduler/tools/bin/upgrade-schema.sh- 修改 install_env.sh
cd /usr/local/src/apache-dolphinscheduler
vi bin/env/install_env.sh
# 替换 IP 为 DolphinScheduler 所部署 EC2 私有 IP 地址
ips=${ips:-"10.100.1.220"}
masters=${masters:-"10.100.1.220"}
workers=${workers:-"10.100.1.220:default"}
alertServer=${alertServer:-"10.100.1.220"}
apiServers=${apiServers:-"10.100.1.220"}
installPath=${installPath:-"~/dolphinscheduler"} - 修改 DolphinScheduler_env.sh
cd /usr/local/src/
mv apache-dolphinscheduler-3.1.4-bin apache-dolphinscheduler
cd ./apache-dolphinscheduler
# 修改 DolphinScheduler 环境变量
vi bin/env/dolphinscheduler_env.sh
export JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.362.b08-1.amzn2.0.1.x86_64}
export PYTHON_HOME=${PYTHON_HOME:-/bin/python} - 启动 DolphinScheduler
cd /usr/local/src/apache-dolphinscheduler
su dolphinscheduler
bash ./bin/install.sh- 访问 DolphinScheduler
URL 访问使用 IP 为 DolphinScheduler 所部署 EC2 公有 IP 地址 http://ec2-endpoint:12345/dolphinscheduler/ui/login
初始用户名/密码 admin/dolphinscheduler123 05
配置 DolphinScheduler
- 建立租户
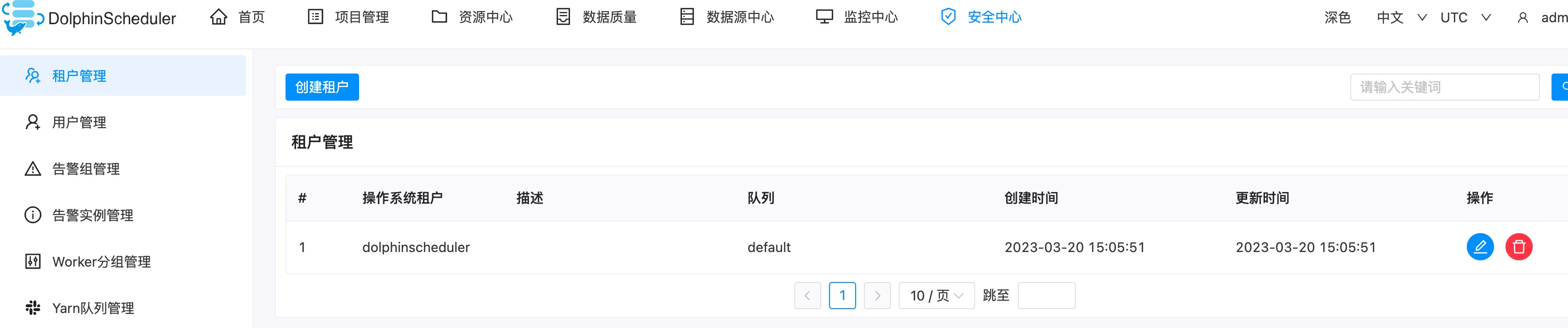 2. 将用户与绑定租户
2. 将用户与绑定租户

- AWS 创建 IAM 策略
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"ElasticMapReduceActions",
"Effect":"Allow",
"Action":[
"elasticmapreduce:RunJobFlow",
"elasticmapreduce:DescribeCluster",
"elasticmapreduce:AddJobFlowSteps",
"elasticmapreduce:DescribeStep",
"elasticmapreduce:TerminateJobFlows",
"elasticmapreduce:SetTerminationProtection"
],
"Resource":"*"
},
{
"Effect":"Allow",
"Action":[
"iam:GetRole",
"iam:PassRole"
],
"Resource":[
"arn:aws:iam::accountid:role/EMR_DefaultRole",
"arn:aws:iam::accountid:role:role/EMR_EC2_DefaultRole"
]
}
]
} - 创建 IAM ⾓⾊
进入 AWS IAM,创建角色,并赋予上⼀步所创建的策略
- DolphinScheduler 部署 EC2 绑定角色
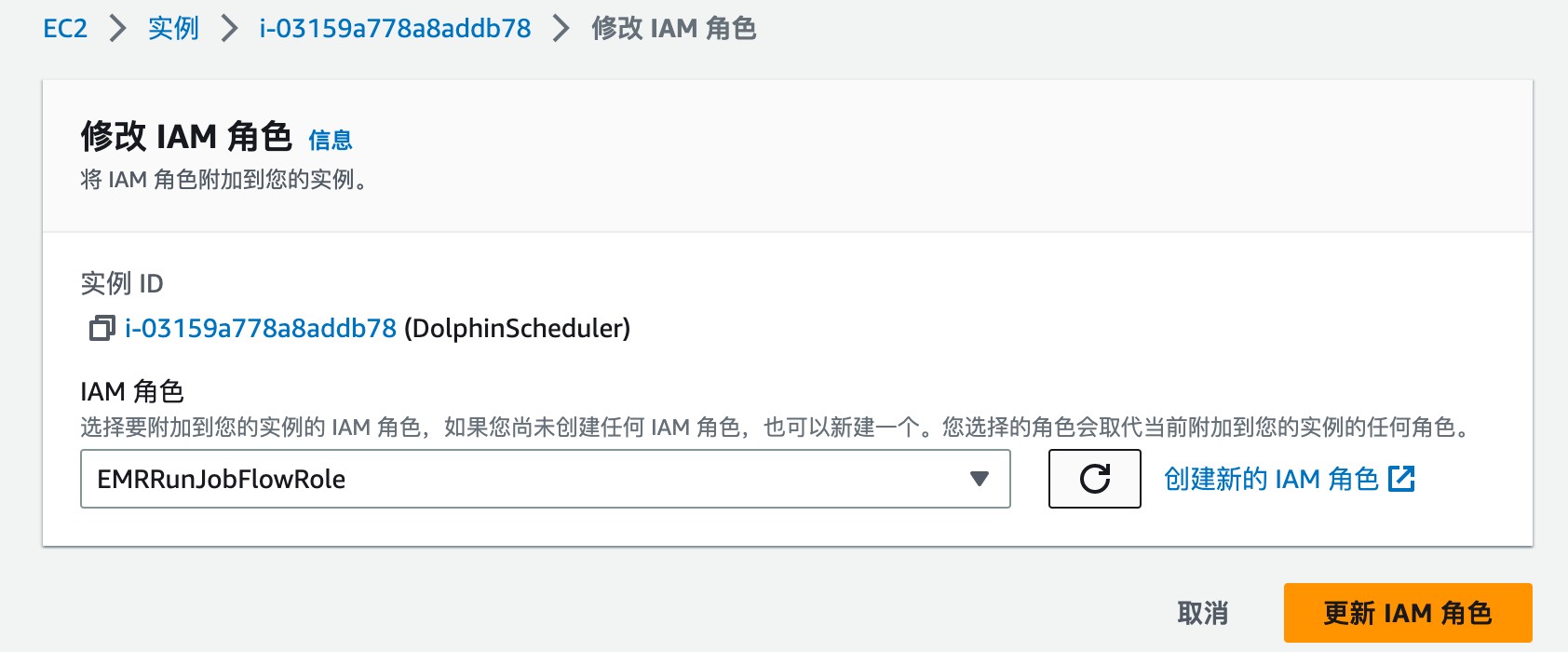
将 EC2 绑定上⼀步创建的角色,使 DolphinScheduler 所部署 EC2 具有调用 EMR 权限。
- python 安装 boto3,以及要用到其他的组件
sudu pip install boto3
sudu pip install redis使用DolphinScheduler进行作业编排
以Python方式执行。
作业执行时序图:
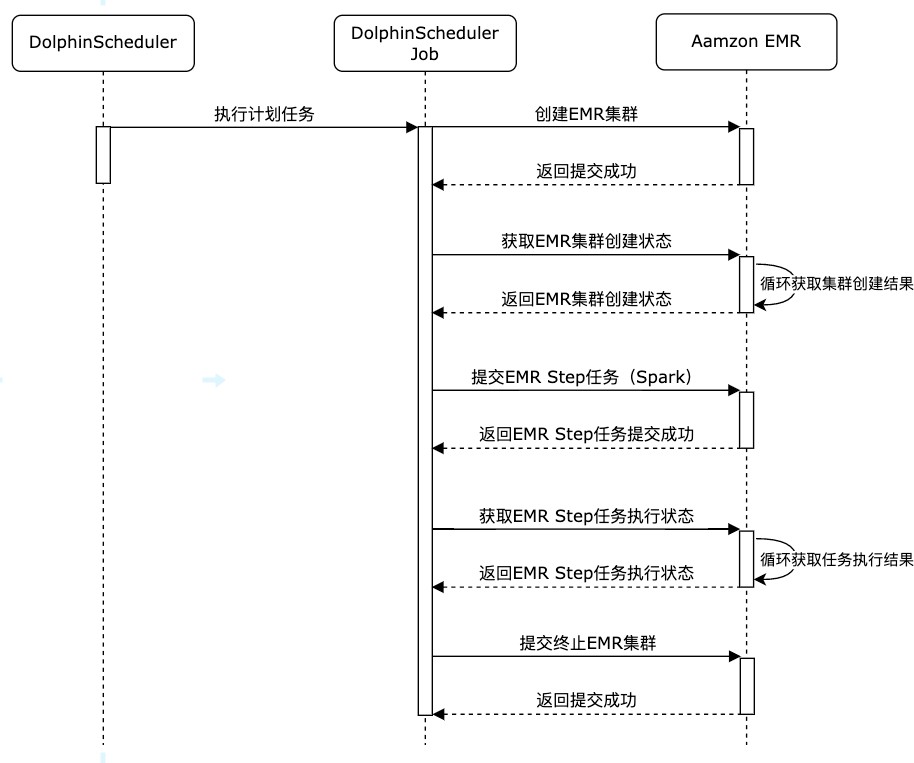
- 创建 EMR 集群创建任务
创建⼀个 EMR 集群,3 个 MASTER,3 个 CORE,指定子网与权限,以及集群空闲十分钟后自动终止。具体参数可见链接。
import boto3
from datetime import date
import redis
def run_job_flow():
response = client.run_job_flow(
Name='create-emrcluster-'+ d1,
LogUri='s3://s3bucket/elasticmapreduce/',
ReleaseLabel='emr-6.8.0',
Instances={
'KeepJobFlowAliveWhenNoSteps': False,
'TerminationProtected': False,
# 替换{Sunbet-id}为你需要部署的子网 id
'Ec2SubnetId': '{Sunbet-id}',
# 替换{Keypairs-name}为你 ec2 使用密钥对名称
'Ec2KeyName': '{Keypairs-name}',
'InstanceGroups': [
{
'Name': 'Master',
'Market': 'ON_DEMAND',
'InstanceRole': 'MASTER',
'InstanceType': 'm5.xlarge',
'InstanceCount': 3,
'EbsConfiguration': {
'EbsBlockDeviceConfigs': [
{
'VolumeSpecification': {
'VolumeType': 'gp3',
'SizeInGB': 500
},
'VolumesPerInstance': 1
},
],
'EbsOptimized': True
},
},
{
'Name': 'Core',
'Market': 'ON_DEMAND',
'InstanceRole': 'CORE',
'InstanceType': 'm5.xlarge',
'InstanceCount': 3,
'EbsConfiguration': {
'EbsBlockDeviceConfigs': [
{
'VolumeSpecification': {
'VolumeType': 'gp3',
'SizeInGB': 500
},
'VolumesPerInstance': 1
},
],
'EbsOptimized': True
},
}
],
},
Applications=[{'Name': 'Spark'},{'Name': 'Hive'},{'Name': 'Pig'},{'Name': 'Presto'}],
Configurations=[
{ 'Classification': 'spark-hive-site',
'Properties': {
'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'}
},
{ 'Classification': 'hive-site',
'Properties': {
'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'}
},
{ 'Classification': 'presto-connector-hive',
'Properties': {
'hive.metastore.glue.datacatalog.enabled': 'true'}
}
],
JobFlowRole='EMR_EC2_DefaultRole',
ServiceRole='EMR_DefaultRole',
EbsRootVolumeSize=100,
# 集群空闲十分钟自动终止
AutoTerminationPolicy={
'IdleTimeout': 600
}
)
return response
if __name__ == "__main__":
today = date.today()
d1 = today.strftime("%Y%m%d")
# {region}替换为你需要创建 EMR 的 Region
client = boto3.client('emr',region_name='{region}')
# 创建 EMR 集群
clusterCreate = run_job_flow()
job_id = clusterCreate['JobFlowId']
# 使用 redis 来保存信息,作为 DolphinScheduler job step 的参数传递,也可以使用 DolphinScheduler 所使用的 mysql 或者其他方式存储
# 替换{redis-endpoint}为你 redis 连接地址
pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.set('cluster_id_'+d1, job_id) - 创建 EMR 集群状态检查任务
检查 EMR 集群是否创建完毕
import boto3
import redis
import time
from datetime import date
if __name__ == "__main__":
today = date.today()
d1 = today.strftime("%Y%m%d")
# {region}替换为你需要创建 EMR 的 Region
client = boto3.client('emr',region_name='{region}')
# 替换{redis-endpoint}为你 redis 连接地址
pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 获取创建的 EMR 集群 id
job_id = r.get('cluster_id_' + d1)
print(job_id)
while True:
result = client.describe_cluster(ClusterId=job_id)
emr_state = result['Cluster']['Status']['State']
print(emr_state)
if emr_state == 'WAITING':
# EMR 集群创建成功
break
elif emr_state == 'FAILED':
# 集群创建失败
# do something...
break
else:
time.sleep(10)
- 使用创建好的 EMR 集群启动 spark job
import time
import re
import boto3
from datetime import date
import redis
def generate_step(step_name, step_command):
cmds = re.split('\\s+', step_command)
print(cmds)
if not cmds:
raise ValueError
return {
'Name': step_name,
'ActionOnFailure': 'CANCEL_AND_WAIT',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': cmds
}
}
if __name__ == "__main__":
today = date.today()
d1 = today.strftime("%Y%m%d")
# {region}替换为你需要创建 EMR 的 Region
client = boto3.client('emr',region_name='{region}')
# 获取 emr 集群 id
# 替换{redis-endpoint}为你 redis 连接地址
pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
job_id = r.get('cluster_id_' + d1)
# job 启动命令
spark_submit_cmd = """spark-submit
s3://s3bucket/file/spark/spark-etl.py
s3://s3bucket/input/
s3://s3bucket/output/spark/"""+d1+'/'
steps = []
steps.append(generate_step("SparkExample_"+d1 , spark_submit_cmd),)
# 提交 EMR Step 作业
response = client.add_job_flow_steps(JobFlowId=job_id, Steps=steps)
step_id = response['StepIds'][0]
# 将作业 id 保存,以便于做任务检查
r.set('SparkExample_'+d1, step_id)- 创建 JOB 执⾏情况检查
import boto3
import redis
import time
from datetime import date
if __name__ == "__main__":
today = date.today()
d1 = today.strftime("%Y%m%d")
# {region}替换为你需要创建 EMR 的 Region
client = boto3.client('emr',region_name='{region}')
# 替换{redis-endpoint}为你 redis 连接地址
pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
job_id = r.get('cluster_id_' + d1)
step_id = r.get('SparkExample_' + d1)
print(job_id)
print(step_id)
while True:
# 查询作业执行结果
result = client describe_step(ClusterId=job_id,StepId=step_id)
emr_state = result['Step']['Status']['State']
print(emr_state)
if emr_state == 'COMPLETED':
# 作业执行完成
break
elif emr_state == 'FAILED'
# 作业执行失败
# do somethine
# ......
break
else:
time.sleep(10)- 设置执⾏顺序
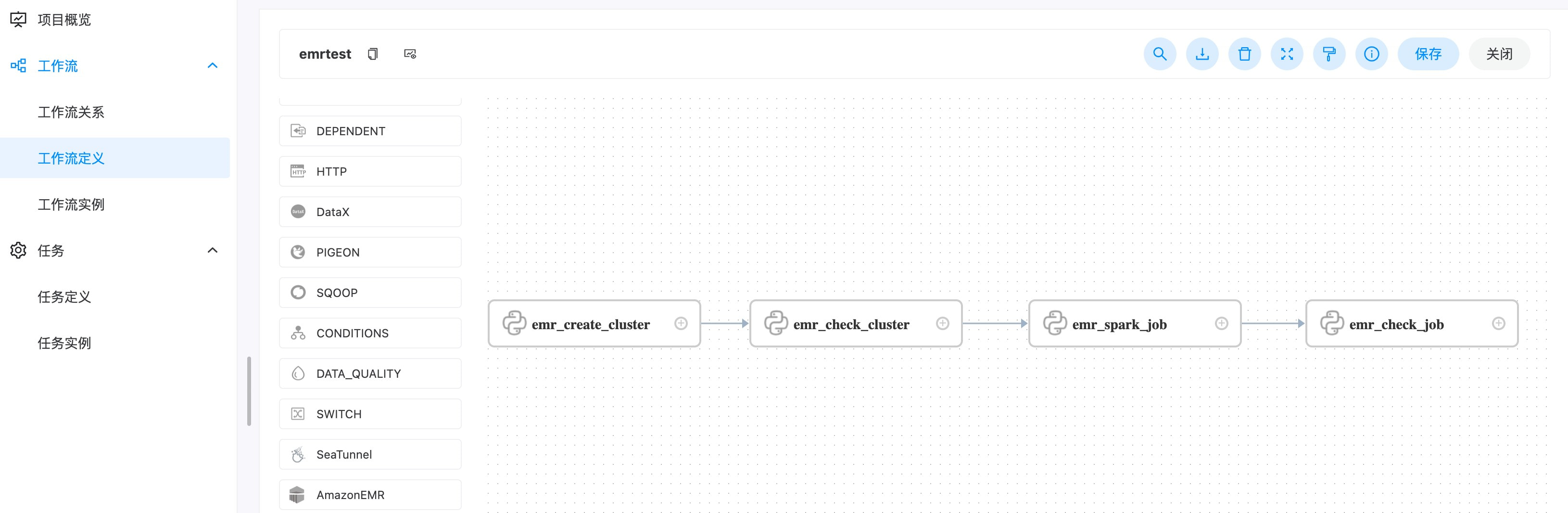 在 DolphinScheduler – 项目管理 – 工作流 – 工作流定义中创建工作流,并创建 python 任务,将以上 python 脚本作为任务串联起来
在 DolphinScheduler – 项目管理 – 工作流 – 工作流定义中创建工作流,并创建 python 任务,将以上 python 脚本作为任务串联起来
- 保存并上线
 保存任务并点击上线
保存任务并点击上线
- 执行
 可以点击立即执行,或指定计划任务按时执行。
可以点击立即执行,或指定计划任务按时执行。
在 EMR 中查看执行情况
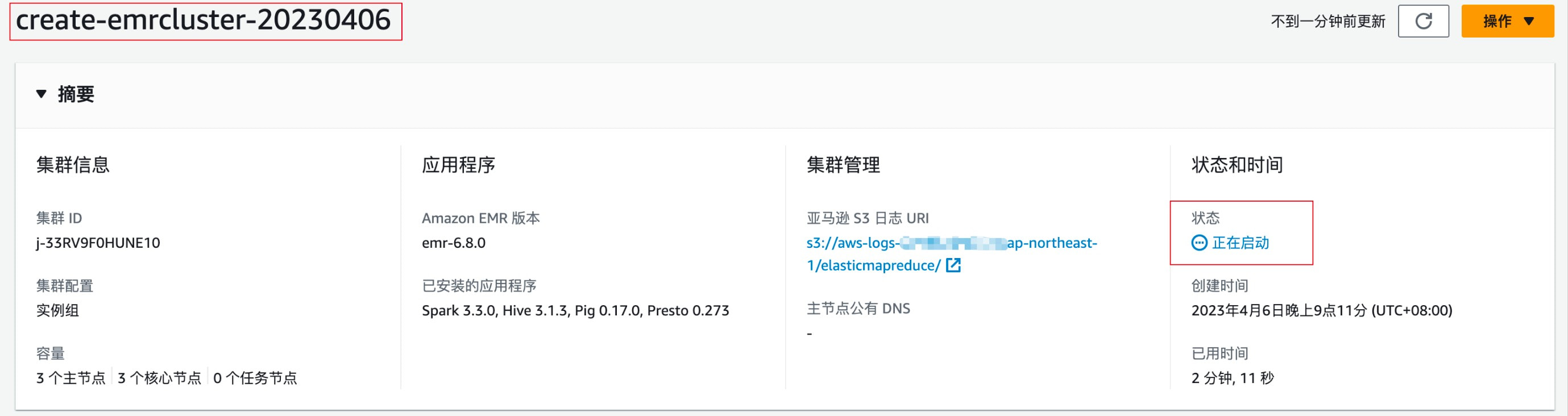
EMR 创建情况——正在启动
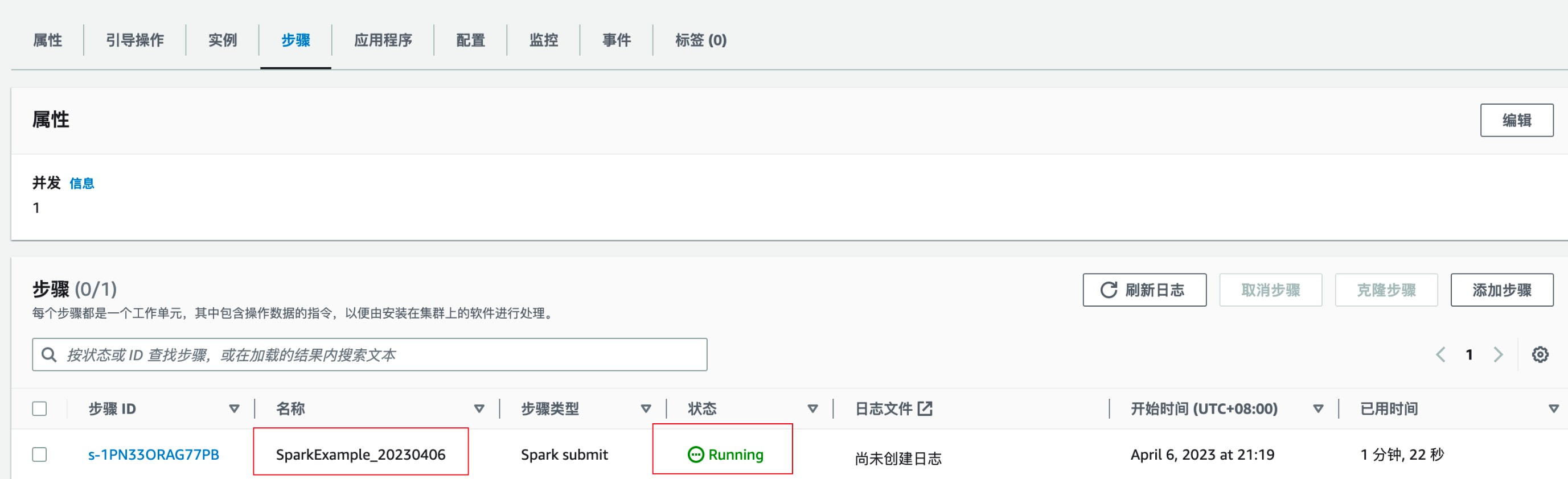
 EMR Step执行情况——正在执行
EMR Step执行情况——正在执行
- 检查执行结果以及执行⽇志
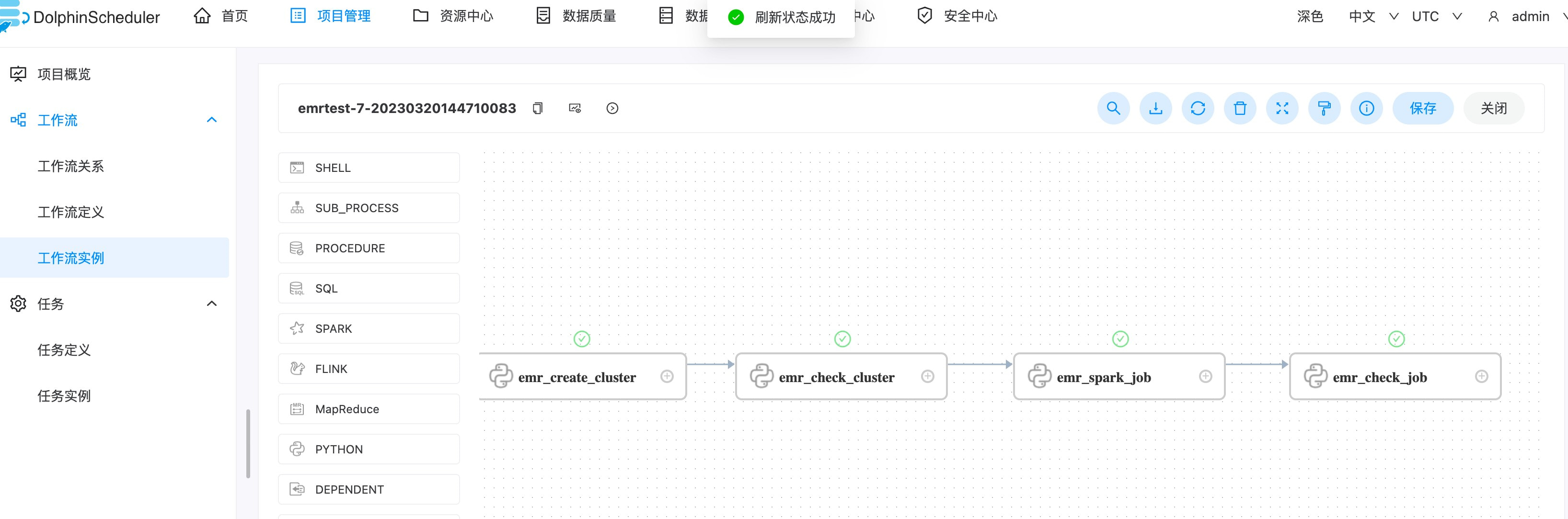 在 DolphinScheduler – 项目管理 – 工作流 – 工作流实例中检查执行状态,以及执行日志
在 DolphinScheduler – 项目管理 – 工作流 – 工作流实例中检查执行状态,以及执行日志 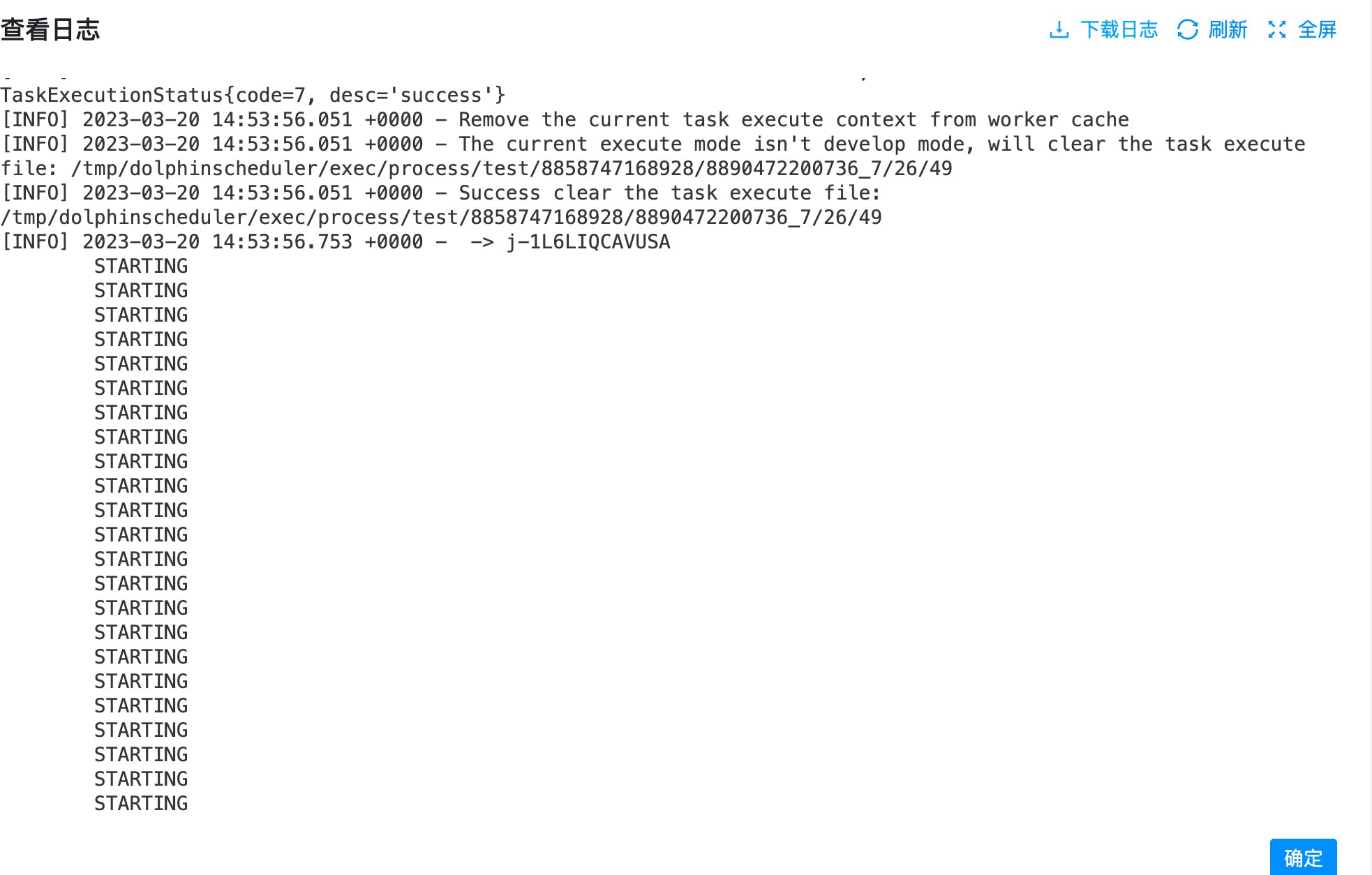 在 EMR 中查看执⾏情况
在 EMR 中查看执⾏情况
EMR 创建情况——正在等待
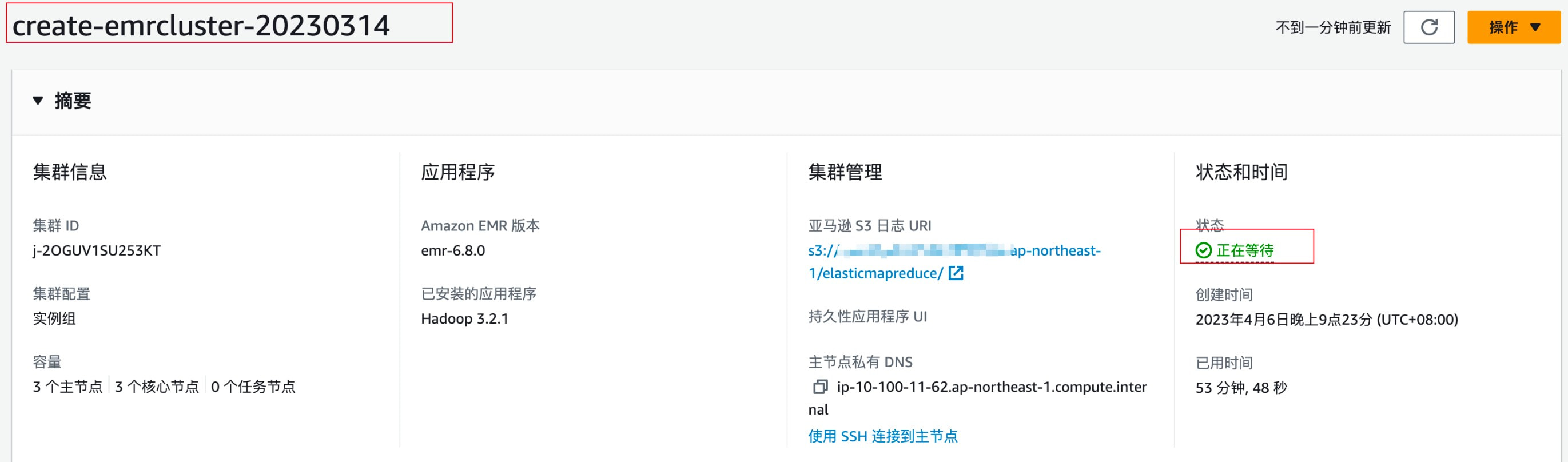 Step 执行情况——完成
Step 执行情况——完成 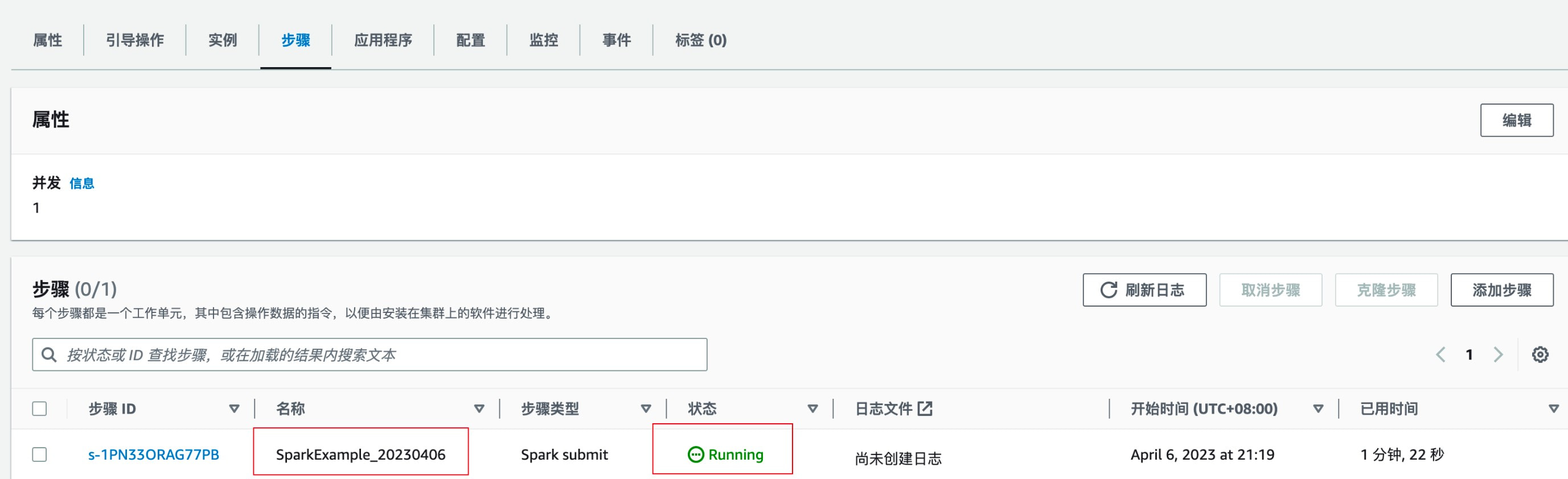
- 终止集群
对于临时性执行作业或者每天定时执行的批处理作业,可以在作业结束后终⽌ EMR 集群以节省成本(EMR 使用最佳实践)。终止 EMR 集群可以使用 EMR 本身功能在空闲后自动终止,或者手动调用中止。
自动终止 EMR 集群,在创建集群中进行配置
AutoTerminationPolicy={
'IdleTimeout': 600
} 此集群将在作业执行完空闲十分钟后自动终止 手动终止 EMR 集群:
import boto3
from datetime import date
import redis
if __name__ == "__main__":
today = date.today()
d1 = today.strftime("%Y%m%d")
# 获取集群 id
# {region}替换为你需要创建 EMR 的 Region
client = boto3.client('emr',region_name='{region}')
# 替换{redis-endpoint}为你 redis 连接地址
pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
job_id = r.get('cluster_id_' + d1)
# 关闭集群终止保护
client.set_termination_protection(JobFlowIds=[job_id],TerminationProtected=False)
# 终止集群
client.terminate_job_flows(JobFlowIds=[job_id]) 将此脚本加⼊到 DolphinScheduler 作业流中,作业流在全部任务执行完成后执行该脚本以实现终止 EMR 集群。
总结
随着企业大数据分析平台的应⽤,越来越多数据处理流程/处理任务需要利用一个简单易用的调度系统去理清其错综复杂的依赖关系,并且按执行计划进行编排调度,同时需要提供易使用易扩展的可视化 DAG 能力,而 Apache DolphinScheduler 正好满足了以上需求。
本文介绍了在 AWS 上独立部署 DolphinScheduler,并利用 EMR 的特性,结合最佳实践,展示了从创建 EMR 集群到提交 ETL 作业,最后作业执行全部完成后将集群进行终止,形成⼀个完整的作业处理的流程。用户可以参考该文档快速的部署搭建自己的大数据调度体系。
作者
王骁,AWS 解决方案架构师,负责基于 AWS 云计算方案架构的咨询和设计,在国内推广 AWS 云平台技术和各种解决方案,具有丰富的企业 IT 架构经验,目前侧重于于大数据领域的研究。
本文由 白鲸开源科技 提供发布支持!