pgembedding 存储结构
pg embedding 数据是存在共享内存中的,pg down 之后索引数据就没了,但索引对象本身还在,第一次访问时会重新创建。
数据以 plain 的形式存储,其中每个点是这样的结构:
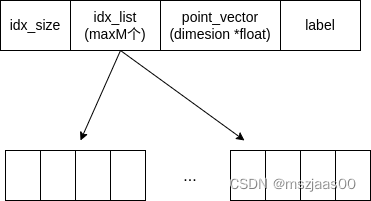
idx_size: 表示这个点目前有多少 neighbour
idx_list: 表示排序好的邻近点的 index(点都存在数组里,因此可以用index访问)
point_vector: 是真正的点坐标,每个维度是一个 float,
label: 是点的标签
knn查找
首先从第0个点的idx_list开始找它的临近neighbour,最多遍历 efconstruction 个点(index 的 option),过程中会用visited 来做去重剪枝。
遍历过程会维护一个距离目标点的距离最小堆(candidateSet)和最大堆(topResults),当为目标点找到的邻居超过maxelements(index 的 option)时,就取出最大距离的点,如果比这个最大的小,则pop出这个最大点,将新邻居插入topResults中。
每有一个邻居成功插入idx_list就把它加入candidateSet,不断candidateSet找到更近的邻居,更新topResults。
点的插入
插入点过程与knn查找类似,先找邻近的n个点,更新自己的idx_list领居列表。
遍历每个邻居,看这个邻居是否idx_list満了,如果満了,则用最小堆做一个排序,更新这个邻居的idx_list。
索引创建
创建过程由于是共享内存里的操作,因而不支持并行 worker,就是普通的扫表创建。
cost 计算
没有什么特别的,就是当成普通的 index 来算
vacuum
没有实现 index tuple 的删除,可能因为是在内存里,没必要实现,只能 drop + create