Where Do the Probabilities Come From?
概率从何而来?
OK, so ChatGPT always picks its next word based on probabilities. But where do those probabilities come from? Let’s start with a simpler problem. Let’s consider generating English text one letter (rather than word) at a time. How can we work out what the probability for each letter should be?
好的,ChatGPT 总是根据概率选择下一个词。但这些概率是从哪里来的呢?让我们从一个更简单的问题开始。考虑每次生成英文文本一个字母(而不是单词)。我们如何计算每个字母的概率呢?
A very minimal thing we could do is just take a sample of English text, and calculate how often different letters occur in it. So, for example, this counts letters in the Wikipedia article on “cats”:
最简单的方法是只需取一段英文文本样本,然后计算不同字母出现的频率。例如,这是统计维基百科关于“猫”的文章中不同字母出现的次数:

And this does the same thing for “dogs”:
这是关于“狗”的文章中做的字母计数:

The results are similar, but not the same (“o” is no doubt more common in the “dogs” article because, after all, it occurs in the word “dog” itself). Still, if we take a large enough sample of English text we can expect to eventually get at least fairly consistent results:
结果是相似的,但不完全相同(毫无疑问 “o”在关于“狗”的文章中更常见,因为毕竟它出现在单词“dog”中)。但是,如果我们取足够大的英文文本样本,我们可以预期最终得到至少相对一致的结果:

Here’s a sample of what we get if we just generate a sequence of letters with these probabilities:
这是我们根据这些概率生成字母序列的示例:

We can break this into “words” by adding in spaces as if they were letters with a certain probability:
我们可以通过添加空格作为字母的一种形式来将其分割成“单词”:

We can do a slightly better job of making “words” by forcing the distribution of “word lengths” to agree with what it is in English:
我们可以通过强制“单词长度”的分布与英文一致,进一步改进“单词”的生成:

We didn’t happen to get any “actual words” here, but the results are looking slightly better. To go further, though, we need to do more than just pick each letter separately at random. And, for example, we know that if we have a “q”, the next letter basically has to be “u”.
这里没有得到“实际单词”,但结果看起来稍微好一些。然而,要进一步,我们需要比仅随机选择每个字母要多做些事情。例如,我们知道如果有一个“q”,下一个字母基本上必须是“u”。
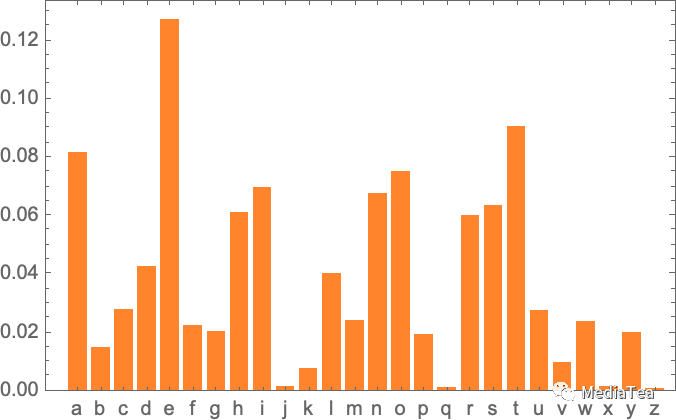
Here’s a plot of the probabilities for letters on their own:
这是字母概率图表:
And here’s a plot that shows the probabilities of pairs of letters (“2-grams”) in typical English text. The possible first letters are shown across the page, the second letters down the page:
这是显示一对字母(“2-grams”)在典型英文文本中的概率的图表。可能的第一个字母显示在页面上方(横坐标),第二个字母显示在页面下方(纵坐标):
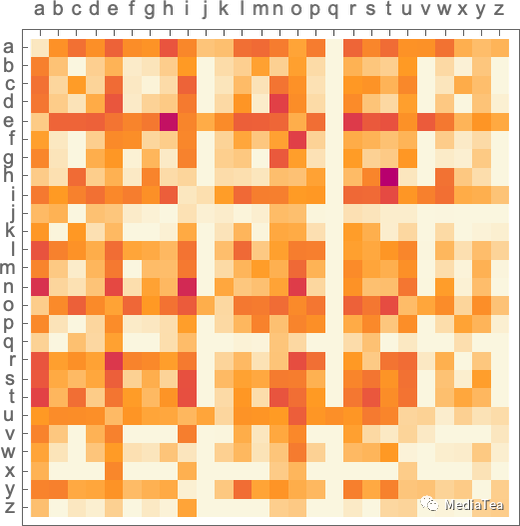
And we see here, for example, that the “q” column is blank (zero probability) except on the “u” row. OK, so now instead of generating our “words” a single letter at a time, let’s generate them looking at two letters at a time, using these “2-gram” probabilities. Here’s a sample of the result—which happens to include a few “actual words”:
我们可以看到,例如,“q”列是空白的(概率为零),除了“u”行。好的,现在,我们不是每次仅随机生成一个字母,而是同时查看两个字母,使用这些“2-gram”概率来生成我们的“单词”。这是结果的一个示例,其中包括一些“实际单词”:
With sufficiently much English text we can get pretty good estimates not just for probabilities of single letters or pairs of letters (2-grams), but also for longer runs of letters. And if we generate “random words” with progressively longer n-gram probabilities, we see that they get progressively “more realistic”:
通过足够多的英文文本,我们不仅可以得到单个字母或一对字母(2-grams)的概率的相当好的估计,还可以得到更长的字母序列的估计。如果我们使用越来越长的 n-gram 概率生成“随机单词”,我们会发现它们变得“更真实”:

But let’s now assume—more or less as ChatGPT does—that we’re dealing with whole words, not letters. There are about 40,000 reasonably commonly used words in English. And by looking at a large corpus of English text (say a few million books, with altogether a few hundred billion words), we can get an estimate of how common each word is. And using this we can start generating “sentences”, in which each word is independently picked at random, with the same probability that it appears in the corpus. Here’s a sample of what we get:
但是现在让我们假设——就像 ChatGPT 一样——我们处理的是整个单词,而不是字母。英语中有大约 40,000 个常用词汇。通过查看大量的英语文本语料库(比如几百亿个单词的数百万本书),我们可以估计每个词汇的常见程度。根据这个,我们可以开始生成“句子”,其中每个词汇都是独立地随机选择的,其概率与它在语料库中出现的概率相同。这是我们得到的一个示例:

Not surprisingly, this is nonsense. So how can we do better? Just like with letters, we can start taking into account not just probabilities for single words but probabilities for pairs or longer n-grams of words. Doing this for pairs, here are 5 examples of what we get, in all cases starting from the word “cat”:
不出所料,这是无意义的。那么我们该怎么做得更好呢?就像字母一样,我们可以开始考虑不仅仅是单词的概率,还有一对或更长的单词 n-grams 的概率。在考虑了一对单词后,以下是我们得到的5个示例,所有示例均从单词“cat”开始:

It’s getting slightly more “sensible looking”. And we might imagine that if we were able to use sufficiently long n-grams we’d basically “get a ChatGPT”—in the sense that we’d get something that would generate essay-length sequences of words with the “correct overall essay probabilities”. But here’s the problem: there just isn’t even close to enough English text that’s ever been written to be able to deduce those probabilities.
这看起来稍微更加“合理”。我们可以想象,如果我们能够使用足够长的 n-grams,我们基本上会“得到一个 ChatGPT”——在这个意义上,我们会得到一个可以生成具有“正确整体概率”的文章长度的单词序列。但问题在于:已经没有足够的英文文本被书写出来,可以推断出这些概率。
In a crawl of the web there might be a few hundred billion words; in books that have been digitized there might be another hundred billion words. But with 40,000 common words, even the number of possible 2-grams is already 1.6 billion—and the number of possible 3-grams is 60 trillion. So there’s no way we can estimate the probabilities even for all of these from text that’s out there. And by the time we get to “essay fragments” of 20 words, the number of possibilities is larger than the number of particles in the universe, so in a sense they could never all be written down.
在网页中爬行可能会有几百亿个单词;在数字化的书籍中可能有另外几百亿个单词。但是,对于 40,000 个常见单词,甚至可能的 2-grams 数量已经达到 16 亿,而可能的 3-grams 数量为 60 万亿。因此,我们无法从已有的文本中估计出所有这些概率。当我们到达 20 个单词的“文章片段”时,可能性的数量已超过宇宙中粒子的数量,因此在某种意义上,它们永远不可能全部被写下来。
So what can we do? The big idea is to make a model that lets us estimate the probabilities with which sequences should occur—even though we’ve never explicitly seen those sequences in the corpus of text we’ve looked at. And at the core of ChatGPT is precisely a so-called “large language model” (LLM) that’s been built to do a good job of estimating those probabilities.
那么我们该怎么办呢?一个重要的想法是创建一个模型,让我们能够估计序列出现的概率——即使我们从未在查看过的文本语料库中明确看到过这些序列。ChatGPT 的核心正是一个被称为“大型语言模型(LLM)的模型,它的目标就是要能够很好地估计这些概率。

“点赞有美意,赞赏是鼓励”