4.6 渲染路径(Rendering Path)
4.6.1 经典顶点光(Legacy Vertex Lit)
严格来说,它也是前向渲染的一种,但有些引擎(如Unity)将它单独抽离出来。由于光照计算在顶点,所以效果和消耗跟4.5.2 Gouraud Shading类似,是早期GPU使用较多的一种渲染方式。
4.6.2 前向渲染(Forward Rendering)
前向渲染是传统的一种渲染方式,受到广泛的硬件支持。它渲染的思路就是按照渲染管线的流程一步步渲染,最终将颜色绘制到Render Target(下图)。
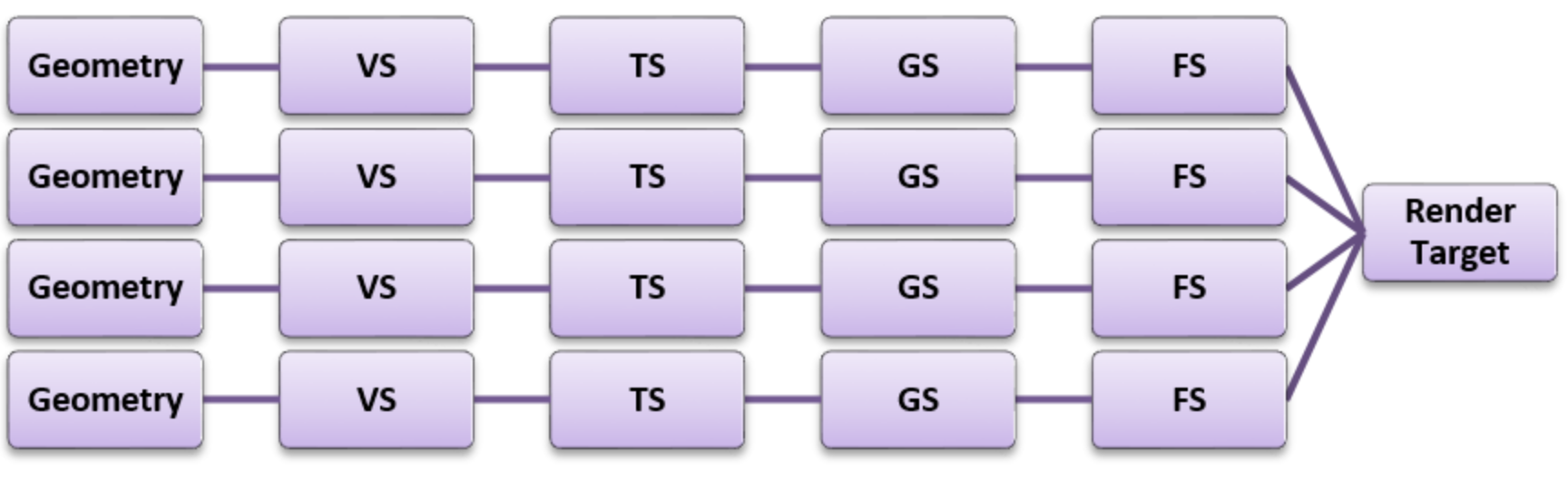
它的消耗跟物体数量和灯光数量有关,是O(Nobject∗Nlight)O(Nobject∗Nlight)的关系,对于灯光数量较多的场景,显得力不从心。光照计算伪代码:
Color color = Color.black;
for each(light in lights)
{
for each(object in objectsEffectedByLight)
{
color += object.color * light.color;
}
}
有些引擎(如Unity)在灯光数量多的情况下,会做一些优化:对所有灯光按亮度进行排序,将最亮的那部分灯光做逐像素计算,中间的一部分做逐顶点计算,排在后面的用球谐函数(SH,Spherical Harmonics)模拟。(见下图)

4.6.3 延迟渲染(Deferred Shading)
延迟渲染的精髓在于将灯光计算延后,与场景物体数量解耦。具体做法是:先将所有物体渲染一遍,但不计算光照,将物体渲染后的像素数据(Position/Normal/DiffuseColor和其他参数)存于各自的GBuffer;然后,利用这些数据采用后处理方式做光照计算。(下图)

实现伪代码:
// 第一遍:渲染物体不带光照的数据,存于各自GBuffer。
for each(object in objects)
{
RenderObjectDataToGBuffers(object);
}
// 第二遍:将所有光照对所有像素做计算。
for each(light in lights)
{
Color color = Color.black;
for each(pixel in pixels)
{
color += CalculateLightColor(light, pixelDatas);
}
WriteColorToFinalRenderTarget(color);
}
由于最耗时的光照计算延迟到后处理阶段,所以跟场景的物体数量解耦,只跟Render Targe尺寸相关,复杂度是O(Nlight∗Wrendertarget∗Hrendertarget)O(Nlight∗Wrendertarget∗Hrendertarget)。延迟渲染并没有在低端设备支持,要求OpenGL ES 3.0以上,多渲染纹理以及更多的显存和带宽。
4.6.4 基于瓦片的延迟渲染(Tile-Based Deferred Rendering,TBDR)
针对Deferred Shading的缺点,出现了一种改进方案,它就是Tile-Based Deferred Rendering。此种渲染方式已广泛应用于GPU图形渲染架构中。实现思路:
- 将渲染纹理分成一个个小块(Tile),通常是32x32。
- 根据Tile内的Depth计算出其Bounding Box。
- 判断Tile的Bounding Box和Light是否求交。
- 摒弃不相交的Light,得到对Tile有作用的Light列表。
- 遍历所有Tile,计算每个Tile有作用的Llight列表的光照。
4.6.5 渲染路径总结
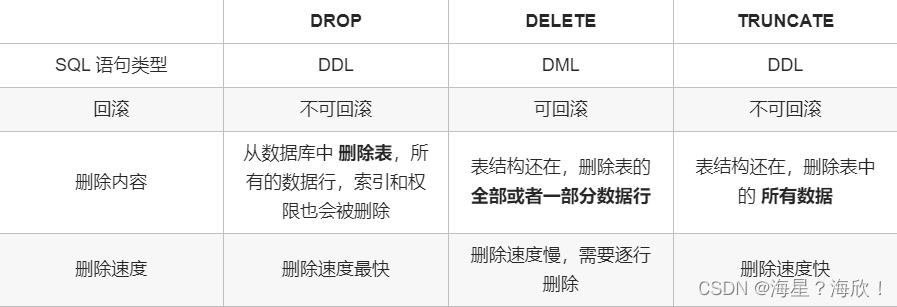
前面已经描述了各个方式的优缺点,下面详细列出它们的性能消耗及平台要求。
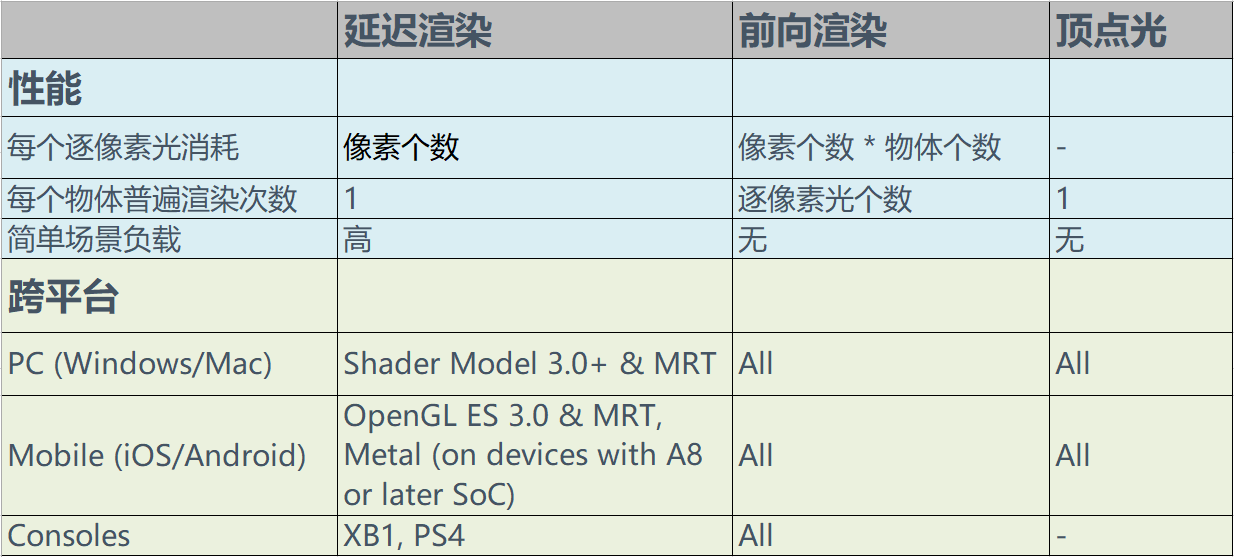
此外,还有Forward+,Physically Based Rendering(PBR),Legacy Deferred Rendering(Unity)等渲染方式,这里不详细描述,有兴趣的可以找资料了解。

![[附源码]计算机毕业设计基于协同过滤的资讯推送平台Springboot程序](https://img-blog.csdnimg.cn/7f9c151cc99e4115ac3f2a411b09a248.png)