ChatGPT一经发布就在科技圈火得不行,这两天也是被传得神乎其神,听说它写得了代码、改得了 Bug,小说、段子统统不再话下!那他到底是怎么训练成现在这样的呢?本文介绍李宏毅老师的分析。
那么接下来我们就来介绍Chat GPT是怎样练成的!
1.找寻资料参考:
李老师在翻看OpenAI的博客发现,其目前并没有发表关于ChatGPT的论文。但是!在OpenAI官方博客介绍中,我们可以发现CharGPT有一个兄弟,InstructGPT,因此他决定依靠InstructGPT去寻找一些ChatGPT的训练逻辑。

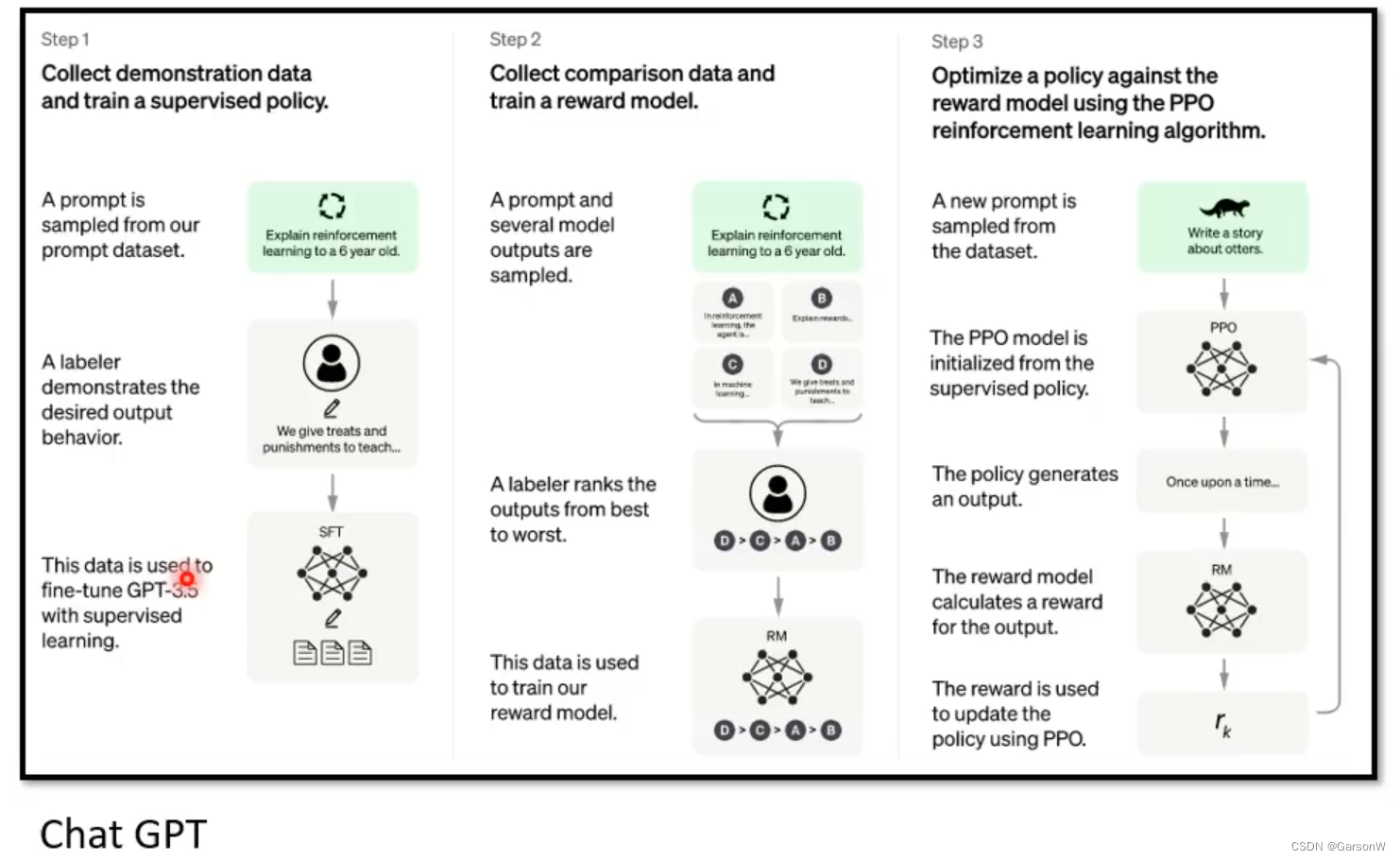
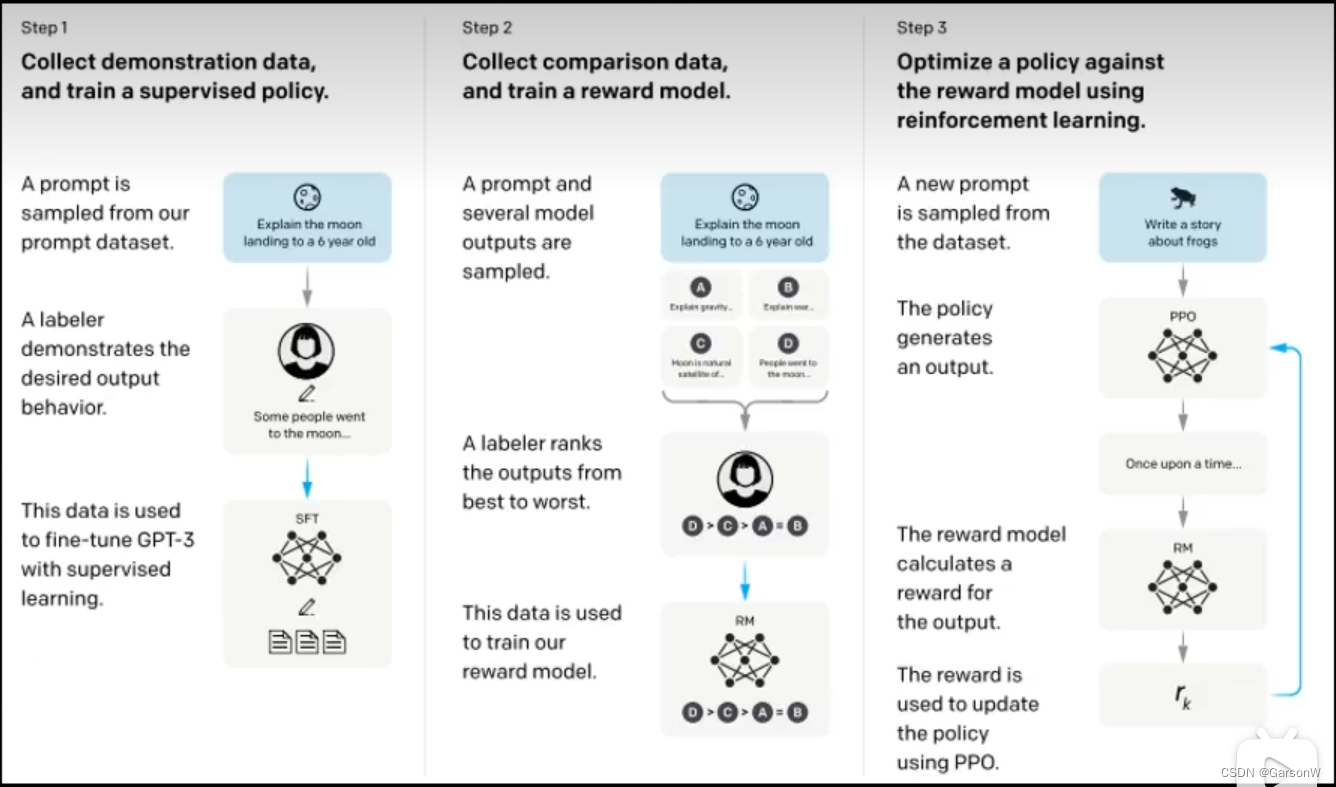
当我们看到ChatGPT与InstructGPT的对比时,更加坚定的确定通过InstructGPT是可以找到ChatGPT模型的蛛丝马迹的。如下,上面为ChartGPT的训练流程下面为InstructGPT的流程图。可以说像的7788了,比较面明显的区别其实只有GPT的版本不同而已,前者是GPT3.5,后者是GPT3。所以李老师决定直接分析InstructGPT来推测Chat GPT是怎样练成的!
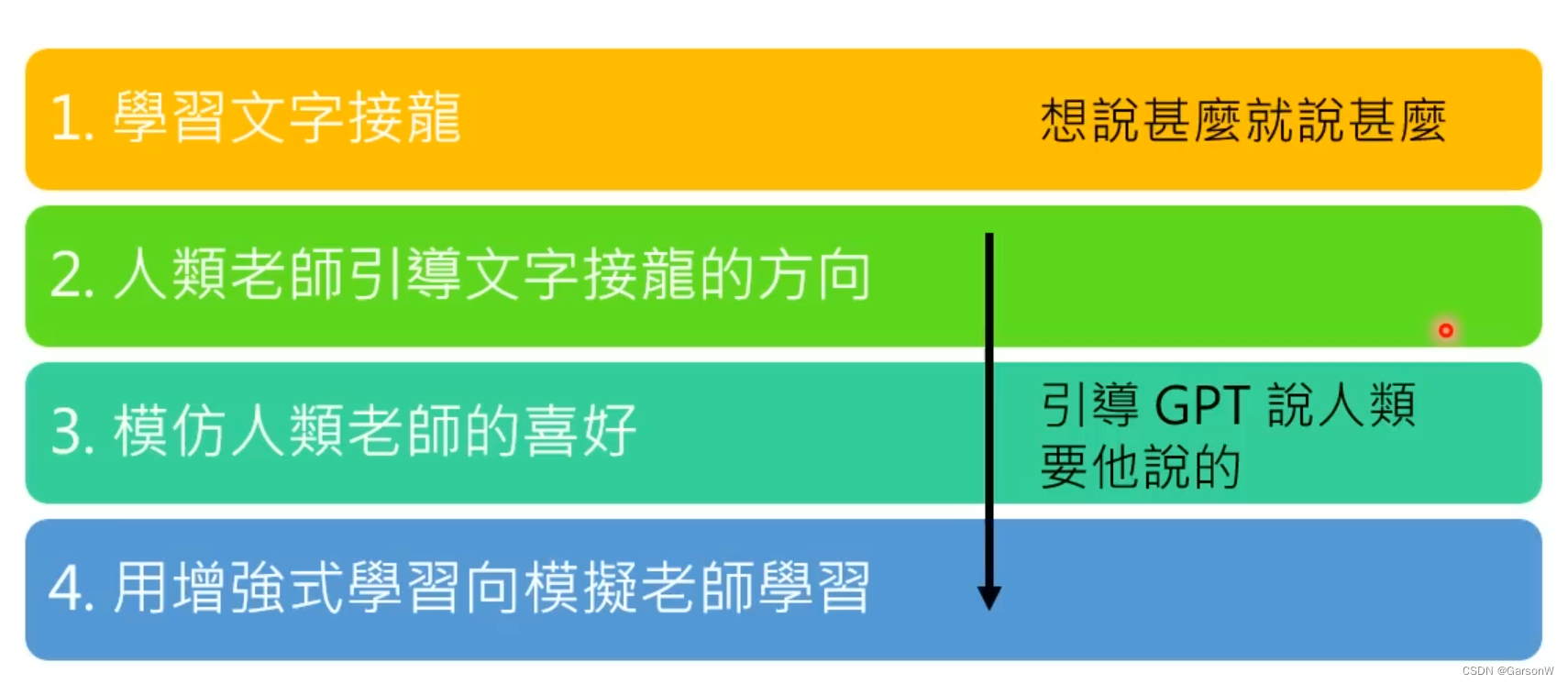
2.正式开始介绍Chat GPT的学习四阶段:

2.1 学习文字接龙
学习文字接龙,其实就是依据目前已有的信息,去推测下一个可能出现的字,以此类推。与我们在学习机器学习中的文字翻译Transformer架构很相似。
正如下面的例子所演示的,当我们有目前有:“你好”这一个不完整的句子的时候,程序可以基于在互联网上学习到的知识去预测下一个字,有可能是 “美”
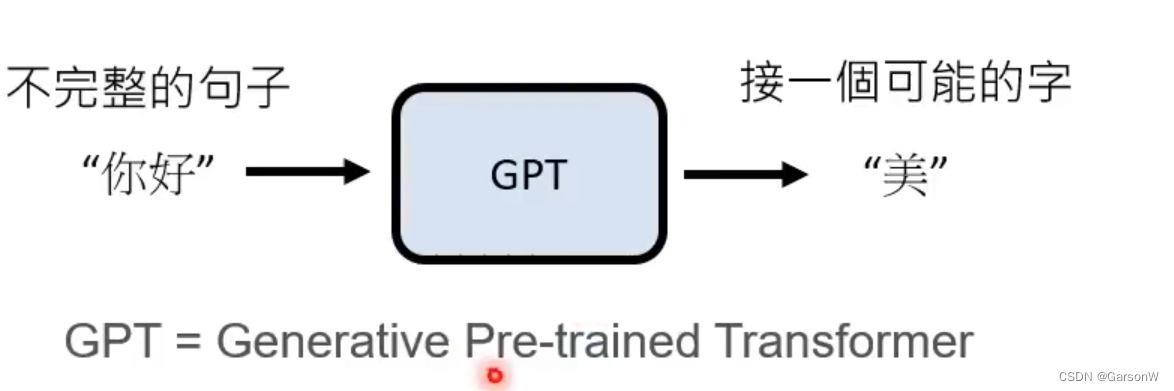
这种学习的好处是,我们并不需要人工标注出机器需要训练的内容,只需要把他放到互联网上,看到文字就自我学习文字接龙即可。
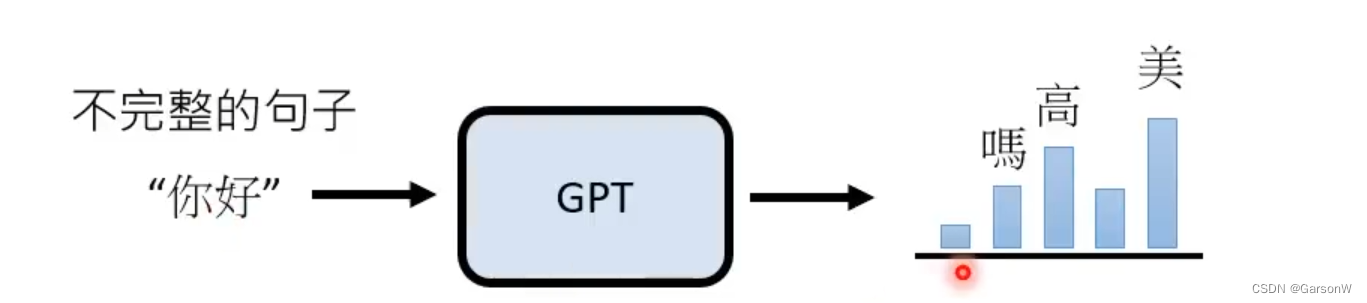
但是,坏处也显而易见了,对于一个不完整的句子,我们后面的词可以是很多种多样的,比如说在 “你好” 后面,我们可以接上 “吗” 、 “高”、“美” 等,所以GPT返回的其实是一个概率分布,也就是说每次回答的内容其实都是随机的。这次说 “你好吗”,下次可能就说 “你好美了” 。
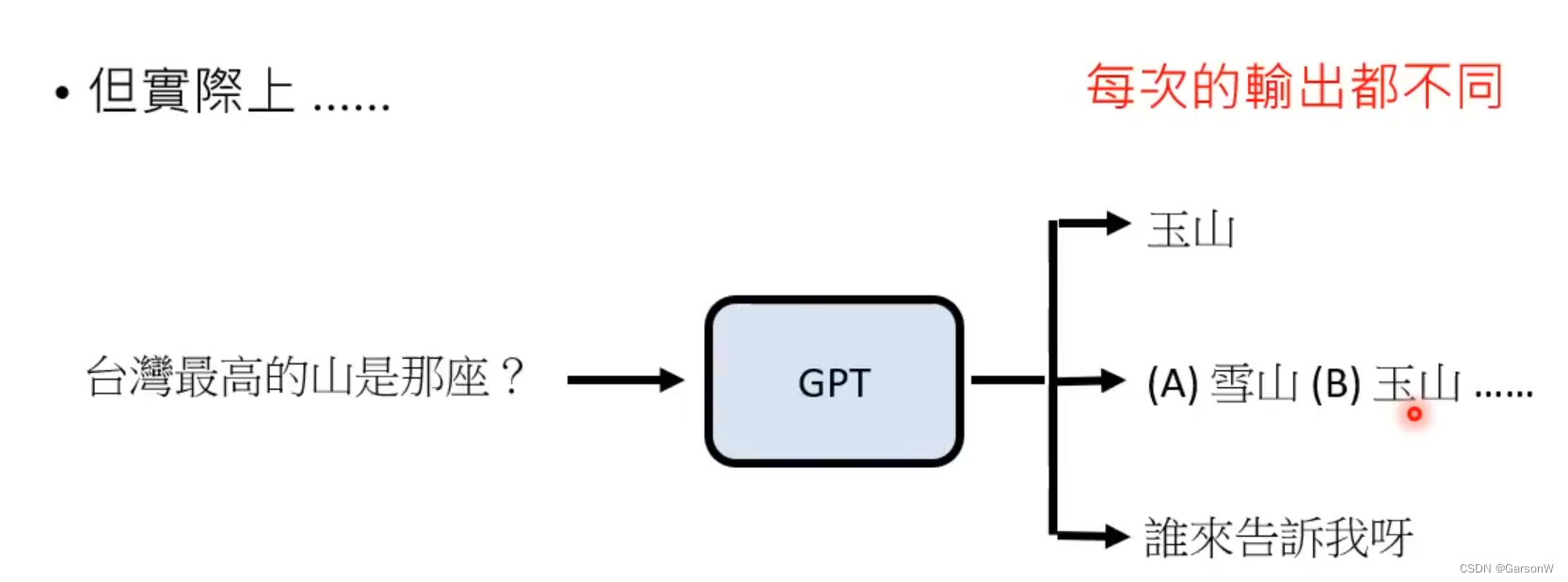
但是单单依靠文字接龙,其实GPT就已经可以回答问题了。比如下面的例子,我们问出“台湾最高的山是哪座?” 当GPT在网上看过这么多资料,它通过文字接龙的形式回答,可能可以直接回答出玉山,也可能给你出一道选择题(如果他读过的资料是这么连接起来的),也可能反问你 “谁来告诉我呀?”
2.2 人类老师引导文字接龙方向
经过了文字接龙,我们会发现GPT虽然能回答我们的问题,但是并不一定能回答出我们想要的答案。说白了就是人工来筛选哪些是我们需要的答案(还是逃离不了有多人工就有多智能呐!)
2.3 模仿人类老师的喜好
人类希望获得的答案就会被赋予更高的分数
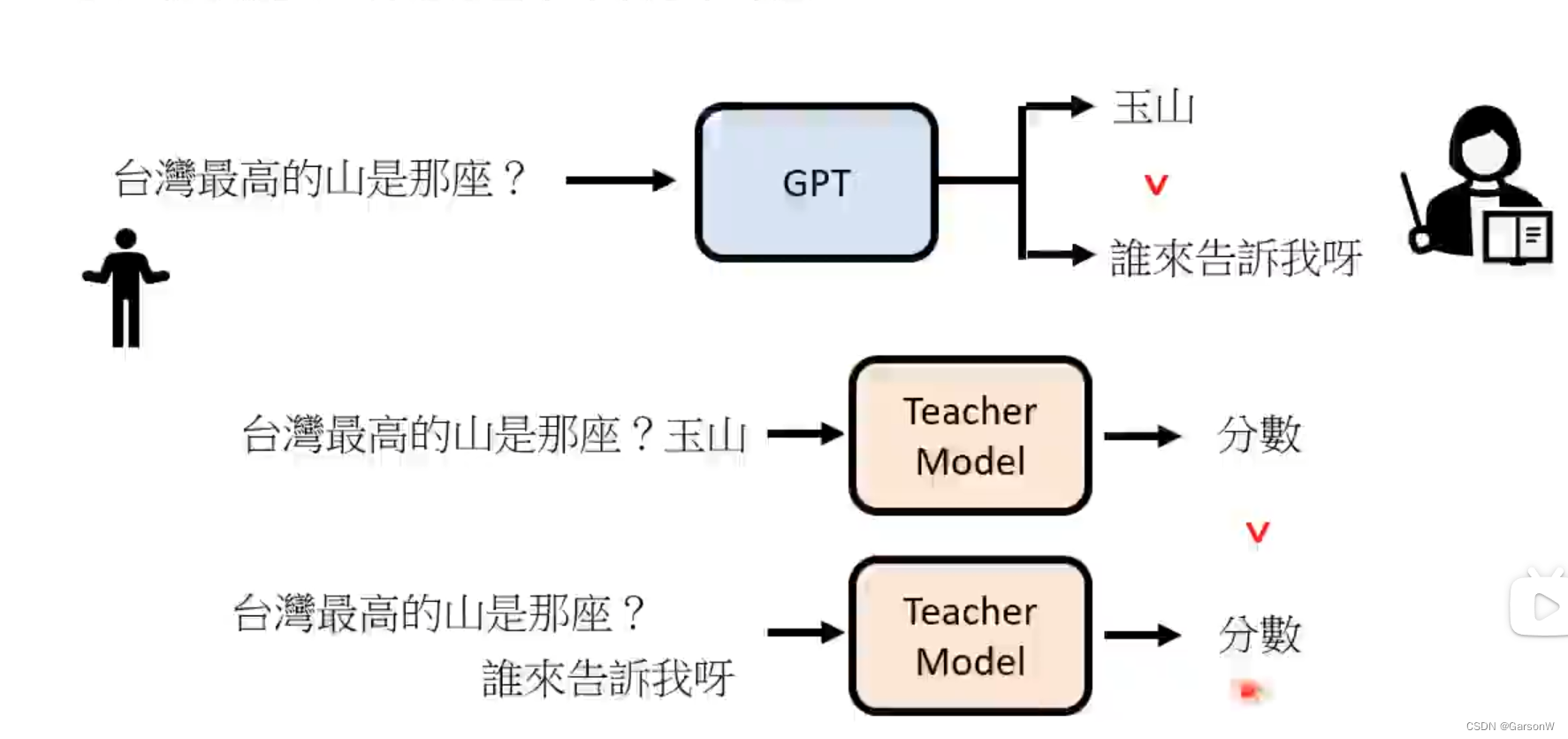
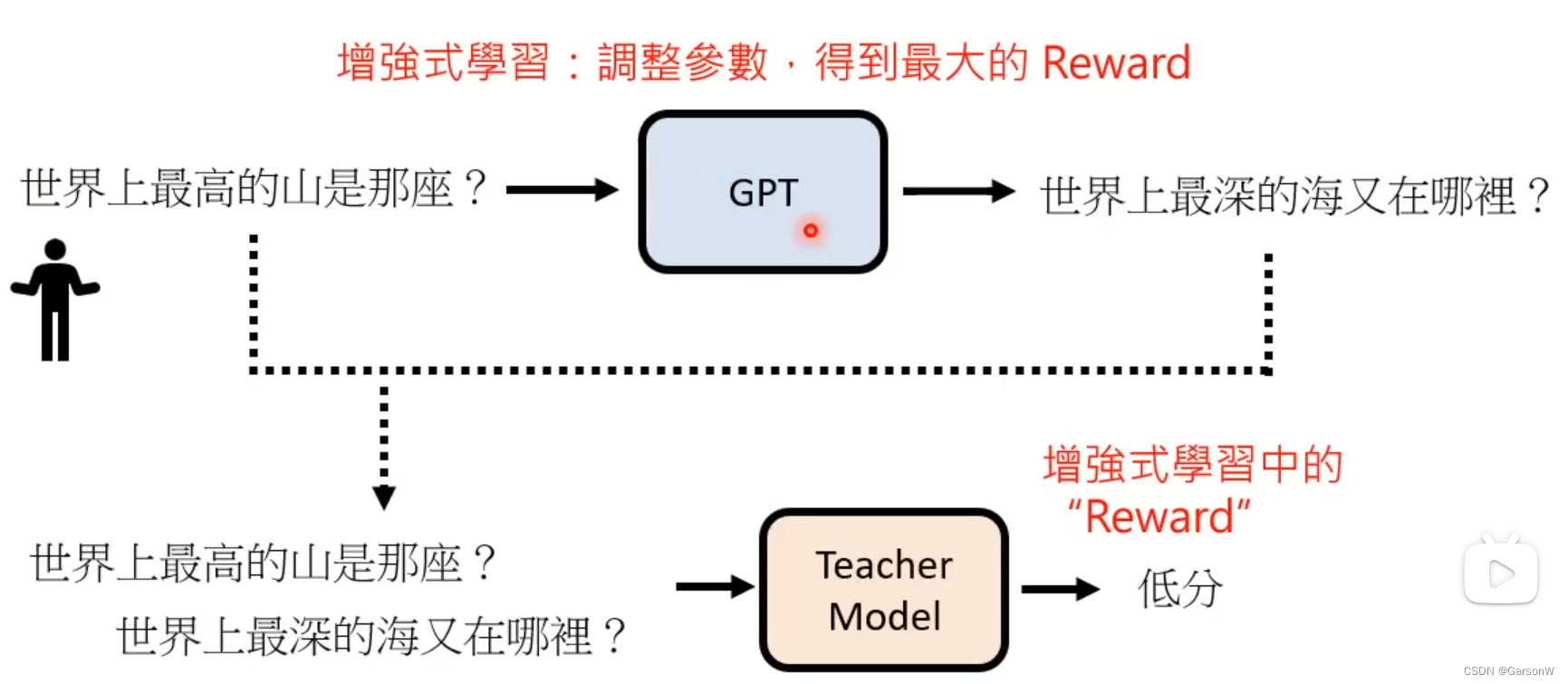
2.4 使用增强向模拟老师学习
就是我们将每次GPT得到的答案都丢给TeacherModel来评判,如果是人类希望的答案就给高分,如果不是则给低分,这个模式被称为增强式学习种的“Reward”模块
3. 当然,ChatGPT目前并不是完美的...
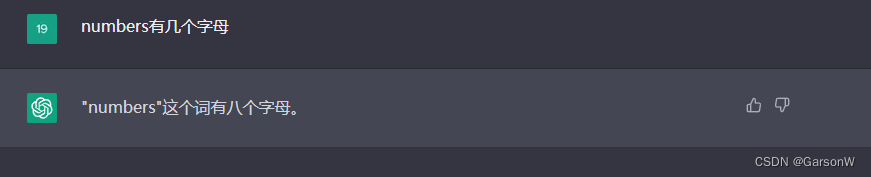
目前ChatGPT模型已经很难再被找到错误了,但是根据上面的分析,我们只需要问出一些没有人问过的内容,他就回答不出来了。比如说:我问 “numbers”是由几个字母组成的,他会回答八个,这是八个吗???这明明就是七个!!!
4.总结
李宏毅老师认为ChatGPT是GPT的社会化过程,从一开始的想说什么就说什么,一直到后面的人类引导他说出期望的答案。


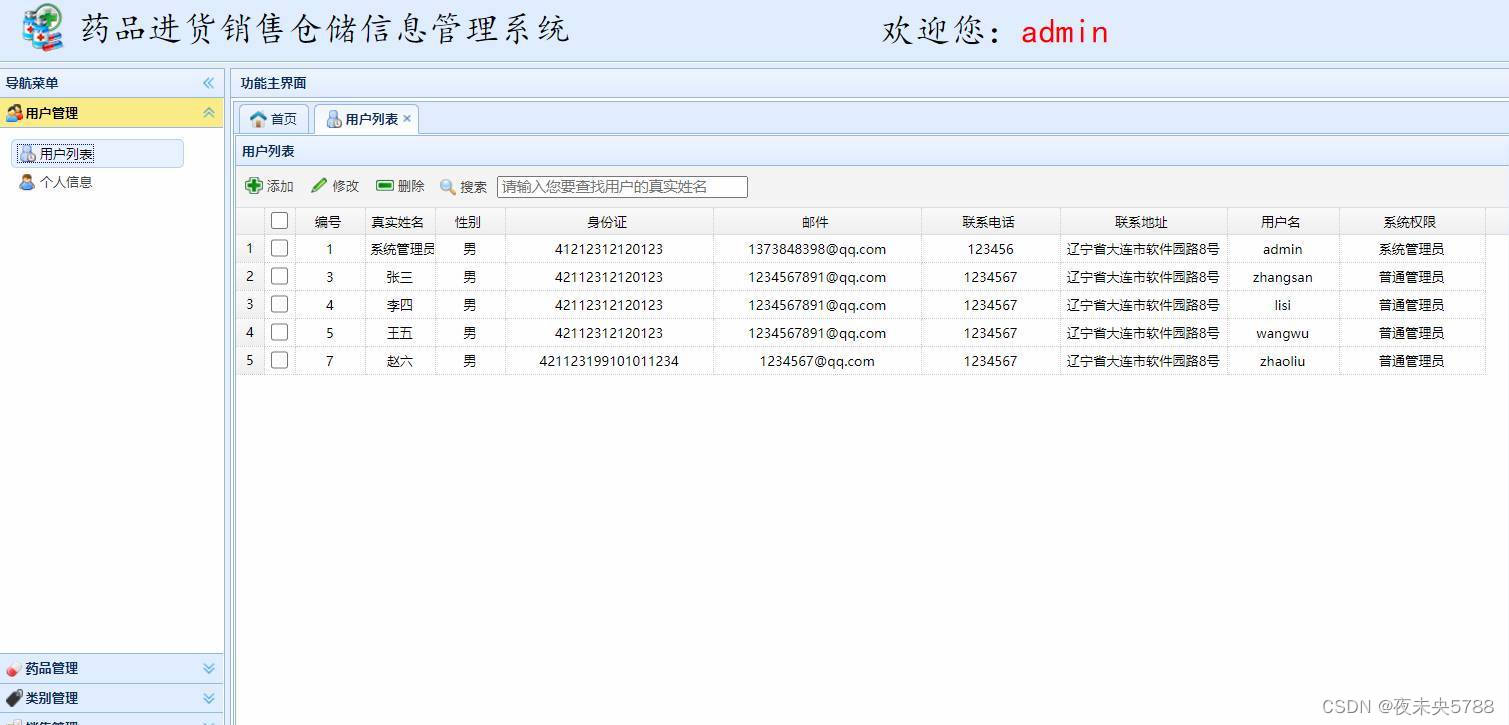
![[附源码]Python计算机毕业设计SSM基于的优质房源房租管理系统(程序+LW)](https://img-blog.csdnimg.cn/2e9e0174262a424786318e4b4eaee57b.png)