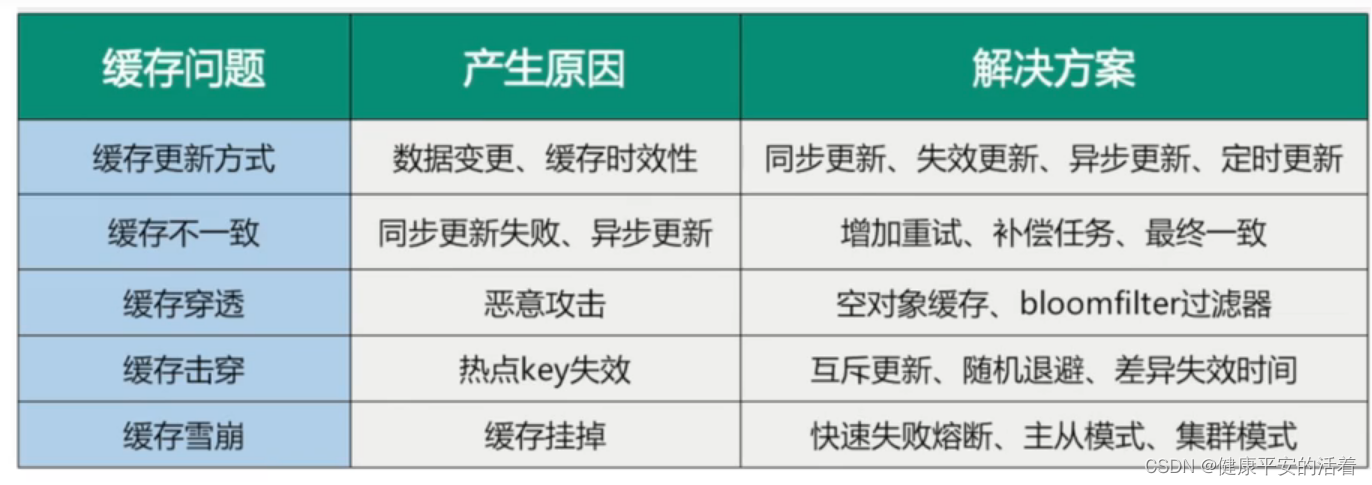
0、kafka常用命令
Kafka是一个分布式流处理平台,它具有高度可扩展性和容错性。以下是Kafka最新版本中常用的一些命令:
-
创建一个主题(topic):
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092 -
查看主题列表:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092 -
查看主题的详细信息:
bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092 -
发送消息到主题:
bin/kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092 -
从主题消费消息:
bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9092 -
查看消费者组的偏移量(offset):
bin/kafka-consumer-groups.sh --describe --group my-group --bootstrap-server localhost:9092 -
启动Kafka服务:
bin/kafka-server-start.sh config/server.properties
一、如果是zk单节点
- 下载并启动zk http://bit.ly/2sDWSgJ。 单机服务 下⾯的例⼦演⽰了如何使⽤基本的配置安装 Zookeeper,安装⽬录为 /usr/local/zookeeper, 数据⽬录为 /var/lib/zookeeper。
- 启动zk
-
# tar -zxf zookeeper-3.4.6.tar.gz # mv zookeeper-3.4.6 /usr/local/zookeeper # mkdir -p /var/lib/zookeeper # cat > /usr/local/zookeeper/conf/zoo.cfg << EOF tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 > EOF # export JAVA_HOME=/usr/java/jdk1.8.0_51 # /usr/local/zookeeper/bin/zkServer.sh start JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED - 确认2181端口开启
telnet localhost 2181
ss -luntp|grep 2181二、如果是zk集群
一般选择3或者5个基数节点
修改群组配置文件,增加my.id文件和配置项
vim /usr/local/zookeeper/conf/zoo.cfg
myid=1
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888其中initLimit 表⽰⽤于在从节点与主节点之间建⽴初始化连接的时间上限, syncLimit 表⽰允许从节点与主节点处于不同步状态的时间上限,这两个值都是 tickTime 的 倍数,所以 initLimit 是 20*2000ms,也就是 40s
配置⾥还列出了群组中所有服务器的地 址。服务器地址遵循 server.X=hostname:peerPort:leaderPort
除了公共的配置⽂件外,每个服务器都必须在 data Dir ⽬录中创建⼀个叫作 myid 的⽂件,⽂ 件⾥要包含服务器 ID,这个 ID 要与配置⽂件⾥配置的 ID 保持⼀致。完成这些步骤后,就可以 启动服务器,让它们彼此间进⾏通信了。
三、安装kafka
下载kafkaApache Kafka下载最新版本的 Kafkahttps://downloads.apache.org/kafka/3.5.1/kafka_2.12-3.5.1.tgz
# tar -zxvf kafka_2.12-3.5.1.tgz
mv kafka_2.12-3.5.1 /usr/local/kafka
mkdir /tmp/kafka-logs
# export JAVA_HOME=/usr/java/jdk1.8.0_51
/usr/local/kafka/bin/kafka-server-start.sh -daemon
/usr/local/kafka/config/server.properties
查看kafka是否启动
查看kafka是否报错
ps -ef|grep kafka
测试是否正常安装,备注新版本不需要以来zook
kafka版本过高所致,2.2+=的版本,已经不需要依赖zookeeper来查看/创建topic,新版本使用 --bootstrap-server替换老版本的 --zookeeper-server。
创建topic
老版本kafka
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
新版本kafka
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server 172.18.207.104:9092 --create --replication-factor 1 --partitions 1 --topic test
Created topic test.
列出topic
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 172.18.207.104:9092
test
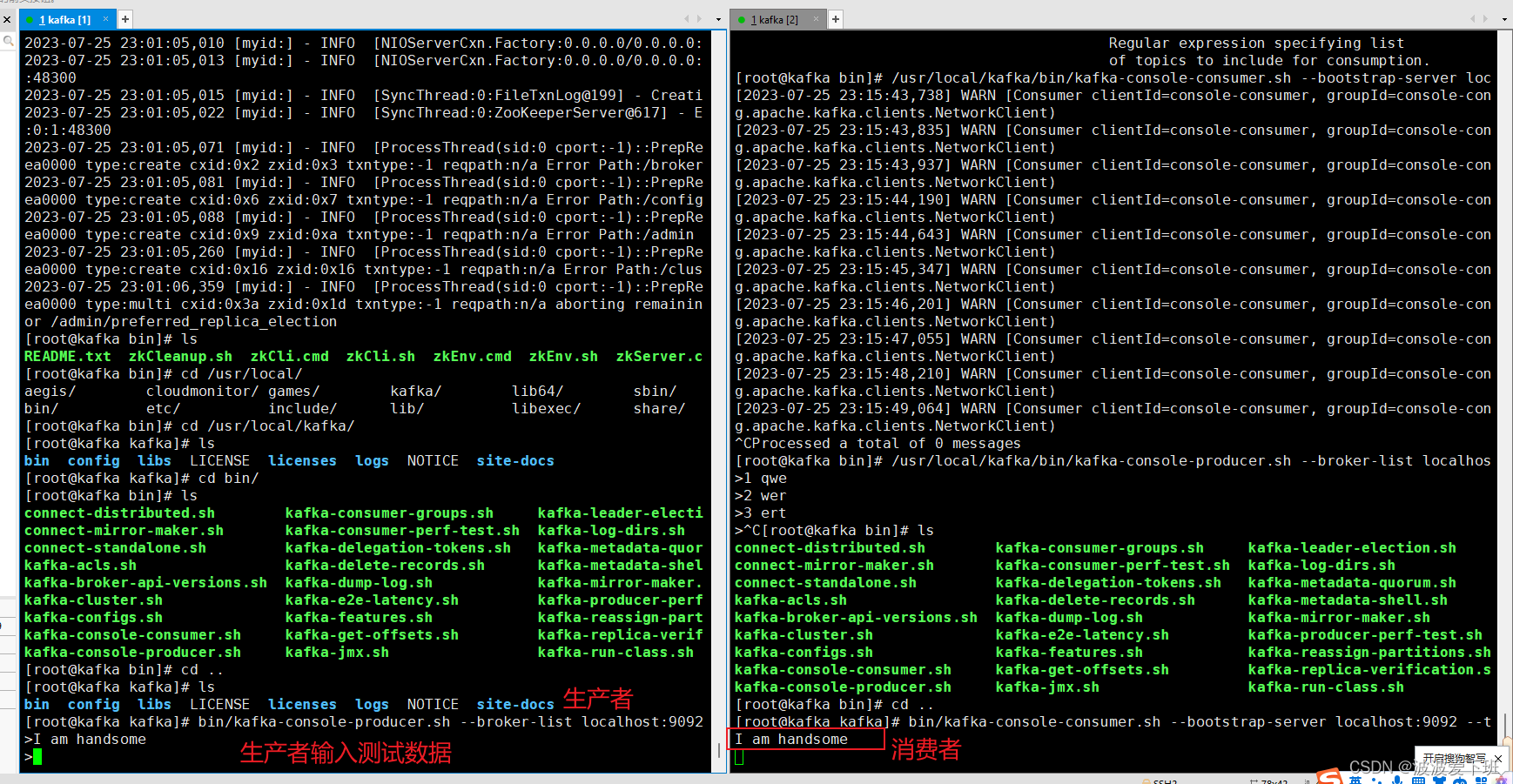
4 启动消费端接收消息
命令:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test执行上述命令红不要关闭窗口,继续并执行下面的生产端命令
5 生产端发送消息
命令:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test在生产端输入消息:I am handsome 然后回车,在消费端4查看会发现实施消费,前提是在同一个topic下
三、kafka集群配置
3.1 broker配置(好好看一遍)
3.1.1 broker.id
每个 broker 都需要有⼀个标识符,使⽤ broker.id 来表⽰。它的默认值是 0,也可以被设置成 其他任意整数。这个值在整个 Kafka 集群⾥必须是唯⼀的。这个值可以任意选定,如果出于维护 的需要,可以在服务器节点间交换使⽤这些 ID。建议把它们设置成与机器名具有相关性的整数, 这样在进⾏维护时,将 ID 号映射到机器名就没那么⿇烦了。例如,如果机器名包含唯⼀性的数 字(⽐如 host1.example.com、host2.example.com),那么⽤这些数字来设置 broker.id 就 再好不过了。
02. port 如果使⽤配置样本来启动 Kafka,它会监听 9092 端⼝。修改 port 配置参数可以把它设置成其 他任意可⽤的端⼝。要注意,如果使⽤ 1024 以下的端⼝,需要使⽤ root 权限启动 Kafka,不 过不建议这么做。
03 zookeeper.connect ⽤于保存 broker 元数据的 Zookeeper 地址是通过 zookeeper.connect 来指定的。 localhost:2181 表⽰这个 Zookeeper 是运⾏在本地的 2181 端⼝上。该配置参数是⽤冒号 分隔的⼀组 hostname:port/path 列表,每⼀部分的含义如下: hostname 是 Zookeeper 服务器的机器名或 IP 地址; port 是 Zookeeper 的客户端连接端⼝; /path 是可选的 Zookeeper 路径,作为 Kafka 集群的 chroot 环境。如果不指定,默认使 ⽤根路径。 如果指定的 chroot 路径不存在,broker 会在启动的时候创建它。
在 Kafka 集群⾥使⽤ chroot 路径是⼀种最佳实践。Zookeeper 群组可以共享给其他应⽤ 程序,即使还有其他 Kafka 集群存在,也不会产⽣冲突。最好是在配置⽂件⾥指定⼀组 Zookeeper 服务器,⽤分号把它们隔开。⼀旦有⼀个 Zookeeper 服务器宕机,broker 可 以连接到 Zookeeper 群组的另⼀个节点上。
04. log.dirs Kafka 把所有消息都保存在磁盘上,存放这些⽇志⽚段的⽬录是通过 log.dirs 指定的。它是⼀组 ⽤逗号分隔的本地⽂件系统路径。如果指定了多个路径,那么 broker 会根据“最少使⽤”原则, 把同⼀个分区的⽇志⽚段保存到同⼀个路径下。要注意,broker 会往拥有最少数⽬分区的路径新 增分区,⽽不是往拥有最⼩磁盘空间的路径新增分区。
05. num.recovery.threads.per.data.dir 对于如下 3 种情况,Kafka 会使⽤可配置的线程池来处理⽇志⽚段: 服务器正常启动,⽤于打开每个分区的⽇志⽚段; 服务器崩溃后重启,⽤于检查和截短每个分区的⽇志⽚段; 服务器正常关闭,⽤于关闭⽇志⽚段。 默认情况下,每个⽇志⽬录只使⽤⼀个线程。因为这些线程只是在服务器启动和关闭时会⽤到, 所以完全可以设置⼤量的线程来达到并⾏操作的⽬的。特别是对于包含⼤量分区的服务器来说, ⼀旦发⽣崩溃,在进⾏恢复时使⽤并⾏操作可能会省下数⼩时的时间。设置此参数时需要注意, 所配置的数字对应的是 log.dirs 指定的单个⽇志⽬录。也就是说,如果 num.recovery.threads.per.data.dir 被设为 8,并且 log.dir 指定了 3 个路径,那么 总共需要 24 个线程。
06. auto.create.topics.enable 默认情况下,Kafka 会在如下⼏种情形下⾃动创建主题: 当⼀个⽣产者开始往主题写⼊消息时; 当⼀个消费者开始从主题读取消息时; 当任意⼀个客户端向主题发送元数据请求时。 很多时候,这些⾏为都是⾮预期的。⽽且,根据 Kafka 协议,如果⼀个主题不先被创建,根本⽆ 法知道它是否已经存在。如果显式地创建主题,不管是⼿动创建还是通过其他配置系统来创建, 都可以把 auto.create.topics.enable 设为 false。
3.1.2 主题的默认配置(了解)
01. num.partitions
num.partitions 参数指定了新创建的主题将包含多少个分区,该参数的默认值是 1。要注意, 我们可以增加主题分区的个数,但不能减少分区的个数。所以,如果要让⼀个主题的分区个数少 于 num.partitions 指定的值,需要⼿动创建该主题
如何选定分区数量
为主题选定分区数量并不是⼀件可有可⽆的事情,在进⾏数量选择时,需要考虑如下⼏个因 素。
如果不知道这些信息,那么根据经验,把分区的⼤⼩限制在 25GB 以内可以得到⽐较理想的效 果。
02. log.retention.ms
Kafka 通常根据时间来决定数据可以被保留多久。默认使⽤ log.retention.hours 参数来配 置时间,默认值为 168 ⼩时,也就是⼀周。除此以外,还有其他两个参数 log.retention.minutes 和 log.retention.ms。这 3 个参数的作⽤是⼀样的,都是决定 消息多久以后会被删除,不过还是推荐使⽤ log.retention.ms。如果指定了不⽌⼀个参数, Kafka 会优先使⽤具有最⼩值的那个参数
03. log.retention.bytes 另⼀种⽅式是通过保留的消息字节数来判断消息是否过期。它的值通过参数 log.retention.bytes 来指定,作⽤在每⼀个分区上。也就是说,如果有⼀个包含 8 个分区 的主题,并且 log.retention.bytes 被设为 1GB,那么这个主题最多可以保留 8GB 的数 据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。
如果同时指定了 log.retention.bytes 和 log.retention.ms(或者另⼀个时间参 数),只要任意⼀个条件得到满⾜,消息就会被删除
04. log.segment.bytes 以上的设置都作⽤在⽇志⽚段上,⽽不是作⽤在单个消息上。当消息到达 broker 时,它们被追 加到分区的当前⽇志⽚段上。当⽇志⽚段⼤⼩达到 log.segment.bytes 指定的上限(默认是 1GB)时,当前⽇志⽚段就会被关闭,⼀个新的⽇志⽚段被打开。如果⼀个⽇志⽚段被关闭,就 开始等待过期。这个参数的值越⼩,就会越频繁地关闭和分配新⽂件,从⽽降低磁盘写⼊的整体 效率。
⽇志⽚段的⼤⼩会影响使⽤时间戳获取偏移量。在使⽤时间戳获取⽇志偏移量时,Kafka 会 检查分区⾥最后修改时间⼤于指定时间戳的⽇志⽚段(已经被关闭的),该⽇志⽚段的前⼀ 个⽂件的最后修改时间⼩于指定时间戳。然后,Kafka 返回该⽇志⽚段(也就是⽂件名)开 头的偏移量。对于使⽤时间戳获取偏移量的操作来说,⽇志⽚段越⼩,结果越准确。
3.2需要多少个broker
⼀个 Kafka 集群需要多少个 broker 取决于以下⼏个因素。⾸先,需要多少磁盘空间来保留数据,以 及单个 broker 有多少空间可⽤。如果整个集群需要保留 10TB 的数据,每个 broker 可以存储 2TB,那么⾄少需要 5 个 broker。如果启⽤了数据复制,那么⾄少还需要⼀倍的空间,不过这要取决 于配置的复制系数是多少(将在第 6 章介绍)。也就是说,如果启⽤了数据复制,那么这个集群⾄少 需要 10 个 broker。
第⼆个要考虑的因素是集群处理请求的能⼒。这通常与⽹络接⼝处理客户端流量的能⼒有关,特别是 当有多个消费者存在或者在数据保留期间流量发⽣波动(⽐如⾼峰时段的流量爆发)时。如果单个 broker 的⽹络接⼝在⾼峰时段可以达到 80% 的使⽤量,并且有两个消费者,那么消费者就⽆法保持 峰值,除⾮有两个 broker。如果集群启⽤了复制功能,则要把这个额外的消费者考虑在内。因磁盘吞 吐量低和系统内存不⾜造成的性能问题,也可以通过扩展多个 broker 来解决。
3.2.1 broker配置
要把⼀个 broker 加⼊到集群⾥,只需要修改两个配置参数。⾸先,所有 broker 都必须配置相同的 zookeeper.connect,该参数指定了⽤于保存元数据的 Zookeeper 群组和路径。
其次,每个 broker 都必须为 broker.id 参数设置唯⼀的值。
3.2.2为什么不把 vm.swappiness 设为零?
先前,⼈们建议尽量把 vm.swapiness 设为 0,它意味着“除⾮发⽣内存溢出,否则不要进 ⾏内存交换”。直到 Linux 内核 3.5-rc1 版本发布,这个值的意义才发⽣了变化。这个变化被 移植到其他的发⾏版上,包括 Red Hat 企业版内核 2.6.32-303。在发⽣变化之后,0 意味 着“在任何情况下都不要发⽣交换”。所以现在建议把这个值设为 1。
3.2.3脏页
脏⻚会被冲刷到磁盘上,调整内核对脏⻚的处理⽅式可以让我们从中获益。Kafka 依赖 I/O 性能 为⽣产者提供快速的响应。这就是为什么⽇志⽚段⼀般要保存在快速磁盘上,不管是单个快速磁 盘(如 SSD)还是具有 NVRAM 缓存的磁盘⼦系统(如 RAID)。这样⼀来,在后台刷新进程将 脏⻚写⼊磁盘之前,可以减少脏⻚的数量,这个可以通过将 vm.dirty_background_ratio 设为⼩于 10 的值来实现。该值指的是系统内存的百分⽐,⼤部分情况下设为 5 就可以了。它不 应该被设为 0,因为那样会促使内核频繁地刷新⻚⾯,从⽽降低内核为底层设备的磁盘写⼊提供 缓冲的能⼒。
通过设置 vm.dirty_ratio 参数可以增加被内核进程刷新到磁盘之前的脏⻚数量,可以将它设 为⼤于 20 的值(这也是系统内存的百分⽐)。这个值可设置的范围很⼴,60~80 是个⽐较合理 的区间。不过调整这个参数会带来⼀些⻛险,包括未刷新磁盘操作的数量和同步刷新引起的⻓时 间 I/O 等待。如果该参数设置了较⾼的值,建议启⽤ Kafka 的复制功能,避免因系统崩溃造成数 据丢失。 为了给这些参数设置合适的值,最好是在 Kafka 集群运⾏期间检查脏⻚的数量,不管是在⽣存环 境还是模拟环境。可以在 /proc/vmstat ⽂件⾥查看当前脏⻚数量
cat /proc/vmstat | egrep "dirty|writeback"3.2.4文件系统
不管使⽤哪⼀种⽂件系统来存储⽇志⽚段,最好要对挂载点的 noatime 参数进⾏合理的设置。 ⽂件元数据包含 3 个时间戳:创建时间(ctime)、最后修改时间(mtime)以及最后访问时间 (atime)。默认情况下,每次⽂件被读取后都会更新 atime,这会导致⼤量的磁盘写操作,⽽ 且 atime 属性的⽤处不⼤,除⾮某些应⽤程序想要知道某个⽂件在最近⼀次修改后有没有被访问 过(这种情况可以使⽤ realtime)。Kafka ⽤不到该属性,所以完全可以把它禁⽤掉。为挂载 点设置 noatime 参数可以防⽌更新 atime,但不会影响 ctime 和 mtime
3.2.5网络,用到了查哈怎么该
⽹络 默认情况下,系统内核没有针对快速的⼤流量⽹络传输进⾏优化,所以对于应⽤程序来说,⼀般 需要对 Linux 系统的⽹络栈进⾏调优,以实现对⼤流量的⽀持。实际上,调整 Kafka 的⽹络配 置与调整其他⼤部分 Web 服务器和⽹络应⽤程序的⽹络配置是⼀样的。⾸先可以对分配给 socket 读写缓冲区的内存⼤⼩作出调整,这样可以显著提升⽹络的传输性能。socket 读写缓冲 区对应的参数分别是 net.core.wmem_default 和 net.core.rmem_default,合理的值是 131 072(也就是 128KB)。读写缓冲区最⼤值对应的参数分别是 net.core.wmem_max 和 net.core.rmem_max,合理的值是 2 097 152(也就是 2MB)。要注意,最⼤值并不意味着 每个 socket ⼀定要有这么⼤的缓冲空间,只是说在必要的情况下才会达到这个值。 除了设置 socket 外,还需要设置 TCP socket 的读写缓冲区,它们的参数分别是 net.ipv4.tcp_wmem 和 net.ipv4.tcp_rmem。这些参数的值由 3 个整数组成,它们使⽤空 格分隔,分别表⽰最⼩值、默认值和最⼤值。最⼤值不能⼤于 net.core.wmem_max 和 net.core.rmem_max 指定的⼤⼩。例如,“4096 65536 2048000”表⽰最⼩值是 4KB、默认 值是 64KB、最⼤值是 2MB。根据 Kafka 服务器接收流量的实际情况,可能需要设置更⾼的最⼤ 值,为⽹络连接提供更⼤的缓冲空间。 还有其他⼀些有⽤的⽹络参数。例如,把 net.ipv4.tcp_window_scaling 设为 1,启⽤ TCP 时间窗扩展,可以提升客户端传输数据的效率,传输的数据可以在服务器端进⾏缓冲。把 net.ipv4.tcp_max_syn_backlog 设为⽐默认值 1024 更⼤的值,可以接受更多的并发连 接。把 net.core.netdev_max_backlog 设为⽐默认值 1000 更⼤的值,有助于应对⽹络流 量的爆发,特别是在使⽤千兆⽹络的情况下,允许更多的数据包排队等待内核处理。
还是建议使⽤最新版本的 Kafka,让消费者把偏移量提交到 Kafka 服务器上,消除对 Zookeeper 的依赖。
虽然多个 Kafka 集群可以共享⼀个 Zookeeper 群组,但如果有可能的话,不建议把 Zookeeper 共 享给其他应⽤程序。Kafka 对 Zookeeper 的延迟和超时⽐较敏感,与 Zookeeper 群组之间的⼀个 通信异常就可能导致 Kafka 服务器出现⽆法预测的⾏为。这样很容易让多个 broker 同时离线,如果 它们与 Zookeeper 之间断开连接,也会导致分区离线
四、Kafka ⽣产者——向 Kafka 写⼊数据
在⼀个信⽤卡事务处理系统⾥,有⼀个客户端应⽤程序,它可能是⼀个在线商店,每当有⽀付 ⾏为发⽣时,它负责把事务发送到 Kafka 上。另⼀个应⽤程序根据规则引擎检查这个事务,决定是批 准还是拒绝。批准或拒绝的响应消息被写回 Kafka,然后发送给发起事务的在线商店。第三个应⽤程 序从 Kafka 上读取事务和审核状态,把它们保存到数据库,随后分析师可以对这些结果进⾏分析,或 许还能借此改进规则引擎。
在这⼀章,我们将从 Kafka ⽣产者的设计和组件讲起,学习如何使⽤ Kafka ⽣产者。我们将演⽰如 何创建 KafkaProducer 和 ProducerRecords 对象、如何将记录发送给 Kafka,以及如何处理从 Kafka 返回的错误,然后介绍⽤于控制⽣产者⾏为的重要配置选项,最后深⼊探讨如何使⽤不同的分 区⽅法和序列化器,以及如何⾃定义序列化器和分区器。
第三⽅客户端 除了内置的客户端外,Kafka 还提供了⼆进制连接协议,也就是说,我们直接向 Kafka ⽹络端⼝ 发送适当的字节序列,就可以实现从 Kafka 读取消息或往 Kafka 写⼊消息。还有很多⽤其他语 ⾔实现的 Kafka 客户端,⽐如 C++、 Python、Go 语⾔等,它们都实现了 Kafka 的连接协议, 使得 Kafka 不仅仅局限于在 Java ⾥使⽤。这些客户端不属于 Kafka 项⽬,不过 Kafka 项⽬ wiki 上提供了⼀个清单,列出了所有可⽤的客户端。
4.1生产者概览
使用场景区分需求
⼀个应⽤程序在很多情况下需要往 Kafka 写⼊消息:记录⽤户的活动(⽤于审计和分析)、记录度量 指标、保存⽇志消息、记录智能家电的信息、与其他应⽤程序进⾏异步通信、缓冲即将写⼊到数据库 的数据,等等。 多样的使⽤场景意味着多样的需求:是否每个消息都很重要?是否允许丢失⼀⼩部分消息?偶尔出现 重复消息是否可以接受?是否有严格的延迟和吞吐量要求? 在之前提到的信⽤卡事务处理系统⾥,消息丢失或消息重复是不允许的,可以接受的延迟最⼤为 500ms,对吞吐量要求较⾼——我们希望每秒钟可以处理⼀百万个消息。
保存⽹站的点击信息是另⼀种使⽤场景。在这个场景⾥,允许丢失少量的消息或出现少量的消息重 复,延迟可以⾼⼀些,只要不影响⽤户体验就⾏。换句话说,只要⽤户点击链接后可以⻢上加载⻚ ⾯,那么我们并不介意消息要在⼏秒钟之后才能到达 Kafka 服务器。吞吐量则取决于⽹站⽤户使⽤⽹ 站的频度。 不同的使⽤场景对⽣产者 API 的使⽤和配置会有直接的影响。
流程
在发送 ProducerRecord 对象------序列化------>>分区器--->>发动到主题-->>
如果消息成功写⼊ Kafka,就返回⼀个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区⾥的偏移量。如果写⼊失败, 则会返回⼀个错误。⽣产者在收到错误之后会尝试重新发送消息,⼏次之后如果还是失败,就返回错 误信息