LLM 如火如荼地发展了大半年,各类大模型和相关框架也逐步成型,可被大家应用到业务实际中。在这个过程中,我们可能会遇到一类问题是:现有的哪些数据,如何更好地与 LLM 对接上。像是大家都在用的知识图谱,现在的图谱该如何借助大模型,发挥更大的价值呢?
在本文,我便会和大家分享下如何利用知识图谱构建更好的 In-context Learning 大语言模型应用。
此文最初以英文撰写的,而后我麻烦 ChatGPT 帮我翻译成了英文。下面是翻译的 prompt:
“In this thread, you are a Chinese Tech blogger to help translate my blog in markdown from English into Chinese, the blog style is clear, fun yet professional. I will paste chapters in markdown to you and you will send back the translated and polished version.”
LLM 应用的范式
作为认知智能的一大突破,LLM 已经改变了许多行业,以一种我们没有预料到的方式进行自动化、加速和启用。我们每天都会看到新的 LLN 应用被创建出来,我们仍然在探索如何利用这种魔力的新方法和用例。
将 LLM 引入流程的最典型模式之一,是要求 LLM 根据专有的/特定领域的知识理解事物。目前,我们可以向 LLM 添加两种范式以获取这些知识:微调——fine-tune 和 上下文学习—— in-context learning。
微调是指对 LLM 模型进行附加训练,以增加额外的知识;而上下文学习是在查询提示中添加一些额外的知识。
据观察,目前由于上下文学习比微调更简单,所以上下文学习比微调更受欢迎,在这篇论文中讲述了这一现象:https://arxiv.org/abs/2305.16938。
下面,我来分享 NebulaGraph 在上下文学习方法方面所做的工作。
Llama Index:数据与 LLM 之间的接口
上下文学习
上下文学习的基本思想是使用现有的 LLM(未更新)来处理特定知识数据集的特殊任务。
例如,要构建一个可以回答关于某个人的任何问题,甚至扮演一个人的数字化化身的应用程序,我们可以将上下文学习应用于一本自传书籍和 LLM。在实践中,应用程序将使用用户的问题和从书中"搜索"到的一些信息构建提示,然后查询 LLM 来获取答案。
┌───────┐ ┌─────────────────┐ ┌─────────┐
│ │ │ Docs/Knowledge │ │ │
│ │ └─────────────────┘ │ │
│ User │─────────────────────────────────────▶ LLM │
│ │ │ │
│ │ │ │
└───────┘ └─────────┘
在这种搜索方法中,实现从文档/知识(上述示例中的那本书)中获取与特定任务相关信息的最有效方式之一是利用嵌入(Embedding)。
嵌入(Embedding)
嵌入通常指的是将现实世界的事物映射到多维空间中的向量的方法。例如,我们可以将图像映射到一个(64 x 64)维度的空间中,如果映射足够好,两个图像之间的距离可以反映它们的相似性。
嵌入的另一个例子是 word2vec 算法,它将每个单词都映射到一个向量中。例如,如果嵌入足够好,我们可以对它们进行加法和减法操作,可能会得到以下结果:
vec(apple) + vec(pie) ≈ vec("apple apie"),或者向量测量值 vec(apple) + vec(pie) - vec("apple apie") 趋近于 0:
|vec(apple) + vec(pie) - vec("apple apie")| ≈ 0
类似地,“pear” 应该比 “dinosaur” 更接近 “apple”:|vec(apple) - vec(pear)| < |vec(apple) - vec(dinosaur)|
有了这个基础,理论上我们可以搜索与给定问题更相关的书籍片段。基本过程如下:
- 将书籍分割为小片段,为每个片段创建嵌入并存储它们
- 当有一个问题时,计算问题的嵌入
- 通过计算距离找到与书籍片段最相似的前 K 个嵌入
- 使用问题和书籍片段构建提示
- 使用提示查询 LLM
┌────┬────┬────┬────┐
│ 1 │ 2 │ 3 │ 4 │
├────┴────┴────┴────┤
│ Docs/Knowledge │
┌───────┐ │ ... │ ┌─────────┐
│ │ ├────┬────┬────┬────┤ │ │
│ │ │ 95 │ 96 │ │ │ │ │
│ │ └────┴────┴────┴────┘ │ │
│ User │─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─▶ LLM │
│ │ │ │
│ │ │ │
└───────┘ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ └─────────┘
│ ┌──────────────────────────┐ ▲
└────────┼▶│ Tell me ....., please │├───────┘
└──────────────────────────┘
│ ┌────┐ ┌────┐ │
│ 3 │ │ 96 │
│ └────┘ └────┘ │
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
Llama Index
Llama Index 是一个开源工具包,它能帮助我们以最佳实践去做 in-context learning:
- 它提供了各种数据加载器,以统一格式序列化文档/知识,例如 PDF、维基百科、Notion、Twitter 等等,这样我们可以无需自行处理预处理、将数据分割为片段等操作。
- 它还可以帮助我们创建嵌入(以及其他形式的索引),并以一行代码的方式在内存中或向量数据库中存储嵌入。
- 它内置了提示和其他工程实现,因此我们无需从头开始创建和研究,例如,《用 4 行代码在现有数据上创建一个聊天机器人》。
文档分割和嵌入的问题
嵌入和向量搜索在许多情况下效果良好,但在某些情况下仍存在挑战,比如:丢失全局上下文/跨节点上下文。
想象一下,当查询"请告诉我关于作者和 foo 的事情",在这本书中,假设编号为 1、3、6、19-25、30-44 和 96-99 的分段都涉及到 foo 这个主题。那么,在这种情况下,简单地搜索与书籍片段相关的前 k 个嵌入可能效果不尽人意,因为这时候只考虑与之最相关的几个片段(比如 k = 3),会丢失了许多上下文信息。
┌────┬────┬────┬────┐
│ 1 │ 2 │ 3 │ 4 │
├────┴────┴────┴────┤
│ Docs/Knowledge │
│ ... │
├────┬────┬────┬────┤
│ 95 │ 96 │ │ │
└────┴────┴────┴────┘
而解决、缓解这个问题的方法,在 Llama Index 工具的语境下,可以创建组合索引和综合索引。
其中,向量存储(VectorStore)只是其中的一部分。除此之外,我们可以定义一个摘要索引、树形索引等,以将不同类型的问题路由到不同的索引,从而避免在需要全局上下文时错失它。
然而,借助知识图谱,我们可以采取更有意思的方法:
知识图谱
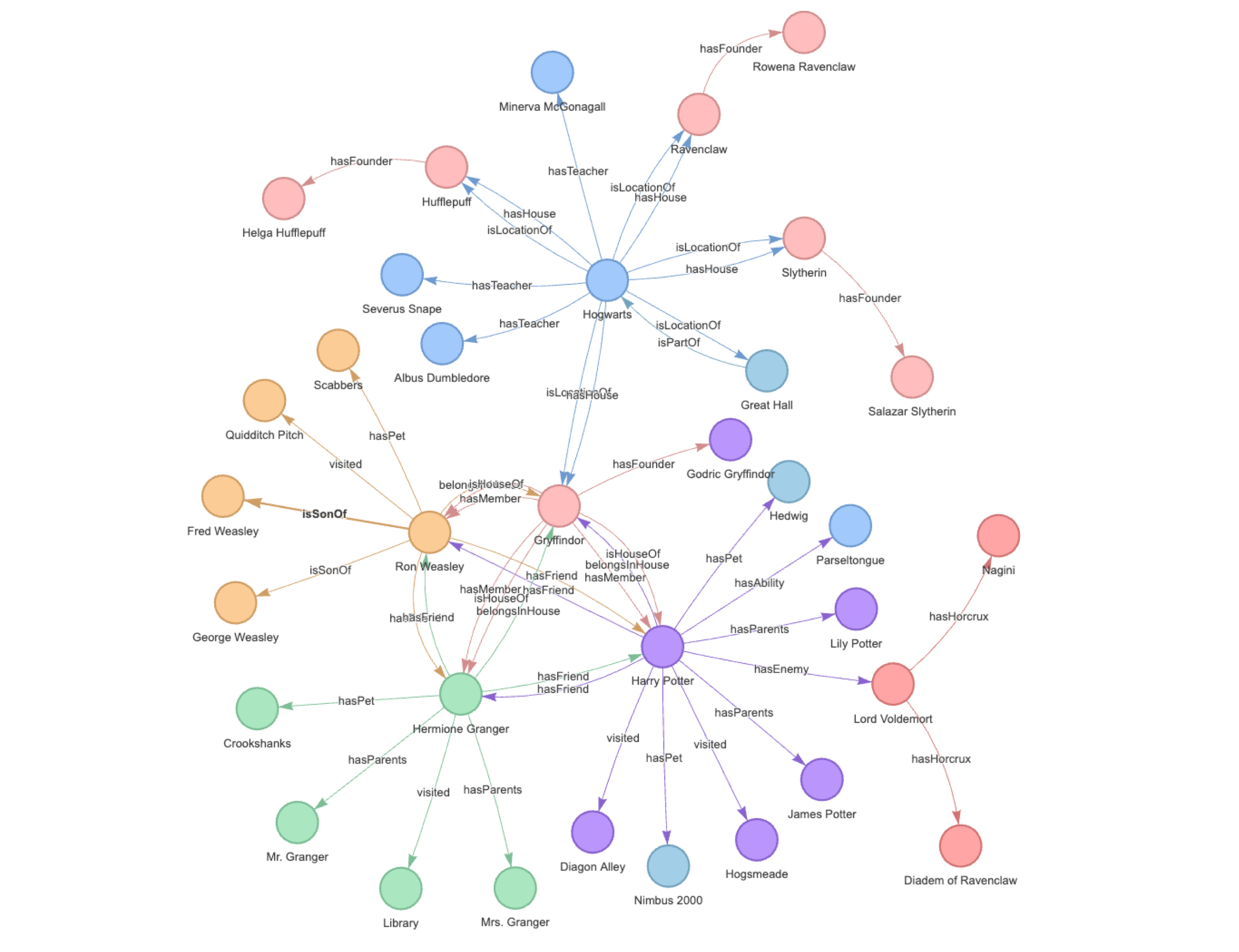
知识图谱这个术语最初由谷歌在 2012 年 5 月提出,作为其增强搜索结果,向用户提供更多上下文信息的一部分实践。知识图谱旨在理解实体之间的关系,并直接提供查询的答案,而不仅仅返回相关网页的列表。
知识图谱是一种以图结构形式组织和连接信息的方式,其中节点表示实体,边表示实体之间的关系。图结构允许用户高效地存储、检索和分析数据。
它的结构如下图所示:
现在问题就来了,上面说过知识图谱能帮忙搞定文档分割和嵌入的问题。那么,知识图谱到底能怎么帮到我们呢?
嵌入和知识图谱的结合
这里的基本实现思想是,作为信息的精炼格式,知识图谱可切割的数据颗粒度比我们人工的分割的更细、更小。将知识图谱的小颗粒数据与原先人工处理的大块数据相结合,我们可以更好地搜索需要全局/跨节点上下文的查询。
下面来做个题:请看下面的图示,假设提问同 x 有关,所有数据片段中有 20 个与 x 高度相关。现在,除了获取主要上下文的前 3 个文档片段(比如编号为 1、2 和 96 的文档片段),我们还从知识图谱中对 x 进行两次跳转查询,那么完整的上下文将包括:
- 问题:“Tell me things about the author and x”
- 来自文档片段编号 1、2 和 96 的原始文档。在 Llama Index 中,它们被称为节点 1、节点 2 和节点 96。
- 包含 “x” 的知识图谱中的 10 个三元组,通过对
x进行两层深度的图遍历得到:- x -> y(来自节点 1)
- x -> a(来自节点 2)
- x -> m(来自节点 4)
- x <- b-> c(来自节点 95)
- x -> d(来自节点 96)
- n -> x(来自节点 98)
- x <- z <- i(来自节点 1 和节点 3)
- x <- z <- b(来自节点 1 和节点 95)
┌──────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ .─. .─. │ .─. .─. │ .─. │ .─. .─. │
│( x )─────▶ y ) │ ( x )─────▶ a ) │ ( j ) │ ( m )◀────( x ) │
│ `▲' `─' │ `─' `─' │ `─' │ `─' `─' │
│ │ 1 │ 2 │ 3 │ │ 4 │
│ .─. │ │ .▼. │ │
│( z )◀────────────┼──────────────────┼───────────( i )─┐│ │
│ `◀────┐ │ │ `─' ││ │
├───────┼──────────┴──────────────────┴─────────────────┼┴──────────────────┤
│ │ Docs/Knowledge │ │
│ │ ... │ │
│ │ │ │
├───────┼──────────┬──────────────────┬─────────────────┼┬──────────────────┤
│ .─. └──────. │ .─. │ ││ .─. │
│ ( x ◀─────( b ) │ ( x ) │ └┼▶( n ) │
│ `─' `─' │ `─' │ │ `─' │
│ 95 │ │ │ 96 │ │ │ 98 │
│ .▼. │ .▼. │ │ ▼ │
│ ( c ) │ ( d ) │ │ .─. │
│ `─' │ `─' │ │ ( x ) │
└──────────────────┴──────────────────┴──────────────────┴──`─'─────────────┘
显然,那些(可能很宝贵的)涉及到主题 x 的精炼信息来自于其他节点以及跨节点的信息,都因为我们引入知识图谱,而能够被包含在 prompt 中,用于进行上下文学习,从而克服了前面提到的问题。
Llama Index 中的知识图谱进展
最初,William F.H.将知识图谱的抽象概念引入了 Llama Index,其中知识图谱中的三元组与关键词相关联,并存储在内存中的文档中,随后Logan Markewich还增加了每个三元组的嵌入。
最近的几周中,我一直在与 Llama Index 社区合作,致力于将 “GraphStore” 存储上下文引入 Llama Index,从而引入了知识图谱的外部存储。首个知识图谱的外部存储是对接开源分布式图数据库 NebulaGraph,目前在我的努力下已经实现了。
在实现过程中,还引入了遍历图的多个跳数选项以及在前 k 个节点中收集更多关键实体的选项,用于在知识图谱中搜索以获得更多全局上下文。上面提到的这些变更还在陆续完善中。
在大模型中引入 GraphStore 后,还可以从现有的知识图谱中进行上下文学习,并与其他索引结合使用,这也非常有前景。因为知识图谱被认为具有比其他结构化数据更高的信息密度。
本文作为开篇,讲述了一些知识图谱和 LLM 的关系。在后续的文章中,将会偏向实操同大家分享具体的知识图谱和 LLM 的应用实践。
–
谢谢你读完本文 (///▽///)
欢迎前往 GitHub 来阅读 NebulaGraph 源码,或是尝试用它解决你的业务问题 yo~ GitHub 地址:https://github.com/vesoft-inc/nebula 想要交流图技术和其他想法,请前往论坛:https://discuss.nebula-graph.com.cn/